







Segment Anything
前言
被称为CV领域的GPT-3的工作,大一统了图像分割领域,实现了可提示及时分割,并且能够实现模糊感知,此外还构建了迄今最大的图像分割数据集,在1100万张授权的隐私图像上超过了10亿个mask。该工作中稿于ICCV 2023,其方法构建、实验设计以及写作格局都值得我们学习。
| Paper | https://arxiv.org/pdf/2304.02643.pdf |
|---|---|
| Code | https://github.com/facebookresearch/segment-anything |
| From | ICCV 2023 |
Abstract
本文提出SA项目,包含图像分割领域里新的任务、模型和数据集。作者构建了迄今最大的图像分割数据集,在1100万张授权的隐私图像上超过了10亿个mask。模型被设计和训练成可提示的,因此在新的图像和任务分布上有很好的泛化性能,甚至优于监督训练的结果。
1. Introduction
NLP领域预训练的基础模型可以轻松泛化到未见的任务和数据上,在prompt加持和训练语料的堆叠下,性能甚至能超过微调的模型。CV领域也对基础模型进行了探索,CLIP等多模态模型实现了文图两种模态的对齐,可以通过文本提示对视觉概念进行泛化, 但是CV的任务更为广泛,对于其中许多问题,并不存在丰富的训练数据。
本文的目标是为图像分割任务构建基础模型,通过在通用任务的大规模数据集上进行预训练,使用Prompt工程就能够将模型泛化到未见的数据分布中。为了实现这个目标,需要关注以下三个组件:
- 任务。什么样的任务可以实现零样本泛化?
- 模型。相应的模型架构是什么样的?
- 数据。什么数据可以驱动这样的任务和模型?
作者首先定义了足够通用的可提示分割任务,这就要求模型能够支持灵活提示,为了训练,那就需要大规模的数据。但是目前图像分割领域没有理想规模的数据集,因此作者构建了数据引擎,在帮助收集数据的同时又利用新数据更新模型。具体设计如下:
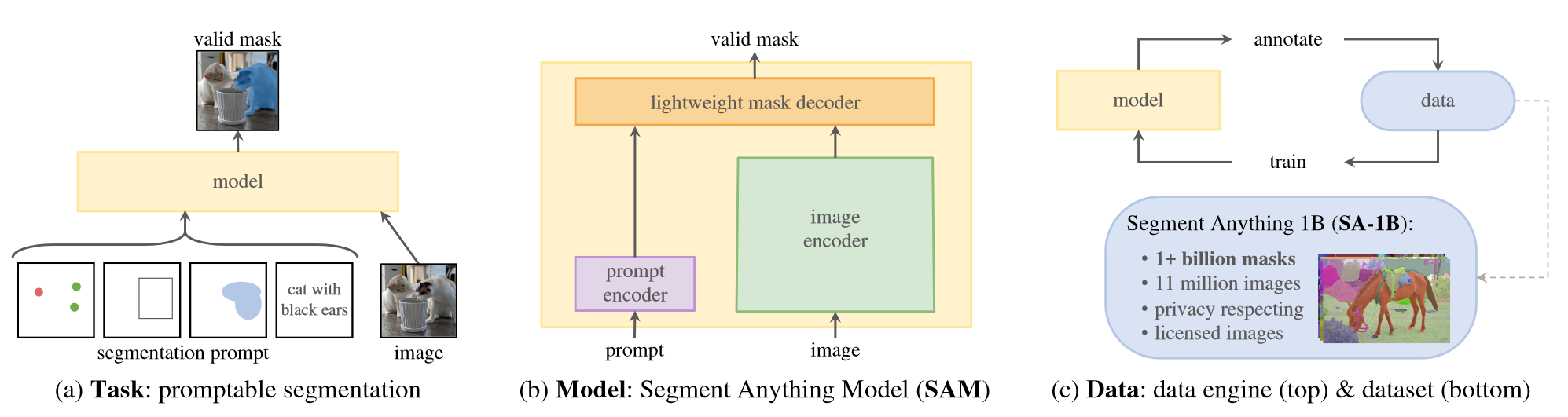
- 任务:作者提出可提示分割任务,一个prompt指出需要分割出图像中的内容,比如识别对象的空或者文本信息。合法的输出即使prompt模糊不清也能够找到一个或多个对象(见图1a)。作者使用可提示分割任务作为预训练任务,并通过提示工程解决下游任务。
- 模型:模型的关键在于支持灵活的提示,能够及时计算mask以允许交互,并且具有模糊感知。作者发现一个强大的图像编码器和一个prompt编码器,将二者的输出过一个轻量级的mask解码器(见图1b)就能够满足上面三个约束。该模型称为SAM,为了使SAM能够感知歧义,作者将其设计为预测单个Prompt的多个mask,从而让SAM自然处理歧义。
- 数据引擎:当前领域的数据量难以支撑模型的强泛化性能,潜在的解决方法是在线获取数据,但是mask并不丰富。为此,作者构建了数据引擎,它分为三个阶段,第一阶段,SAM协助标注人员标注mask;第二阶段,SAM通过提示对象可能位置对对象子集生成mask,标注人员只需要关注剩下的对象,提高标注的多样性;最后阶段,作者采用前景点的规则网格提示SAM,为每张图像产生约100个高质量的mask。
- 数据:本文提出的数据集,SA-1B,在1100万张图像上超过10亿个mask,全部由数据引擎生成,比现有任何分割数据集多400倍。
实验部分作者广泛评估了SAM,在23个分割数据集组合的数据集中,SAM能够生成高质量mask,通常只比手动注释略低。其次,在Prompt工程下,SAM展现出一致的强大定性和定量结果。这些实验表明SAM即插即用,具有极佳的泛化性能。

2. Segment Anything Task
可提示的分割任务受到NLP中基础模型通过自回归预训练,然后使用Prompt工程解决下游任务的启发。作者首先将Prompt的概念从NLP转化为分割,这里Prompt可以是一组前景/背景点、一个粗糙的框,自由的文本等,那么任务就是基于这些Prompt返回有效的分割,即使是模糊的对象,也需要返回一个合理的mask,如下图所示,每一列都是合理的输出。

任务提出了一种自然的预训练算法,根据每个训练样本的Prompt将模型的预测mask与真实情况进行比较,即使Prompt不够明确,也能够预测出有效的mask,这特别适用于在对下游任务零样本迁移过程。
图像分割是一个广阔的领域,包括交互式分割、边缘检测、超像素化、前景分割等任务,本文提出的可提示分割任务目标是产出一个基础模型,可以通过Prompt适用于任何分割任务,甚至是未见的任务,这种方法类似于其他基础模型的使用方式。此外,这与之前的多任务分割系统不同,多任务系统中单个模型执行一组固定的任务,并在相同的任务上进行测试,而本文的任务在下游执行不同的任务,泛化性更好。
3. Segment Anything Model
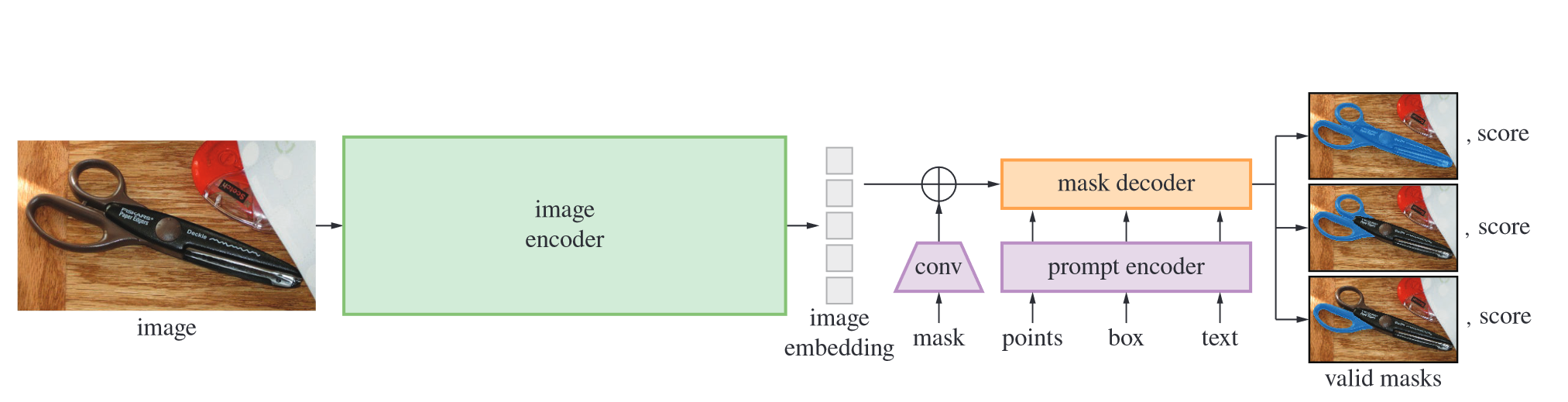
SAM模型包括三个组件:图像编码器,灵活的Prompt编码器,以及一个快速的mask解码器。
- 图像编码器采用MAE。
- Prompt编码器考虑了两种不同的Prompt形式:稀疏(点,锚框,文本)和密集(mask)。作者通过位置编码表示点和框,采用CLIP编码文本嵌入,密集Prompt采用卷积计算得到嵌入,并与图像的嵌入按元素求和。
- mask解码器将图像嵌入、Prompt嵌入以及输出token映射为mask。作者受到其他工作启发,采用动态mask预测head的解码器模块,该模块使用prompt自注意力和双向跨注意力(Prompt2Image and vice-versa)。运行两个块后进行上采样,MLP将输出的token映射到动态线性分类器,用于计算mask概率。
如果输入Prompt不明确,模型将会平均多个有效的mask。为了解决这个问题,作者修改模型以预测单个Prompt的多个输出mask,一般三个足以覆盖常见情况。模型的整体设计很大程度出于效率的考虑,给定图像嵌入,Prompt编码器和mask解码器在CPU上的耗时约50ms,可以实现实时的交互提示。对于损失函数和训练,作者采用焦点损失和骰子损失的线性组合来监督mask的预测,训练时采用混合的几何提示来训练可提示的分割任务。
4. Segment Anything Data Engine
为了解决互联网中分割数据不充足问题,作者构建了一个数据引擎用于构建SA-1B。引擎拥有三个阶段,模型辅助手动标注阶段,半自动阶段,以及全自动阶段。
- 辅助手动阶段。专业标注团队使用交互式分割工具来手动标记mask。该阶段初期,使用常见的公共分割数据集对SAM进行训练,经过足够多的数据标注,仅使用新注释的mask重新训练SAM。该阶段从12万张图像中收集了430万个mask。
- 半自动阶段。该阶段目标是增加mask的多样性,以提高模型分割的能力。作者首先自动检测置信的mask,在由标注人员标注未被检测出来的对象。该阶段作者在180k个图像中额外收集了590万个mask,让每张图像的平均mask数量从44增加到72。
- 全自动阶段。受益于开始阶段大量收集的mask,以及对于模糊情况下的有效预测,模型现在可以全自动标注。具体来说,作者采用32×32的规则点网格提示模型,为每个点预测一组可能有有效对象的mask。最后,模型在1100万张图片上生成了1.1B个高质量mask。
5. Segment Anything Dataset
数据集SA-1B的图片多样化,分辨率高,显著优于其他数据分割数据集如COCO。数据引擎为SA-1B自动生成了1.1B的mask,这些mask对于训练模型来说是高质量且有效的。为了评估mask的质量,作者随机采样了500张图片,并要求专业的标注人员提高标注的质量。该过程产生校准的mask,结果发现94%的mask的IoU高于90%,为了对比,之前工作的标注人员的一致性为85%-91%。
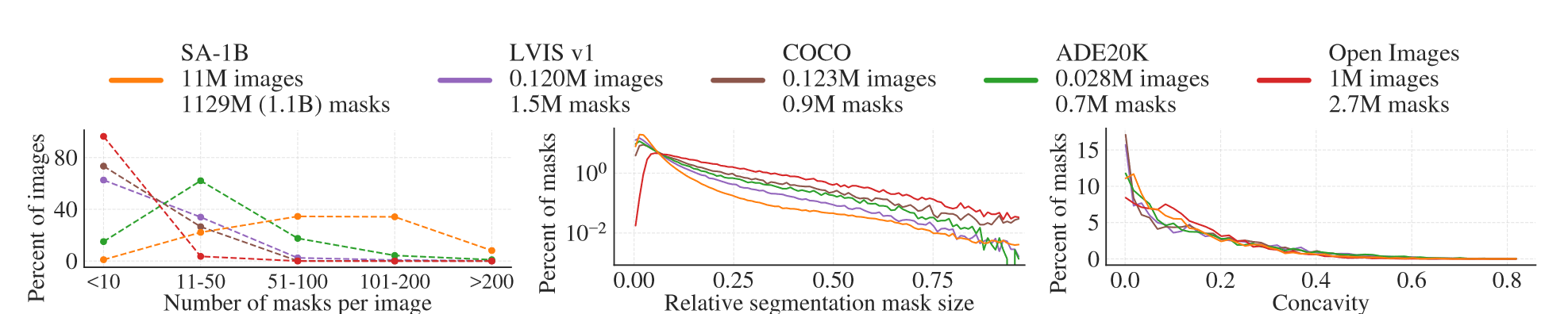
下图绘制了SA-1B中对象中心的空间分布与最大的现有分割数据集之间的比较。SA-1B对图像的覆盖更广。

从数量上看,SA-1B比第二大的Open Images多11倍,mask多400多倍,下图左边是每张图片平均mask的分布,中间图像是mask的尺寸,由于数据集中每个图像有更多的mask,因此它也包含更大比例的中小型相对尺寸mask。右图是mask凹度,可以看到各个数据集mask凹度的分布几乎一致。
6. Segment Anything RAI Analysis
接着作者调查了使用SA-1B和SAM时潜在的公平问题和偏见,对工作进行了严格的AI分析。

从地理上来看,图像最多的三个国家来自不同的地区,并且在中等收入国家中图像比例要高得多,此外,每个图像的平均mask数量在不同地区和收入之间相当一致。从公平角度,作者调查了性别表现、年龄和肤色的潜在公平问题。
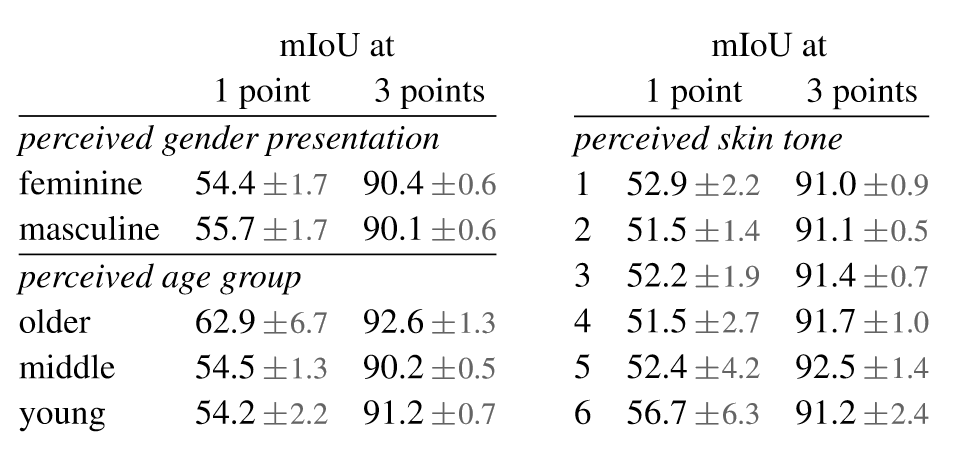
可以看到,虽然在各个维度上存在微小的差异,但整体上的表现是相似的,没有显著差异。
7. Zero-Shot Transfer Experiments
作者在5个任务上(4个与预训练任务显著不同)测试SAM的零样本迁移能力。
7.1. Zero-Shot Single Point Valid Mask Evaluation
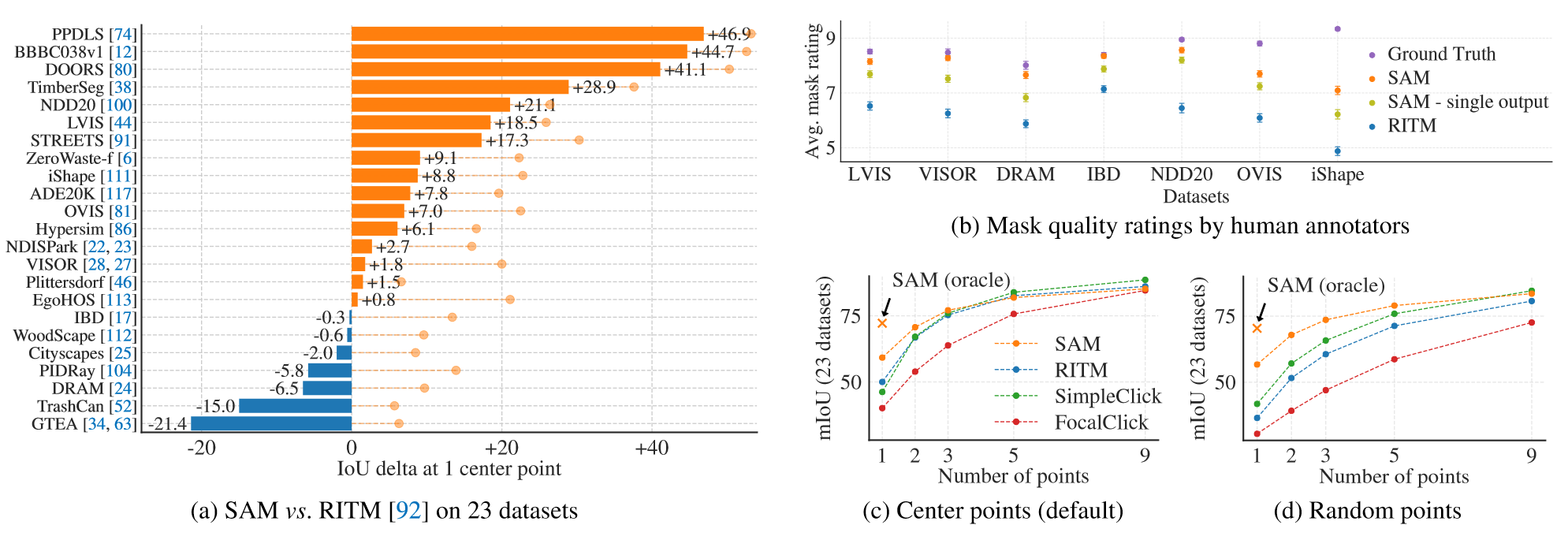
本节评估从单个前景点分割对象。测试数据集采用包含23个不同图像分布数据集的组合,如下图所示:

SAM在23个数据集中的16个上产生了更高的结果。作者还提出了一个Oracle结果,这是从SAM产生的三个mask中选择最真实的而不是最有信心的结果,这揭示了模糊性对自动评估的影响。人工评估的结果如下图b所示,SAM的质量始终高于最强baseline RRITM。图c展现了SAM优秀的单点能力,图d采用随机点采样替换默认的中心点采样,观察到SAM与baseline差距越来越大。
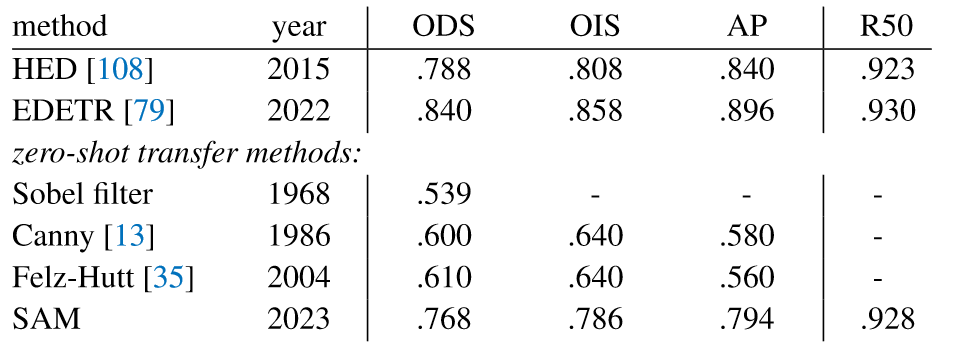
7.2. Zero-Shot Edge Detection
作者使用BSDS500在边缘检测任务上评估SAM。具体来说,作者采用16×16的前景点来提示SAM,生成768个mask,冗余的mask由NMS删除。

可以看到,SAM没有经过边缘检测的训练也能产生合理的边缘图。与真实值相比,SAM预测了更多边缘,明显优于之前的零样本迁移方法。
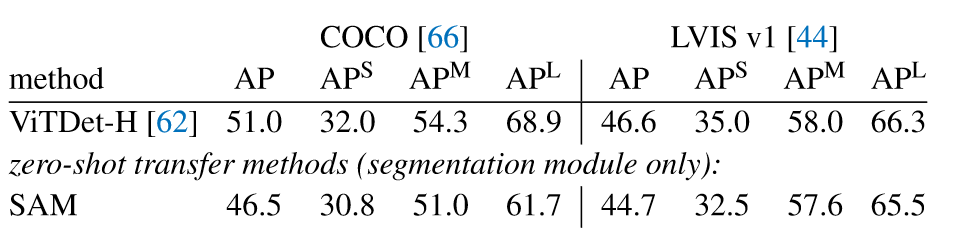
7.3. Zero-Shot Object Proposals
接下来,作者在对象提议生成的中级任务上评估SAM,为了能够生成对象提议,作者对SAM进行了修改。

虽然该领域最优的模型ViTDet-H总体表现最佳,但是SAM在几个指标上都有突出表现。
7.4. Zero-Shot Instance Segmentation
本节将SAM作为实例分割的模块。实验运行一个对象检测器,根据其输出框提示SAM。
结果如上图所示,虽然效果仍然落后于ViTDet-H,但是在mask质量上,SAM通常优于ViTDet。作者认为COCO上的mask有一定的偏差(质量较低),ViTNet学习了这种特定偏差,所以在指标上分数更高,但是实际效果不如SAM。

7.5. Zero-Shot Text-to-Mask
最后,作者考虑了更高级别的任务,即从自由文本中分割对象。作者将通过CLIP的文本得到的文本嵌入作为SAM的prompt。

上图展示了定性的结果,SAM可以根据简单的文本提示以及短语来分割对象,当无法选择正确对象时,附加点可以帮助修复预测。
7.6. Ablations

作者采用单中心点prompt对23个数据集组合进行多次消融实验。左图展示了SAM在数据引擎阶段累积数据时训练的性能。在所有三个阶段的训练中,自动mask的数量远超过手动和半自动mask的数量。为了解决这个问题,作者测试了仅使用自动mask的设置,结果仅略低于使用所有数据的性能。
上图中间研究了数据量的影响,可以看到0.1M时mIoU有较大的下降,而1M和11M的结果没有明显的区别,此时仍然包含100M个mask,这可能是比较实用的设置。
最后是图像编码器采用不同的规模的消融实验,可以看出进一步的图像编码器缩放没有明显的成效。
8. Discussion
本文工作的目标与分割领域的基础模型对齐,模型SAM展现出强大的泛化能力,在不同任务的数据集上执行零样本取得了不错的结果。虽然SAM表现优秀,但是它还是会错过精细的结构,也会出现不连贯的幻觉问题,不过SAM的初衷是通用性和广泛使用,而不是为了高IoU的交互分割。此外,SAM虽然可以实时处理prompt,但当使用重型的图像编码器时,SAM的整体性能不是实时的。
最后进一步总结,SAM项目试图将图像分割提升到基础模型时代,本文的主要贡献是提出新的分割领域大一统任务,分割模型SAM和数据集SA-1B。SAM能否成为基础模型还需要时间的检验。
阅读总结
许多科研人员都将SAM称为是CV领域的GPT-3,是具有跨时代意义的工作。从方法阐述、实验分析以及演示效果来看,SAM提出新的任务大一统了图像分割领域的大部分任务,就像NLP中自回归任务大一统NLP任务一样。SAM优秀的泛化性能让其在未见的任务上也有优异的表现。文章中作者指出SAM有三点大的贡献:新的任务,新的模型以及新的数据集,此外还指出三点在应用中的贡献:可提示,及时响应以及模糊感知,这表明SAM的初衷不只是一篇形而上的文章,而是真正能够落地的方法。
SAM工作看起来并不复杂,它真正的难点可能就在于如何将不同的分割任务大一统,而实现的过程也很简单,将这些分割任务的指示作为prompt就好了,即对不同的指示(点、锚框、文本等)统一编码成嵌入再和图像编码融合训练。剩下的工作都是工程了,所以优秀的工作并不是复杂且繁琐的,而是如何透过现象看本质,找到研究内容的共性,这才是科研的真功夫,才是优秀工作必备的条件。
当然,SAM还有一些问题,比如性能上确实比不过某个具体任务上的模型,分割时会出现幻觉,分割也不够细致,在自然语言prompt下分割不够准确等,这些都是日后可以改进的点,这并不影响SAM在分割领域里程碑式的意义。
















 1350
1350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











