






1: ambiguious:
条件:
出现至少两个parse tree或者两种最左/右推导,
一般来说形式是A->aAbA,A->c|d,此时只需要利用第二个式子的两种情况分别替换第一个式子的两个A,如果得到相同结果即可。
2: 生成最小状态
1: 根据是否是终结状态分为两个集合
2: 看第一个集合输入a是否会进入第二个集合,将其细分
3: 看第二步分好的集合输入b是否会进入不同的集合
…
有时候可以从DFA的表格中直接看出来
3: 正则表达式转为NFA:
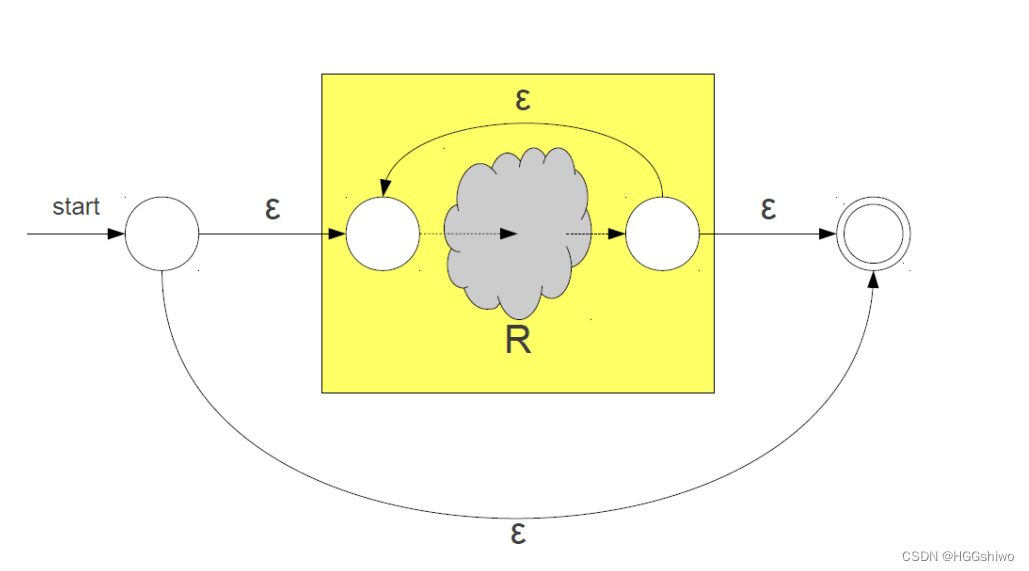
闭包: 增加两个状态和两个转移
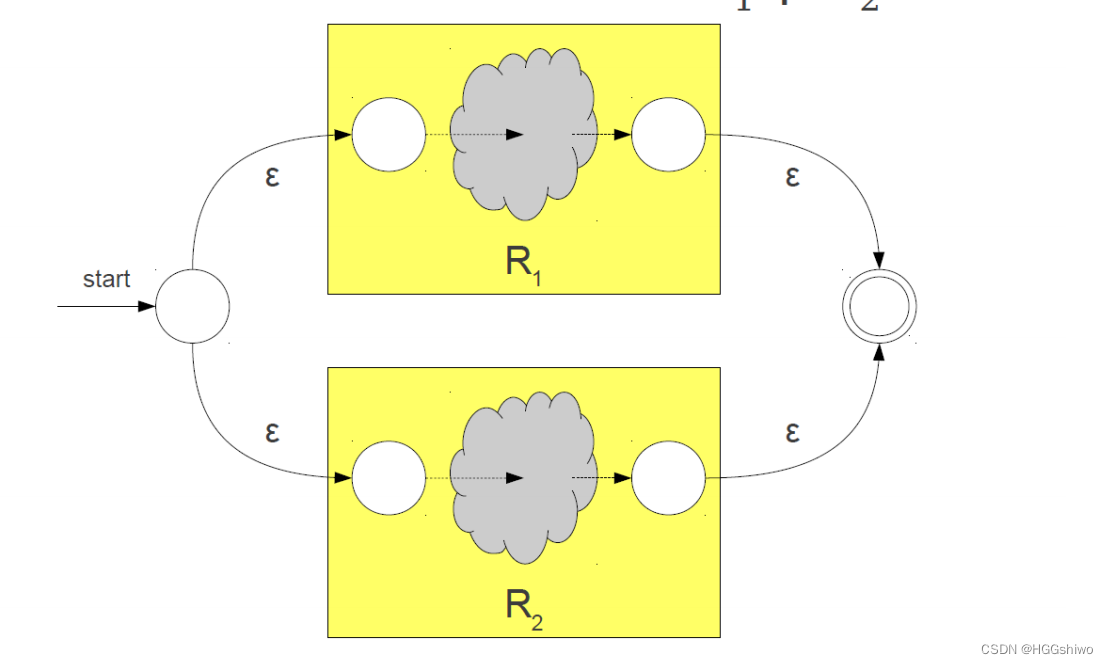
或: 增加2个状态和n个转移
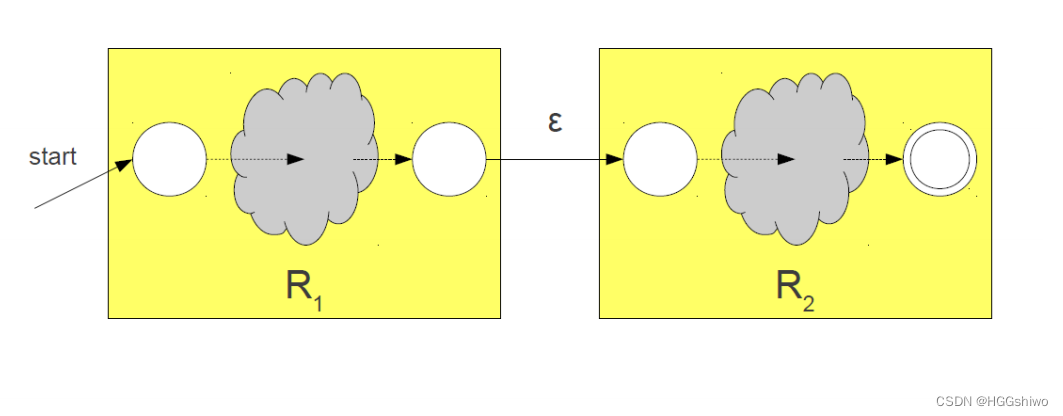
连接:增加一个转移
4: NFA转为DFA
需要列出的列:S, S ˉ \bar{S} Sˉ, Sa, Sb, Sc,…
S表示初始状态, S ˉ \bar{S} Sˉ表示S经过 ϵ \epsilon ϵ转移到达的状态,包括S状态本身,Sx表示输入x后到达的状态。其中 S ˉ \bar{S} Sˉ需要比较大的空间,其他的空间较小。
1: 列出哪几个状态可以通过输入a,b,c,d,…到达
2: 从开始状态开始,作为S, 然后计算 S ˉ \bar{S} Sˉ,在上面的表对应项找是否有可以输入x到达下一个状态的。
5: 构造LL(1) parse table
表格的列:所有的非终结符,行:所有的终结符+$
对于表格M[N,T]:
- 把或的都写开来
- 对于每一行,如果非终结符在FIRST集中,找一条规则填入
- 填完以后观察有FIRST(A)中是否有e,将A->e填入FOLLOW(A)中

6: 判断是否是LL(1)
如果已经有LL(1) table,则
LL(1) table includes/doesn’t include anyentry that has more than one item
如何求了FIRST集和FOLLOW集:
1: 对于A-> B1|B2|B3|…, 要求任意两个FIRST(Bi) ∩ FIRST(Bj) = Φ
2: 对于A->e|b , 要求FIRST(b) ∩ FOLLOW(A) = Φ
7: 消除left-recursion:
1: 对于A->Ax1|Ax2|y1|y2|…用A’表示递归产生的式子:
A->y1A’|y2A’|…
然后用A’->x1A’|x2A’|e生成递归产生的符号, 小心注意不要忘记e
2: 如果有A->B, B->Axx|yy这种隐式的,需要将B代入到A
改为A->Axx|yy,然后进行修改
8: 求FIRST集和FOLLOW集:
加入的顺序:

first集:
1: 终结符和e的first集就是其本身
2: 计算非终结符的first集,对于A->abc
将First(a)-{e}加入到First(A)中,注意不是First(A)等于First(a),而是First(a) in First(A)
3: 如果First(a)包含e, 则将First(b)-{e}加入First(A),依次类推
4.对于A->abcd, 只有当a,b,c,d都包含e时,将e加入First(A)
注意:
1: 计算时的顺序,先算右侧是终结符开始的式子
2: 出现|符号的,两边都加入FIRST集
follow集:
将FOLLOW集看成水杯,
1 if A is the start symbol, the $ is in the Follow(A).
2 if there is a production B→ α Aγ, then First(γ)-{ε} is in Follow(A).
3 if there is a production B→α Aγ, such that ε in First(γ), then Follow(A) contains Follow(B)
注意:
1: 不要忘记开始时将$加入FOLLOW(S)
2: 先观察右侧的非终结符,将后面的FIRST集导入该终结符,
然后将左边的FOLLOW集倒入右边的最后一个
此时注意如果右边最后一个可能为e时,需要再倒入倒数第二个
3: 后面倒入前面的时候,是First集倒入,不是follow集,一定要小心
4: FOLLOW集中不包含e
5: FOLLOW集只计算非终结符的
例子:
P → A | L
L → (S)
S→ PS’
S’→ PS’| ε
A → n|i
写开来:
| 序号 | 推导规则 |
|---|---|
| 1 | P->A |
| 2 | P->L |
| 3 | L->(S) |
| 4 | S->PS’ |
| 5 | S’->PS’ |
| 6 | S’->e |
| 7 | A->n|i |
算First集:先算右侧开始是终结符的:
First(L) = {(},
First(S’) = {e},
First(A) = {n,i}
然后算右侧是非终结符开始的
r1: First( P) = {n, i}
r2: First( P) = {n, i, (}
r4: First( S) = {n, i, (}
r5: Firsrt(S’) = {n, i, (, e}
算FOLLOW集:
第一轮:
P = {$}
r1: P->A: A={$}
r2: P->L: L={$}
r3: (->S: S={)}
r4: First(S’)-{e}->P, S->P P={n,i,(,),$}, S->S’ S’={)}
第二轮
r1:P->A: A={$,n,i,(,)}
r2: P->L: L={$,n,i,(,)}
完成
9. parse中的操作
LL1:
generate(将非终结符替换)
match (消去终结符)
accept(接受)
LR0:
shift(移动)
reduce(将栈中的元素替换为终结符)
accept(接受)
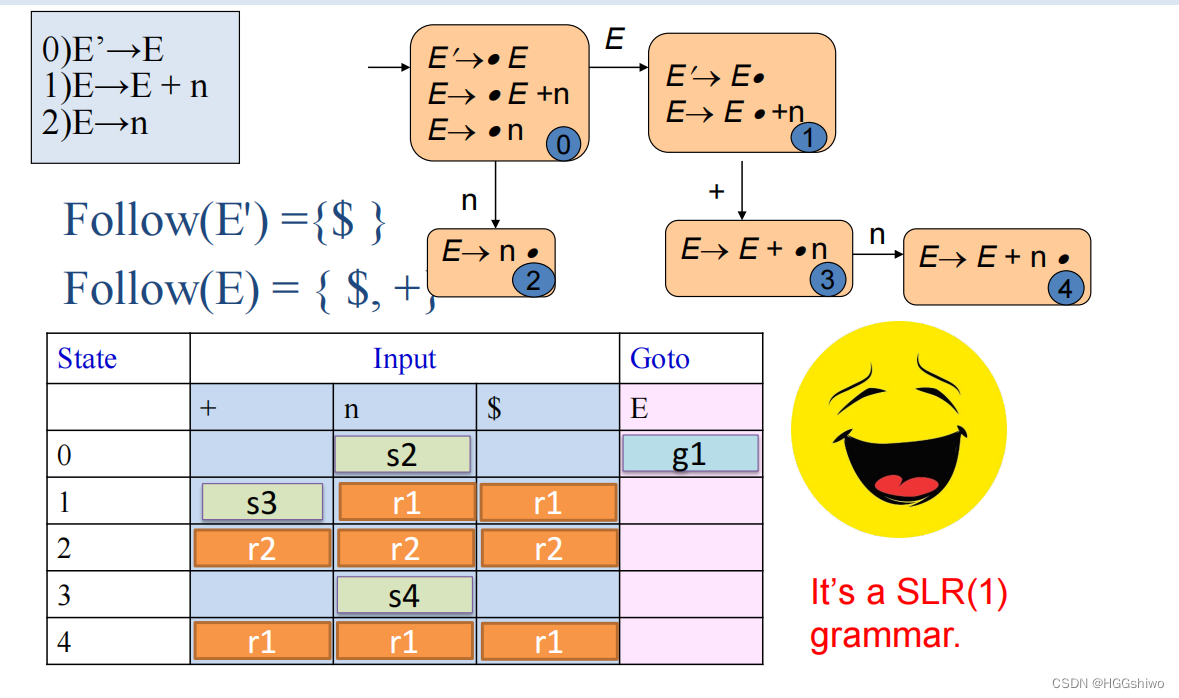
10. 对比LR,SLR
shift的条件相同,都是A->xx.yyy,如果下一个输入y,则移动为A->xxxy.yyy
只有reduce的条件不同
| LR(0) | SLR(1) | LR(1) | LALR(1) | |
|---|---|---|---|---|
| 什么时候选择reduce | 任意输入(不是$) | A->abc.,当下一个输入在FOLLOW(A)中时 | 下一个输入是lookhead | 下一个输入是lookhead |
| 出现了reduce-reduce是否矛盾 | 不能出现两条reduce | A->xxx. B->yyy.中,FOLLOW(A)和FOLLOW(B)不能有交集 | 要求两条reduce的lookhead不同 | 要求reduce的lookhead集都不同 |
| 出现了reduce-shift是否矛盾 | 不能同时出现reduce-shift | A->xxx.yyy, B->zzz.,要求y不在FOLLOW(B)中 | 要求A->xxx.yyy,则y不在reduce的lookhead中 | 要求A->xx.yyy, y不在reduce的lookhead集中 |
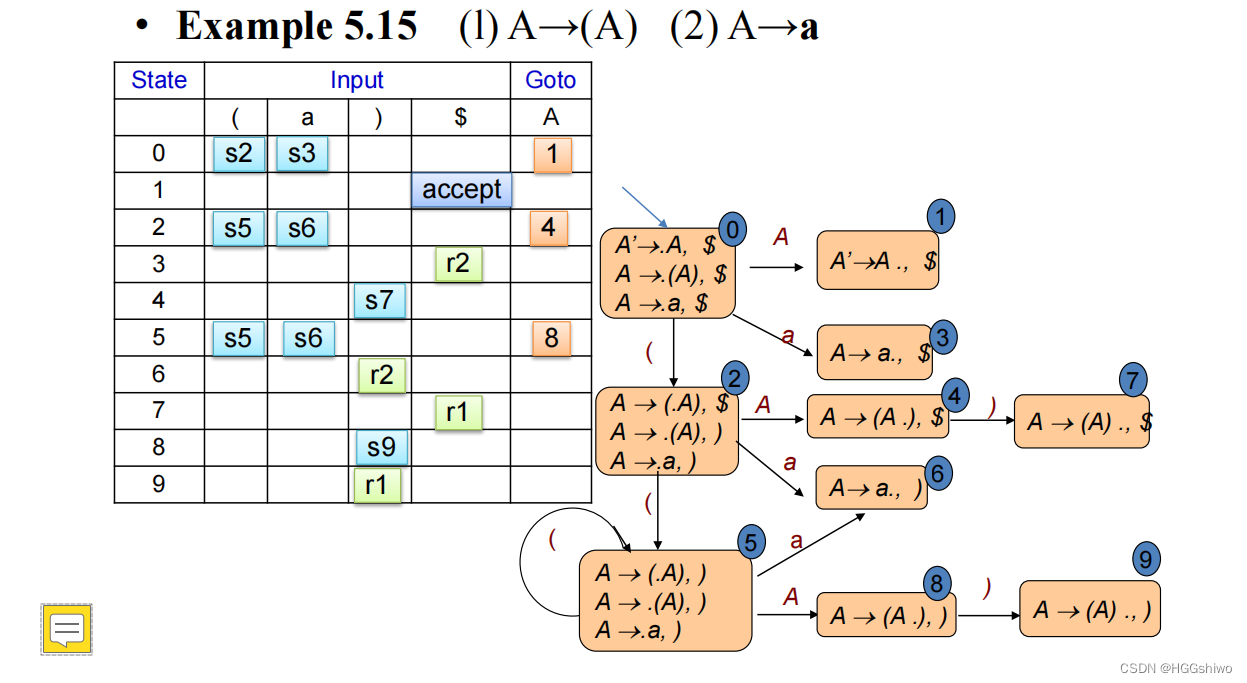
11.构建DFA:
0: 增加一条规则 S’->S, 写出所有的LR(0) item(方便核的扩充),如果是A->e,则直接写为A->.即可
1: 通过S->.Bxxx作为开始状态的核
2: 如果点后面是一个非终结符B,将B->.xxx全部加入该状态,递归进行,直到点后面全部为终结符
3: 如果出现A->xxxx.表明是一个reduce, 如果出现了A->xxx.yyy,则通过y进入核为A->xxxxy.yyy,的状态
4: 对于每一步,如果点后面是非终结符,则一定别忘记扩充。
5: 对于LR(1),后面跟上一个lookhead,
- 开始状态lookhead是$, lookhead只有在从核扩展的时候发生改变,如果A->xxx.Byyy, z,则增加为B->.tttt, Firsrt(yyyz)
- 值得注意的是: B的lookhead虽然是通过FIRST(yyyz)计算出来的,但是一定也在FOLLOW(B)中
12. LR(1) parse table
先构建DFA,然后构建parse table。将终结符和$写在Input下面,将非终结符写在Goto下面。
按照状态来填,
- 如果是移动,输入是终结符则填写s+目的状态,输入是非终结符,则填写g+目的状态
- 如果是终止状态,则填写r+哪一条规约规则
- 如果是S’->S的,在$中填写acc
注意在LR(0)中,输入任何值都进行规约,所以reduce state整行是r,如果是SLR(1)或者LR(1)等,则需要根据输入是否符合要求看是否规约。
A→(A) | a LR(0)
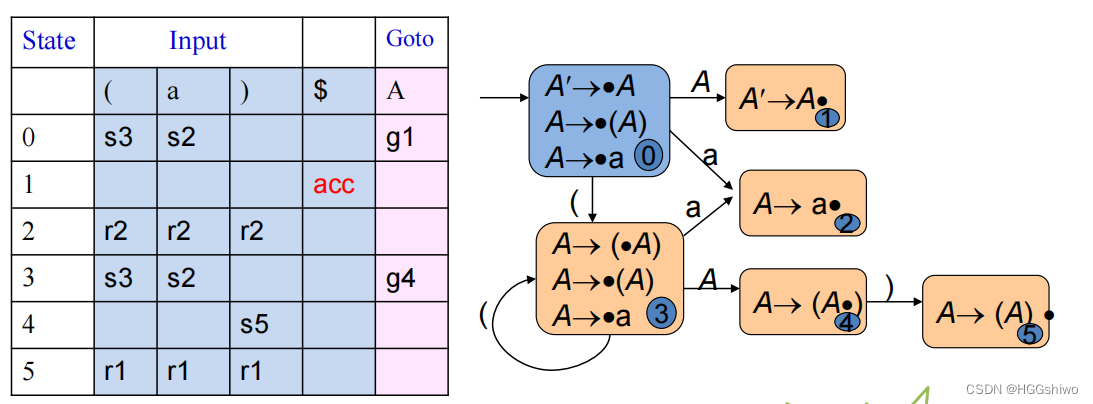
SLR(1)
A→(A) | a LR(1)
13.能力大小比较:
LR(1)>LALR(1)>SLR(1)>LR(0)>LL(1)
14.栈溢出:
LR如果有右递归,则可能发生栈溢出。
15. viable prefixes
对于一个推导过程:E’ => E => E+n => n+n,将其倒着写:
n+n
E+n
E
E’
然后将上下不一样的元素后面加上.
n.+n
E+n.
E.
E’
则可以看出栈中的元素就是点移动过去的元素
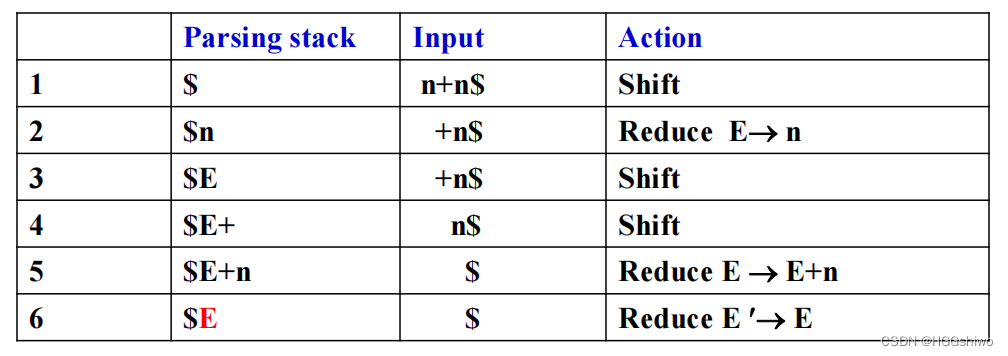
栈中的元素就是可行前缀















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









