






本文是DataWhale开源项目Sora原理与技术实战的第二次打卡任务的第一节,主要是简单试用Stable diffusion技术在魔塔社区进行文生图实践。同一打卡任务的其他小节请参见个人主页。
目录
4.基于Transformers的扩散(diffusion)模型
一.【AIGC简介——以文生图为例】
AlGC (不是ACGN)即 Al-Generated Content,人工智能生产内容,是利用Al来自动生产内容的生产方式。AIGC技术可以基于用户的输入或自动生成内容,无需或仅需很少的人工干预。这种技术的发展极大地推动了内容创作的自动化和个性化,为各种行业和应用提供了新的可能性。以图片生成任务为例,介绍其发展路线来理解AIGC技术的发展的进程,我们把文生图的发展历程发展成如下4个阶段:
1.基于生成对抗网络的(GAN)模型
生成对抗网络(GAN)是一种深度学习模型,由Goodfellow等人于2014年提出。GAN包含两个主要部分:生成器(Generator)和判别器(Discriminator)。生成器的目标是生成尽可能接近真实数据的假数据,而判别器的目标则是区分输入是真实数据还是生成器生成的假数据。这两部分在训练过程中相互对抗,不断优化,最终生成器能生成高质量的数据。GAN在图像生成、图像编辑、风格转换等方面有广泛应用。
GAN的优势是在一些窄分布(比如人脸)数据集上效果很好,采样速度快,方便嵌入到一些实时应用里面去。缺点是比较难训练、不稳定,因为具有潜在的不稳定训练和较少的生成多样性从而有Mode Collapse(模式崩塌)等问题。
2.基于自回归(Autoregressive)模型
自回归模型是一种序列数据生成模型,通过学习序列中前一个元素到下一个元素的映射来生成数据。这种模型在处理时间序列数据和语言模型中非常有效。自回归模型的一个关键特点是它们按顺序生成数据,每次生成一个数据点,依赖于之前生成的所有数据点。PixelRNN和PixelCNN是两个著名的基于自回归的图像生成模型,它们可以生成高质量的图像数据。因为每个code预测过程是有随机采样的,因此可以生成多样性比较高的不同图像。
3.基于扩散(diffusion)模型
扩散模型是一类近年来发展迅速的生成模型,它们通过模拟扩散过程(即从有序状态逐渐过渡到无序状态的过程)来生成数据。diffusion模型的灵感来源于非平衡态热力学,定义了一个马尔可夫链的扩散步骤,慢慢地向数据中添加随机噪声,然后学习逆向扩散过程,从噪声中构造所需的数据样本。在生成过程中,模型首先生成一个随机噪声,然后逐步将这个噪声转化为有意义的数据。这个过程类似于物理学中的扩散过程,但是方向相反。扩散模型在生成高质量图像和音频方面显示出了卓越的性能。扩散模型的数学推导可参见sora笔记(二):diffusion model推导 (yuque.com)
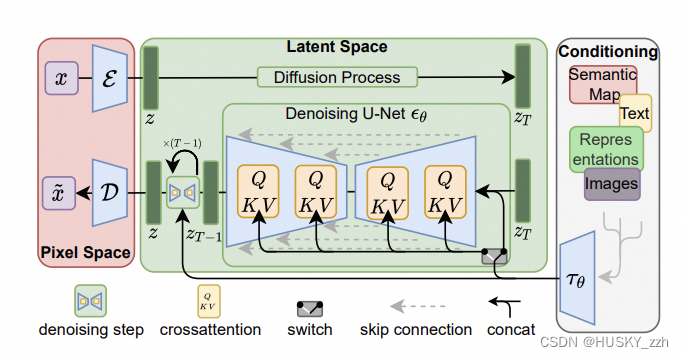
4.基于Transformers的扩散(diffusion)模型
结合了Transformers架构和扩散模型的优点,这类模型利用Transformers强大的序列建模能力来改进扩散模型的生成过程。Transformers能够处理长距离依赖问题,使得基于Transformers的扩散模型在理解和生成复杂数据方面更为有效。这种模型特别适合于处理大规模数据集,并且能生成高质量的图像、文本等数据。
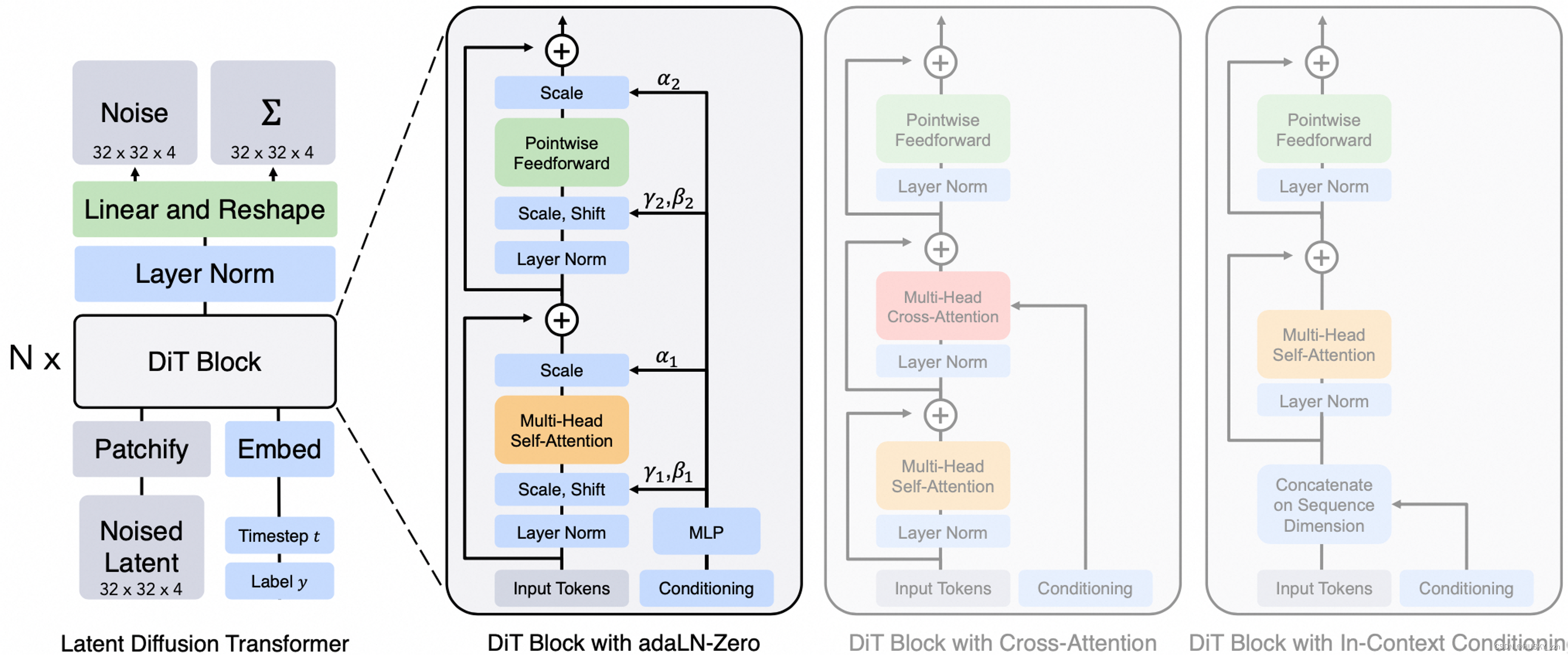
5.表格总结文生图的发展历程
| 特性 / 模型 | 生成对抗网络(GAN) | 自回归模型 | 扩散模型 | Transformers的扩散模型 |
| 优点 | 生成高质量、逼真图像 | 生成过程可控,稳定 | 能生成高质量图像;较强的理论基础 | 结合Transformers和扩散模型的优点;处理长距离依赖能力强 |
| 缺点 | 训练不稳定;模式坍塌 | 生成速度慢;计算成本高 | 训练过程复杂;计算资源要求高 | 极大的计算资源需求;模型复杂度高 |
| 训练参数量 | 大 | 中到大 | 大 | 非常大 |
| 适用范围 | 图像、视频、艺术作品生成 | 文本、图像像素级生成 | 图像、音频、视频生成 | 图像生成;文本到视频生成 |
| 图像生成模型举例 | DCGAN, Pix2Pix, CycleGAN | PixelRNN, PixelCNN | DDPM (Denoising Diffusion Probabilistic Models) | DALL·E, Imagen |
| 流行时间 | 2014年后 | 2016年后 | 2020年后 | 2021年后 |
二.【Stable diffusion技术】
扩散(diffusion)模型是一类生成模型,通过模拟扩散过程(即将结构化数据转化为无结构噪声的过程)和其逆过程(从噪声重建数据的过程)来生成数据。在图像生成的上下文中,这意味着模型首先学习如何将真实图像“扩散”成随机噪声,然后学习如何逆转这一过程,从噪声中“去噪”以生成图像。
Stable diffusion是一种用于将文本转换为图像的深度学习模型。只需输入任何文本,它就可以生成看起来像真实照片的高质量、逼真的图像。该模型的最新版本是Stable Diffusion XL,它具有更大的UNet主干网络,可以生成更高质量的图像。独特之处在于它可以生成高质量的图像,并对输出进行高度控制。它可以使用各种描述性文本输入(例如样式、框架或预设)生成输出。除了创建图像之外,SD 还可以通过修复和扩展图像的大小(称为修复)来添加或替换部分图像。
1.技术特点
- 高质量图像生成:Stable Diffusion能够生成高分辨率、逼真的图像,包括但不限于人物肖像、风景、艺术作品等。
- 文本到图像生成:它支持通过文本描述来引导图像生成过程,使用户能够通过输入文本描述来生成符合要求的图像。
- 编辑和修复能力:除了从头开始生成图像外,Stable Diffusion还可以用于编辑现有图像或修复图像中的缺陷。
2.实现机制
Stable Diffusion的实现依赖于几个关键步骤:
-
扩散与去噪过程:Stable Diffusion的核心是一个基于扩散的生成过程,该过程包括多个步骤,每一步将图像从带有高噪声的状态逐步转换为清晰的图像。这一过程是通过学习逆扩散过程实现的,即如何从噪声状态逐步恢复到清晰图像的过程。
-
条件生成的实现:在生成过程中,模型可以接收额外的信息(如文本描述)作为条件,这允许模型根据这些条件生成特定的图像。这是通过将条件编码融合到模型的去噪过程中来实现的,从而引导图像生成过程。
-
训练数据的重要性:Stable Diffusion的训练依赖于大量的图像数据及其相关的文本描述。这些数据使模型能够学习到丰富的视觉特征和它们与文本描述之间的关系,从而在生成过程中利用这些关系来产生符合文本条件的图像。
3.变分自编码器(VAE)
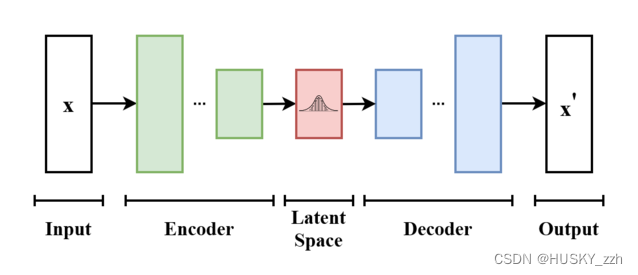
VAE是一种生成模型,它通过学习输入数据的潜在(latent)表示来生成新的数据实例。在Stable Diffusion中使用了VAE这种变分自编码器技术。VAE通常包括两部分:编码器和解码器。编码器负责将输入数据映射到一个潜在空间,而解码器则从潜在空间中的表示生成输出数据。潜在空间是一个较小的、连续的多维空间,可以捕捉输入数据的关键特征。
在Stable Diffusion中,VAE的使用与传统意义上的生成噪声图像不同,它是在潜在空间中操作。在训练过程中,Stable Diffusion首先使用编码器将图像映射到潜在空间中的一个点,然后在这个潜在表示上添加噪声。这个带噪声的潜在表示随后被解码器用来生成输出图像。通过这种方式,模型学习如何从带有噪声的潜在表示中恢复出清晰的图像。整个过程强调了从高噪声状态到清晰图像状态的逆扩散过程,但这一切都发生在高效且信息丰富的潜在空间中。这种在潜在空间中操作的方法不仅提高了效率,而且由于潜在空间的连续性和更高的抽象级别,还增强了生成图像的质量和多样性。这就是为什么Stable Diffusion能够快速生成高质量、具有多样性的图像的原因之一。这有几个关键优点:
- 潜在空间的高效性:通过在潜在空间而不是像素空间中添加噪声,模型操作的维度大大减少。潜在空间的维度通常远小于图像的像素维度,这意味着计算成本更低,处理速度更快。
- 保留关键信息:在潜在空间中添加噪声可以在保留输入数据关键特征的同时引入变化,因为潜在空间的表示捕获了输入数据的重要信息。这使得生成的图像既新颖又具有高质量。
- 控制和灵活性:通过控制潜在空间中的噪声,可以更精细地控制生成过程和结果。这种方法提供了对生成内容的更高级别的控制,使得模型能够根据给定条件生成更符合要求的图像。
三.【SD实践】
使用魔塔社区案例,具体请参考:Sora技术解析与实战-01 | Mikey
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
import cv2
pipe = pipeline(task=Tasks.text_to_image_synthesis,
model='AI-ModelScope/stable-diffusion-xl-base-1.0',
use_safetensors=True,
model_revision='v1.0.0')
prompt = "Beautiful and cute girl, 16 years old, denim jacket, gradient background, soft colors, soft lighting, cinematic edge lighting, light and dark contrast, anime, art station Seraflur, blind box, super detail, 8k"
output = pipe({'text': prompt})
cv2.imwrite('SDXL.png', output['output_imgs'][0])这段代码演示了如何使用ModelScope库来执行文本到图像合成任务,具体是利用Stable Diffusion XL模型根据给定的文本描述生成图像,并使用OpenCV将生成的图像保存到文件。
- 从`modelscope.utils.constant`导入`Tasks`,从`modelscope.pipelines`导入`pipeline`函数,该函数用于创建和配置特定任务的处理管道。导入`cv2`,即OpenCV库,用于图像处理和保存功能。
- 使用`pipeline`函数初始化一个管道,指定任务类型为`Tasks.text_to_image_synthesis`,表明这是一个文本到图像的合成任务。
- 指定模型为`'AI-ModelScope/stable-diffusion-xl-base-1.0'`,这是ModelScope平台上的一个预训练模型,基于Stable Diffusion技术。`use_safetensors=True`是指在处理数据时使用安全的张量操作,`model_revision='v1.0.0'`指定了模型的版本。
- 创建一个字符串`prompt`,包含用于生成图像的详细文本描述。这里描述了一个场景,包含年龄、服装、背景、颜色、光照条件等多个维度。
- 调用初始化好的管道`pipe`,并传入一个字典,其中`'text'`键对应于之前定义的文本提示`prompt`。管道处理该输入并返回生成的图像。
- 用`cv2.imwrite`函数,将生成的图像保存到文件`'SDXL.png'`。`output['output_imgs'][0]`从输出中取出第一张生成的图像
【引用】
【AI+X组队学习】Sora原理与技术实战:文生图片技术路径、原理与SD实战_哔哩哔哩_bilibili

















 4571
4571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









