






1. BCELoss
(BCELoss)BCEWithLogitsLoss用于单标签二分类或者多标签二分类,输出和目标的维度是(batch,C),batch是样本数量,C是类别数量,对于每一个batch的C个值,对每个值求sigmoid到0-1之间,所以每个batch的C个值之间是没有关系的,相互独立的,所以之和不一定为1。每个C值代表属于一类标签的概率。如果是单标签二分类,那输出和目标的维度是(batch,1)即可。
例如在图片多标签分类时,如果3张图片分3类,会输出一个3*3的矩阵。

先用Sigmoid给这些值都归一化到0~1之间:

假设Target是:



参考链接:https://blog.csdn.net/qq_22210253/article/details/85222093
2. BCEWithLogitsLoss
BCEWithLogitsLoss = Sigmoid+BCELoss,当网络最后一层使用nn.Sigmoid时,就用BCELoss,当网络最后一层不使用nn.Sigmoid时,就用BCEWithLogitsLoss。直接用刚刚的input验证一下是不是0.7193:

3. CrossEntropyLoss
CrossEntropyLoss用于多类别分类,输出和目标的维度是(batch,C),batch是样本数量,C是类别数量,每一个C之间是互斥的,相互关联的,对于每一个batch的C个值,一起求每个C的softmax,所以每个batch的所有C个值之和是1,哪个值大,代表其属于哪一类。如果用于二分类,那输出和目标的维度是(batch,2)。
CrossEntropyLoss损失函数结合了nn.LogSoftmax()和nn.NLLLoss()两个函数。它在做分类(具体几类)训练的时候是非常有用的。在训练过程中,对于每个类分配权值,可选的参数权值应该是一个1D张量。当你有一个不平衡的训练集时,这是是非常有用的。
什么是交叉熵?
交叉熵主要是用来判定实际的输出与期望的输出的接近程度,为什么这么说呢,举个例子:在做分类的训练的时候,如果一个样本属于第K类,那么这个类别所对应的的输出节点的输出值应该为1,而其他节点的输出都为0,即[0,0,1,0,….0,0],这个数组也就是样本的Label,是神经网络最期望的输出结果。也就是说用它来衡量网络的输出与标签的差异,利用这种差异经过反向传播去更新网络参数。


参考链接:https://zhuanlan.zhihu.com/p/98785902
4. MSELoss均方损失函数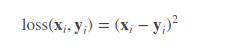
这里 loss, x, y 的维度是一样的,可以是向量或者矩阵,i 是下标。
很多的 loss 函数都有 size_average 和 reduce 两个布尔类型的参数。因为一般损失函数都是直接计算 batch 的数据,因此返回的 loss 结果都是维度为 (batch_size, ) 的向量。
一般的使用格式如下所示:
loss_fn = torch.nn.MSELoss(reduce=True, size_average=True)
这里注意一下两个参数:
A reduce = False,返回向量形式的 loss
B reduce = True, 返回标量形式的loss
C size_average = True,返回 loss.mean()
D 如果 size_average = False,返回 loss.sum()
默认情况下:两个参数都为True.
参考链接:https://www.cnblogs.com/dylancao/p/9848978.html
MSELoss()与CrossEntropyLoss() 区别
基于pytorch来讲
MSELoss()多用于回归问题,也可以用于one_hotted编码形式;
CrossEntropyLoss()名字为交叉熵损失函数,不用于one_hotted编码形式;
MSELoss()要求batch_x与batch_y的tensor都是FloatTensor类型;
CrossEntropyLoss()要求batch_x为Float,batch_y为LongTensor类型。
参考链接:https://blog.csdn.net/foneone/article/details/90127707
5. Focal Loss
Focal loss是何恺明针对训练样本不平衡提出的loss 函数。公式:
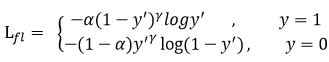
在Focal Loss中,它更关心难分类样本,不太关心易分类样本。
其中gamma>0,平衡因子alpha,用来平衡正负样本本身的比例不均。
alpha取值范围0~1,当alpha>0.5时,可以相对增加y=1所占的比例。实现正负样本的平衡。
虽然何凯明的试验中,lambda为2是最优的,但是不代表这个参数适合其他样本,在应用中还需要根据实际情况调整这两个参数。
参考链接:https://blog.csdn.net/wangdongwei0/article/details/84576044















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









