







每篇一句:
Nobody can go back and start a new beginning, but anyone can start today and make a new ending.
动态聚类算法:
在介绍K-均值算法之前,先介绍一下另一概念——动态聚类算法
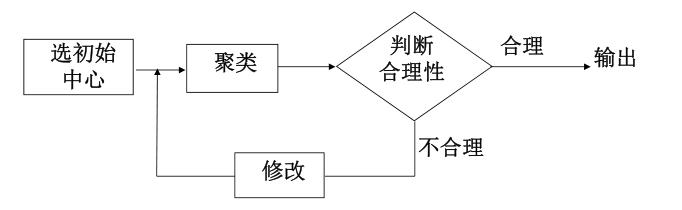
动态聚类法 的基本思想如下图:
两种常用算法:
K-均值算法 (又称C-均值算法)
迭代自组织的数据分析算法 (ISODATA: iterative self-organizing data analysis techniques algorithm)
K-均值算法:
K-均值算法 是一种动态聚类算法。
算法简介:
基于使聚类准则函数最小化。
- 准则函数: 聚类集中每一样本点到该类中心的距离平方和。
对所有K个模式类有:
Sj: 第 j 个聚类集,聚类中心为 Zj ;
Nj: 第 j 个聚类集 Sj 中所包含的样本个数。K-均值算法的聚类算法准则: 聚类中心的选择应使 准则函数J 极小,
即:使 Jj 的值极小。应有:
即:
可解得:
上式表明:Sj类的聚类中心应选为该类样本的均值 。
算法描述:
(1)任选K个初始聚类中心:Z1(1), Z2(1),… ,Zk(1)
括号内序号:迭代运算的次序号。
(2)按最小距离原则将其余样本分配到K个聚类中心中的某一个,即:
(3)计算各个聚类中心的新向量值:Zj(k+1) j=1,2,…,K
Nj:第 j 类的样本数
(4) 判断:
如果Zj(k+1)≠ Zj(k) j = 1, 2, … , K, 则回到(2),将模式样本逐个中心分类,重复迭代计算。
如果Zj(k+1)= Zj(k) j = 1, 2, … , K, 算法收敛,计算完毕。
算法分析:
聚类结果受到所选聚类中心的个数和其初始位置,以及模式样本的几何性质及读入次序的影响。实际应用中需要试探不同的K值和选择不同的聚类中心起始值。
优点:
思想简单易行;
时间复杂度接近线性;
- 对大数据集,是可伸缩和有效的;
缺点:
要求事先给出要生成的簇数k, 不适合的k值可能返回较差的结果;
不适合发现非凸形状的簇,或者大小差别很大的簇;
- 对噪声和离群点敏感;
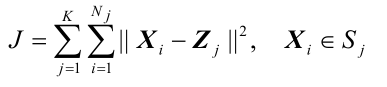
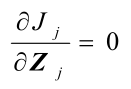
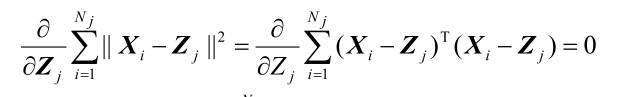
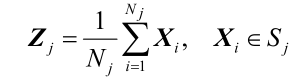
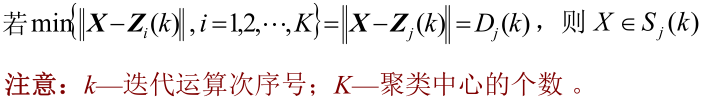
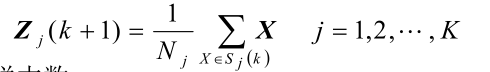
Python实现:
- 解释说明见代码中注释
# coding=utf-8
import math
from max_min_cluster import get_distance
def k_means_cluster(data, k):
# 初始化k个聚类中心
zs = [data[i] for i in range(k)]
result = step2(data, zs)
return result
def step2(data, zs):
# 根据初始化聚类中心分类
result = classify(data, zs)
# 得到新的聚类中心向量值
new_zs = get_newcluster(result)
# 判断是否结束
flag = is_end(zs, new_zs)
if flag:
return result
else:
return step2(data, new_zs)
def is_end(zs, new_zs):
# 判断是否结束
# 遍历新老聚类中心是否相等,发现不相等的第一时间返回FALSE
for i in range(len(zs)):
for j in range(len(zs[i])):
if math.fabs(float(zs[i][j]) - new_zs[i][j]) > 0.000000000000001: # 浮点数比较大小不可以直接用'='号或者'is'
return False
return True
def get_newcluster(result):
# 计算新的聚类中心向量值
zs = []
for aResult in result:
z = []
for i in range(len(aResult[0])):
mean = 0
for a in aResult:
mean += a[i]
mean /= float(len(aResult))
z.append(mean)
zs.append(z)
return zs
def classify(data, zs):
# 按最小距离原则分类
result = [[] for i in range(len(zs))]
for aData in data:
min_distance = get_distance(aData, zs[0])
index = 0
for i in range(len(zs)):
distance = get_distance(aData, zs[i])
if distance < min_distance:
min_distance = distance
index = i
result[index].append(aData)
return result
# 测试k_means_cluster
# data = [[0, 0], [1, 0], [0, 1], [1, 1], [2, 1], [1, 2], [2, 2], [3, 2], [6, 6], [7, 6], [8, 6], [6, 7], [7, 7],
# [8, 7], [9, 7], [7, 8], [8, 8], [9, 8], [8, 9], [9, 9]]
# k = 2
# result = k_means_cluster(data, k)
# for i in range(len(result)):
# print "----------第" + str(i+1) + "个聚类----------"
# print result[i]
# 打印结果:
# ----------第1个聚类----------
# [[0, 0], [1, 0], [0, 1], [1, 1], [2, 1], [1, 2], [2, 2], [3, 2]]
# ----------第2个聚类----------
# [[6, 6], [7, 6], [8, 6], [6, 7], [7, 7], [8, 7], [9, 7], [7, 8], [8, 8], [9, 8], [8, 9], [9, 9]]
注:
- 在算法实现过程中,遇到了一个递归函数返回值的问题,具体体现在step2()中,详情请参看Python :递归函数返回值为None的解决办法。
最后:
本文简单的介绍了 聚类算法——K-均值算法 中的相关内容,以及相应的代码实现,如果有错误的或者可以改进的地方,欢迎大家指出。
代码地址:聚类算法——K-均值算法(码云)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









