






点击蓝字关注我们
关注、星标公众号,精彩内容每日送达
来源:网络素材本实验文档为哈尔滨工业大学(深圳)《深度学习体系结构》2021年秋季课程的实验指导材料。
原文档地址 :
https://hitsz-cslab.gitee.io/dla
示例工程地址 :
https://gitee.com/hitsz-cslab/dla
实验1:神经网络加速器设计入门
实验目的
1. 了解使用硬件加速神经网络前向推导的基本原理,以及硬件加速器设计的基本方法;
2. 掌握利用HLS设计硬件IP核的基本流程和基本方法;
3. 了解ZYNQ异构平台的基本架构,熟悉PYNQ开发板的系统架构及其使用方法。
实验内容
1. 在Vivado HLS中,使用C/C++实现卷积操作,进行仿真、调试、综合并导出IP核;
2. 在Vivado中,利用导出的IP核构建Block Design,生成比特流并下板;
3. 运行实验包的Jupyter Notebook测试程序,并通过阅读代码,分析软件如何调用硬件IP核。
实验原理
1. 概述
1.1 背景简介
近年来,随着人工智能、大数据等技术的不断发展,应用需求也逐渐变得多种多样。在技术发展趋势和各种应用需求的驱动下,人们对移动端设备或嵌入式设备的智能化期望越来越高。在云计算的背景下,移动端设备和嵌入式设备通常合称为端设备,与“云”的概念相对应。端设备数量庞大,产生的数据极多。因此,若想单纯依靠传统云计算来实现端设备的智能化,则云与端之间的网络带宽必定成为系统的性能瓶颈。为了解决这个问题,需要 将云端的一部分计算任务下放到端设备,以减轻云端和网络带宽的压力。然而端设备大多采用嵌入式处理器 —— 嵌入式处理器受到功耗、体积、散热等多方客观因素的限制,其性能远不如桌面平台。为了提高端设备的性能,同时保证其满足原有的功耗、体积、散热等需求,可以利用FPGA、ASIC等 低功耗、高能效 的器件,为相应的应用场景定制该领域所专用的加速器。
1.2 神经网络简介
神经网络一般包含 输入层、中间层 和 输出层。输入层获取神经网络的外部输入数据,其结构取决于输入数据的维度。中间层又称隐藏层,负责对输入数据进行特征提取和分析,从而产生相应的特征图。输出层接收中间层的特征图作为输入,并输出神经网络的最终计算结果,其结构根据应用场景而有所不同。
使用神经网络解决实际问题时,首先要对应用场景进行需求分析,确定需要使用哪一种类型的神经网络。然后,结合实际应用的特点,搭建神经网络的初步结构。接下来,需要通过具备一定规模的数据集对所搭建的网络进行训练,得到网络中各个层各个节点的参数。必要时需要根据训练后的测试结果对神经网络的结构进行合理的调整以完成神经网络的迭代和优化。当神经网络的性能达到预期后,可将其部署到实际应用场景中,进行前向推导。神经网络的前向推导指的是网络接收外部数据,并在经过网络内部的运算后,产生特定结果的过程。
1.3 加速器设计方法概述
神经网络硬件加速器的设计通常遵循如图1-1所示的基本流程。
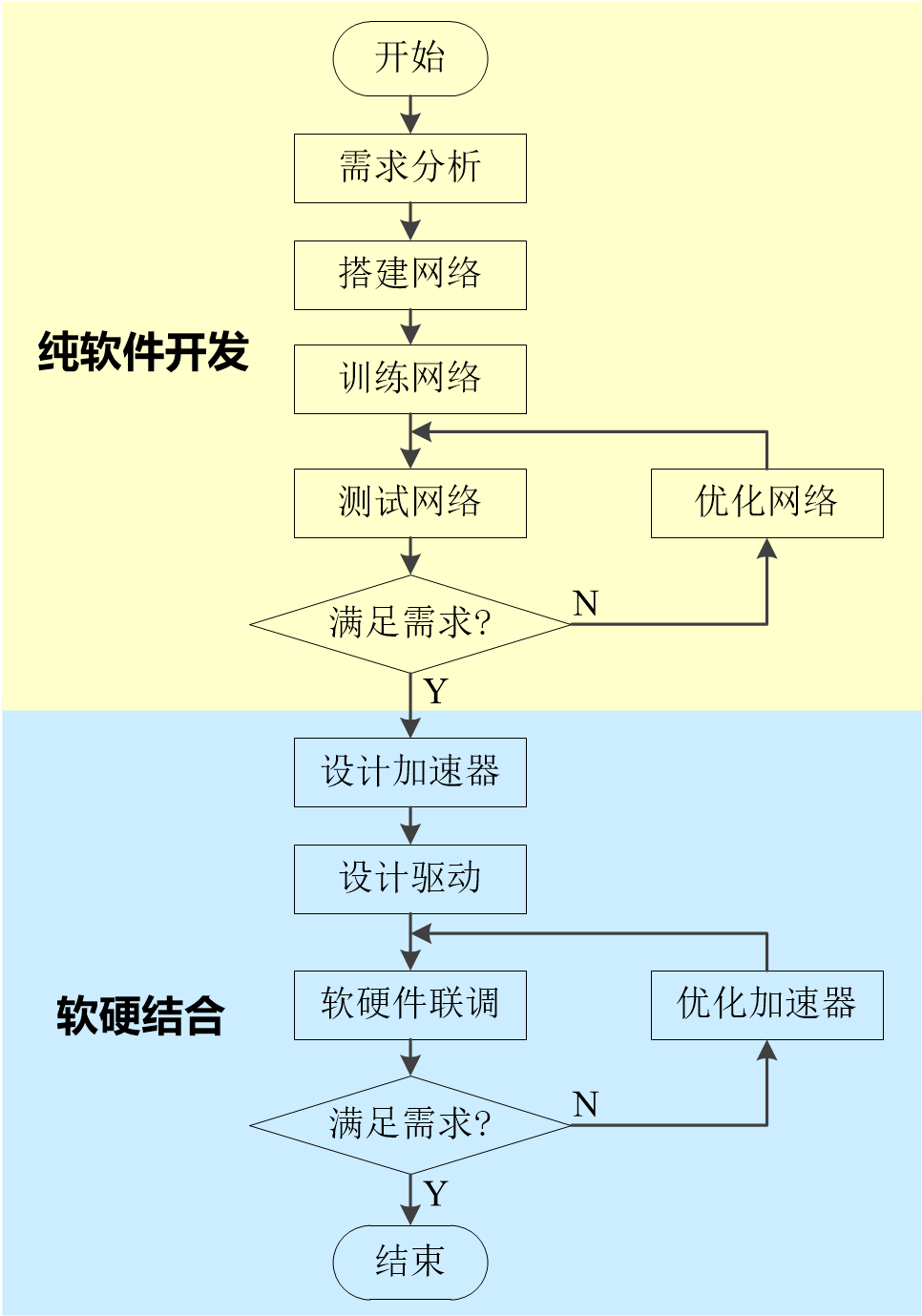 图1-1 AI加速器设计流程
图1-1 AI加速器设计流程
一般地,硬件加速器的设计可采用完全硬件化和部分硬件化2种设计方法。
完全硬件化 的设计方法需要根据网络结构,使用HDL(Hardware Description Language)或HLS(High-Level Synthesis)实现神经网络的每一个层。该方法的优点是硬件化程度高,可实现网络层次的流水线,并且能够获得很高的加速效果,但显然存在开发难度大、开发周期长、硬件资源消耗较多以及通用性差的缺点。
部分硬件化 的设计方法首先从神经网络的运算类型出发进行考虑,通过分析和必要的测试,得出神经网络内部各类运算的占比,然后有针对性地选择占比较大的运算进行加速;对于占比较小的运算,则仍然使用软件实现。部分硬件化设计方法的理论依据是Amdahl定律。该方法具有开发难度较低、开发周期较短、硬件资源消耗较少的优点,同时还能够使加速器具有一定的通用性和灵活性,并且在某些情形下能够获得与完全硬件化方法相近的性能。
本课程实验对上述2种设计方法均有所涉及。在实际应用场合中,同学们需要根据具体需求,自行选择合适的设计方法。
2. PYNQ简述
本课程实验将采用PYNQ-Z2实验平台。PYNQ是Xilinx公司基于ZYNQ平台推出的开源项目,旨在降低开发者(特别是软件开发者)使用异构平台的门槛。所谓异构,是指同一系统中存在功能相似而架构不同的组成部分,如现今流行的大小核处理器即可视为异构平台。开发者使用PYNQ,可以较为方便地实现 硬件加速算法、并行计算、高帧率视频处理、实时信号处理、低时延控制 等高性能应用。
2.1 ZYNQ简介
ZYNQ是Xilinx推出的全可编程片上系统(All-Programmable System-On-Chip,APSoC)。所谓片上系统/SoC指的是在一块芯片上集成一个相对完整的系统,通常包含 时钟、处理器、总线、存储、I/O 等等。
ZYNQ都是异构SoC,通常至少包含ARM CPU和FPGA资源,高端ZYNQ甚至还包含GPU,如Mali-400系列的嵌入式GPU。所谓异构SoC,是指SoC内部包含多个处理核,且这些处理核的架构互不相同。ZYNQ的典型架构可简化为如图1-2所示。
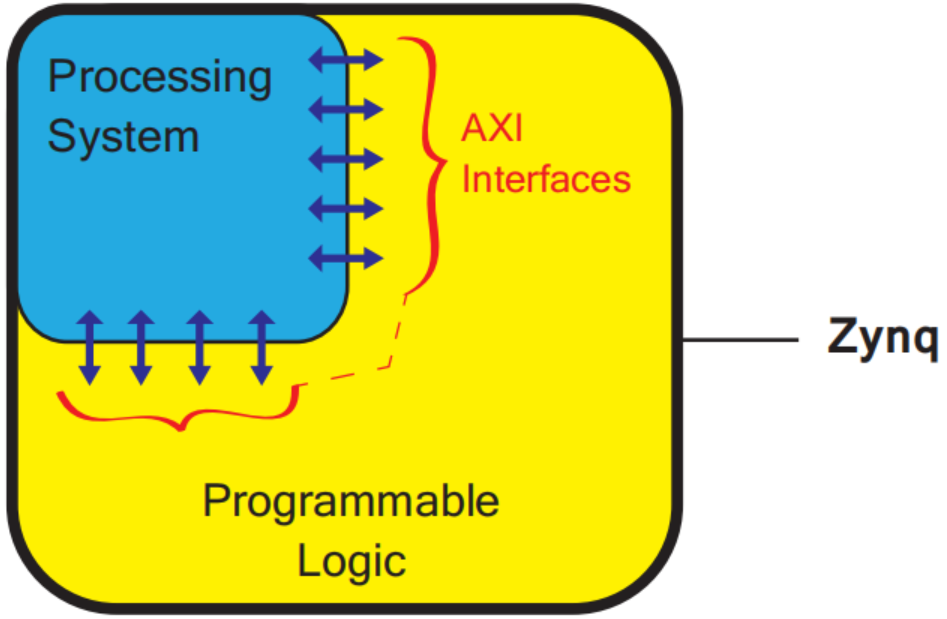 图1-2 ZYNQ架构简图
图1-2 ZYNQ架构简图
由图1-2可知,ZYNQ主要包含 PS(Processing System, 处理系统)和 PL(Programmable Logic, 可编程逻辑)两大部分。PS通常使用ARM Cortex系列的嵌入式CPU,一般采用同构多核CPU,高端芯片则可能采用异构大小核处理器。PL则一般指FPGA的可编程逻辑资源。此外,PS和PL通过 AXI总线 进行数据和控制信号的交互。
2.2 PYNQ架构浅析
PYNQ官网给出了如图1-3所示的PYNQ软硬件架构图。
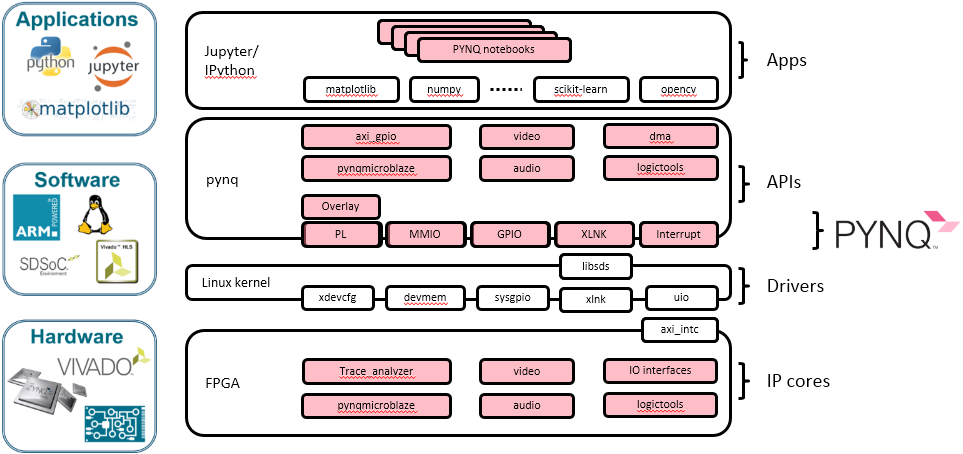 图1-3 PYNQ架构图
图1-3 PYNQ架构图
与一般的计算机系统类似,PYNQ的系统架构可粗分为3个层次:硬件层、系统软件层和应用层。硬件层即是ZYNQ,主要包括PS和PL两部分。系统软件层包括FSBL(First Stage BootLoader)、U-Boot、嵌入式Linux、设备驱动程序等等。应用层则包括Python开发环境、Jupyter Notebook等应用软件。
本课程实验的Xilinx PYNQ-Z2开发板,其PS采用的是双核的ARM Cortex-A9处理器,主芯片型号为xc7z020clg400-1。
可将图1-3所示的架构简化成如图1-4所示的架构。
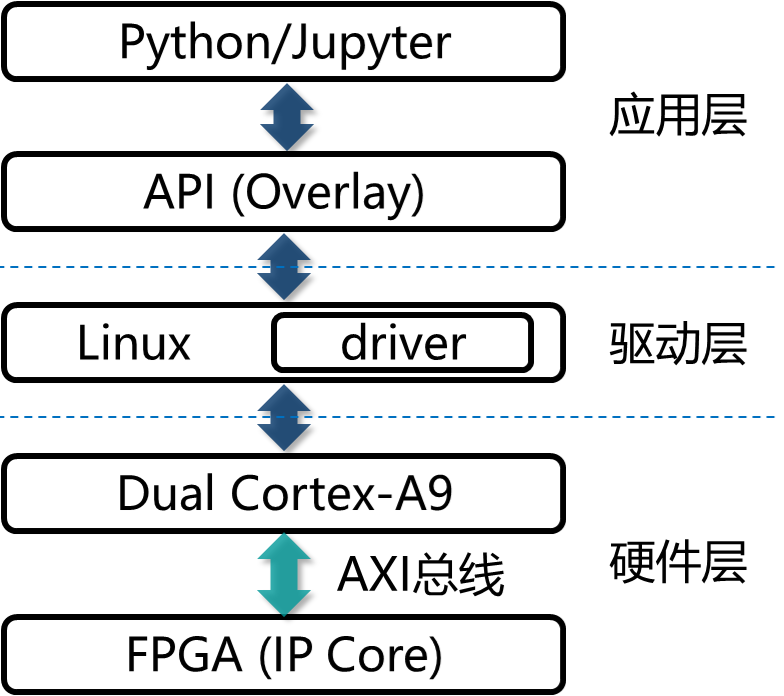 图1-4 PYNQ架构简图
图1-4 PYNQ架构简图
应用层想要读写硬件数据时,需要调用特定的API。API将应用层的读写请求和参数传递给驱动层。驱动层解析应用层的读写请求,并通过特定的接口读写硬件IP核的数据。驱动层的读写程序最终被编译器和汇编器转换成了指令序列在CPU中执行。CPU通过指令的译码和执行,向特定地址的接口发出数据读/写请求,此时,应用层的读写请求已转换成硬件层面的读写信号。读写信号通过AXI总线传递到FPGA上的IP核。IP核根据总线读/写逻辑,读取硬件的数据或将收到的数据写入到特定的存储器中。
更多PYNQ资料,请查看官方文档:https://pynq.readthedocs.io/en/v2.5/index.html。
3. 高层次综合(HLS)
传统FPGA开发使用HDL(Hardware Description Language)进行,如Verilog、VHDL。HDL可将代码编译成片上设计,这种设计方法在上世纪80年代开始得到广泛使用。随着硬件电路复杂度的指数性增长,硬件工程师们不断寻求更便捷高效的硬件开发语言和工具。由此,HLS(High-Level Synthesis)应运而生。
使用HLS设计电路时,更多地需要考虑电路的整体架构而非某个单独的部件。最早大多数HLS工具是基于Verilog的,用户需要使用Verilog描述电路,工具也通过Verilog产生RTL。现今很多HLS工具开始支持使用C/C++等高级语言来完成硬件电路设计。
HLS可自动完成以下曾经需要手动完成的工作:
自动分析并利用一个算法中潜在的并行性
自动在需要的路径上插入寄存器,并自动选择最理想的时钟
自动产生控制数据在一个路径上输入/输出方向的逻辑
自动完成设计中各子模块之间的接口
自动映射数据到存储单元以平衡资源使用量和带宽
自动将程序中的计算部分对应到逻辑单位,在实现等效计算时自动选取最有效的实现方式
3.1 HLS与电路的对应关系
一般地,软件程序中的函数最终会综合成为相应的电路模块实体,而程序中的控制流和数据流则由HLS工具中的调度和绑定程序(Scheduling and Binding Processes)映射到硬件电路当中。具体的软件成分与硬件组成之间的对应关系如表1-1所示。
表1-1 软硬件映射关系(以C语言为例)| 软件成分 | 对应的硬件组成 |
|---|---|
| 函数 | 模块 |
| 函数的参数 | 模块的输入/输出端口 |
| 操作符 | 功能单元 |
| 变量 | 线网(wire)或寄存器(reg) |
| 数组 | 存储器 |
| 控制流 | 控制逻辑 |
举个栗子
程序中的函数通常会被综合成单独的电路模块,如图1-5所示。
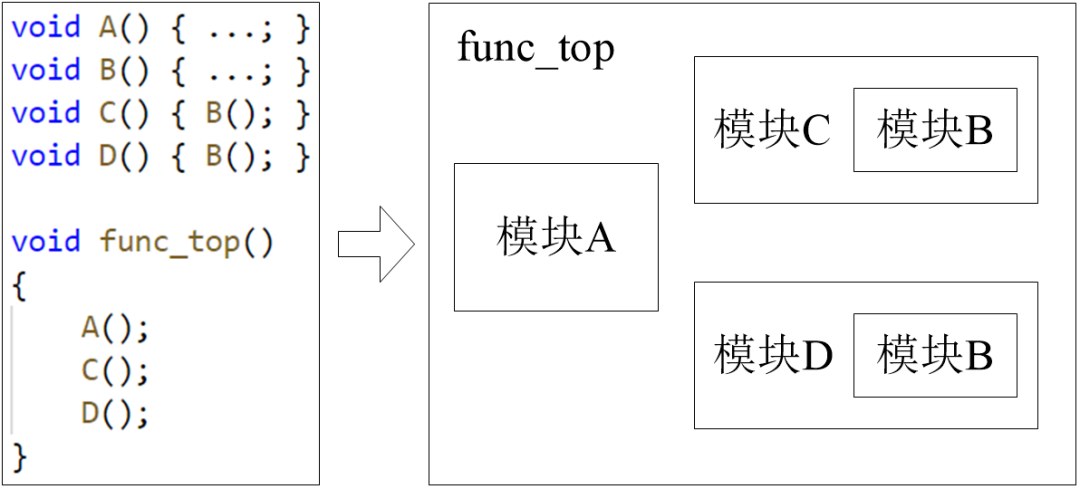 图1-5 函数将被综合成module
图1-5 函数将被综合成module
需要注意的是,在图1-5中函数B被调用了2次。如果在运行时,这2处调用不会同时执行,那么HLS工具将为函数B生成一个 运行时可重用 的电路模块实例;否则,将生成2个电路模块实例。
类似地,函数的参数将被综合成模块的输入/输出端口,如图1-6所示。
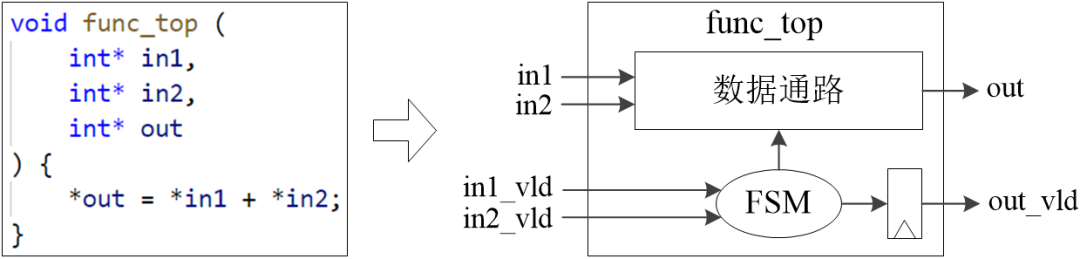 图1-6 函数参数将被综合成module的I/O Ports
图1-6 函数参数将被综合成module的I/O Ports
由图1-6可知,除了参数本身,HLS工具还将额外生成必要的辅助信号。
3.2 HLS的设计规范
虽然HLS可将高级语言描述的程序转换成硬件电路,但HLS并没有强大到可以处理任何代码。许多在软件编程中常用的概念在硬件中很难实现,所以有时需要将HLS与HDL结合,从而使得设计更加灵活。
HLS工具通常需要用户提供附加信息(通过suggestion或#pragma)来帮助完善程序,因此我们说HLS工具会同时"限制"又"加强"了一门语言。例如,HLS一般无法进行动态内存分配,且大部分HLS工具对标准库的支持也非常有限;此外,使用HLS编程时,应当避免使用系统调用和递归语句,以尽量降低程序的复杂程度。除去这些设计限制,HLS的处理范围非常广(包括DMA,数据流,Scratchpad Memory等),优化效率也较高。
一般地,使用HLS设计开发硬件电路时,应遵循的规范如下:
不使用动态内存分配,如malloc()、free()、new和delete等
不使用系统调用,如abort()、exit()、printf()等(可在测试代码中使用系统调用,但在需要综合的代码中,系统调用将被自动忽略或删除)
不使用递归语句
减少使用指针对指针的操作
减少使用标准库函数(HLS支持math.h中的常用函数,但仍存在不兼容)
减少使用C++中的函数指针和虚函数
3.3 HLS设计IP核的流程
使用HLS设计硬件IP核的流程如图1-50所示。
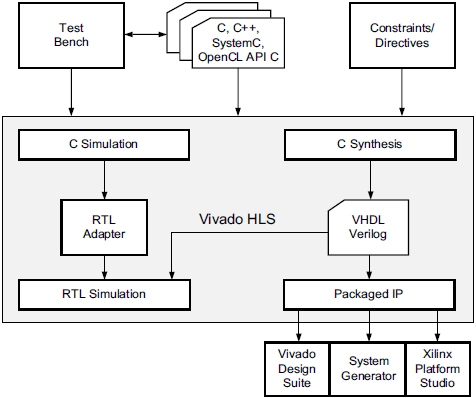 图1-50 HLS设计流程
图1-50 HLS设计流程
由图1-50可知,HLS设计硬件IP核的步骤为:
1)使用C/C++、System C等高级语言实现目标算法,并编写Test Bench以验证和调试代码;
2)通过C Synthesis工具,将算法综合成VHDL或Verilog描述的硬件电路。此时,可进行C和
RTL的联合仿真调试;
3)将通过功能验证的RTL打包成硬件IP核;
4)在Vivado中导入IP核、构建Block Design、生成比特流并进行下板验证。
加州大学圣地亚哥分校(UCSD)的CSE 237C课程里有很多基于HLS开发的项目,比如cordic、DFT、FFT、FIR、histogram、huffman、matrixm、sort、spmv、sum和vs等经典的算法。感兴趣的同学可以自行从Github下载源码学习。
更多HLS资料,请参考《Parallel Programming for FPGAs》。
实验步骤
利用HLS设计加速系统包括3个阶段:
1. 利用HLS生成IP核;
2. 创建Block Design;
3. 系统的软硬件联调。
1. 利用HLS生成IP核
1.1 创建Vivado HLS项目
在桌面双击Vivado HLS快捷方式,或在开始菜单->Xilinx Design Tools->Vivado HLS打开Vivado HLS工具。点击“Quick Start”下方的“Create New Project”,或点击菜单栏中的File->New Project。然后,填写项目名称,并选择项目所在的路径,如图2-1所示。
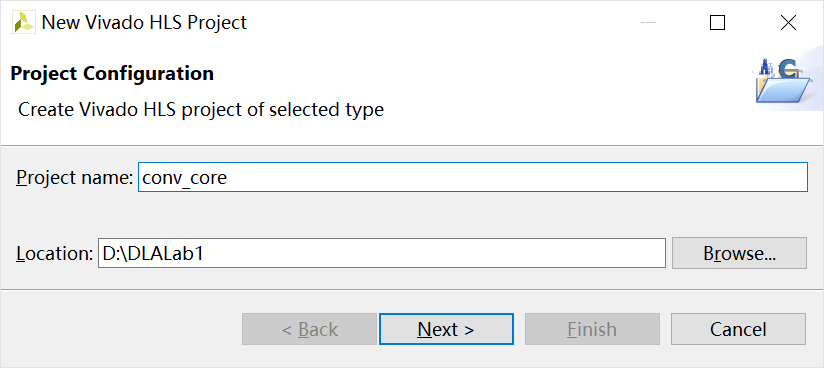 图2-1 创建Vivado HLS项目
图2-1 创建Vivado HLS项目
点击Next,进入源文件添加窗口。在Top Function一栏内填写conv_core,作为顶层函数名,如图2-2所示。
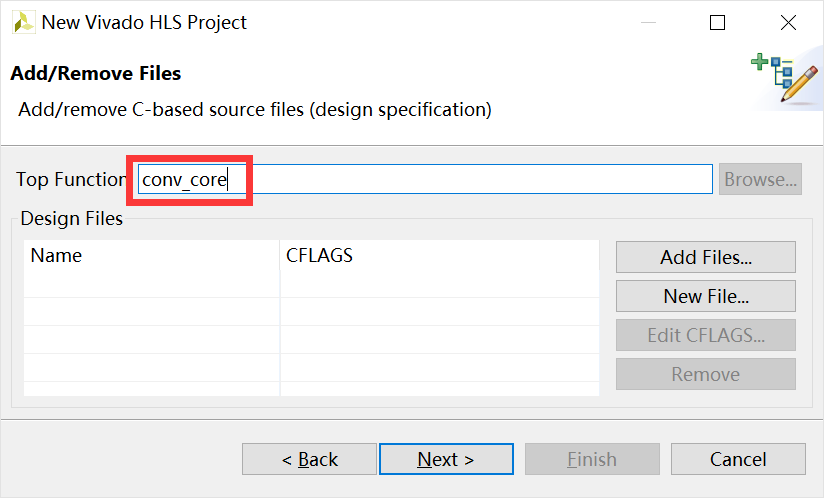 图2-2 填写Top Function名
图2-2 填写Top Function名
点击Next,进入Test Bench的测试源文件添加窗口。此时暂不添加,继续点击Next,进入项目配置窗口。点击Part Selection线框内部的“…”按钮,打开器件选择窗口,输入xc7z020clg400-1,然后点击“OK”按钮,如图2-3所示。
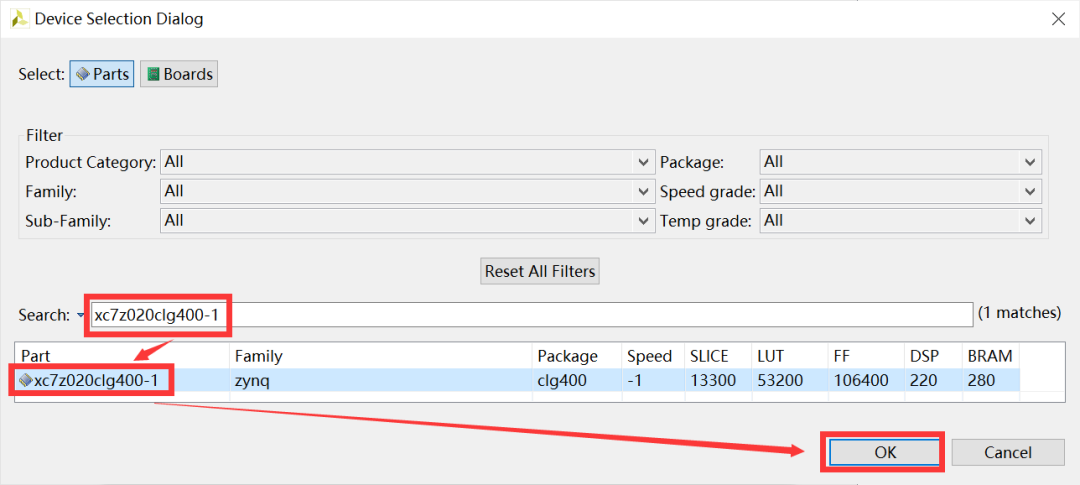 图2-3 选择器件
图2-3 选择器件
点击“Finish”按钮,完成项目的创建,进入主界面,如图2-4所示。
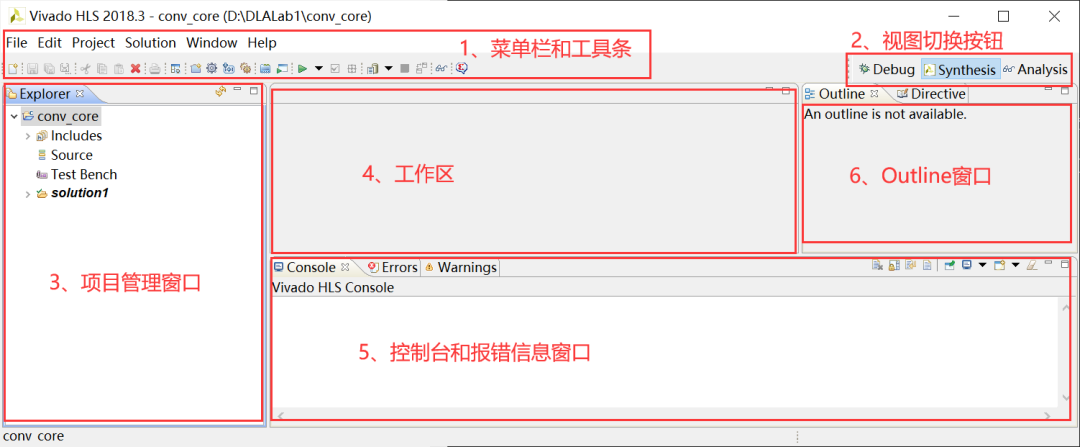 图2-4 Vivado HLS主界面
图2-4 Vivado HLS主界面
Vivado HLS主界面主要包括6个部分:1)菜单栏和工具条。菜单栏和普通的IDE差不多,尤其接近Eclipse,这是因为Vivado HLS就是基于Eclipse开发的。工具栏包含了常用的功能按钮,如综合、仿真、打包IP核等。2)视图切换按钮,用于在Debug、综合和分析3个视图之间切换。3)项目管理窗口,用于管理项目源文件、测试源文件、IP核压缩包等文件。4)工作区:用于编辑源码和调试。5)控制台和报错信息窗口:用于查看报错信息和串口输出等。6)Outline窗口:用于显示项目相关的信息,包括顶层函数输入输出变量所对应的硬件模块的接口信号总线协议等。
1.2 添加源文件
将所提供的conv_core.cpp、conv_core.h和main.cpp三个源文件拷贝至工程目录下(D:\DLAlab1\conv_core)。然后在项目管理窗口的Source图标处右键,选择Add File,选择刚才拷贝的除main.cpp之外的源文件,如图2-5所示。
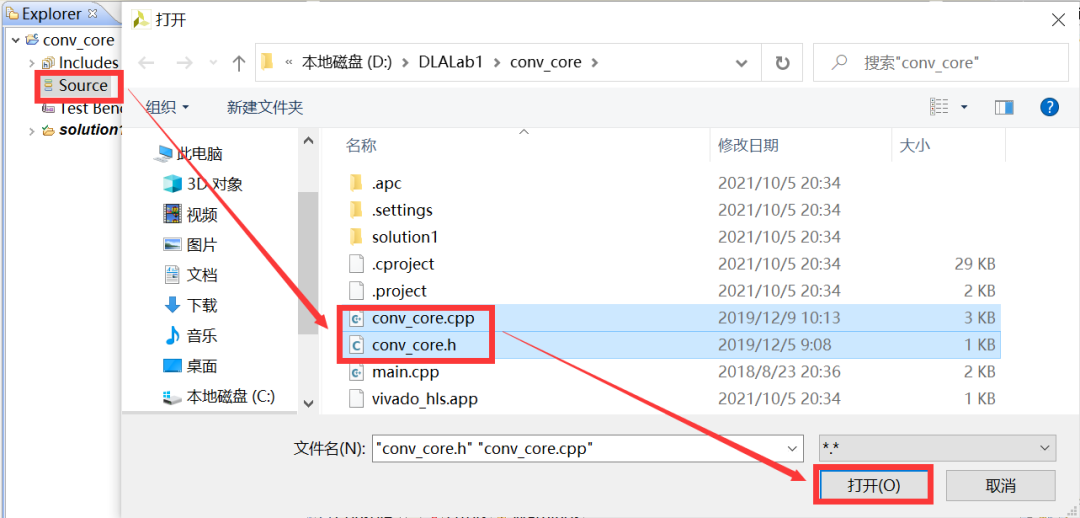 图2-5 添加源文件
图2-5 添加源文件
双击Source下的源文件。可编辑其代码,如图2-6所示。
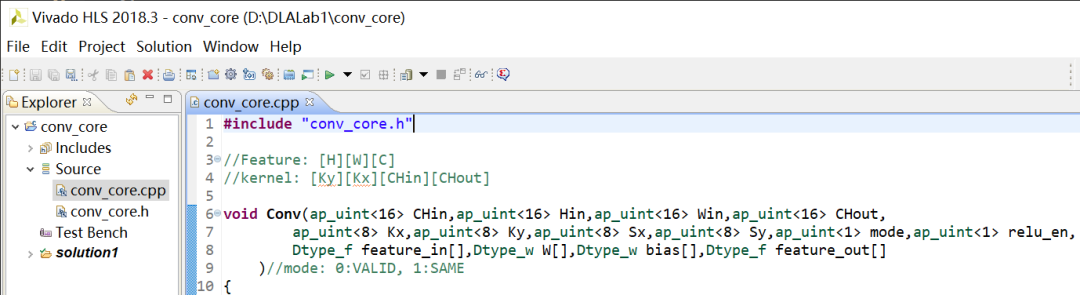 图2-6 查看或编辑源代码
图2-6 查看或编辑源代码
类似地,在Test Bench图标处右键添加main.cpp,如图2-7所示。
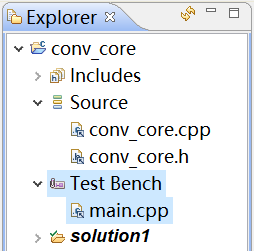 图2-7 添加测试源文件
图2-7 添加测试源文件
1.3 C代码仿真/CSIM
点击Project->Run C Simulation或工具条中的CSim按钮,如图2-8所示。
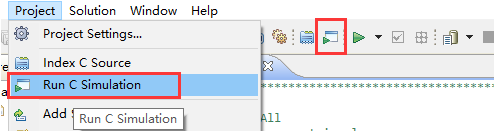 图2-8 点击进行CSim
图2-8 点击进行CSim
点击CSim后,直接在弹出的窗口中点击“OK”按钮以开始C语言仿真。CSim是纯软件的仿真,仅用于验证代码功能的正确性。
CSim完毕后,工作区将弹出一个名为conv_core_csim.log的CSim日志文件以便查看仿真结果,也可在控制台窗口查看源码的编译过程及相应的测试结果,如图2-9所示。
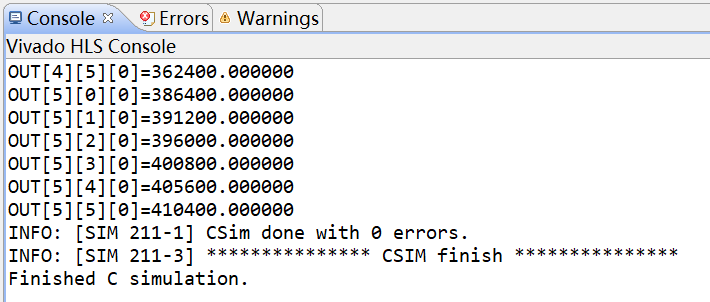 图2-9 查看CSim结果
图2-9 查看CSim结果
1.4 C代码调试
如果CSim时不能通过测试,则需要对代码进行debug。Vivado HLS工具的调试方法和Eclipse基本一致。
点击CSim按钮,在弹出的窗口中勾选Launch Debugger,如图2-10所示。
 图2-10 开始debug
图2-10 开始debug
点击“OK”按钮,将自动进入跟Eclipse一样的Debug视图。可在代码行数的左侧空白处双击以添加断点,如图2-11所示。
 图2-11 添加断点
图2-11 添加断点
点击工具条中的Step Into(F5)或Step Over(F6)按钮,开始debug。此时,可在右上方的Variable窗口查看变量的值,如图2-12所示。
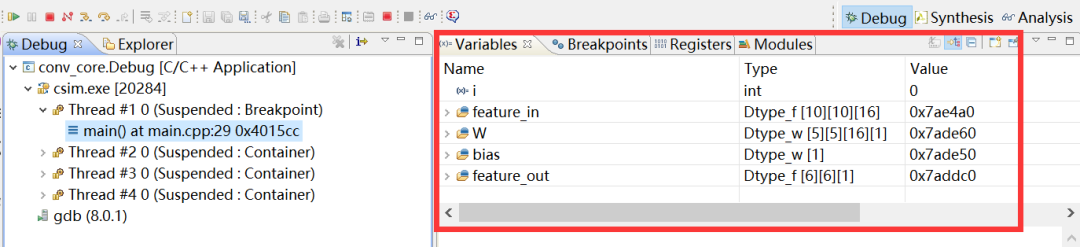 图2-12 debug时查看变量的值
图2-12 debug时查看变量的值
debug完成后,点击图2-12左上角形如红色正方形的按钮,或用快捷键Ctrl+F2结束调试。此时,再点击图2-12右上角的Synthesis按钮,回到图2-4所示的主界面/综合界面。
1.5 综合/Synthesis
综合前,需要为conv_core项目添加Directive/原语,以指定顶层模块所对应的硬件模块的IO信号所使用的总线协议、综合时所使用的并行优化策略(如流水线、循环展开)等。
Directive的添加有2种方法。第一种方法是通过图形化界面添加。添加时,需要在Outline窗口处点击打开Directive标签页,并在相应的函数上右键添加Directive,如图2-13所示。
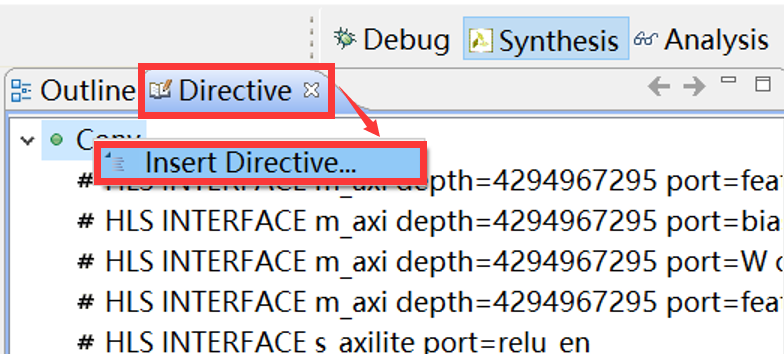 图2-13 用图形化界面添加Directive
图2-13 用图形化界面添加Directive
第二种方法是直接在代码中插入形如#pragma HLS xxx的制导语句,如图2-14所示。
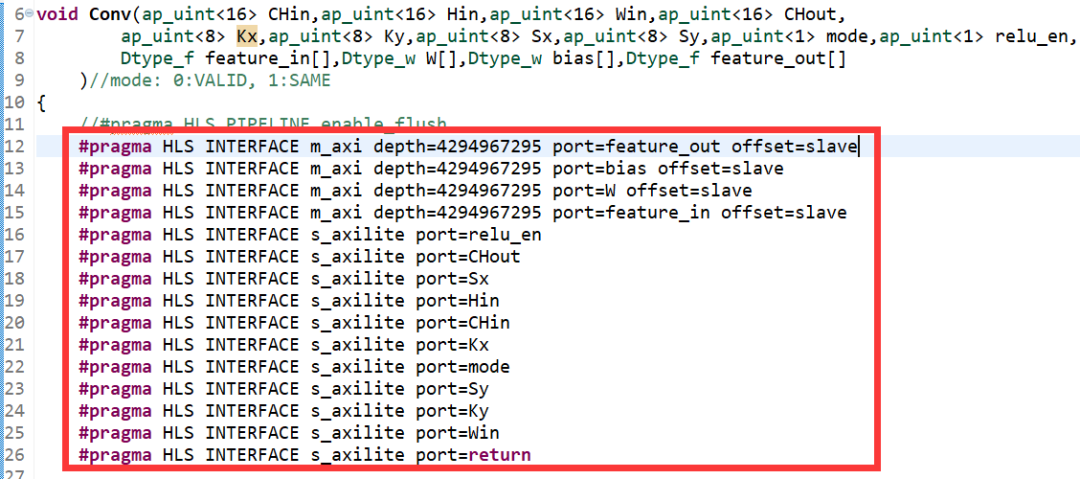 图2-14 直接在代码中添加Directive
图2-14 直接在代码中添加Directive
小提示
在图2-14中,每一个制导语句都指定了一个端口的总线类型、主从属性以及允许的最大数据深度等信息。例如,第一行指定了feature_out将作为AXI总线的从端口,且最大深度为4294967295。
接着,可用同样的方法设置并行优化策略。
补充说明
此处暂不添加优化语句。在后续的实验中,将会再讲解如何优化。
Directive设置完毕,接下来需要对C代码进行综合,以生成RTL电路。
点击Project->Project Settings->Synthesis,点击Top Function右边的Browse,选择conv_core作为Top Function,点击“OK”按钮,如图2-15所示。
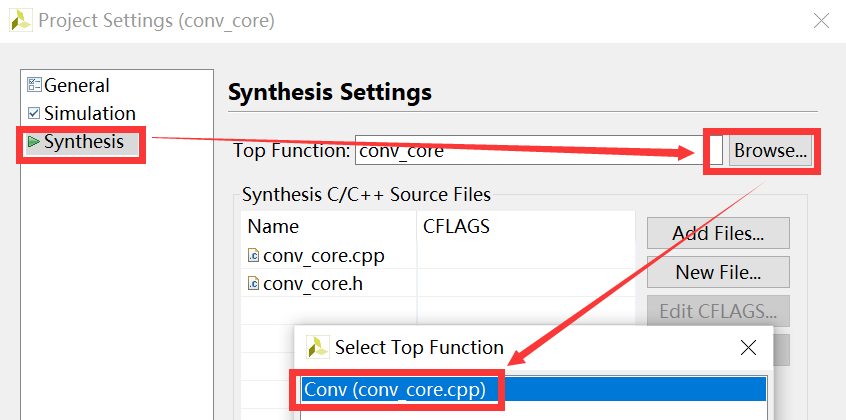 图2-15 选择Top Function
图2-15 选择Top Function
点击菜单栏的Solution->Run C Synthesis->Active Solution,或点击工具栏中形如绿色三角形的综合按钮,如图2-16所示。
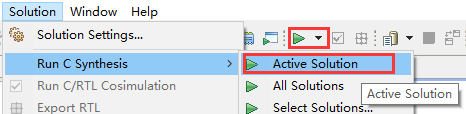 图2-16 点击以进行综合
图2-16 点击以进行综合
综合完成后会自动显示综合报告。报告中包含了预估性能、预估资源情况、电路时延、模块接口等信息,如图2-17所示。
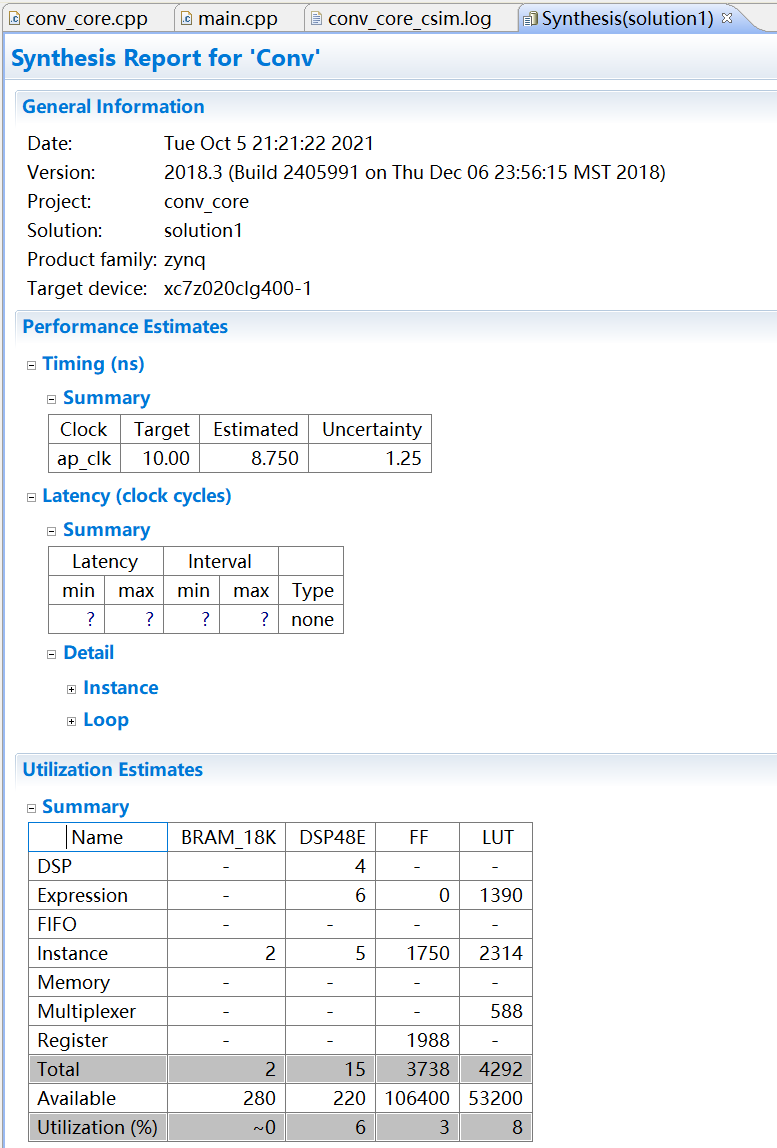 图2-17 综合报告
图2-17 综合报告
1.6 C/RTL协同仿真
运行C/RTL Co-Sim时,会调用HDL仿真工具。
点击Solution->Run C/RTL Cosimluation,或点击工具条中形如对号的按钮,如图2-18所示。
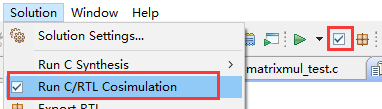 图2-18 点击进行C/RTL联合仿真
图2-18 点击进行C/RTL联合仿真
在弹出的窗口中选中仿真工具为Vivado Simulator,语言选中Verilog,Dump Trace选择all,如图2-19所示。
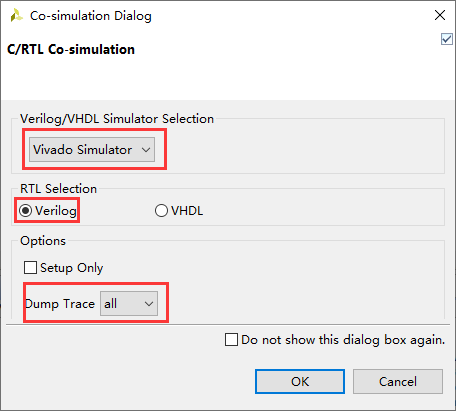 图2-19 联合仿真设置
图2-19 联合仿真设置
仿真报告显示了仿真的结果以及时延等信息,如图2-20所示。
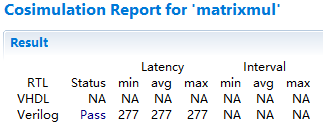 图2-20 联合仿真报告
图2-20 联合仿真报告
还可点击工具条中的波形按钮以查看波形,此时将打开Vivado的仿真波形界面,如图2-21所示。
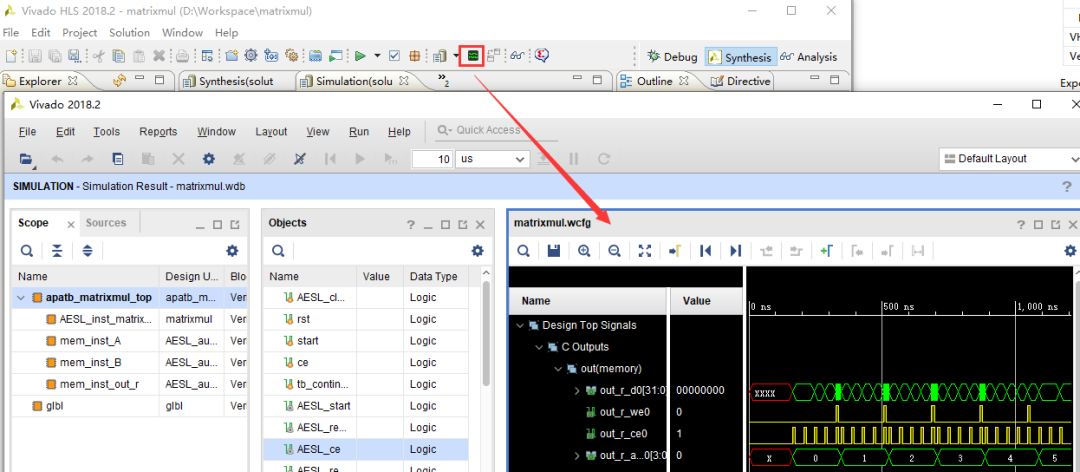 图2-21 查看仿真波形
图2-21 查看仿真波形
补充说明
对于本课程实验,可忽略C-RTL协同仿真的步骤。
1.7 导出RTL并打包成IP核/Export RTL
点击菜单栏的Solution->Export RTL,或点击工具条中形如棕色箱子的按钮,如图2-22所示。
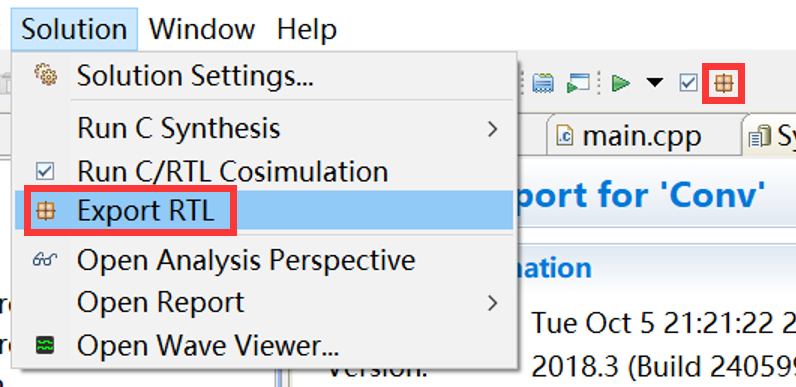 图2-22 点击以导出RTL
图2-22 点击以导出RTL
随后将弹出导出IP核的设置窗口,保持默认即可,点击“OK”按钮。
IP核导出成功后,可在主界面/综合界面左侧的工程目录Solution1->impl->ip中找到.zip格式的IP核,如图2-23所示。
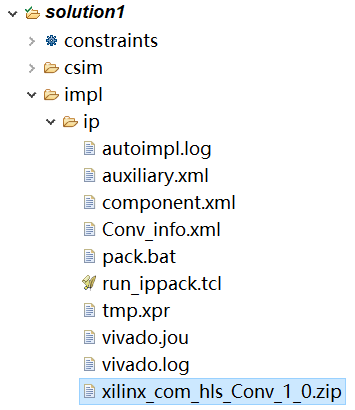 图2-23 查看导出的IP核
图2-23 查看导出的IP核
2. 创建Block Design
2.1 创建Vivado项目
在桌面双击Vivado快捷方式,或在开始菜单->Xilinx Design Tools->Vivado打开Vivado工具。点击“Quick Start”下方的“Create Project”,或点击菜单栏中的File->Project->New。然后,填写项目名称,并选择项目所在的路径,如图2-27所示。
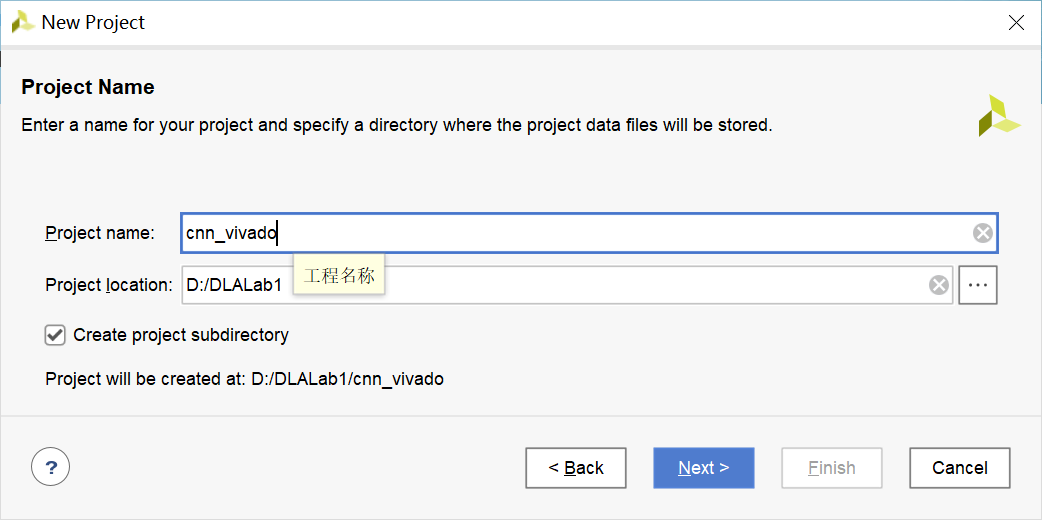 图2-27 创建Vivado项目
图2-27 创建Vivado项目
点击“Next”按钮,勾选“Do not specify sources at this time”,然后继续点击Next按钮。然后在搜索框中输入xc7z020clg400-1,如图2-28所示。
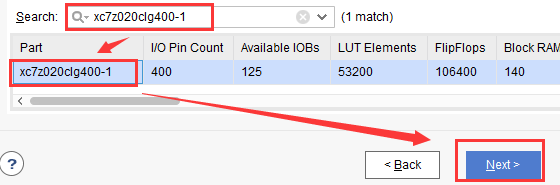 图2-28 输入PYNQ-Z2的器件型号
图2-28 输入PYNQ-Z2的器件型号
一直点击“Next”按钮,最后点击“Finish”按钮,完成Vivado工程的创建。
2.2 添加IP核
点击左侧Flow Navigator->Project Manager->Settings,在IP->Repository中直接添加上文的HLS工程路径,如图2-29所示。
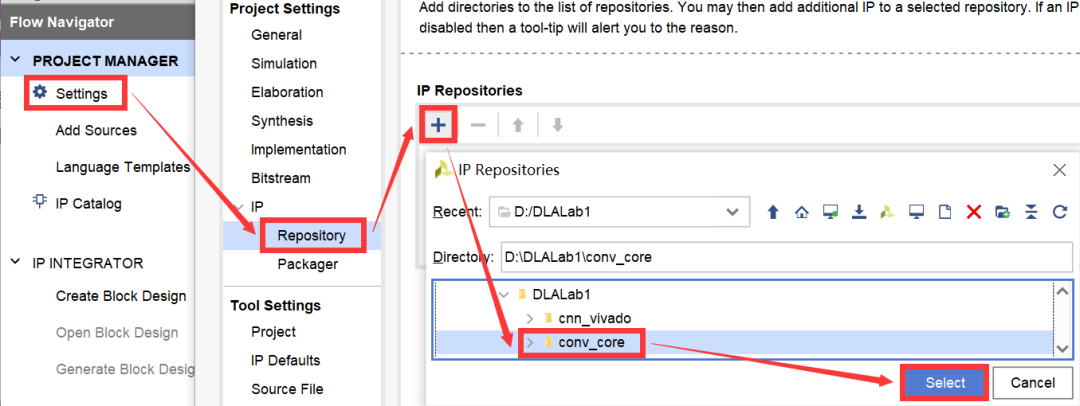 图2-29 添加IP核
图2-29 添加IP核
添加完成后,将弹出确认窗口。在该窗口中,可查看IP核,如图2-30所示。
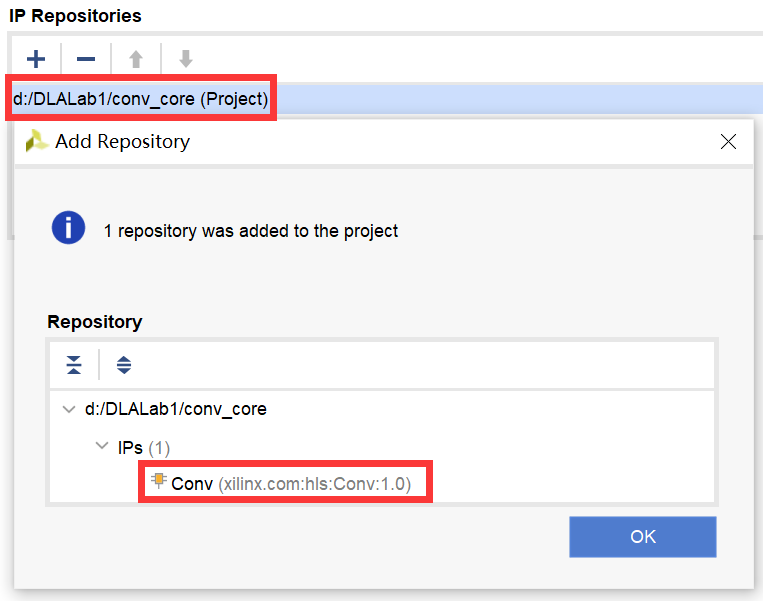 图2-30 添加成功后的窗口
图2-30 添加成功后的窗口
点击“OK”按钮,回到Vivado主界面。
将实验包中的pool_core_ip.zip池化IP核解压后,用类似的方法添加入工程。
2.3 搭建Block Design电路
点击IP Integrator->Create Block Design,并点击“OK”按钮以新建Block Design,如图2-31所示。
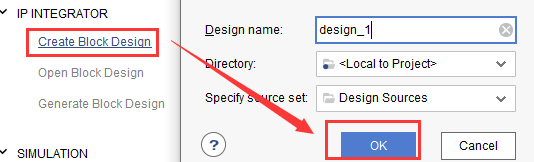 图2-31 新建Block Design
图2-31 新建Block Design
在右上方工作区中的Diagram内,点击加号添加ZYNQ IP核,然后点击Run Block Automation,如图2-32所示。
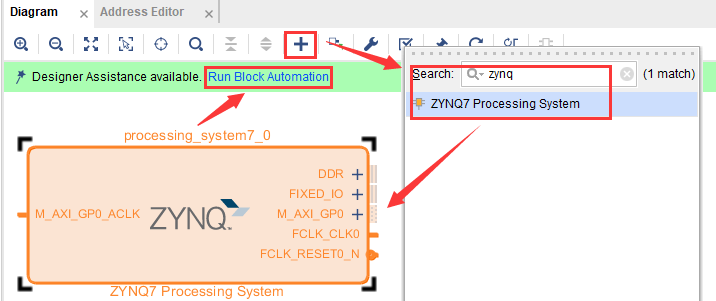 图2-32 添加ZYNQ IP核
图2-32 添加ZYNQ IP核
随后将弹出一个窗口,保持默认设置,点击“OK”按钮即可。
接下来,需要为ZYNQ的PS端添加相应的AXI总线接口,以连接卷积IP核和池化IP核。
双击ZYNQ IP核,为ZYNQ添加S_AXI_HP0、S_AXI_HP1两个高性能AXI从端的总线接口,如图2-33所示。
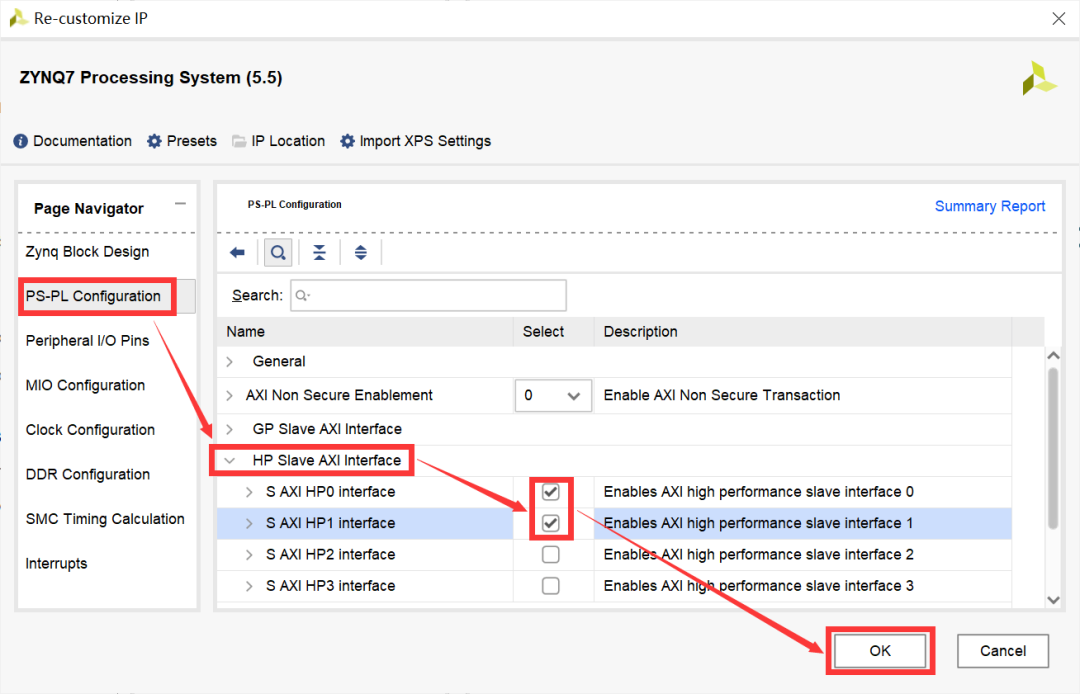 图2-33 为ZYNQ添加AXI总线接口
图2-33 为ZYNQ添加AXI总线接口
点击Diagram中的加号,添加矩阵乘法IP核,如图2-34所示。
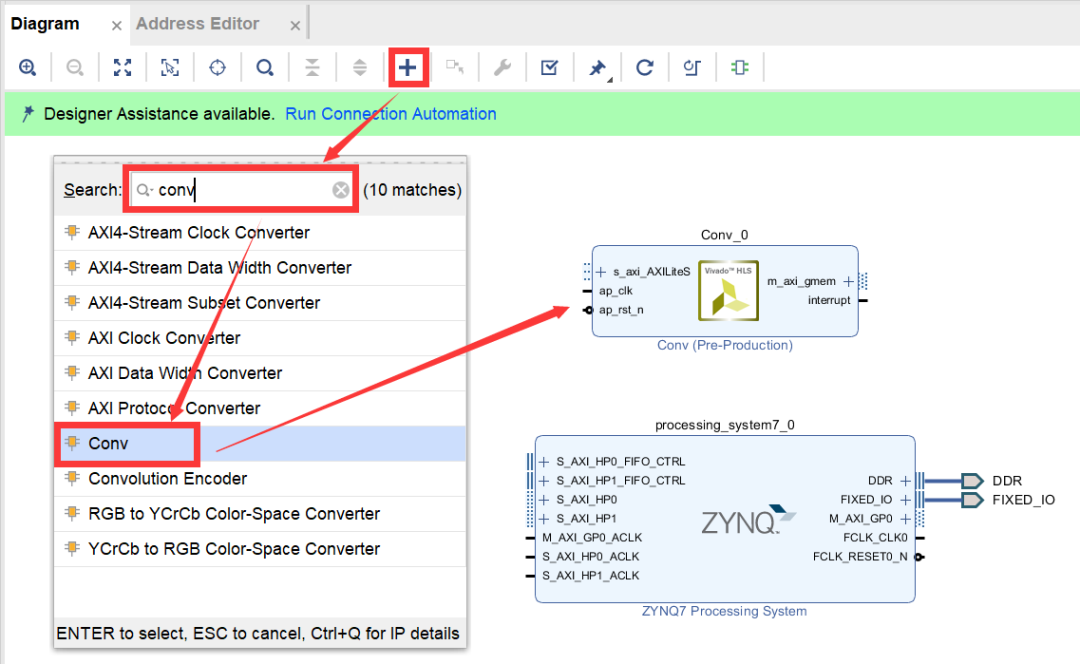 图2-34 添加卷积IP核
图2-34 添加卷积IP核
点击Run Connection Automation,并勾选除S_AXI_HP1以外的所有复选框,随后点击“OK”按钮,如图2-35所示。
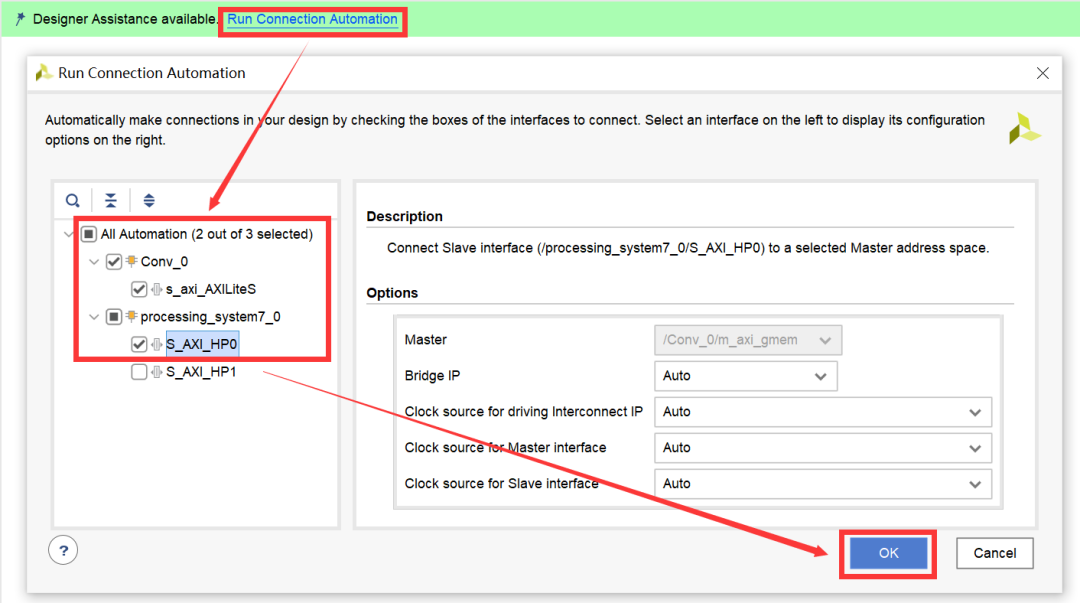 图2-35 自动连接ZYNQ IP核与卷积IP核
图2-35 自动连接ZYNQ IP核与卷积IP核
通常自动布线得到的电路模块图都较不美观,不利于观察和分析电路。可点击圆形箭头进行重新布线,如图2-36所示。
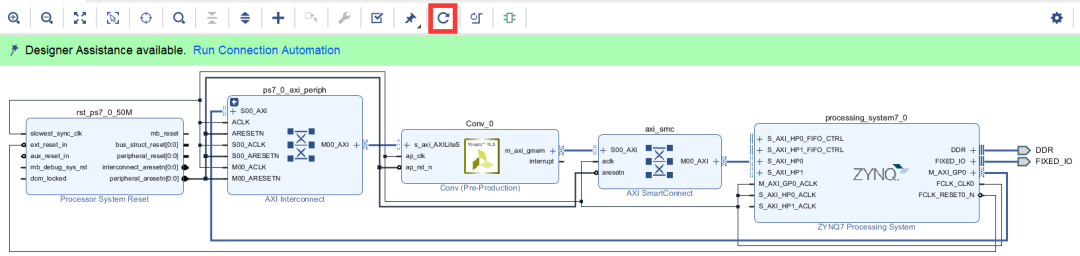 图2-36 重新布线
图2-36 重新布线
同样的,使用如图2-34所示的方法,在搜索框中输入pool,添加池化IP核。
然后,双击打开AXI InterconnectIP核的配置窗口,将其Master接口的数量从1改成2,如图2-37所示。
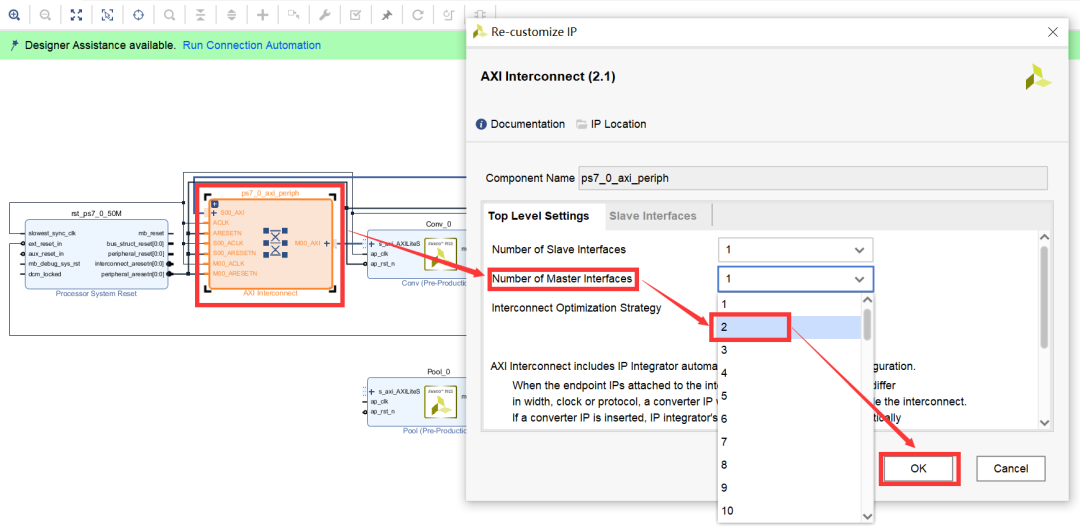 图2-37 增加AXI互联IP核的Master接口
图2-37 增加AXI互联IP核的Master接口
使用Ctrl+C和Ctrl+V快捷键,复制一个AXI SmartConnectIP核,并将AXI InterconnectIP核、池化IP核、新复制的AXI SmartConnectIP核与ZYNQ IP核的S_AXI_HP1接口进行连接,如图2-38所示。
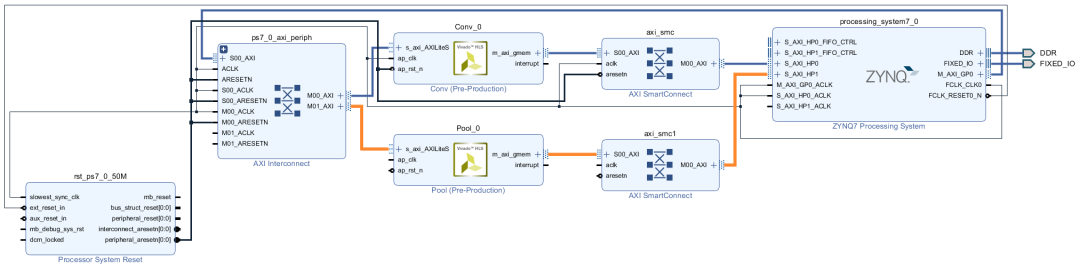 图2-38 连接池化IP核
图2-38 连接池化IP核
再次点击Run Connection Automation,并勾选所有复选框,完成剩余的电路连接。
注意
自动连接完毕后,如果发现axi_smc1IP核的复位信号悬空,则需要手动将其与axi_smcIP核的复位信号连接起来。
再次点击如图2-36所示的圆形箭头以重新布局,最终得到如图2-39所示的电路模块图。
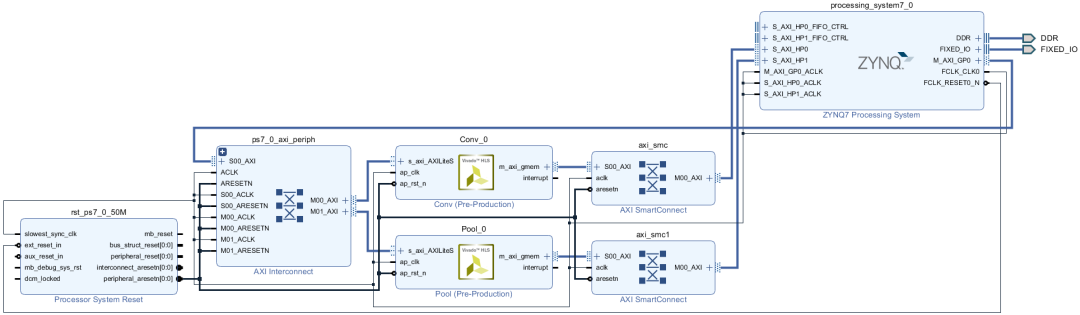 图2-39 本实验的CNN加速器电路模块图
图2-39 本实验的CNN加速器电路模块图
所有连接完成后,点击进入Diagram右侧的Address Editior标签页,并点击Auto Assign Address按钮,从而为IP核分配地址空间,如图2-40所示。
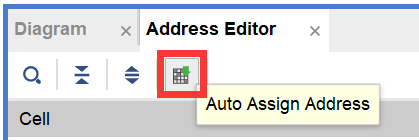 图2-40 分配地址空间
图2-40 分配地址空间
此时,将弹出对话框提示地址已经分配成功,点击OK按钮即可。分配完成后,Auto Assign Address按钮将变成灰色。
补充说明
若打开Address Editior标签页时,Auto Assign Address按钮已经是灰色,说明地址已自动分配完成。
点击回到Diagram标签页,点击Validate Design按钮,如图2-41所示。
 图2-41 检查Block Design是否有错误
图2-41 检查Block Design是否有错误
随后,Vivado将自动检查Block Design的正确性。若Block Design正确无误,将弹出对话框提示Validation successful。否则将显示Critical Warning或者Error信息,此时需要根据这些信息修正设计中的问题或错误。
Validation成功后,点击菜单栏的保存按钮,或用快捷键Ctrl+S保存Block Design。
2.4 生成比特流并导出Overlay
在源文件管理窗口中的Block Design文件上右键,点击Create HDL Wrapper,如图2-42所示。
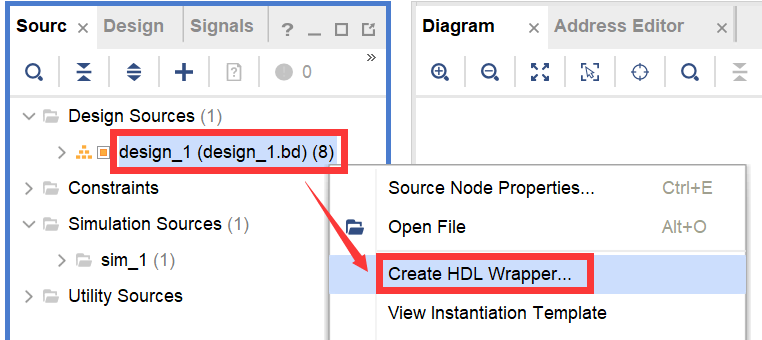 图2-42 为Block Design添加HDL顶层文件
图2-42 为Block Design添加HDL顶层文件
随后将弹出“Create HDL Wrapper”窗口,保持默认设置,然后点击“OK”按钮即可。
接下来,需要生成整个硬件设计的比特流文件。
点击菜单栏中的绿色箭头,生成比特流文件,如图2-43所示。如果希望加快比特流的生成速率,可以将“Number of jobs”设置为最大值。
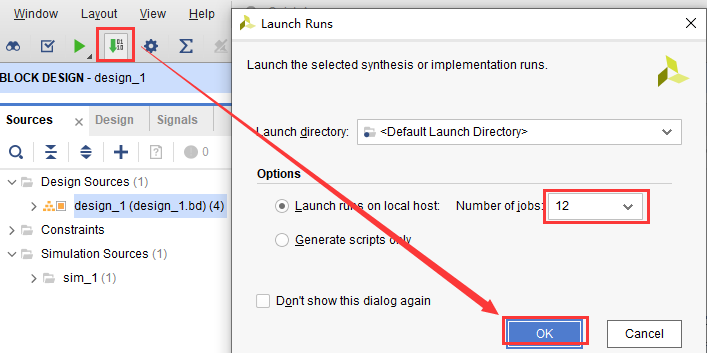 图2-43 生成比特流
图2-43 生成比特流
耐心等待比特流生成完毕,然后点击菜单栏的File->Export->Export Block Design,将Block Design导出到D:/DLALab1/cnn_vivado目录,如图2-44所示。
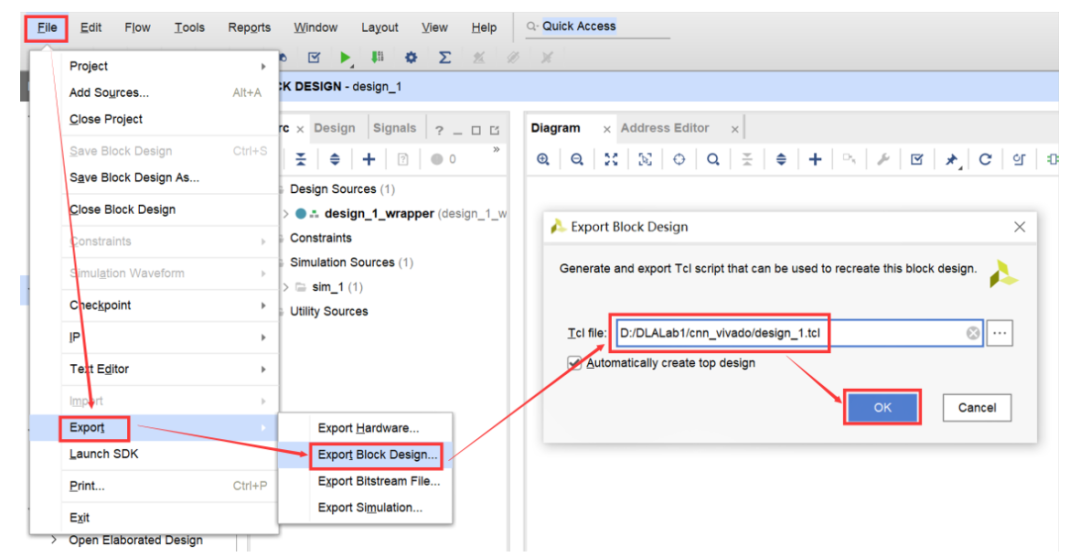
图2-44 导出Block Design的.tcl文件
类似地,点击菜单栏的File->Export->Export Bitstream File,将生成的比特流文件导出到D:/DLALab1/cnn_vivado目录。
将上面导出的.tcl和.bit文件分别重命名为mnist_cnn.tcl和mnist_cnn.bit,并将其拷贝到实验包的mnist_cnn.zip压缩包中,如图2-45所示。
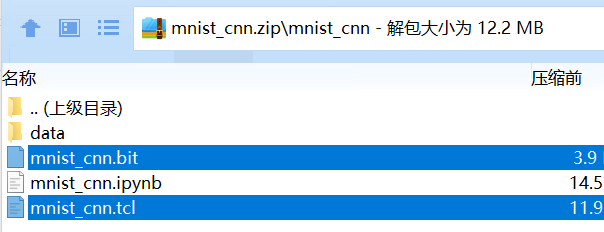
记笔记
在PYNQ开发中,.tcl文件和.bit文件在一起合称Overlay。
3. 上板测试
3.1 上传测试包
本课程实验以远程访问的形式使用PYNQ-Z2平台——校园网内的PC可通过Web浏览器访问10.249.12.21:<port>,以密码xilinx登录Jupyter Notebook。
点击Jupyter网页右侧的Upload按钮,上传mnist_cnn.zip压缩包,如图2-46所示。
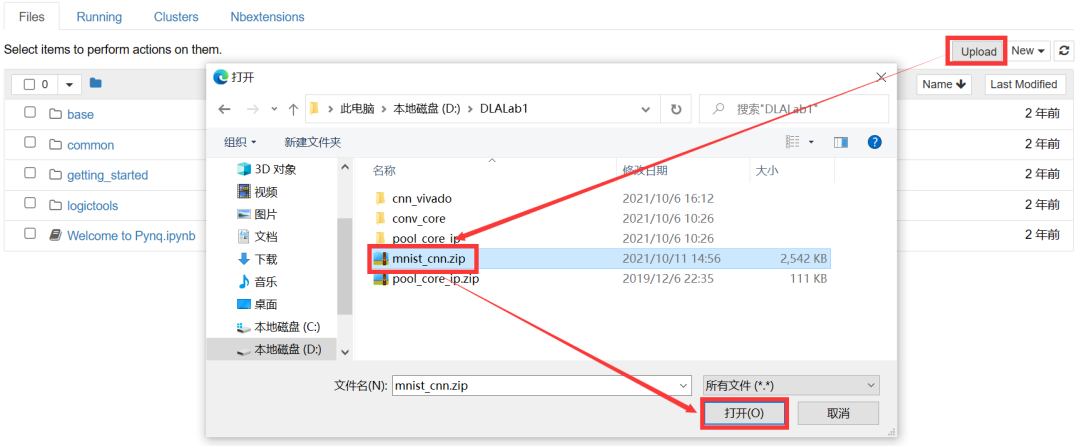
点击文件右侧蓝色的“Upload”按钮,开始上传,如图2-47所示。

莫心急
有时网络不稳定可能导致上传失败。若上传失败,请多尝试几次。
展开Upload按钮右侧的New,并点击Terminal以新建一个命令行终端,如图2-48所示。
 图2-48 新建Linux终端
图2-48 新建Linux终端
在终端中依次输入以下命令,以解压刚才上传的mnist_cnn.zip压缩包。
$> cd jupyter_notebooks/
$> unzip mnist_cnn.zip记笔记 在终端中,若遇到需要输入长串字符的情形,为避免误输入,请多使用Tab键。
使用方法:
先手动输入前几个字符,再按下Tab键,此时将自动补全。若没有补全,说明当前目录至少存在2个文件,
且这些文件的文件名的前几个字符均相同。此时,再手动多输入几个字符,再按Tab键即可。
3.2 运行测试
解压完毕后,回到Jupyter,点击进入mnist_cnn文件夹。
打开mnist_cnn.ipynb,并点击菜单栏的Cell->Run All开始运行测试。如果所设计的IP核功能正确,则程序应当能够正确识别出mnist_cnn/data/目录下名为1.jpg的手写数字图片,将输出如图2-49所示的结果。
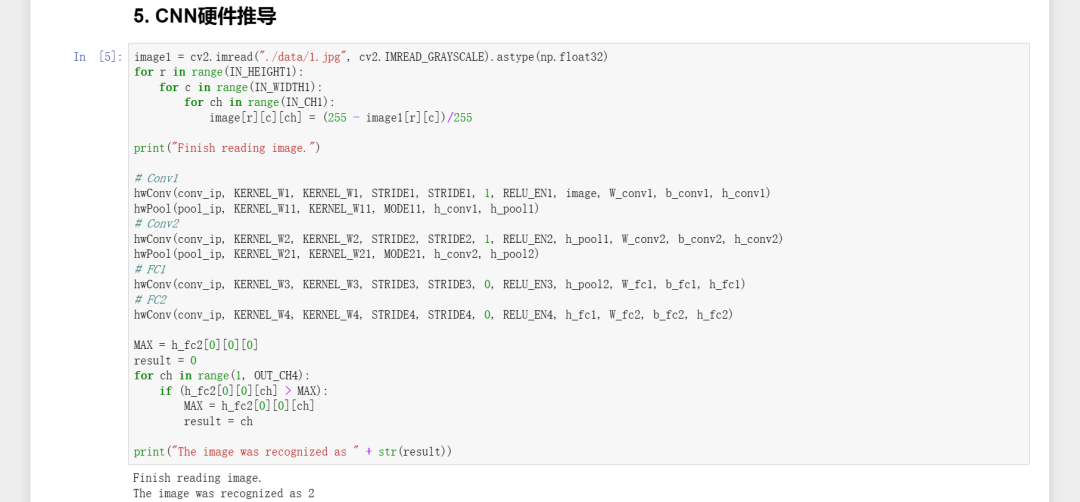 图2-49
图2-49
mnist_cnn.ipynb的运行结果

想要了解FPGA吗?这里有实例分享,ZYNQ设计,关注我们的公众号,探索

















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









