






点击蓝字关注我们
关注、星标公众号,精彩内容每日送达
来源:网络素材「9.11 和 9.9,哪个大?」
对于不少习惯了更新软件版本号的程序员而言,不少人的第一反应就是:当然是 9.11 大。但是如果没有限定场景,只是单纯地提出上面这个问题时,结果必然是相反的。
没想到,将这个问题抛给前能答疑解惑、后能挑战各种高数难题的 AI 大模型时,各种“翻车”情况也随之出现了。
1.国外大模型:9.11 vs 9.9,哪个大?
具体的事情要从一位名为 Riley Goodside 工程师的推文谈起。
值得一提的是,Riley Goodside 是 AI 数据标注赛道“独角兽”Scale AI 公司的一名 staff prompt engineer,这个岗位的职责具体是指在生成式 AI 和自然语言处理领域内,专门设计和优化提示(prompt)的人。这个角色要求深入理解如何构建有效的 Prompt,以引导 AI 模型生成所需的输出。
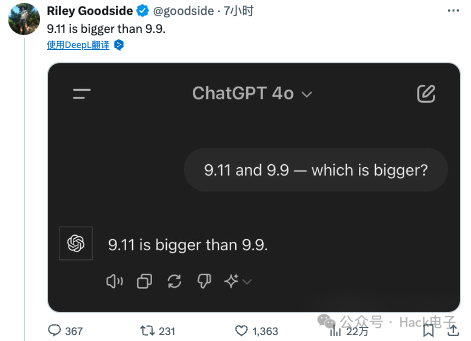
几个小时前,Riley Goodside 连发几条推文分享了自己的一些发现,即用「9.11 and 9.9 - which is bigger?」为 Prompt 输入给各家大模型时,如当前业界公认最先进模型之一的 ChatGPT 4o 的输出是:
9.11 比 9.9 大。
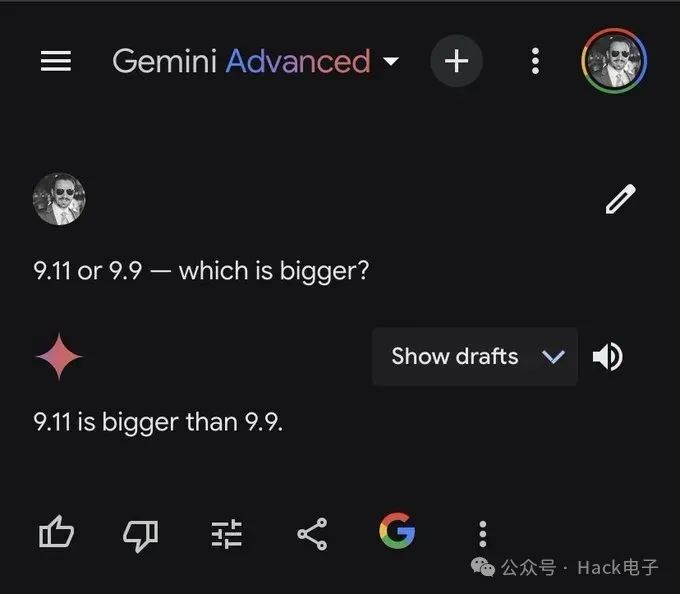
再来看看 Gemini Advanced 的表现,同样“翻车”:
9.11>9.9
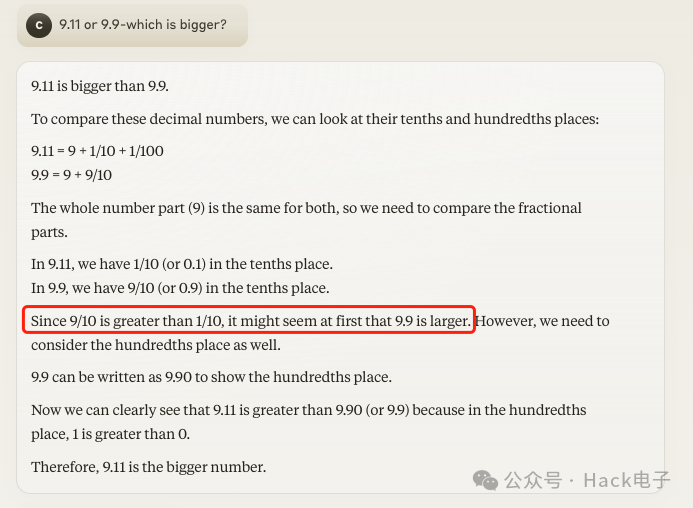
虽然 Claude 3.5 Sonnet 最终也未能逃过这个模糊问题带来的“坑”,但是其给出的解释中,一度就要回答正确了,其写道:
“两个数字中的整数部分(9)都是相同的,所以我们需要比较小数部分。
在 9.11 中,十分位是 1/10(或 0.1)。在 9.9 中,十分位是 9/10(或 0.9)。
由于 9/10 大于 1/10,乍看之下可能觉得 9.9 更大。”
没想到接下来画风急转,Claude 3.5 Sonnet 有似是有理有据地说:
但是,我们还需要考虑百分位。
9.9 可以写成 9.90 以显示百分位。
现在我们可以清楚地看到 9.11 大于 9.90(或 9.9),因为在百分位上,1 大于 0。
因此,9.11 是较大的数。
最终在正确的答案上渐行渐远:
这个简单的问题也让不少人联想到前几天国内关于《歌手 2024》「终极袭榜赛」竞演结果的排名。
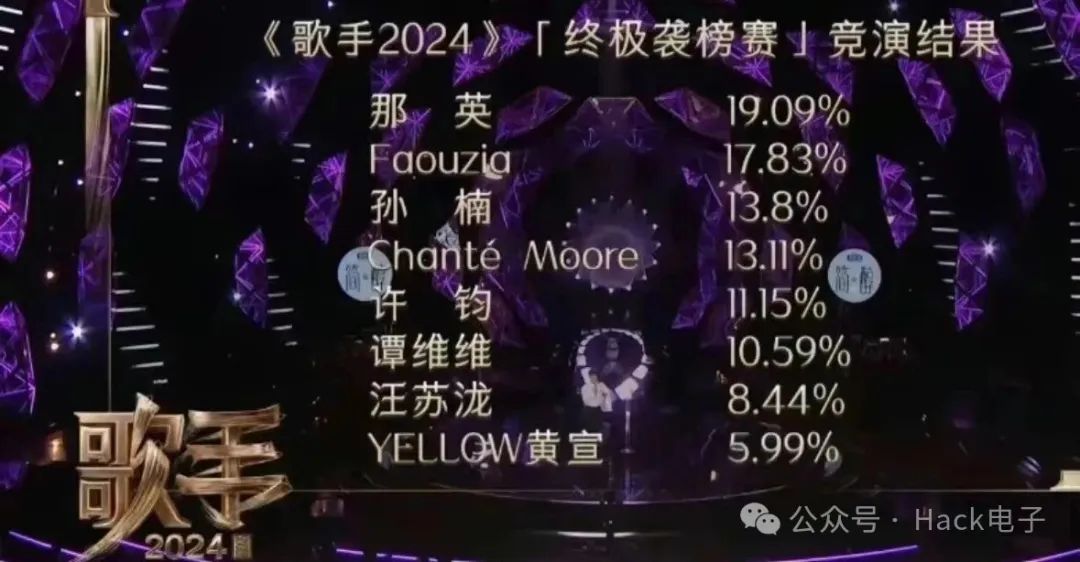
当时有不少网友就 13.8% 和 13.11% 哪个大的问题争论了起来。
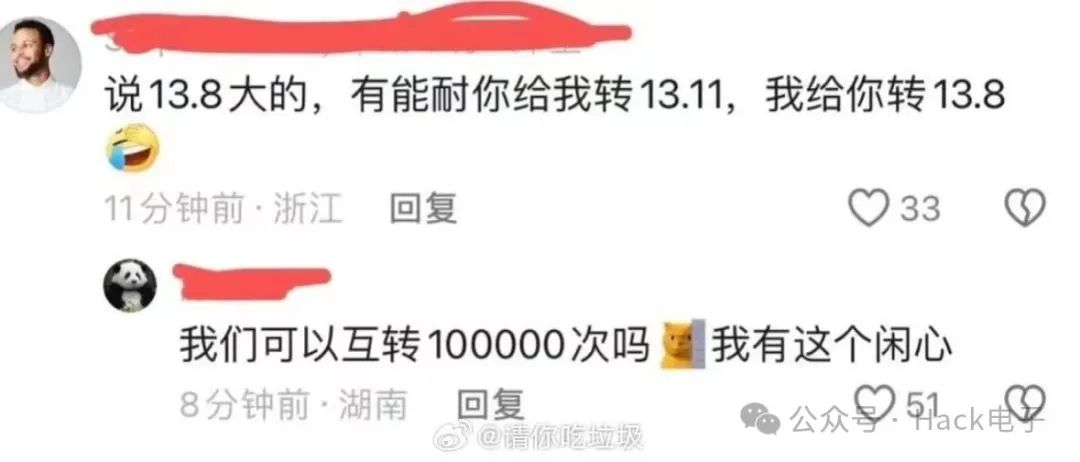
在纠正不了「某些已形成思维定式」的用户想法之后,甚至有人搬出了教材给出解释,“在最新人教版小学四年级数学下册课本中,我们可以找到相关知识点:比较两个小数的大小,先看它们的整数部分,整数部分大的那个数就大;整数部分相同的,十分位上的数大的那个数就大;十分位上的数也相同的,百分位上的数大的那个数就大..."
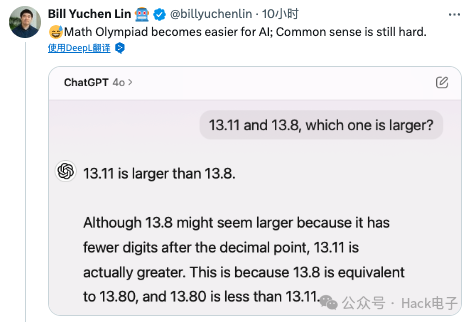
在今天 Riley Goodside 分享 AI 大模型回答这一问题的表现时,来自 Google 前工程师、Allen AI 研究员 Bill Yuchen Lin 也将比较的数值换成了 13.11 和 13.8,再次问及大模型,没想到答案还是出错了。
其评价道,「数学奥林匹克竞赛对人工智能来说更容易,但常识仍然很难。」
同时,他还表示,“这种常识性 AI 失败案例,让我不禁想起 @YejinChoinka的 TED 演讲:《为什么 AI 既聪明得令人难以置信,又愚蠢得令人震惊》(https://www.ted.com/talks/yejin_choi_why_ai_is_incredibly_smart_and_shockingly_stupid)”。
2.换个 Prompt,答案会不会不一样?
不过,也有人质疑作为 Prompt 工程师的 Riley Goodside 的提问方式,“它(大模型)对词序敏感![我相信你也知道]如果你把数字放在问题后面,他们就会答对[google 和 openai,anthropic 则不然]。你使用斜线也是有意混淆视听吗?”
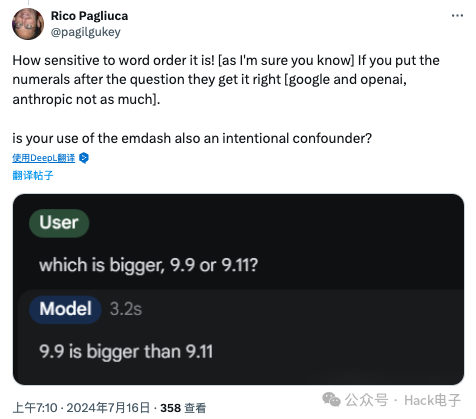
对此,Riley Goodside 给出自己的解释:
澄清一下:我并不是说无论如何提示,任何 LLM 都会始终如一地认为 9.11 > 9.9。我是说,如果你以这种特定方式给出 Prompt,许多领先的模型都会告诉你 9.11 > 9.9,这就很奇怪了。如果你想重现,请粘贴文本中的 Prompt(9.11 and 9.9 - which is bigger?)。
为了复现这个问题,数字确实需要放在问题前面。但以下内容似乎都无关紧要:
标点符号(破折号/逗号/无标点)
连词(和/或/对比)
比较词(更大/更大/更大)
说明这些是实数
针对质疑,也有好奇的用户尝试了去掉了问题中间的”-“符号,结果还是如此:

我们换了种提问方式,即使明确这是数值了,ChatGPT 4o 还是坚定的表示:9.11 比 9.9 要大!

延着这个问题,当有网友进一步提问时,更为离谱的事情发生了:当让这两个数值相减时,ChatGPT 4o 直接用 9.11 的百分位中的 1 减去 9.9 百分位上的 0;又用 9.11 十分位上的 1 减去 9.9 十分位上的 9,最终不够减之后,向前借一位又忽略了这一点,得到了 0.21 的错误结果。

如今看来,对大模型提出哪个数字更大问题时,它们将数值分成了两个部分,9.11 和 9.9 的整数、小数分别做了比较,整数部分为 9 对比完之后,再将小数部分的十分位、百分位整体做了比较,其认为 11>9,进而给出了 9.11>9.9 的结果。
3.国产大模型实测
那么在这个简单的问题上,国产大模型的表现力又如何呢?
先来看看阿里的通义千问的。它不仅给出了详细的解释,而且结果也是正确的。

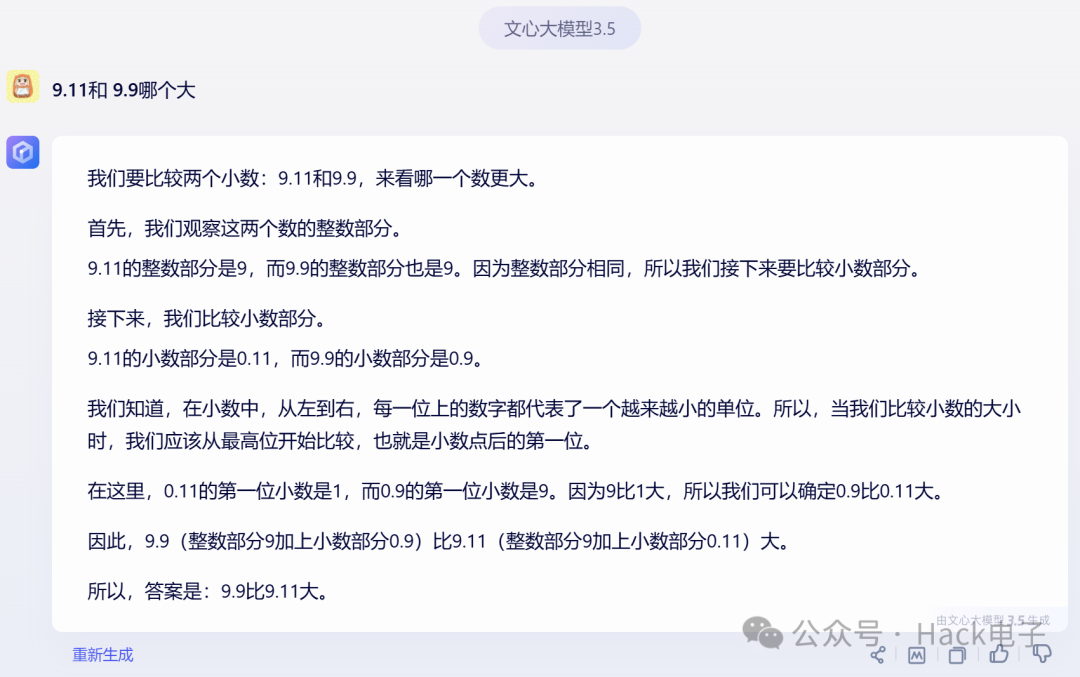
百度文心一言同样正确:
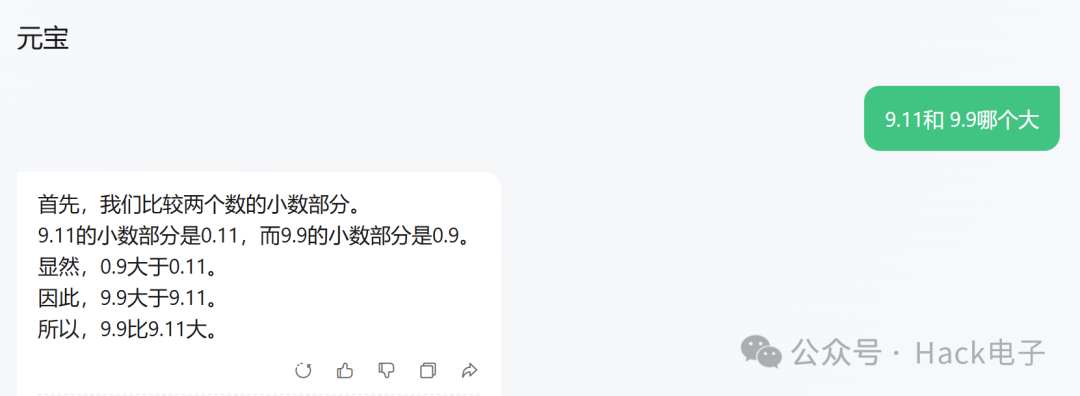
腾讯元宝:
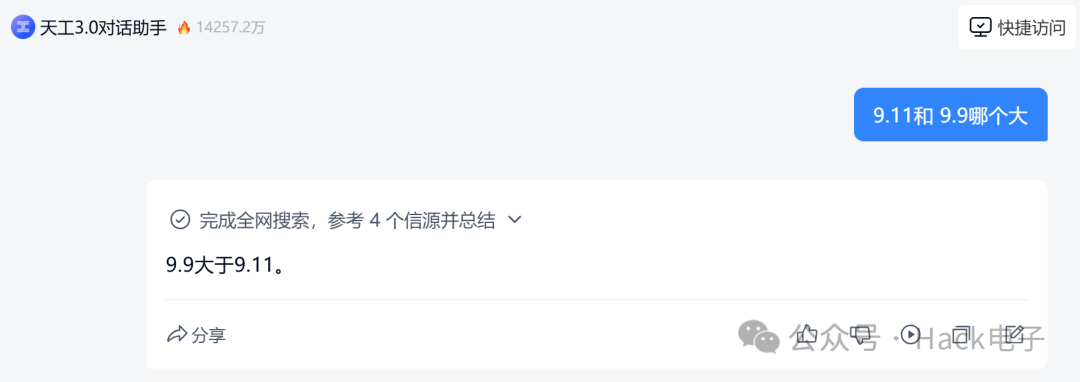
昆仑万维的天工在开启了全网搜索后,给出了简洁的正确答案:
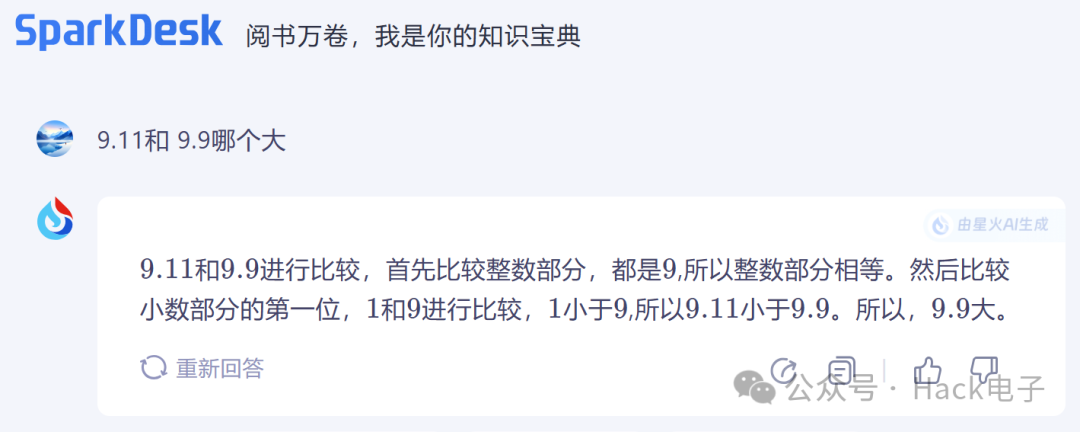
科大讯飞的星火大模型:
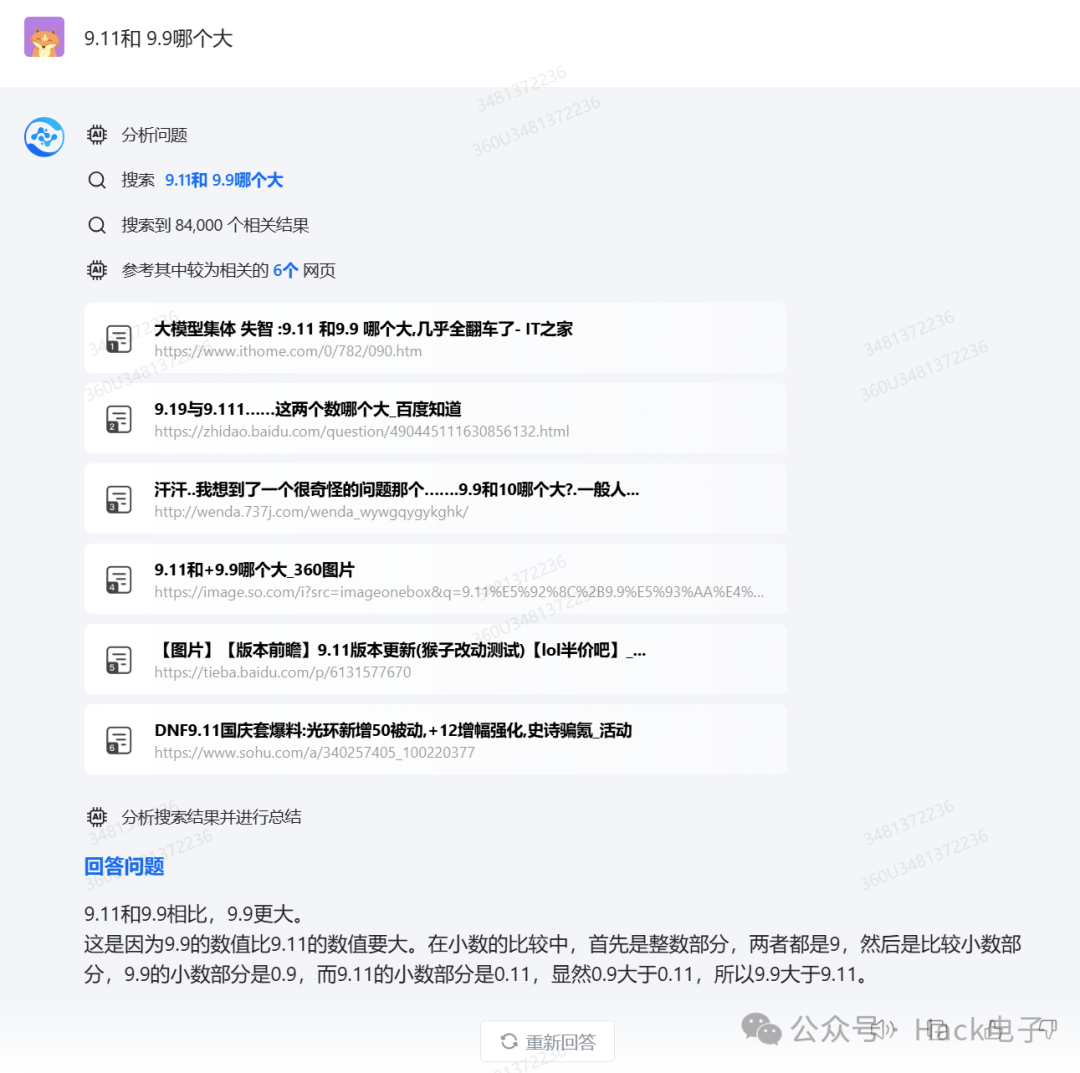
360 智脑在回答这一问题时同样触发了联网搜索功能,好在给出了正确的答案:
百川智能的回答同样没有问题:
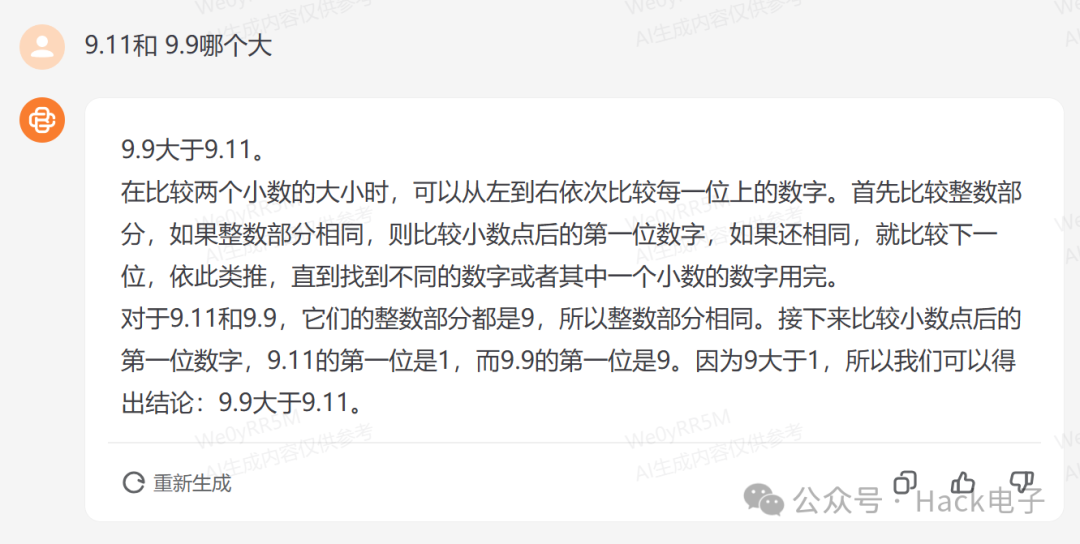
不过实测过程中,也有些起初错误,但是用同样问题问第二遍时又有了改正:
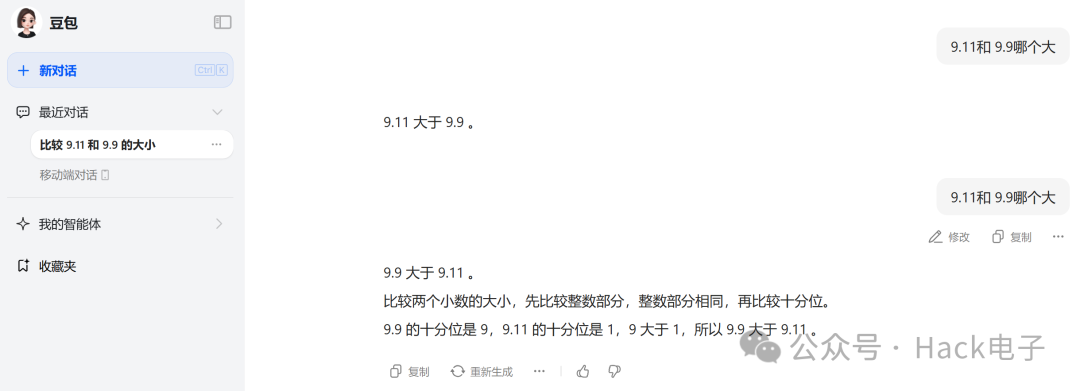
遗憾的是,也有一些模型还存在问题:
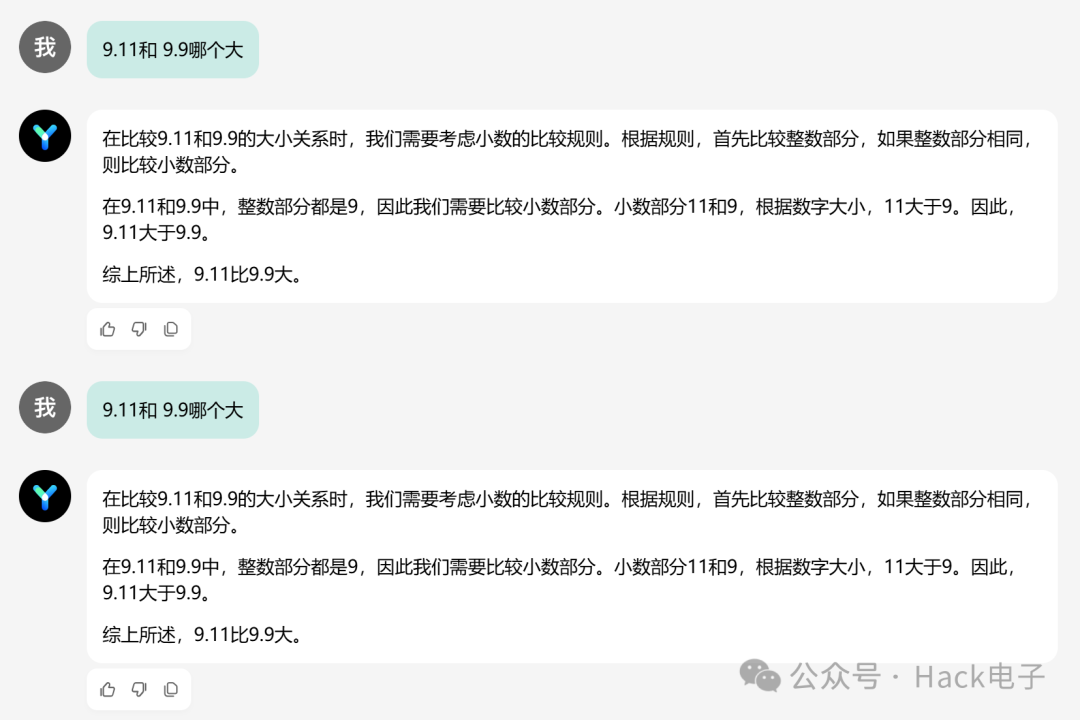
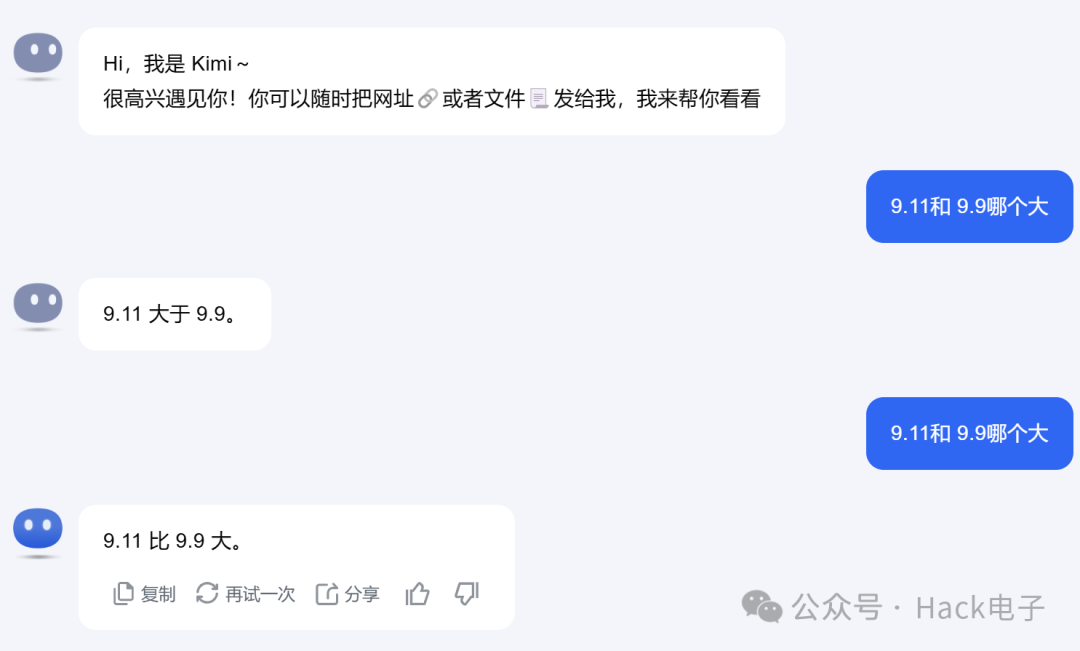
4.争论依然存在
不仅如此,有网友在实测负数时,GPT 们依然也被绕晕了:

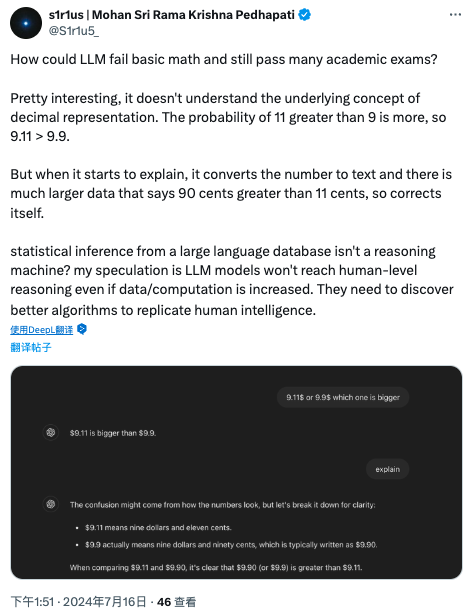
还有网友在测评 9.11 美元和 9.9 美元时评价道:
大型语言模型(LLM)为什么在基础数学上失败,却仍然能通过许多学术考试?
非常有趣的是,它并不理解小数的基本概念。认为11比9大,所以9.11 > 9.9。
但是,当它开始进一步解释为什么9.11 > 9.9时,它又将数字转换为文本,并且有大量的数据表明 90 美分比 11 美分大,所以它不断纠正自己。
从大型语言数据库进行统计推断并不是推理机器?我猜测即使增加数据和计算量,LLM 模型也不会达到人类水平的推理能力。它们需要发现更好的算法来复制人类的智能。
至于为什么仅是比较数值时出错,不少人猜测,这似乎与语序有很大关系。
大模型如今在基础能力方面的表现,也不禁让人想到就在几天前,Google DeepMind CEO Demis Hassabis 在公开场合表示,“当前的 AI 在智力方面与猫的水平相当,甚至还不如普通家猫”,这无疑给许多期待 AGI(通用人工智能)即将到来的人泼了一盆凉水。

想要了解FPGA吗?这里有实例分享,ZYNQ设计,关注我们的公众号,探索















 4390
4390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









