







 本文介绍了线性判别分析(LDA)的基本原理,包括其作为监督降维技术的思路,以及如何通过最大化类间距离和最小化类内距离来提高样本可区分性。文章还涉及了损失函数的推导,使用拉格朗日乘子法求解最优方向w,并讨论了广义特征值和广义瑞利商的概念。
本文介绍了线性判别分析(LDA)的基本原理,包括其作为监督降维技术的思路,以及如何通过最大化类间距离和最小化类内距离来提高样本可区分性。文章还涉及了损失函数的推导,使用拉格朗日乘子法求解最优方向w,并讨论了广义特征值和广义瑞利商的概念。
广义线性模型可以通过“联系函数”完成分类的目的,那线性模型应如何直接完成“分类”呢?
接下来我们引入最基本的一种线性判别分析(LDA)来解答
对于西瓜书中部分符号的说明:

1、算法原理
线性判别分析是一个经典的二分类算法。
(1)主要思想:
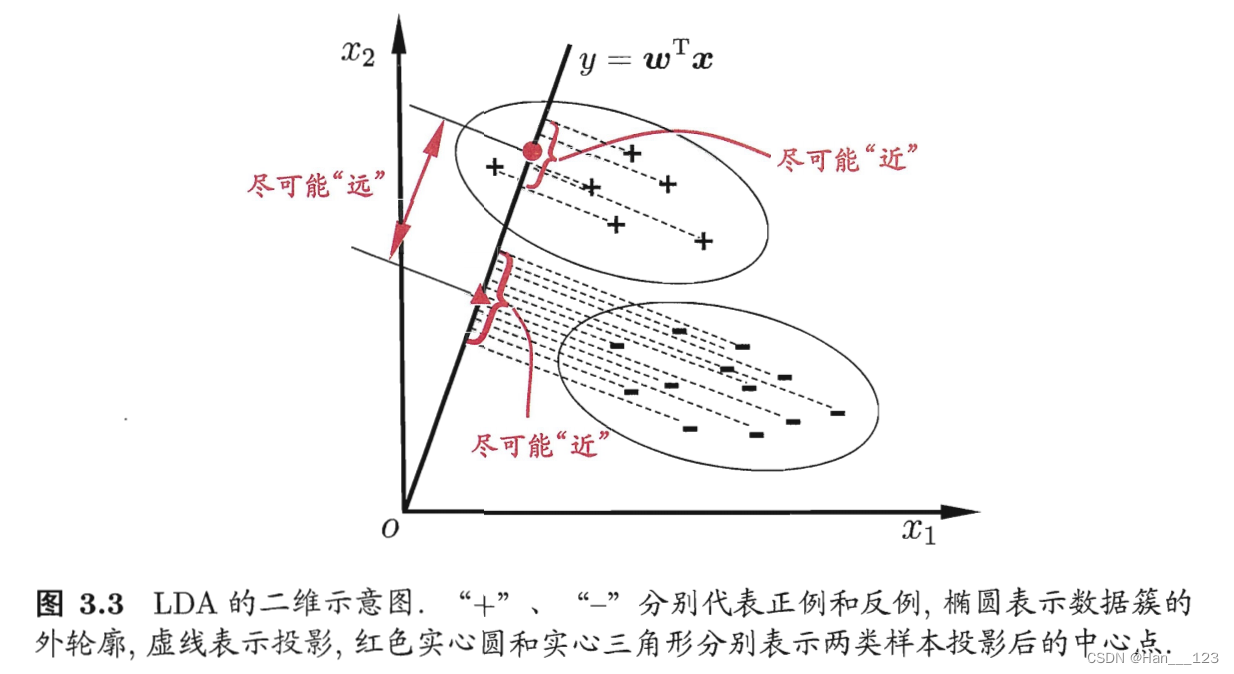
给定训练样例集,设法将样例投影到一条直线(低维空间)上使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离:在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别.图 3.3 给出了一个二维示意图。(因此也可以被看作一种“监督降维技术”)
(2)实例:
线性判别回归即以一种基于降维的方式将所有的样本映射到一维向量w上,然
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









