







视觉任务的难点是像素整体呈现出的结果和个别像素的值没有直接关联,难以遵循具体的规则设计算法。

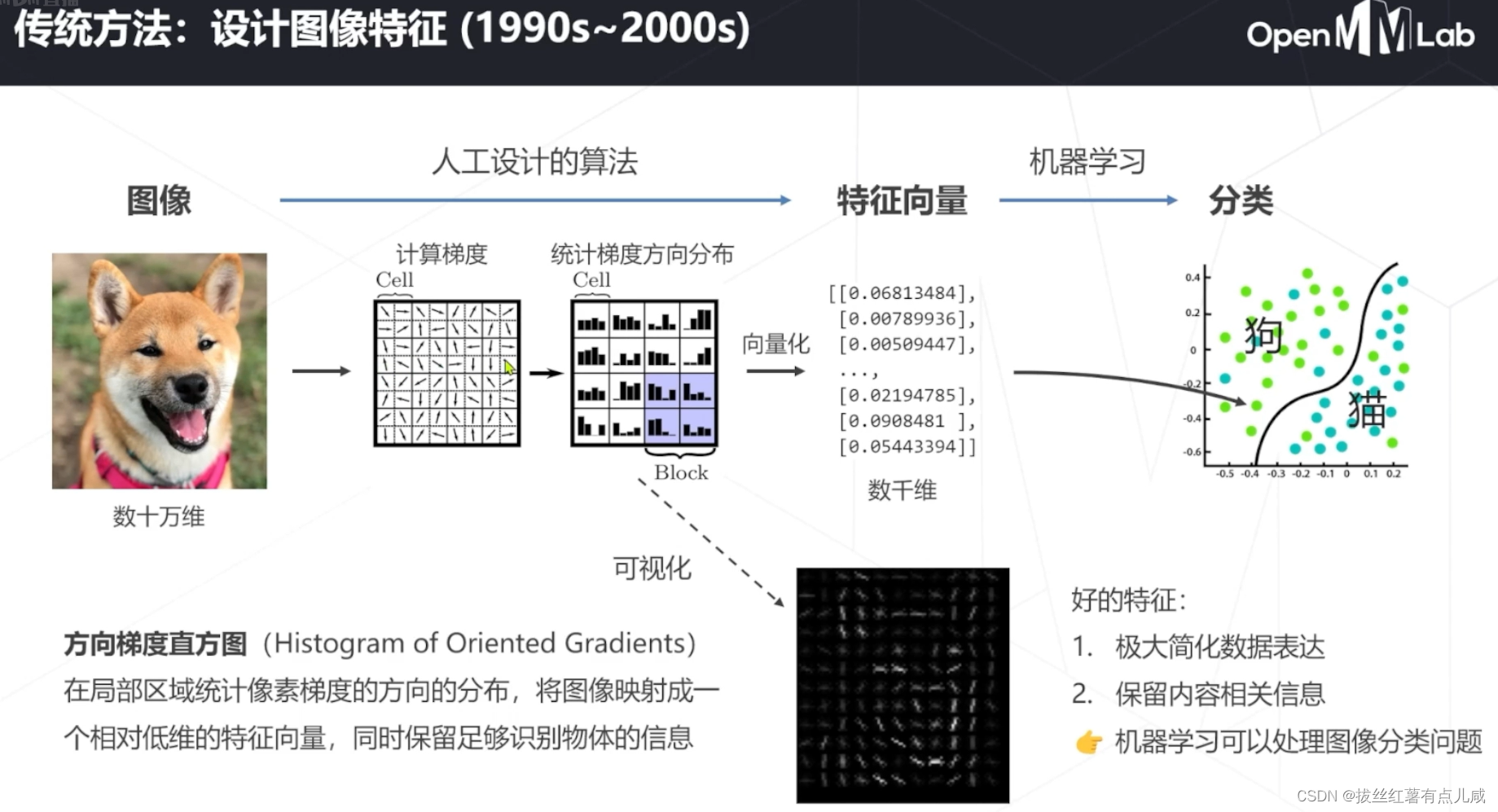
保留边缘轮廓的一些信息,应用于图像分类。
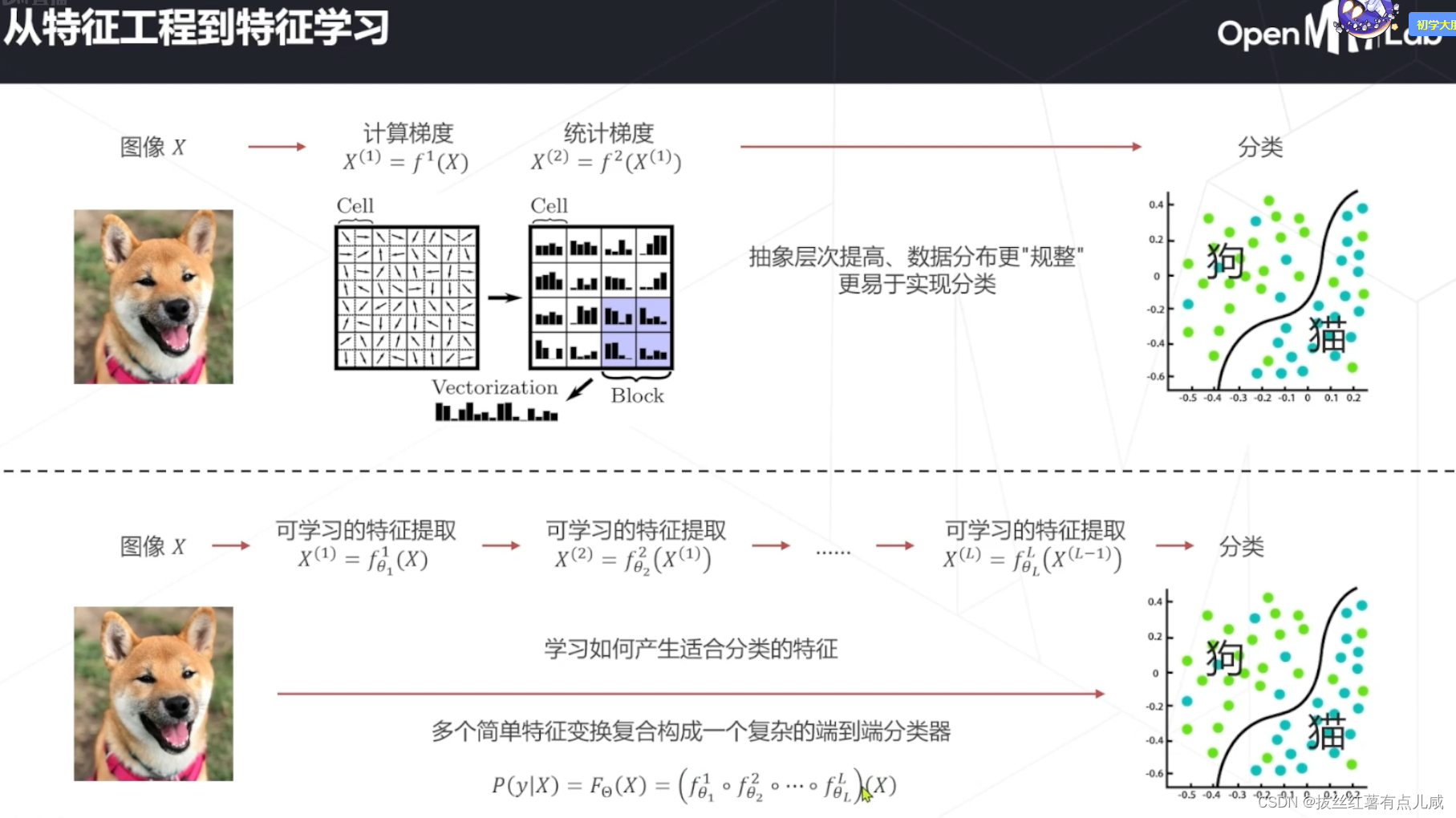
不仅学习分类,还学习如何产生合适分类的特征。深度学习的思想。
课程内容:
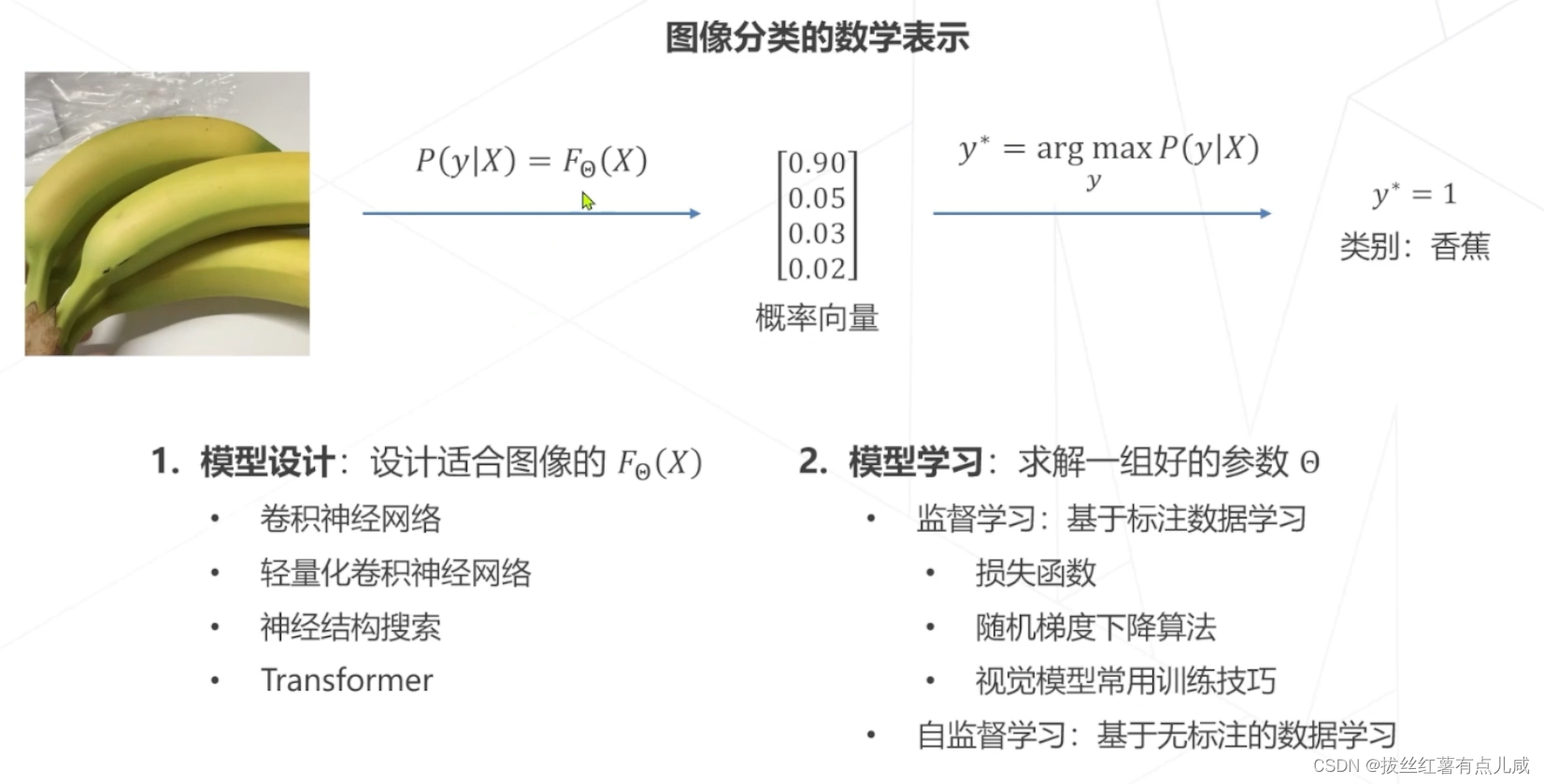
1、函数如何设计
2、如何求解一个好的参数,达到好的效果
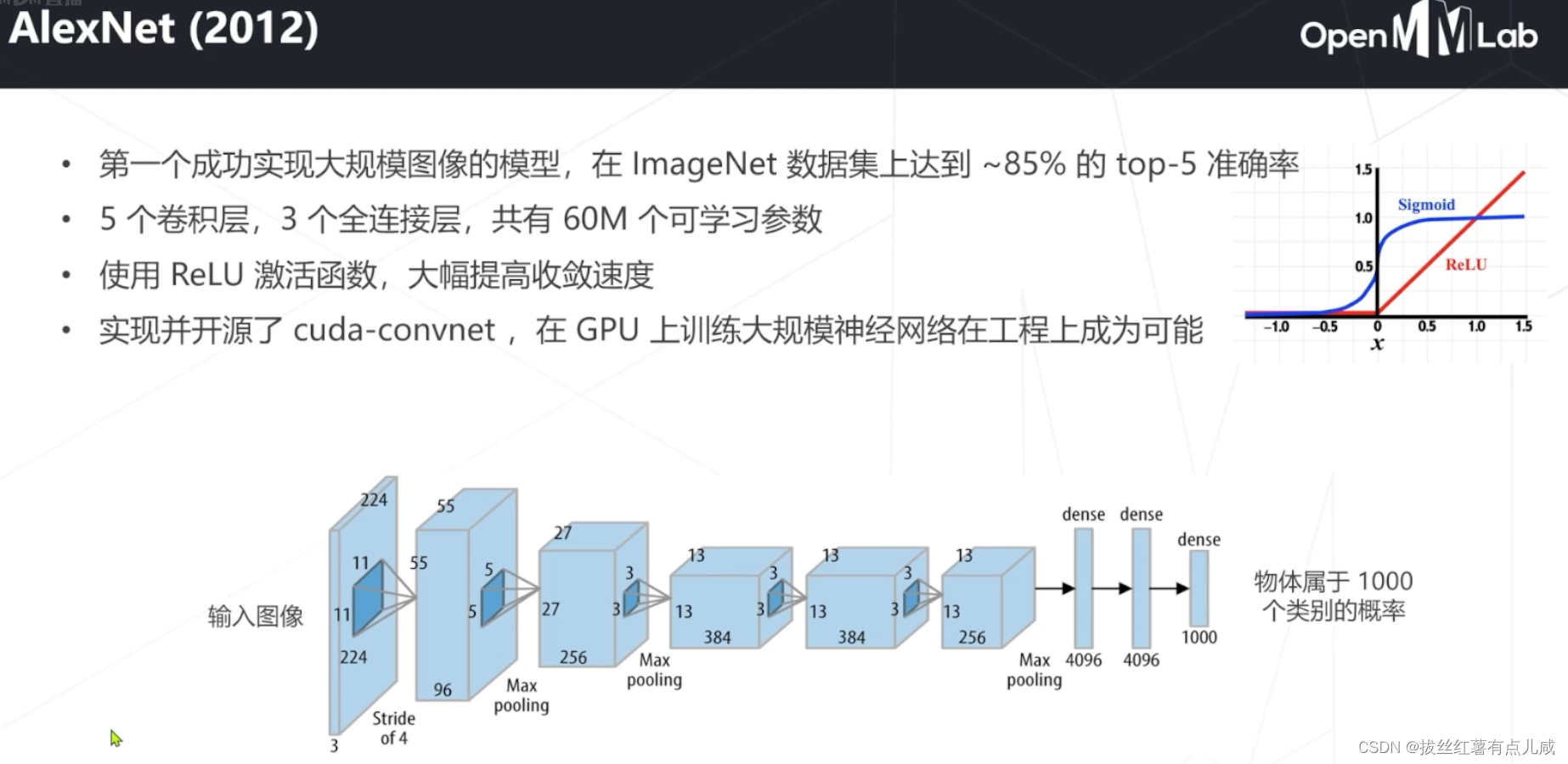
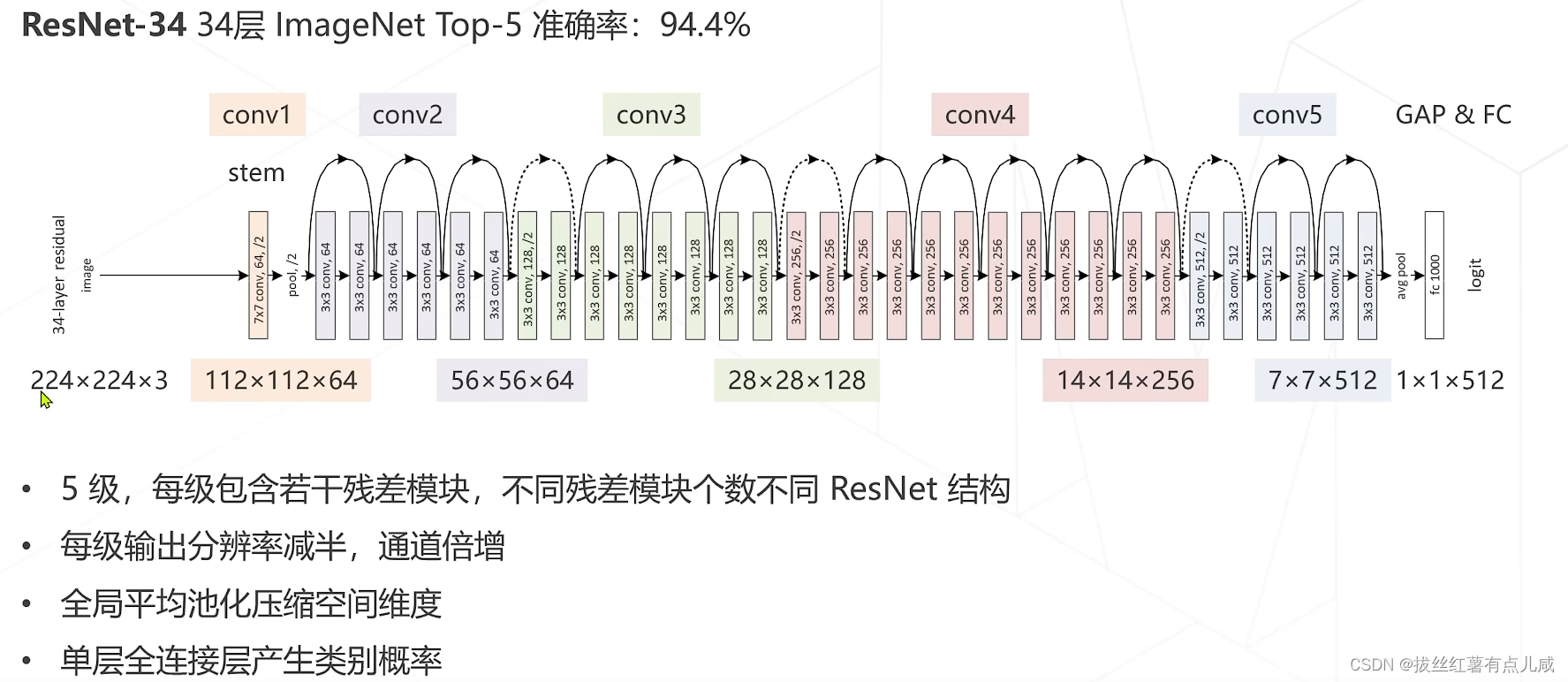
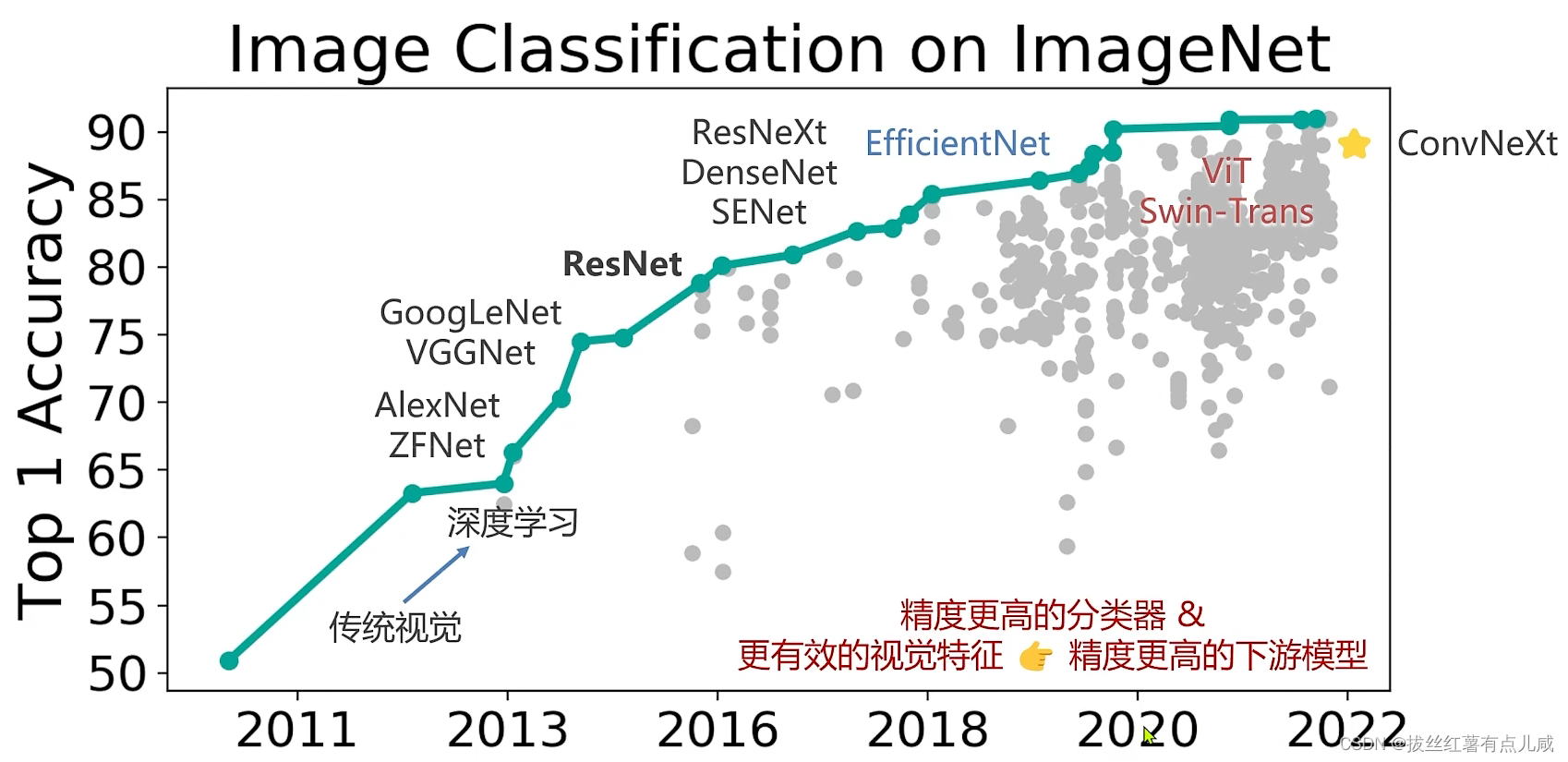
开端。AlexNet
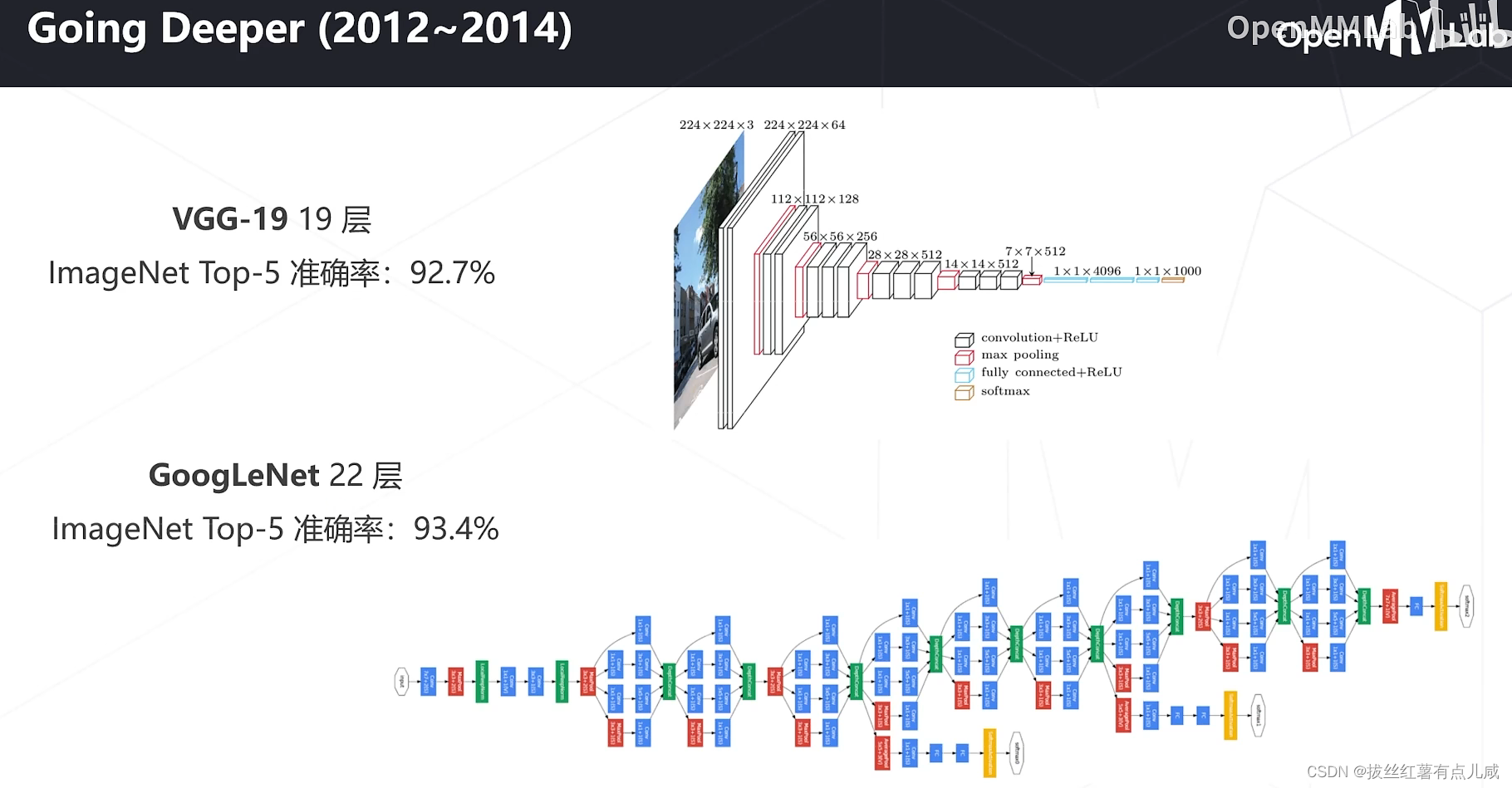
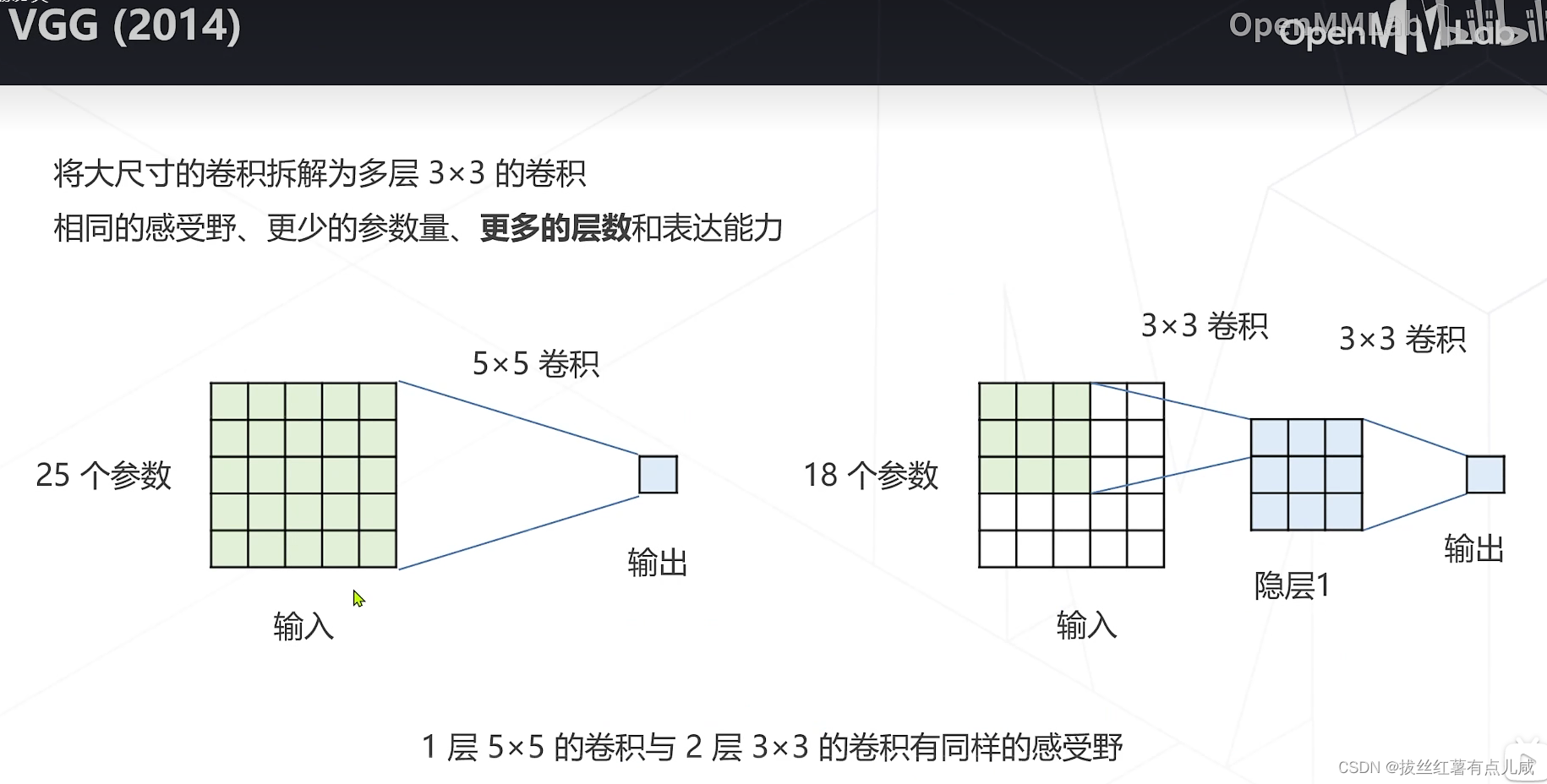
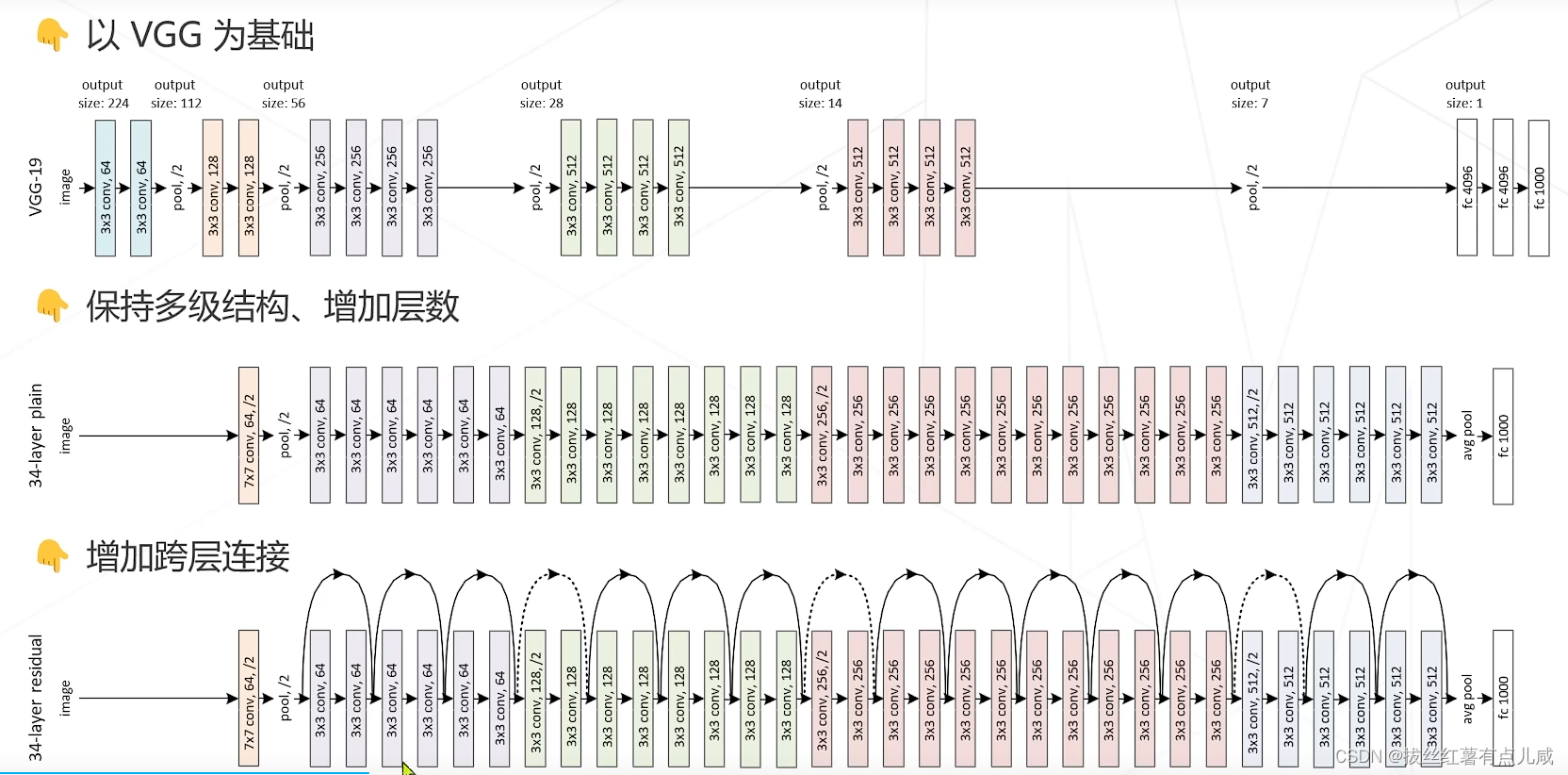
VGG将5*5拆解成3*3。更少的参数。
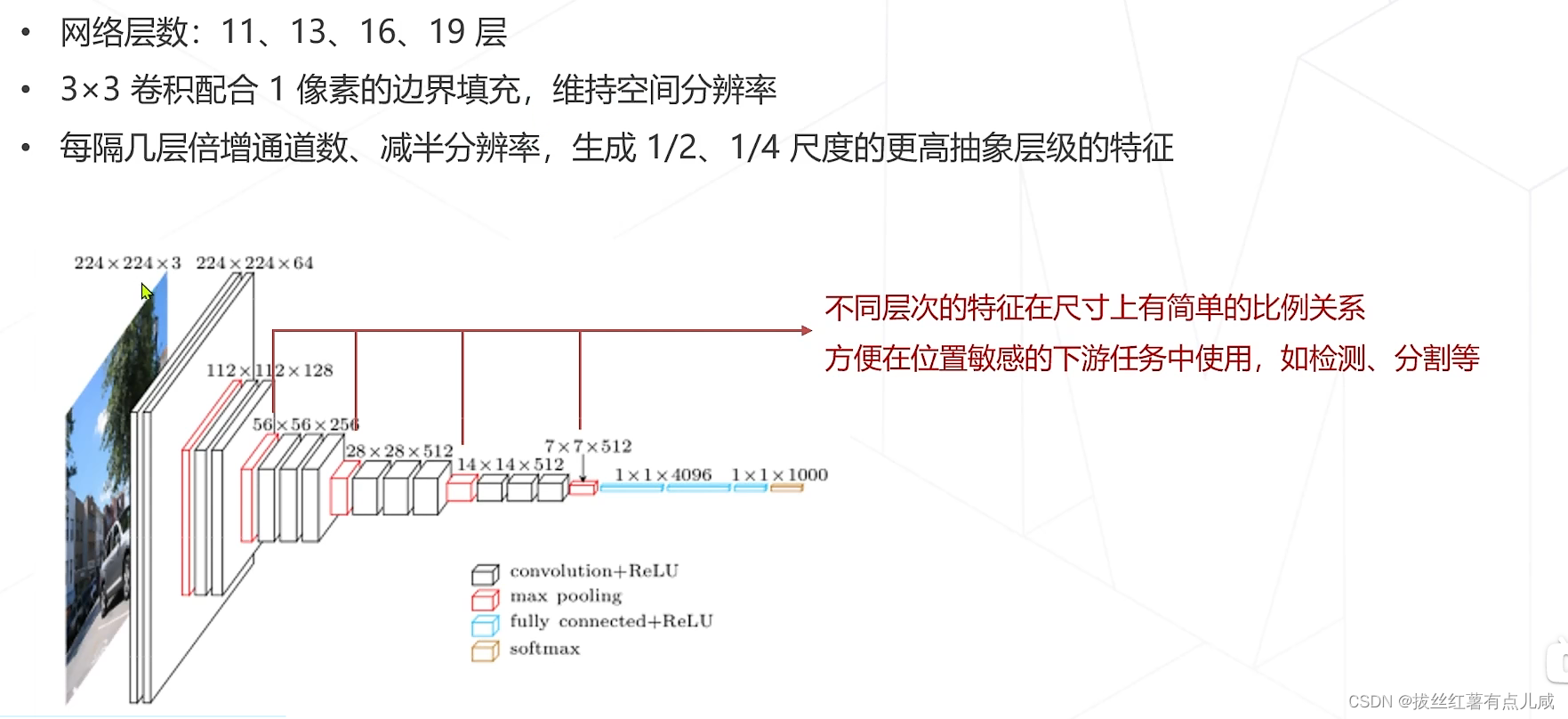
配合边界填充保持分辨率。卷几层后进行一次降采样。
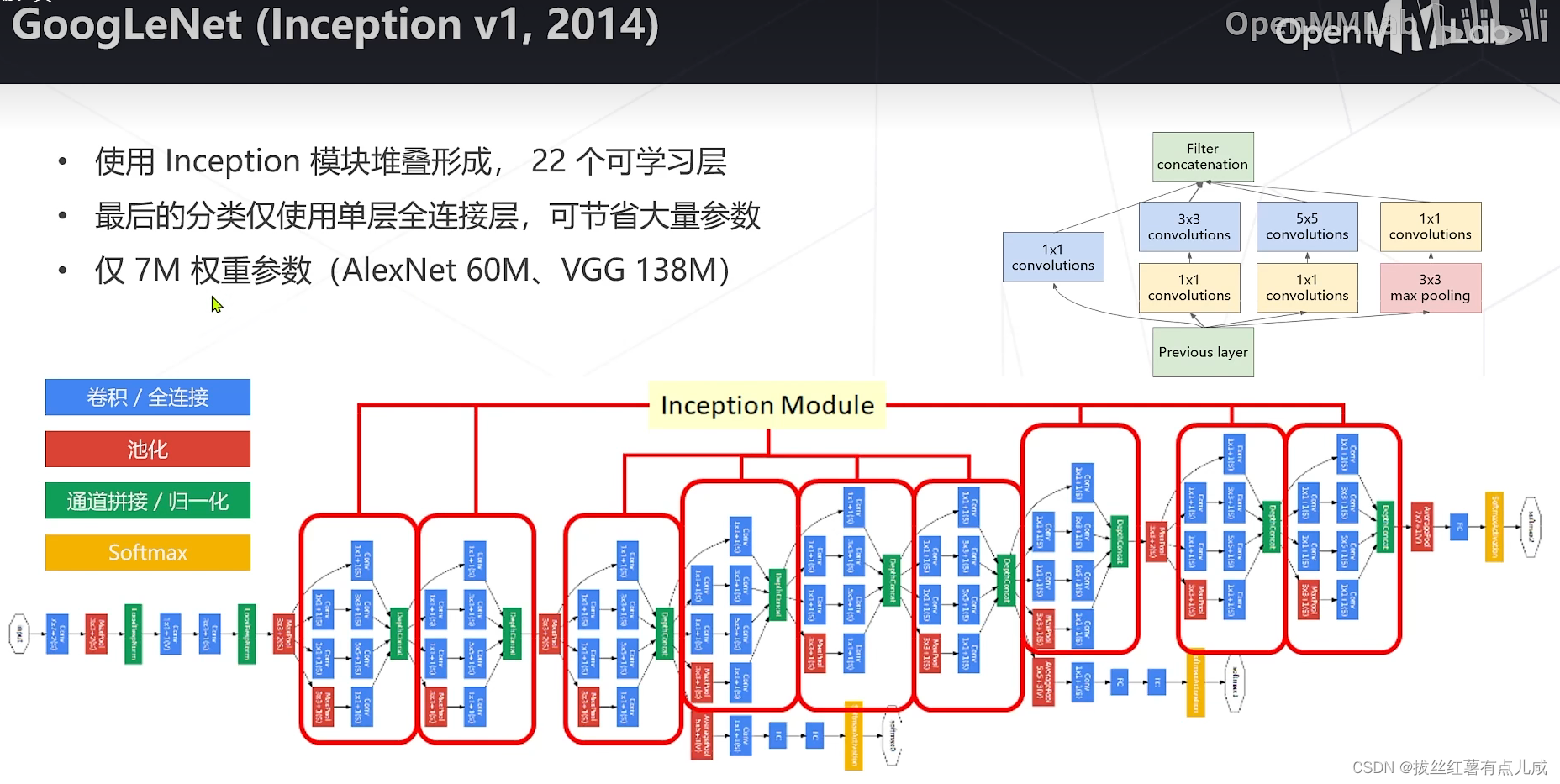
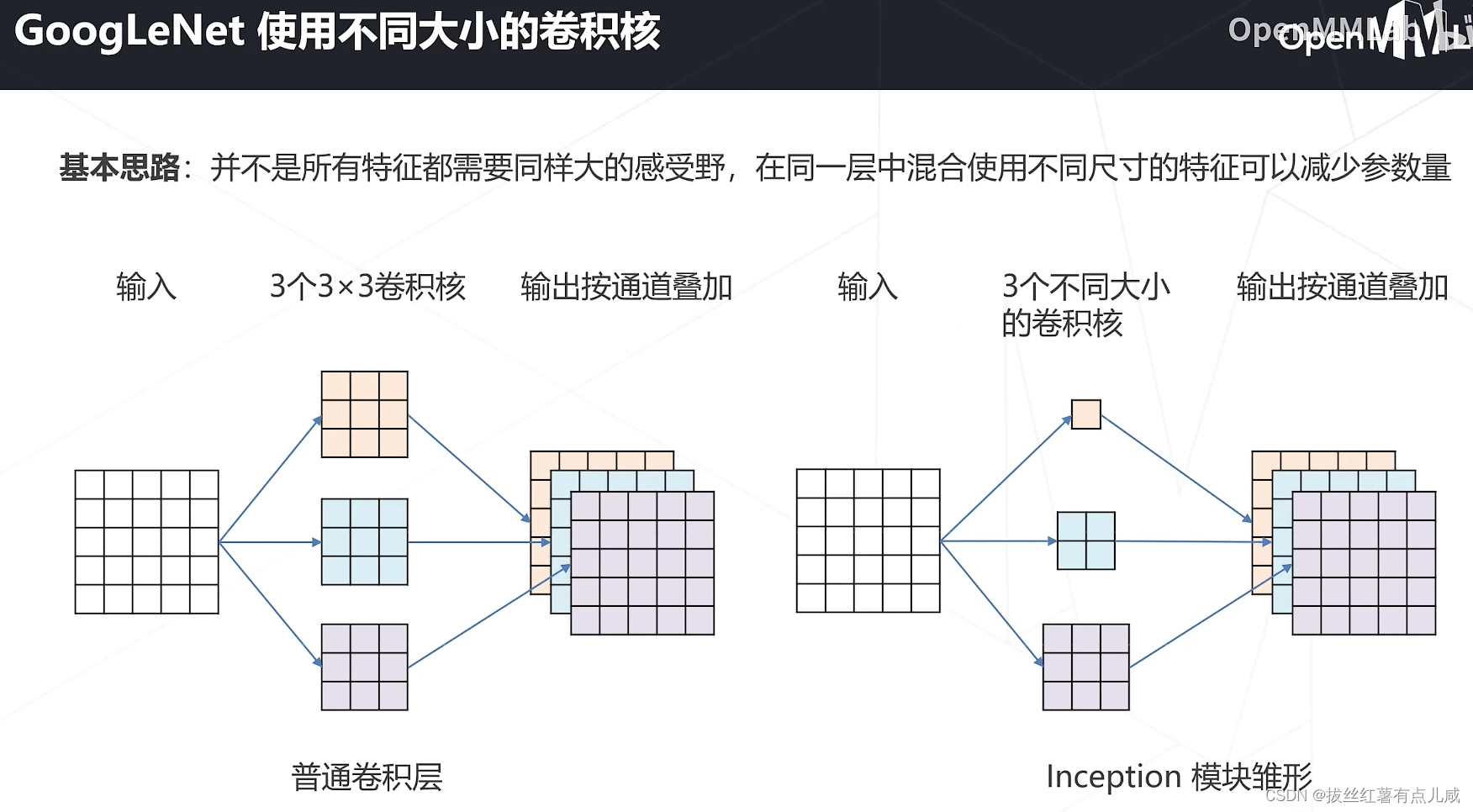
GoogleNet参数量大大减少。
人们逐渐发现精度退化问题
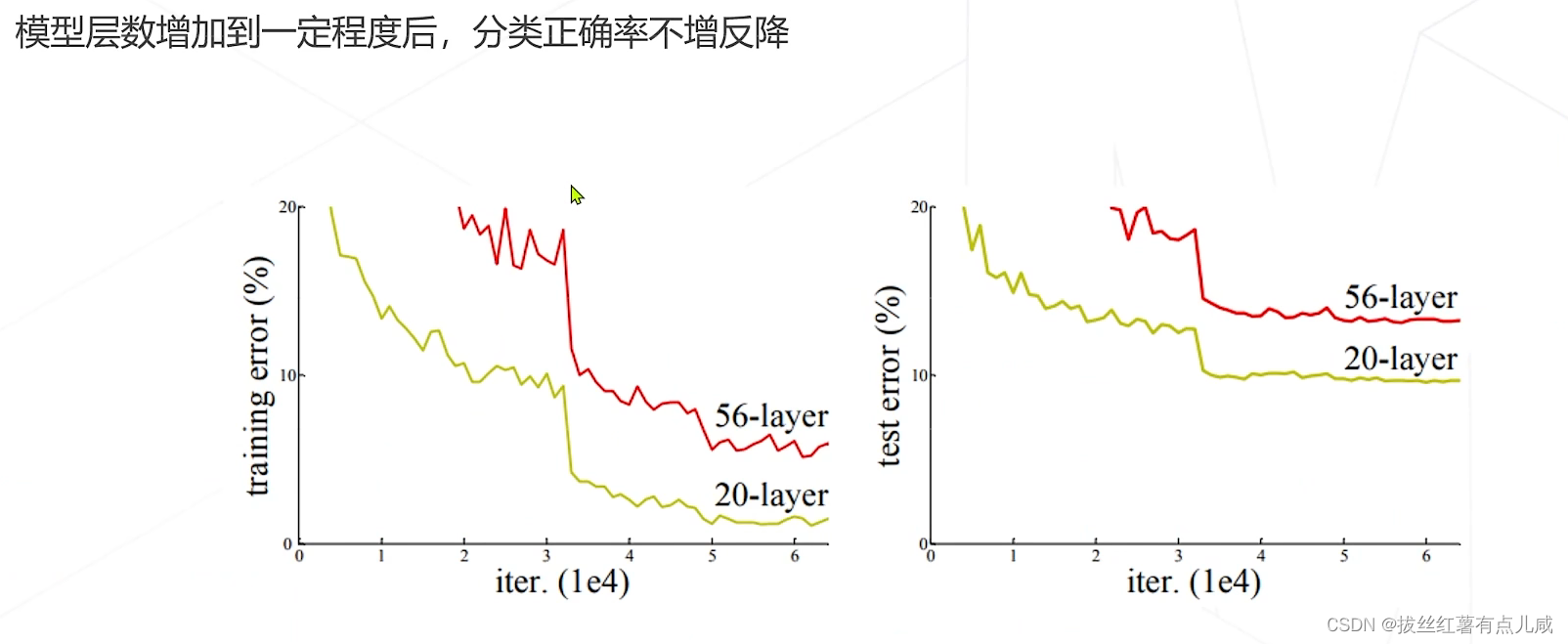
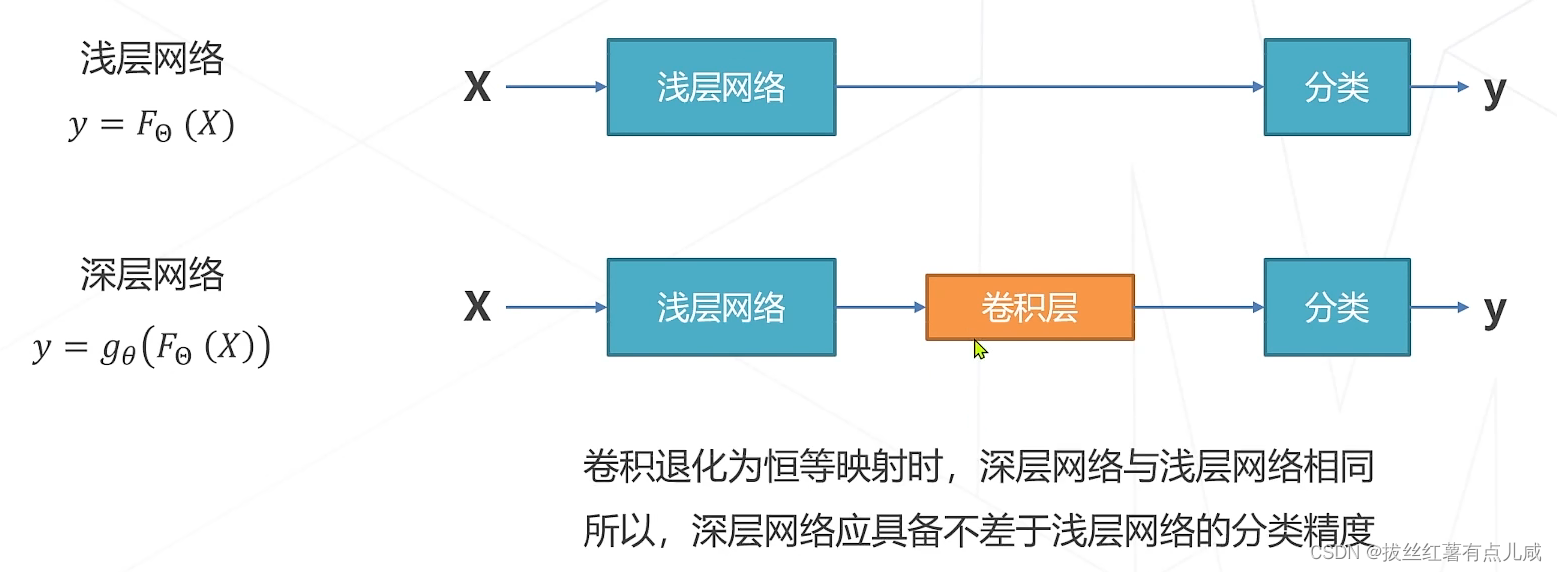

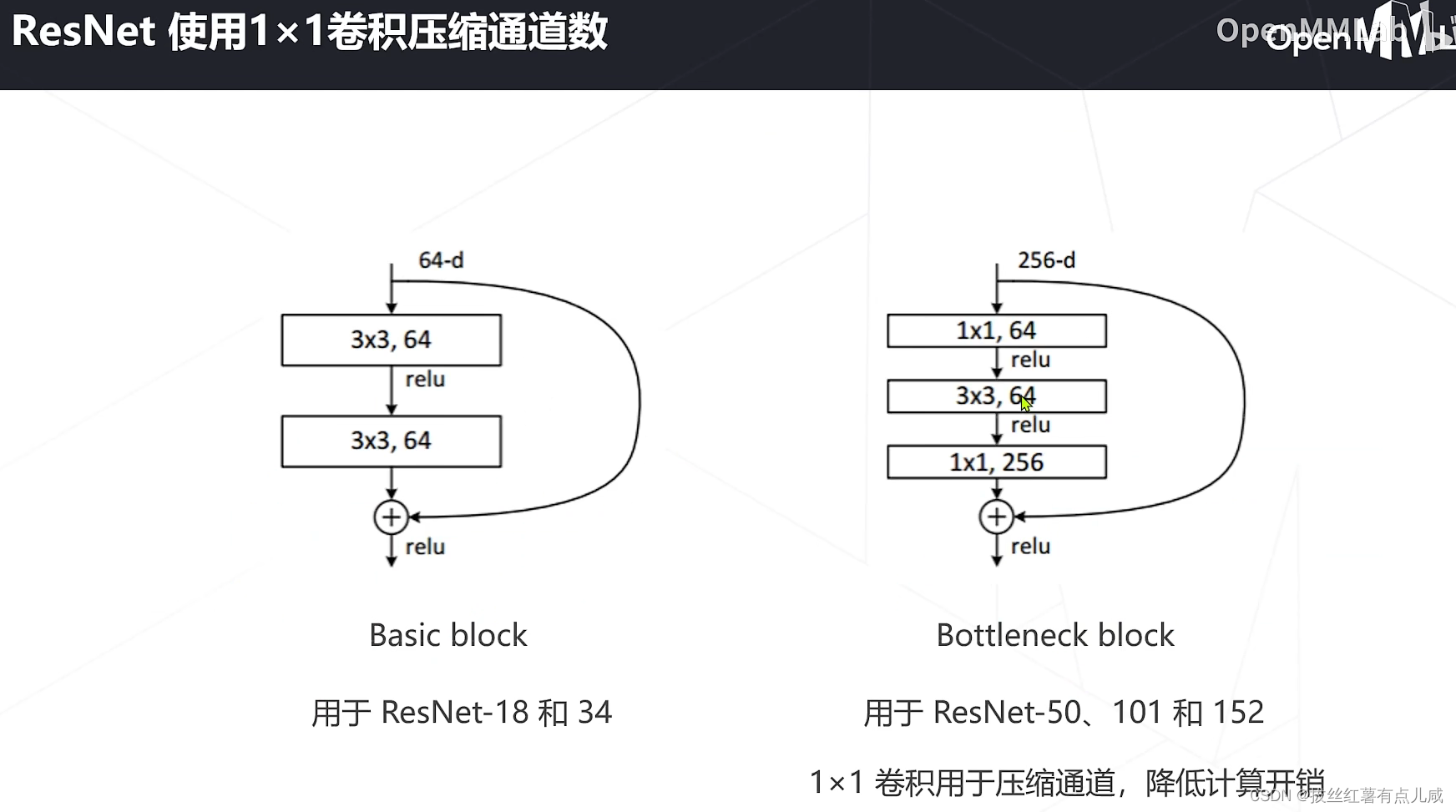
基于此思想,提出来残差学习
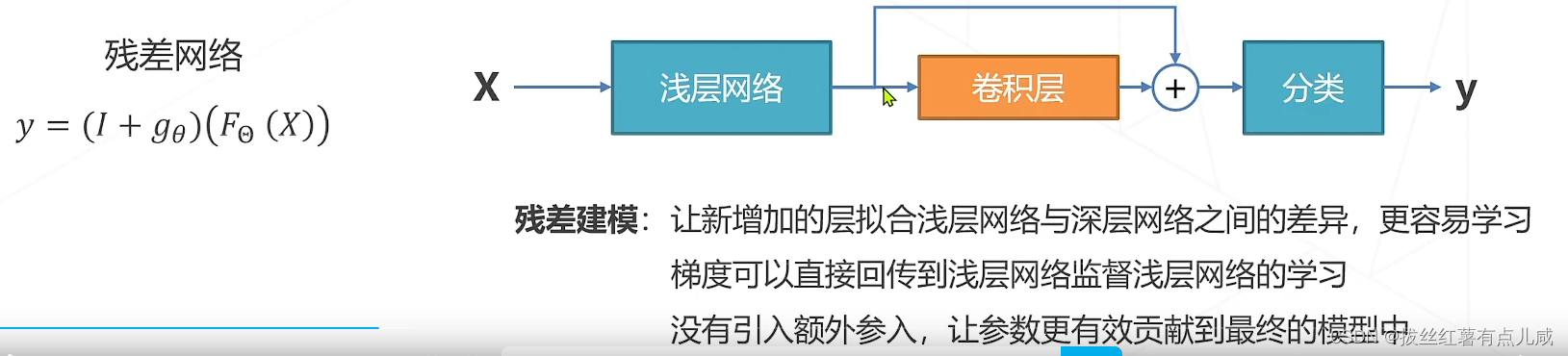

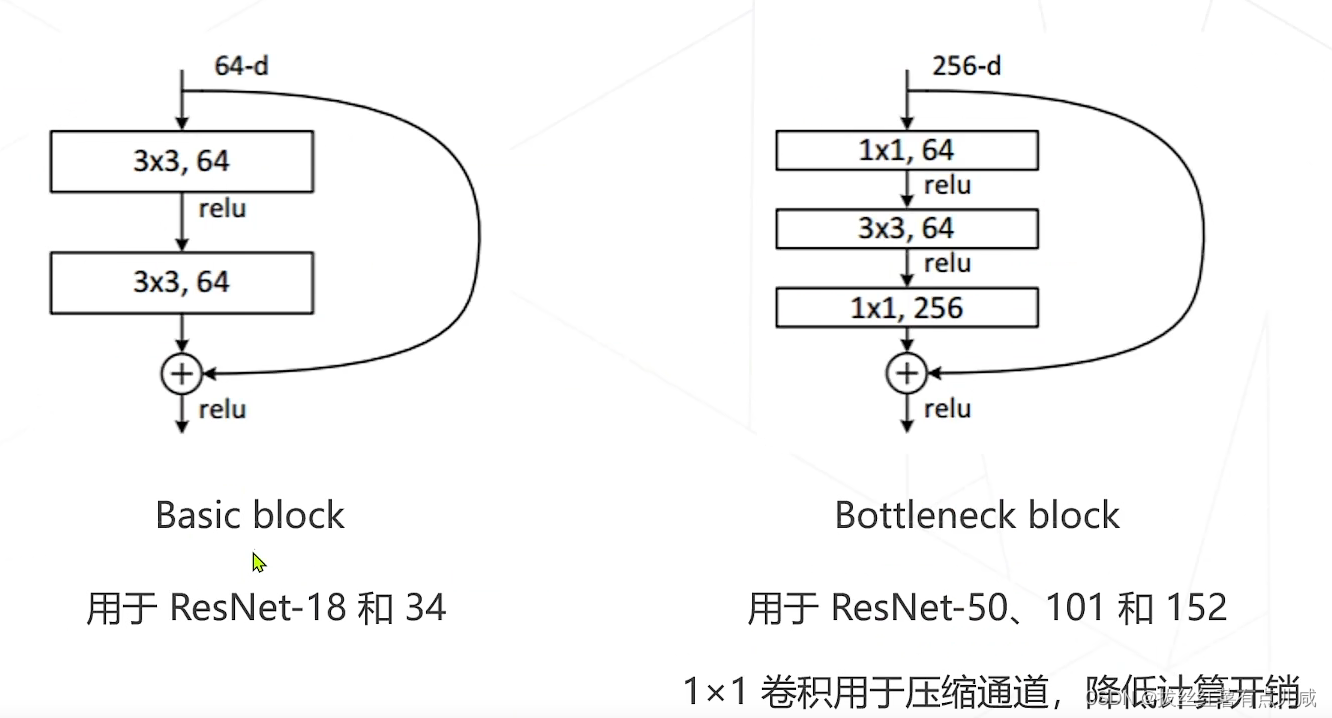
计算技巧:残差模块加了一层,计算量更小。
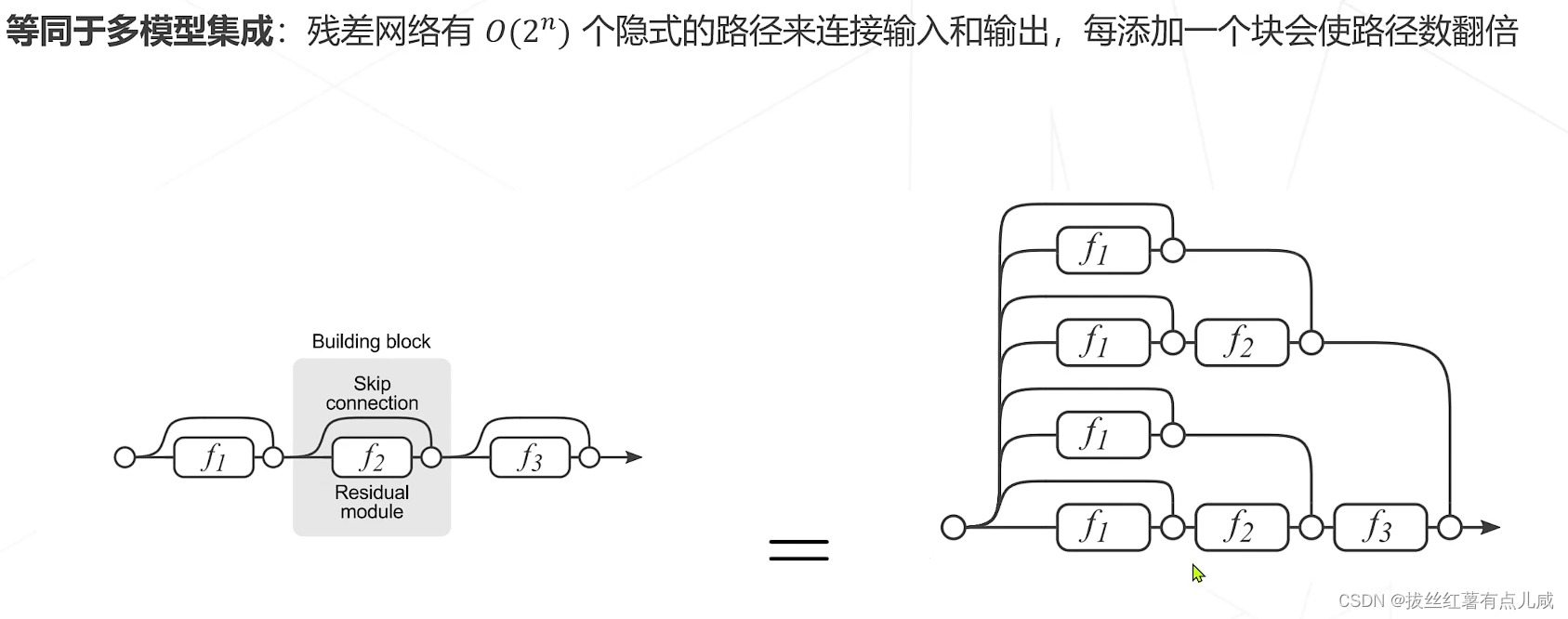
1.ResNet是深浅模型的集成
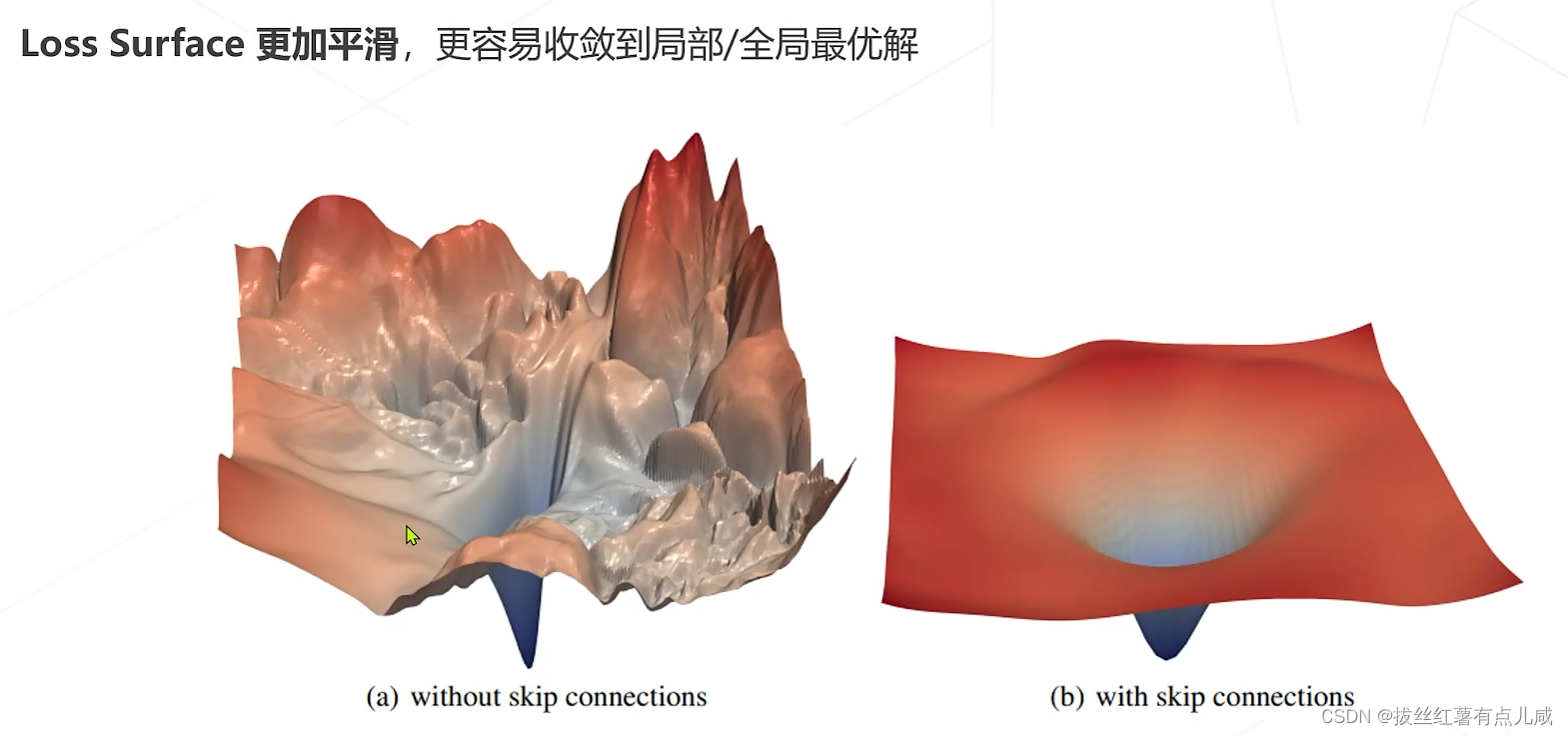
2.残差链接让损失曲面更平滑
3.ResNet后续改进
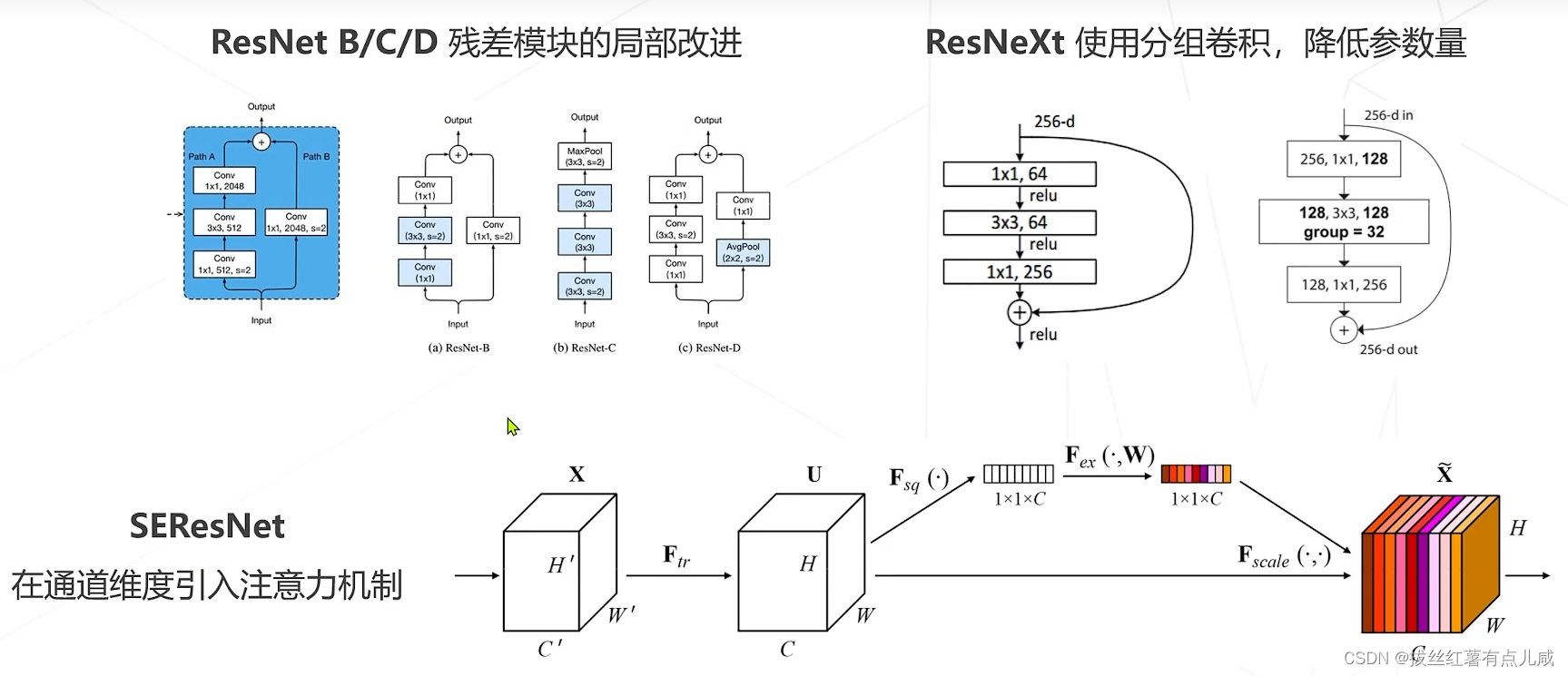
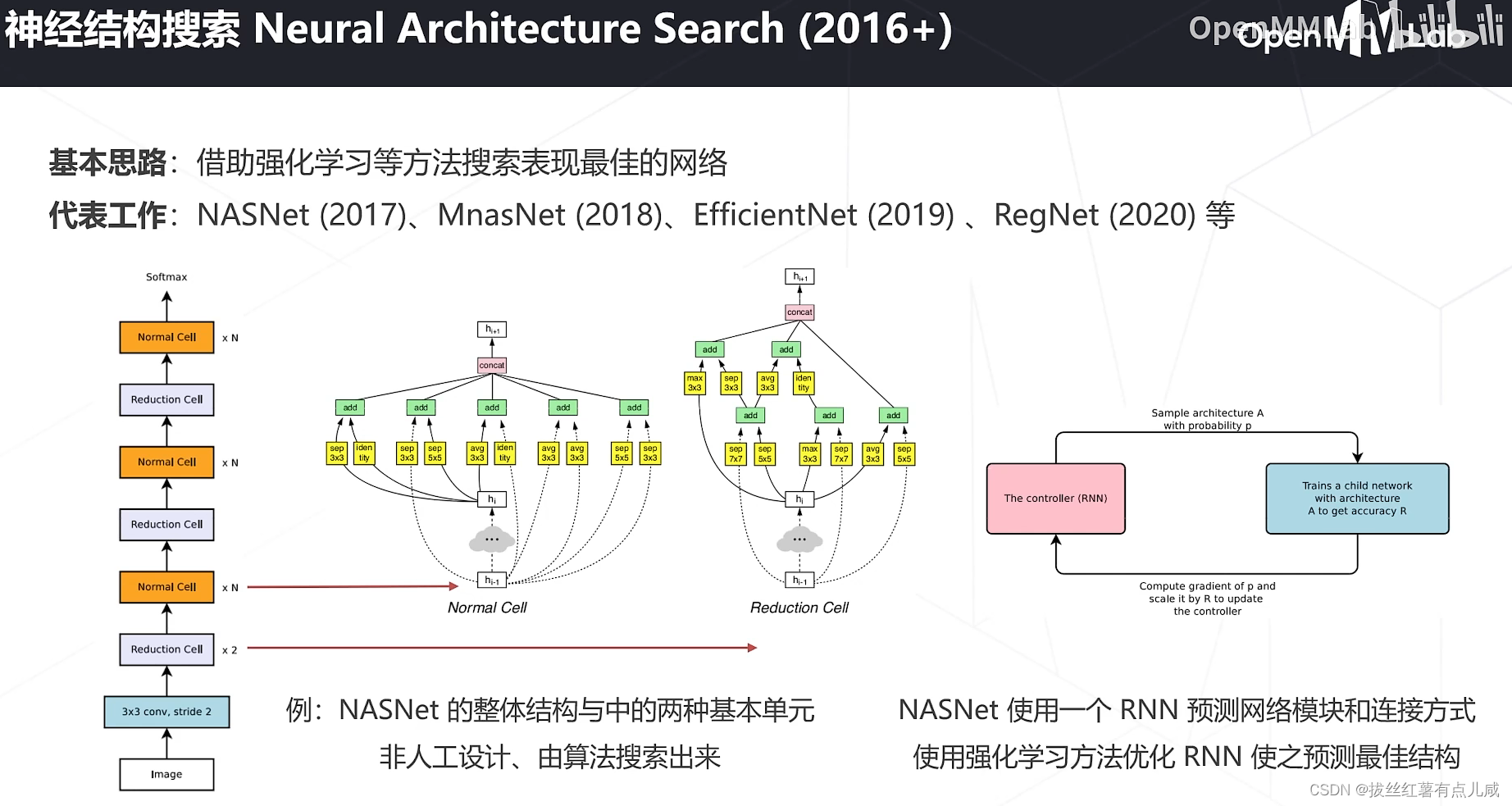
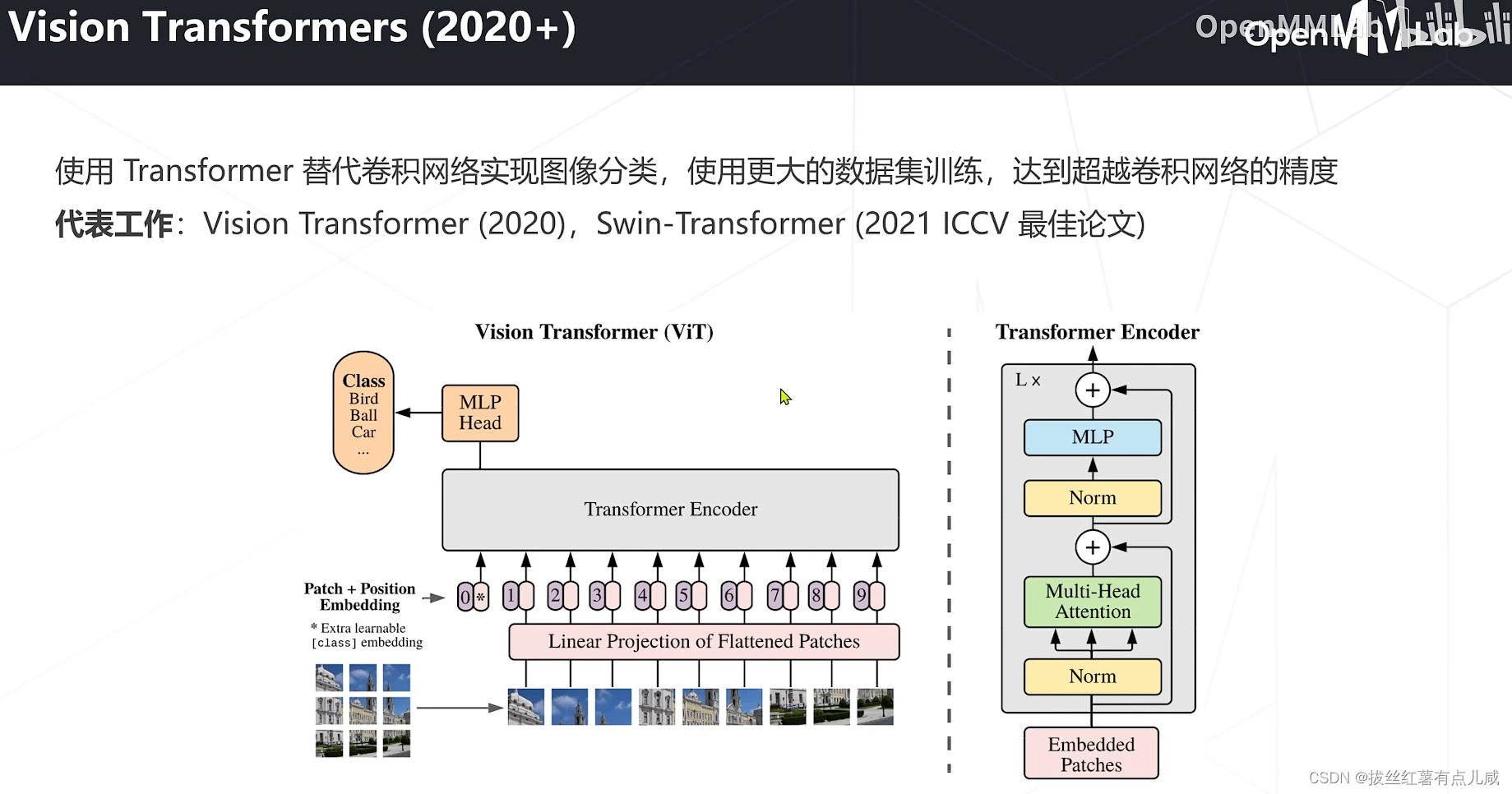
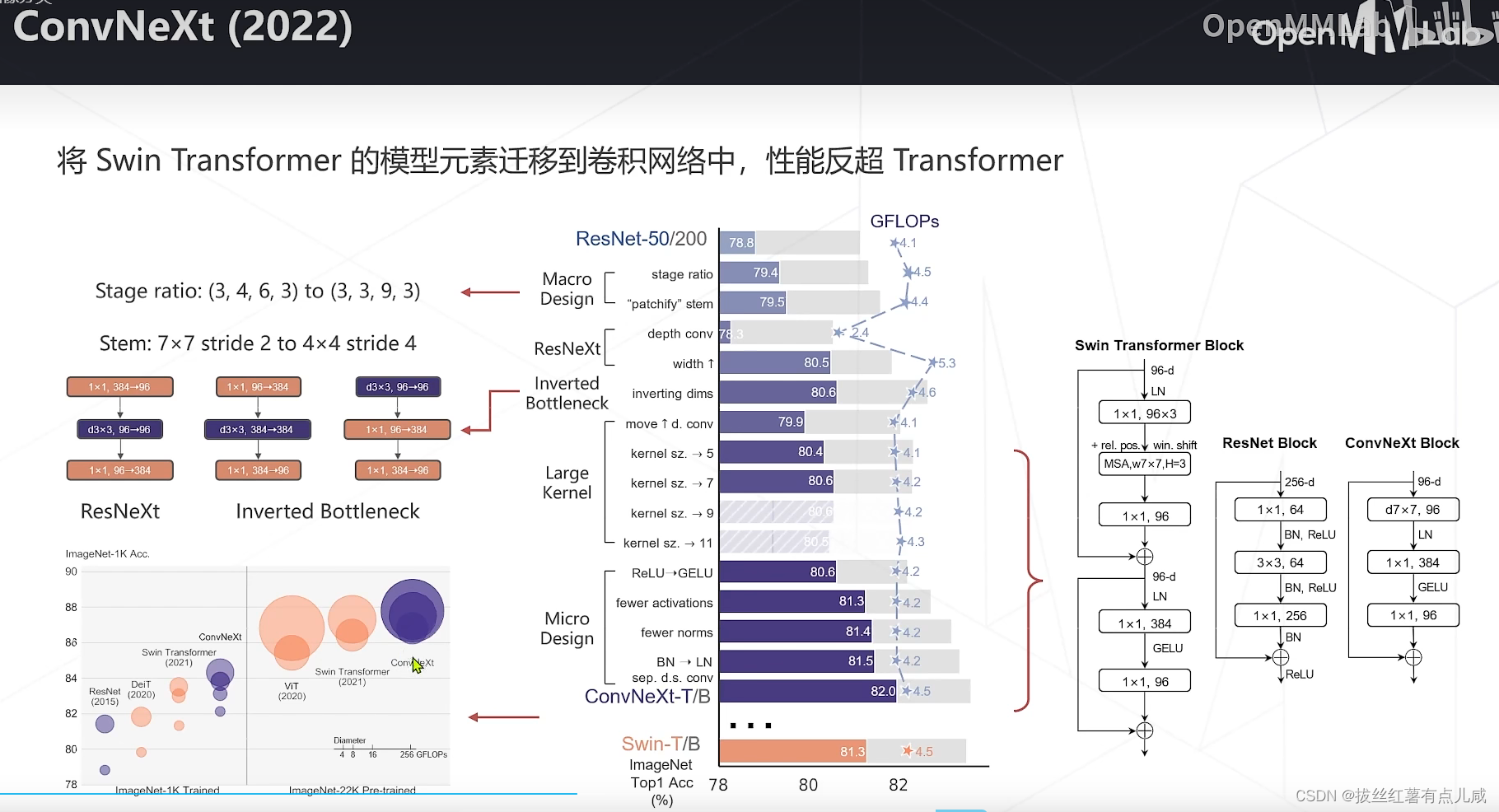
范式未改变,精度有提高。
图像分类&视觉基础模型发展
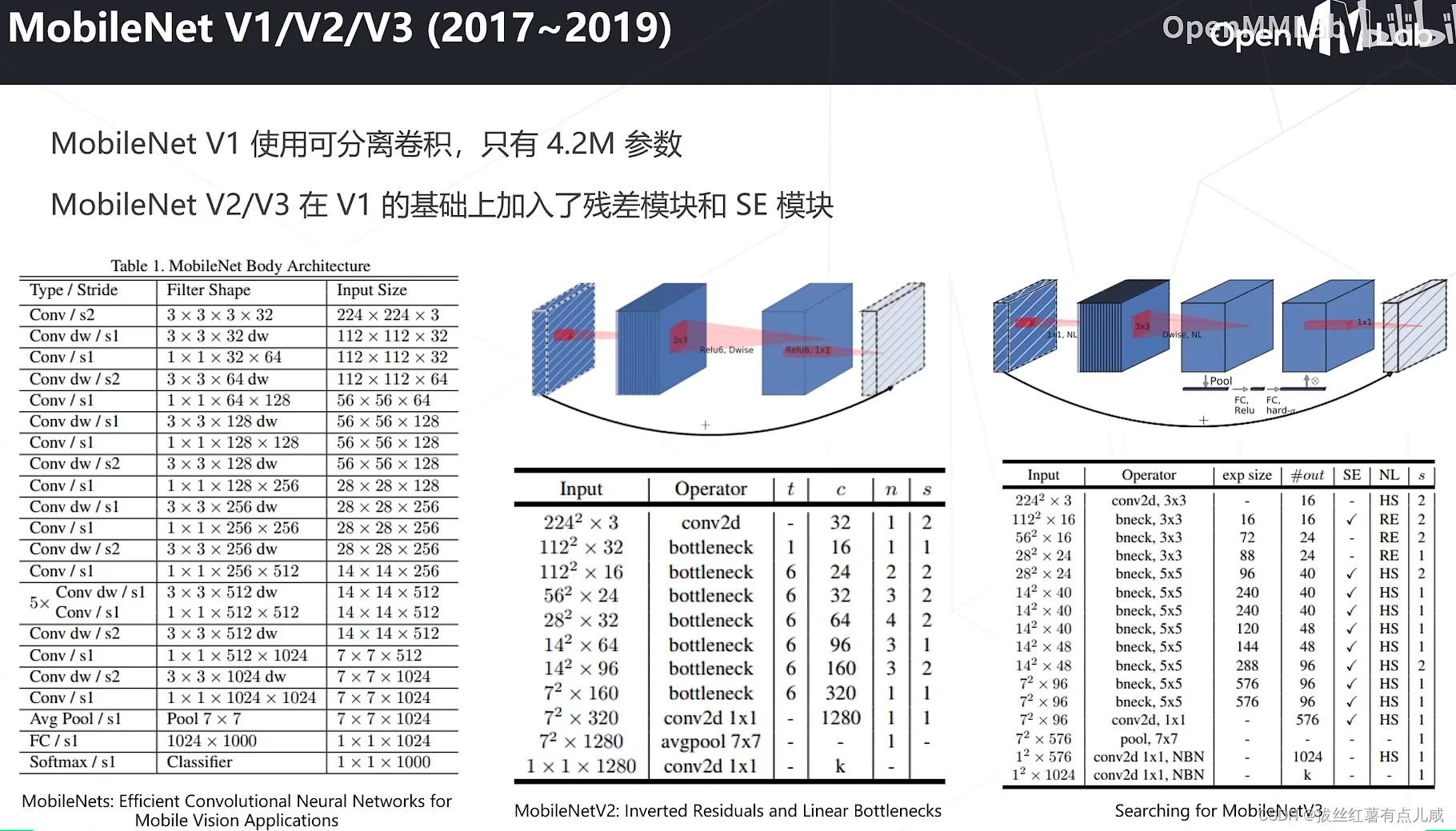
轻量化卷积神经网络
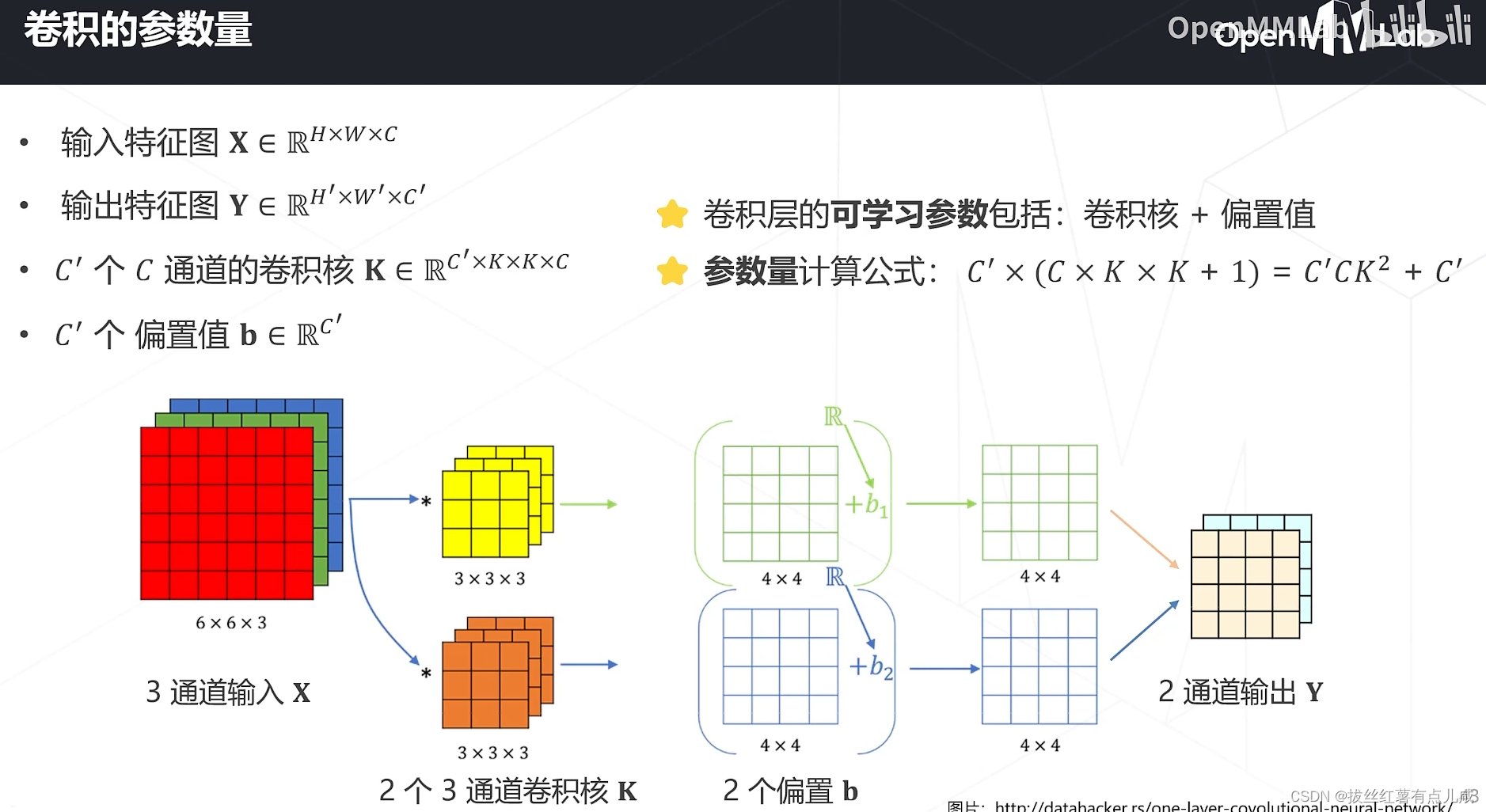
多个多通道

降低模型参数量和计算量的方法

例如:
真正轻量化——可分离卷积
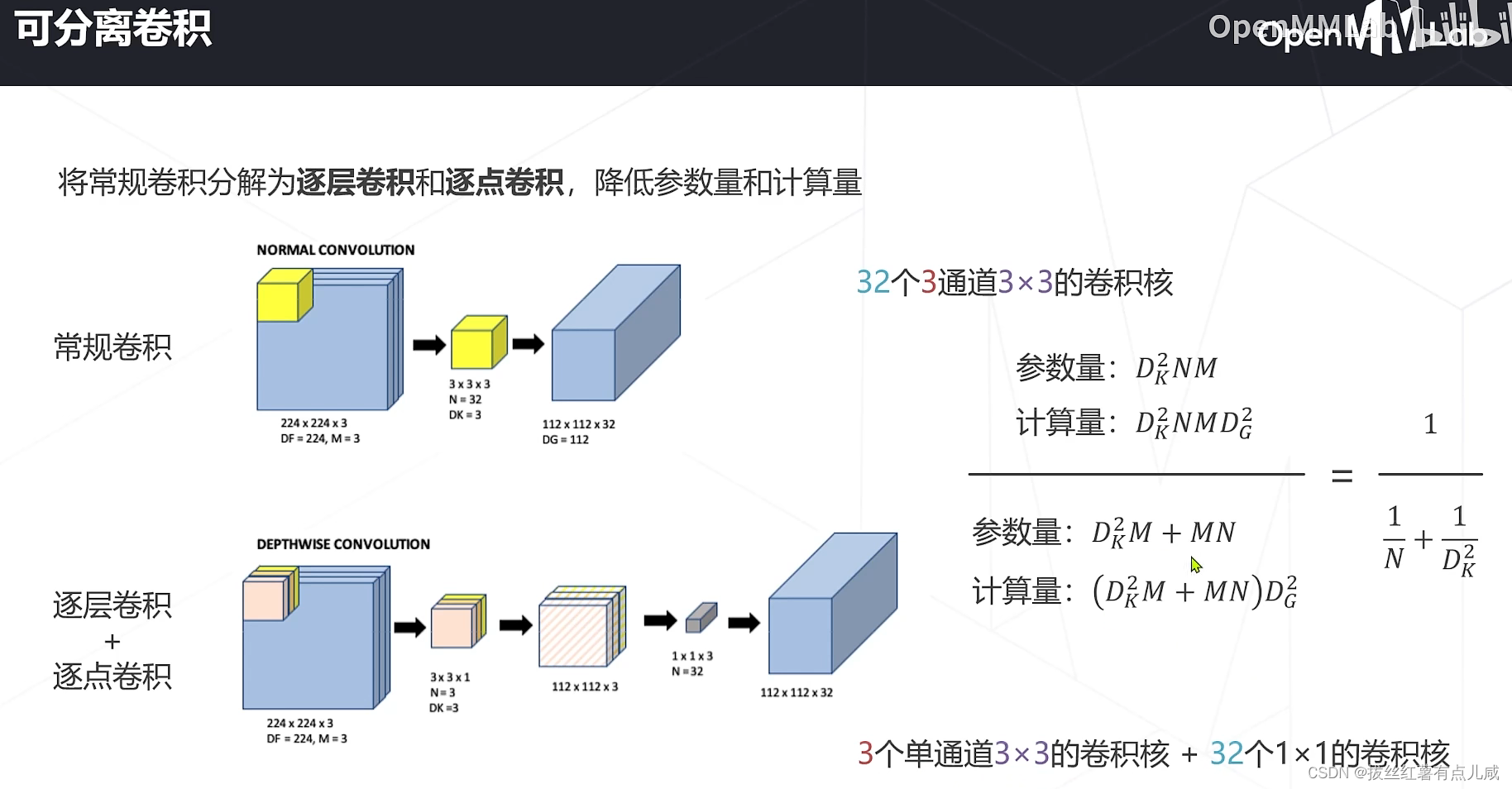
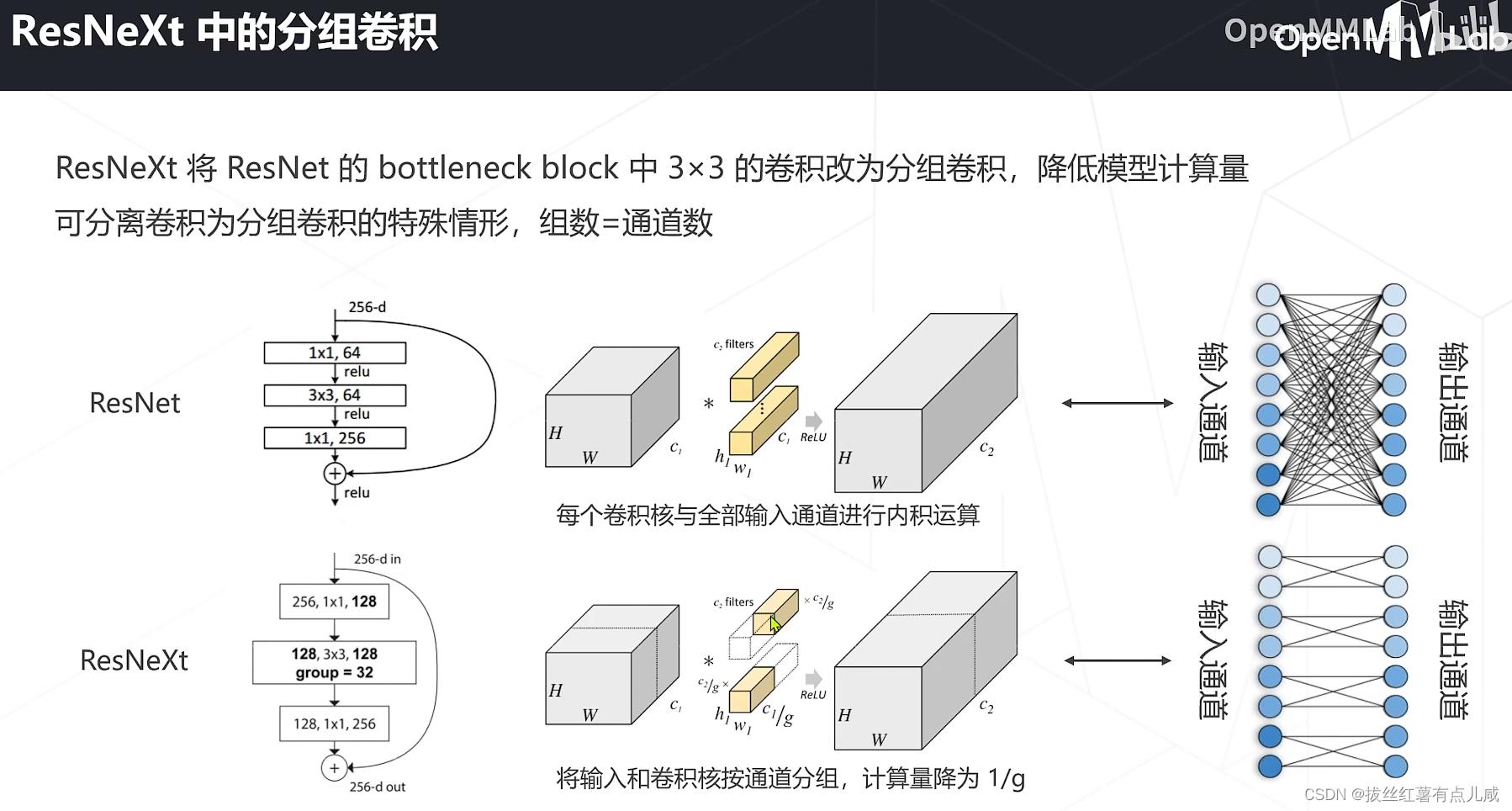
介于可分离卷积和一般卷积中间还有分组卷积
Vision Transformers
自然语言领域发家,后引入图像领域
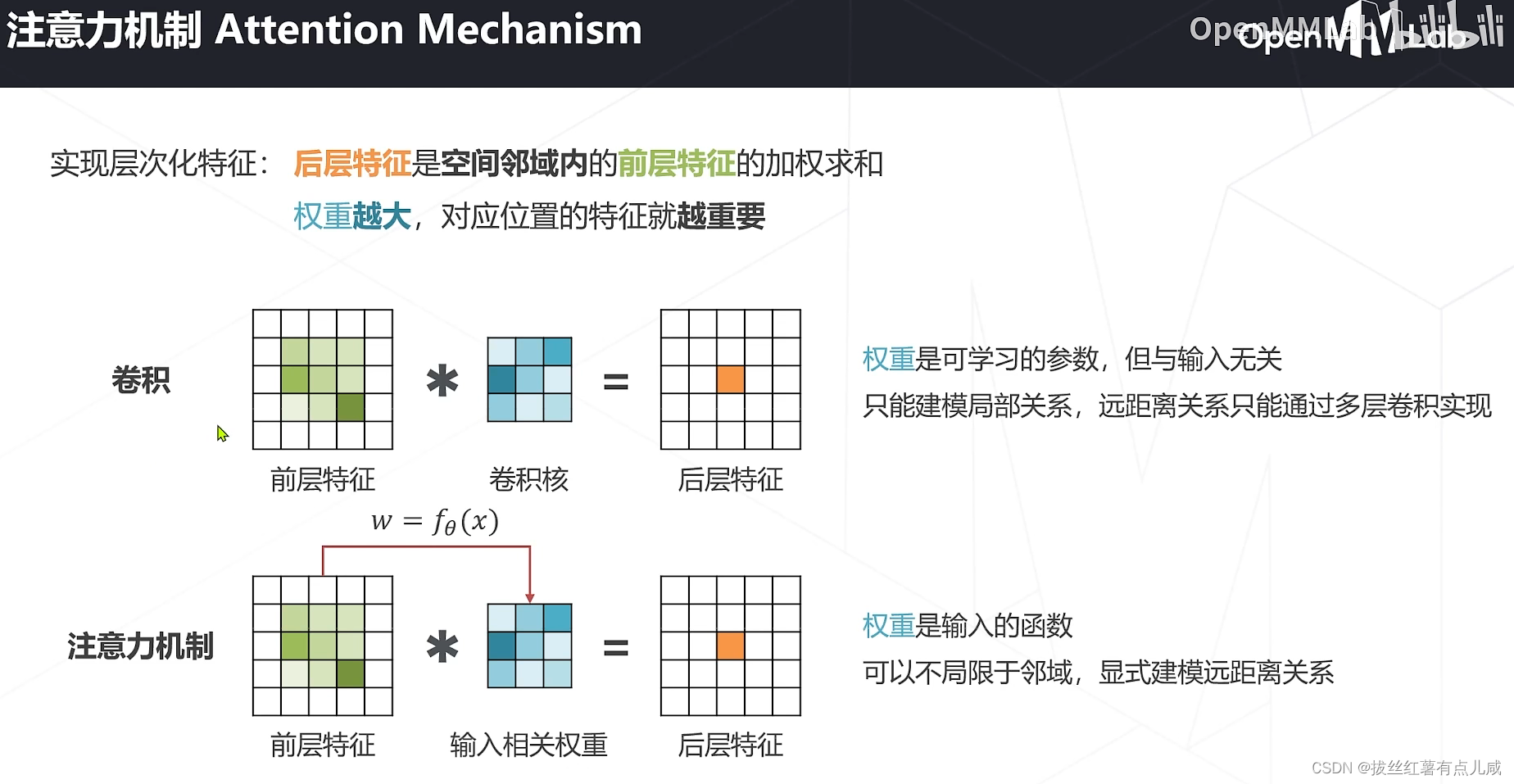
之前卷积里特征是常数,注意力机制中特征是输入的函数。
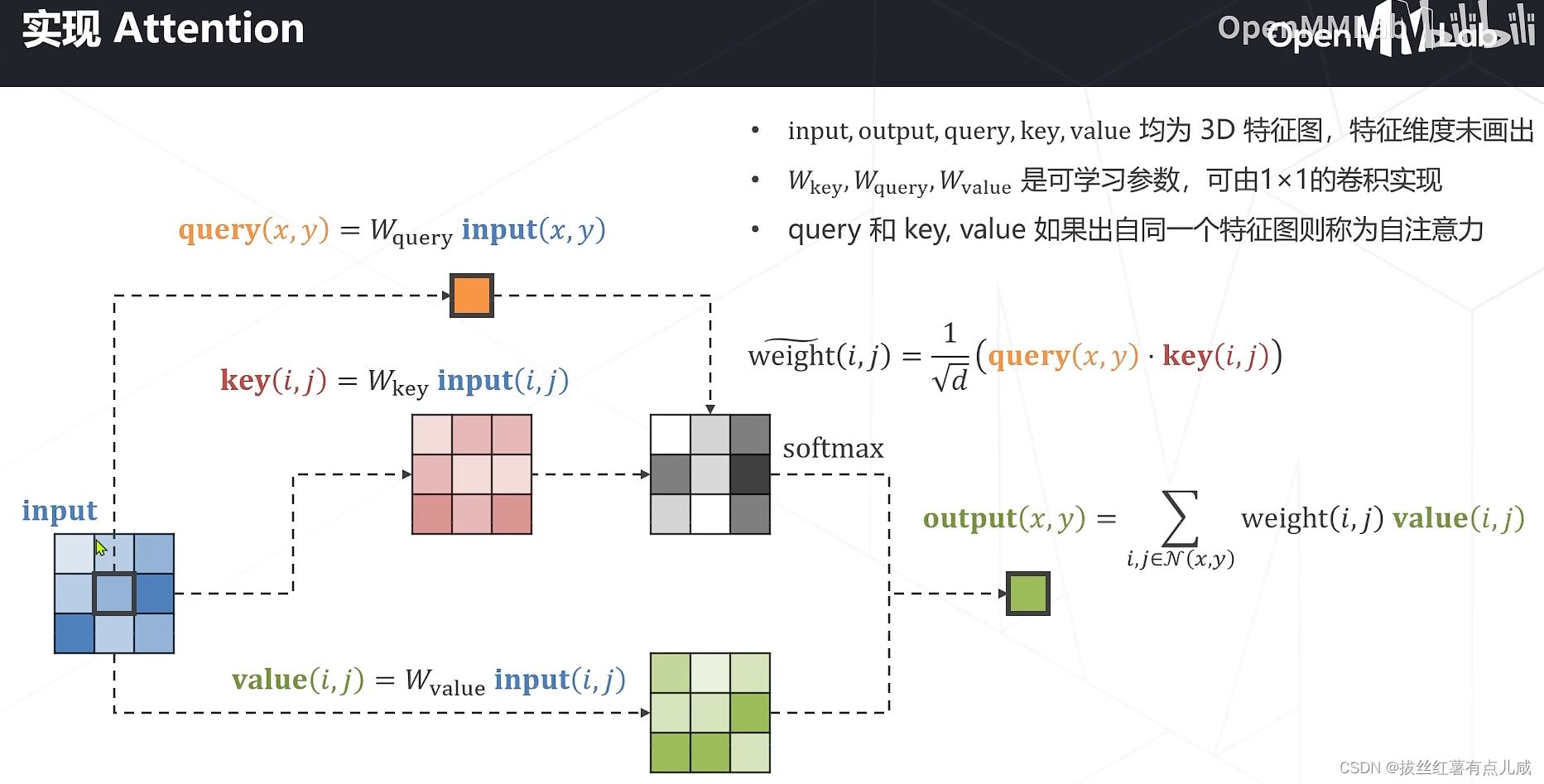
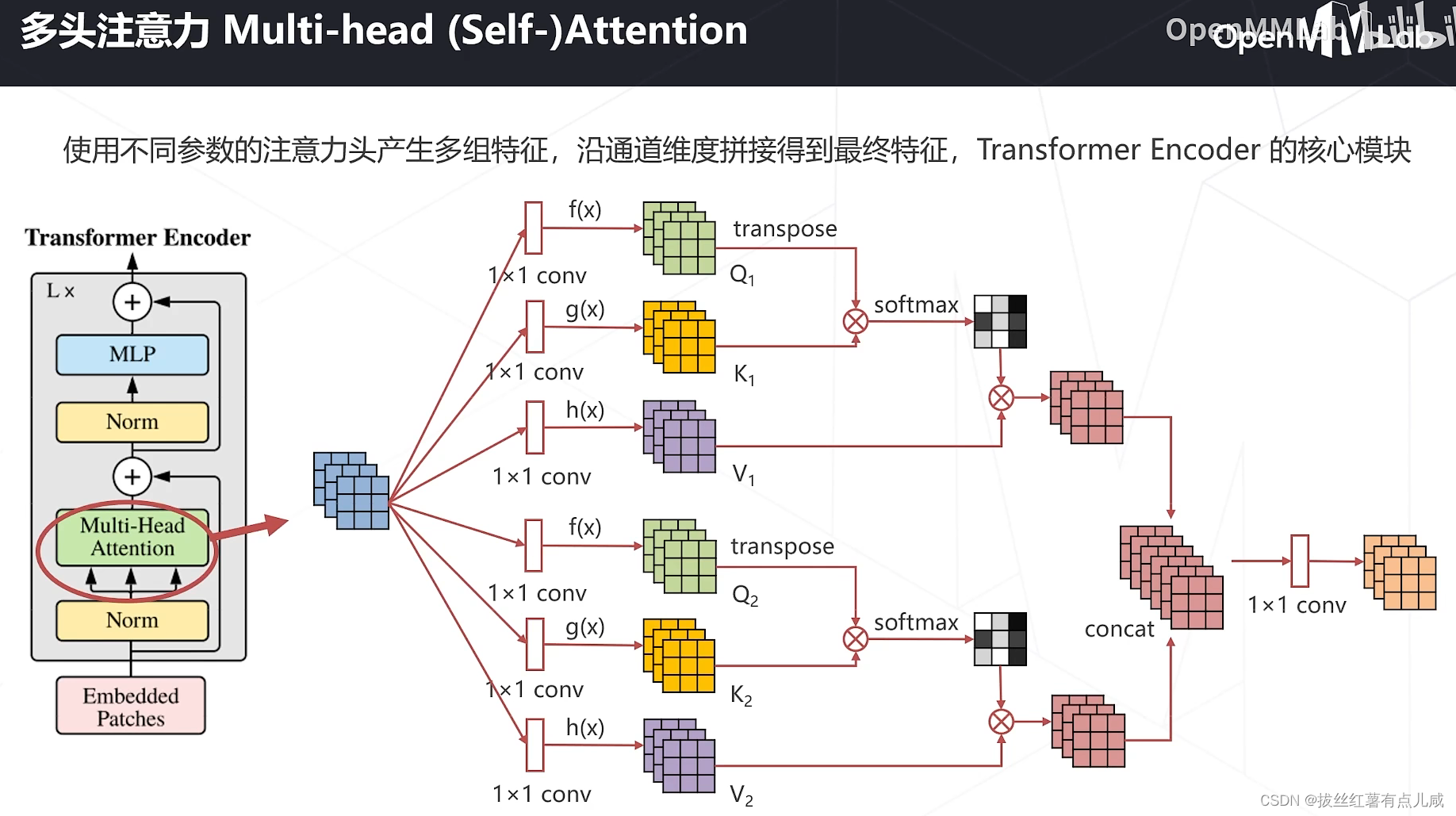
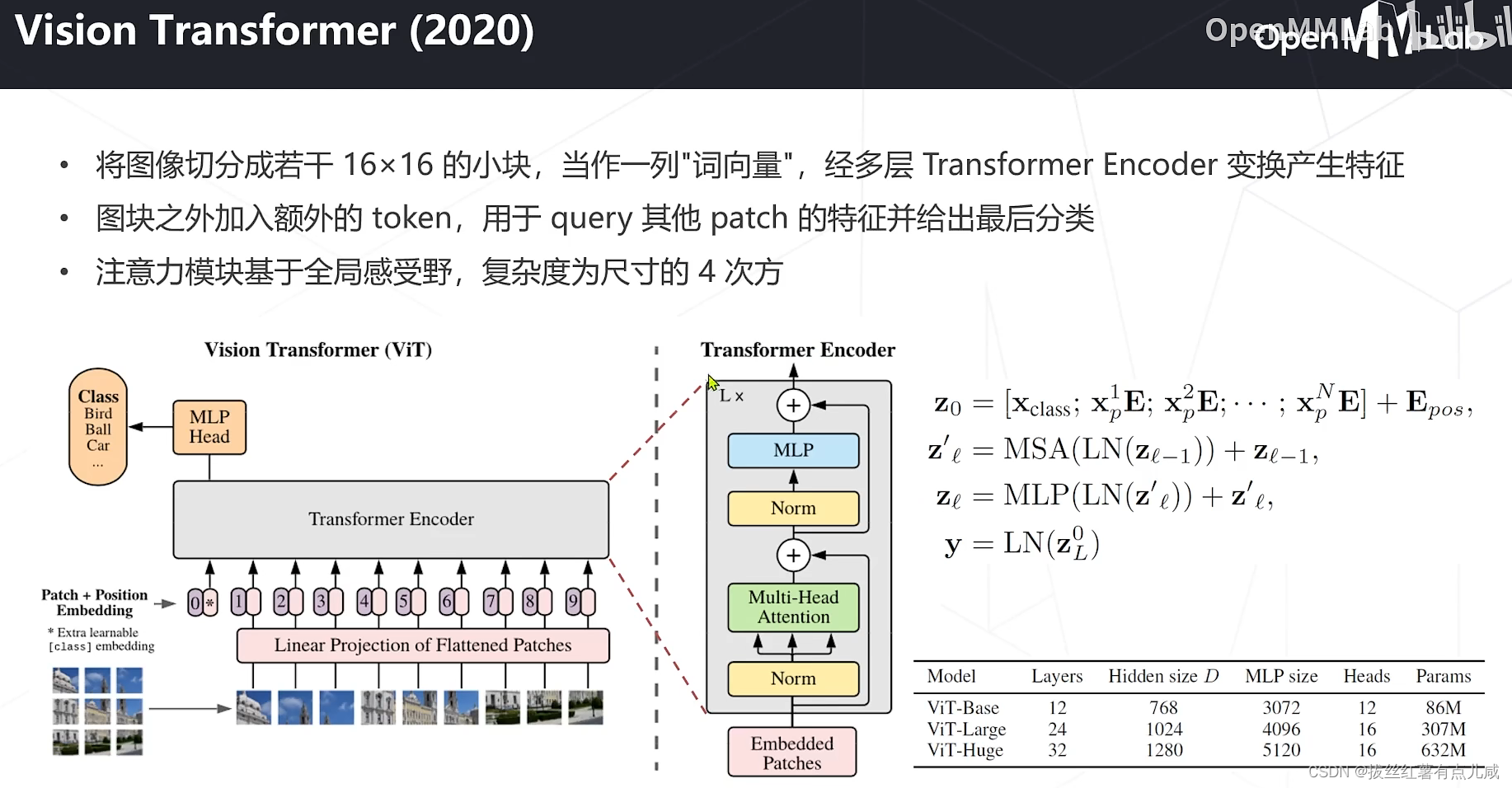

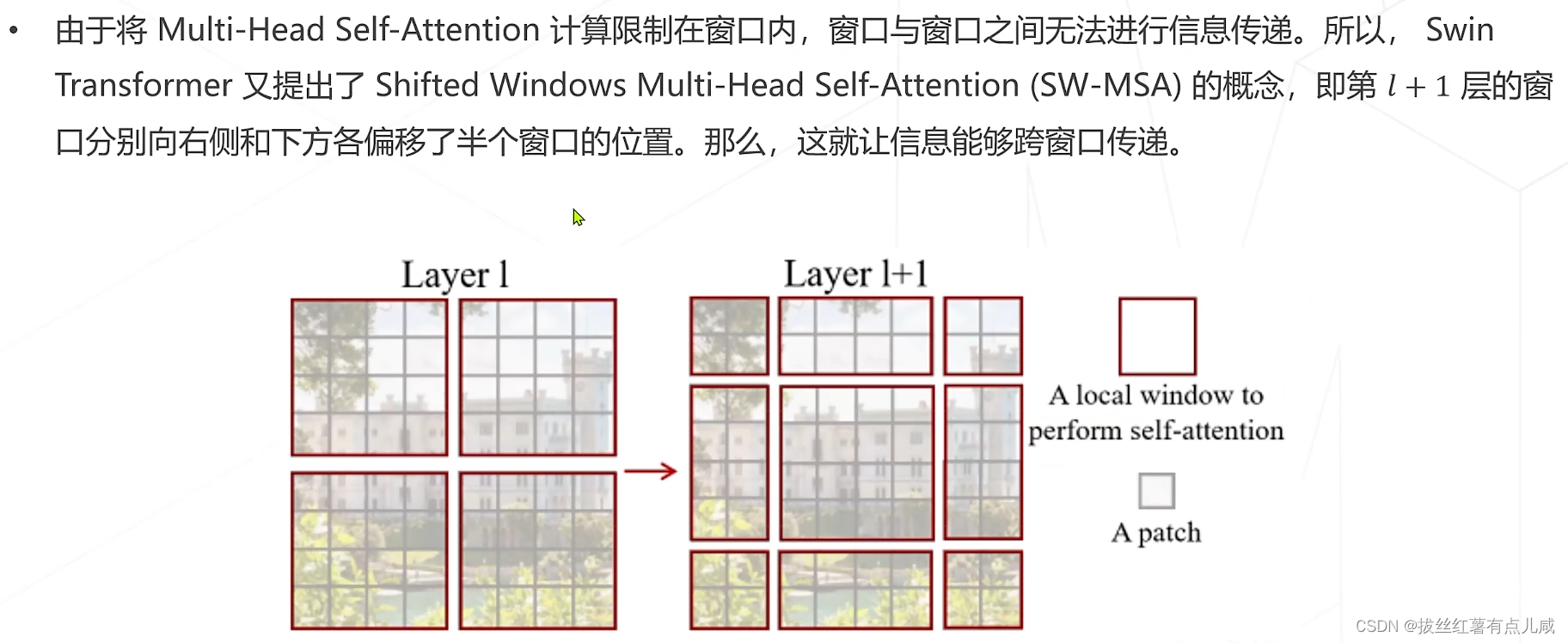

模型学习

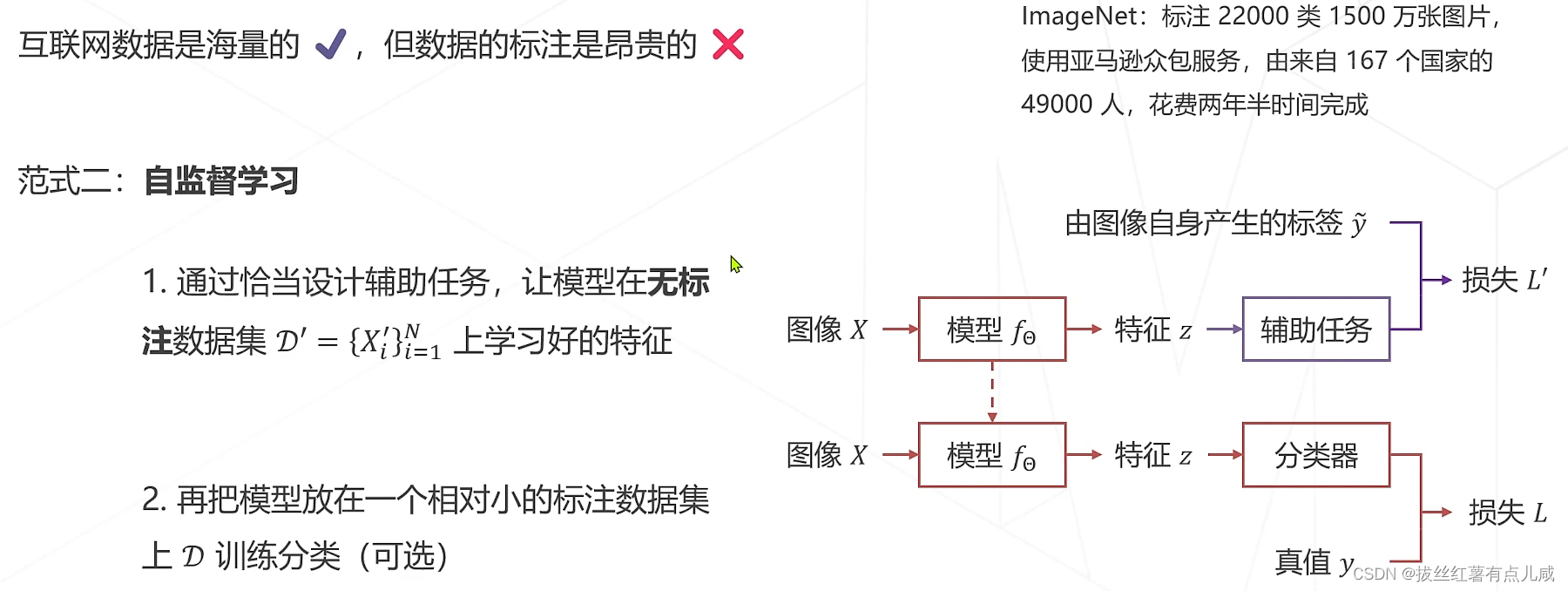
监督学习


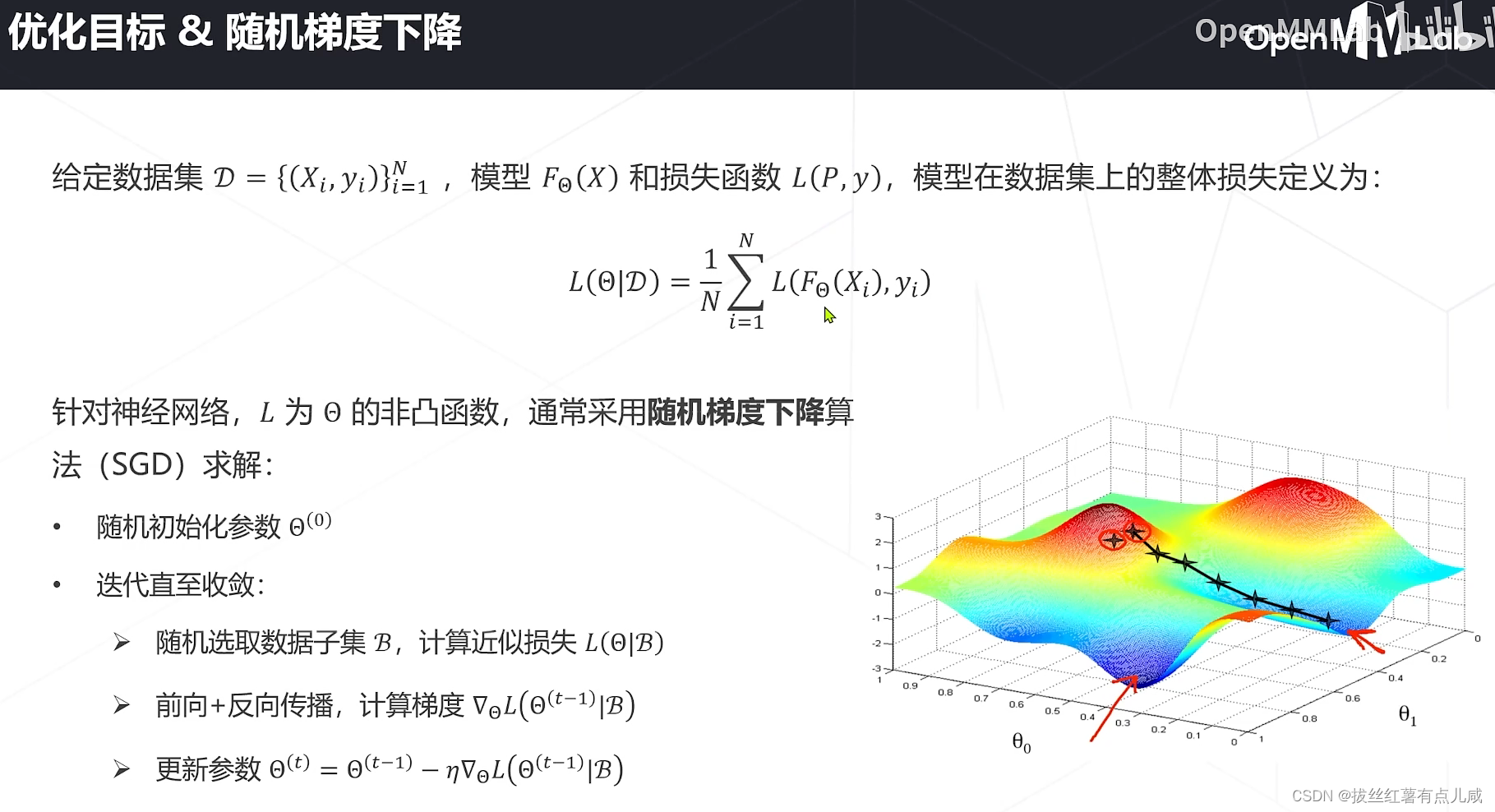
基于梯度下降训练神经网络的整体流程
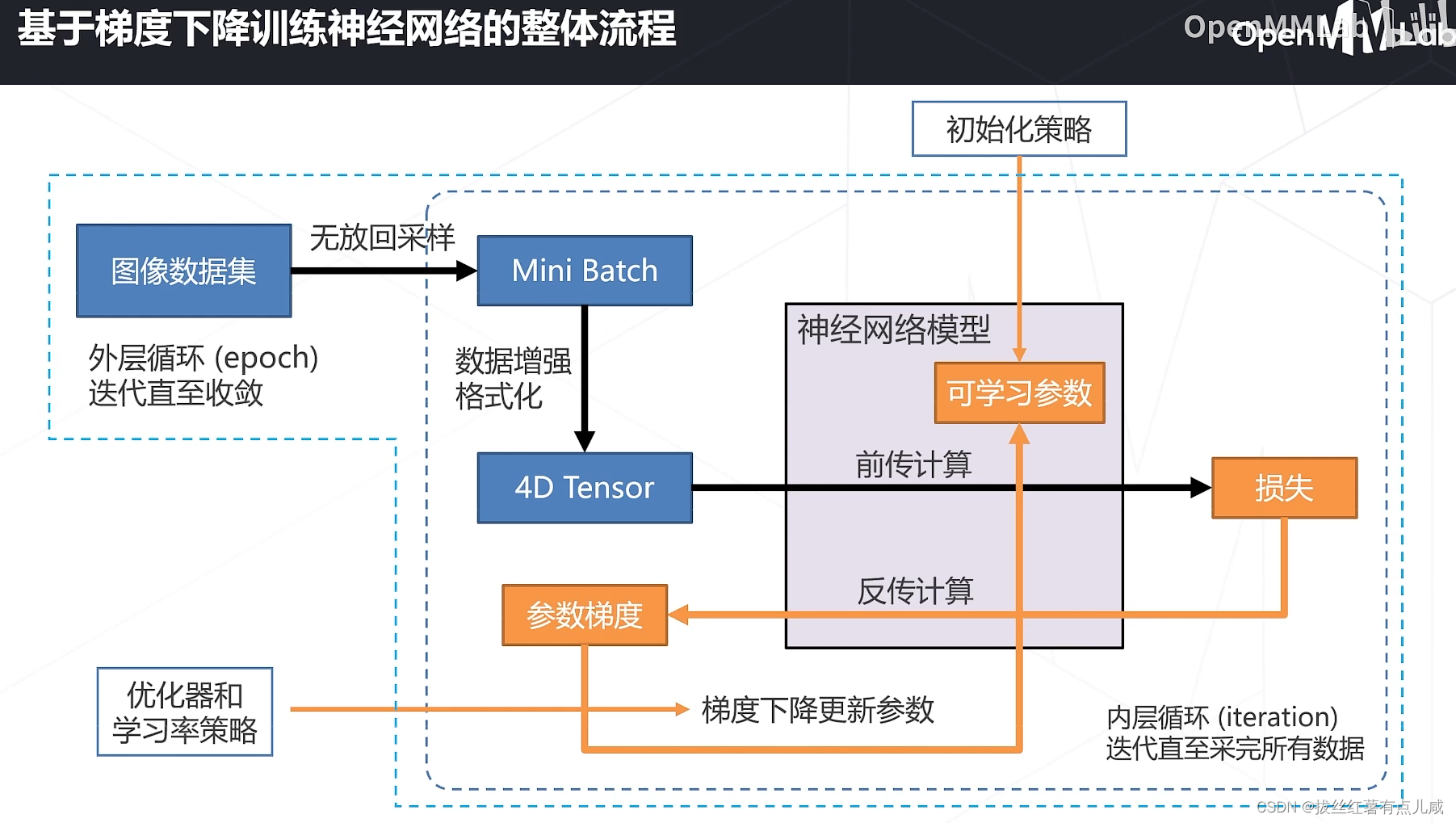
初始化参数,从数据集中采集一个batch(无放回采样),数据处理(增强等)得到四维数组,前传计算损失,反传计算参数梯度,梯度下降更新参数,用优化器增加一些策略技巧
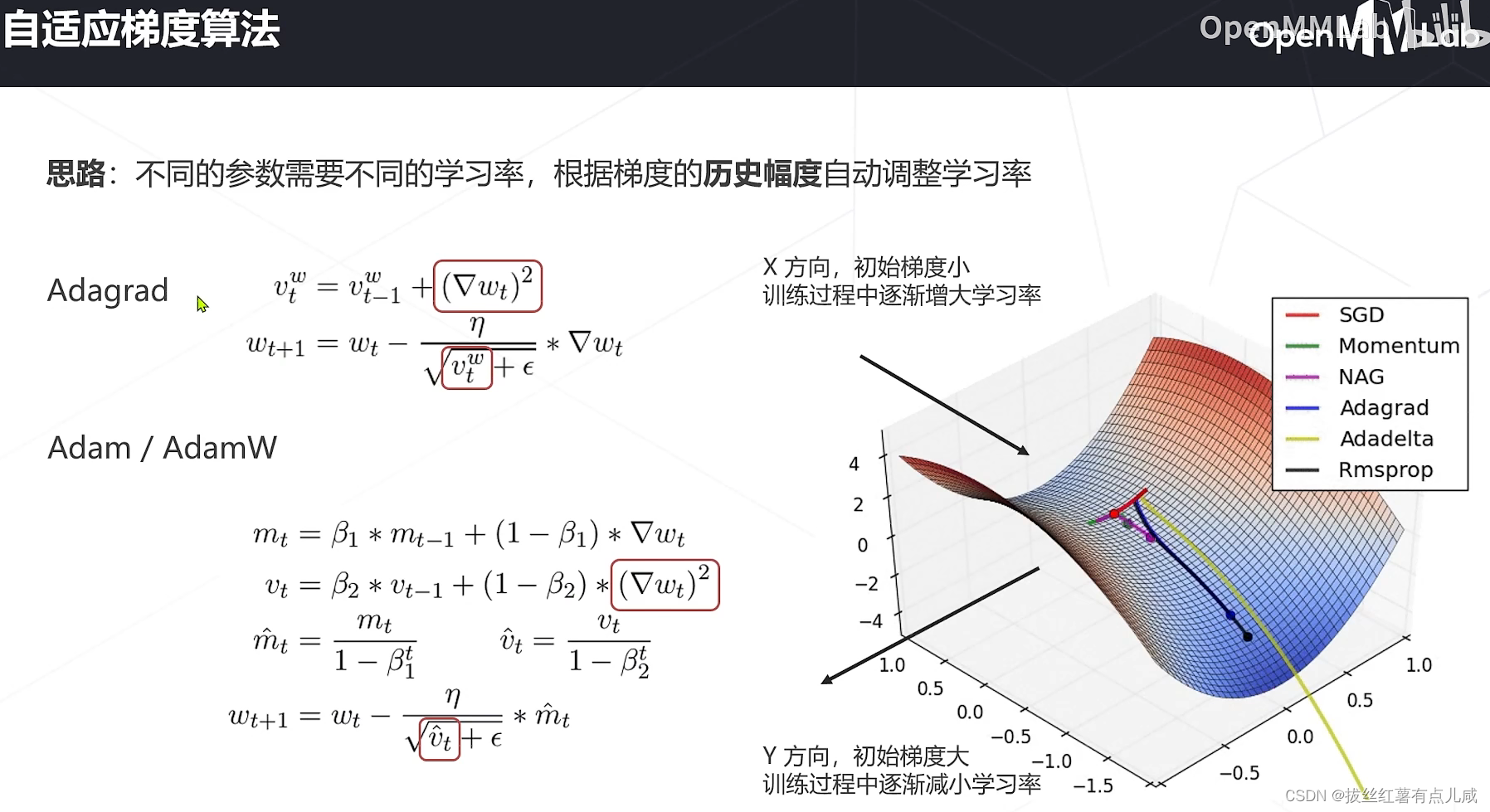
学习率与优化策略

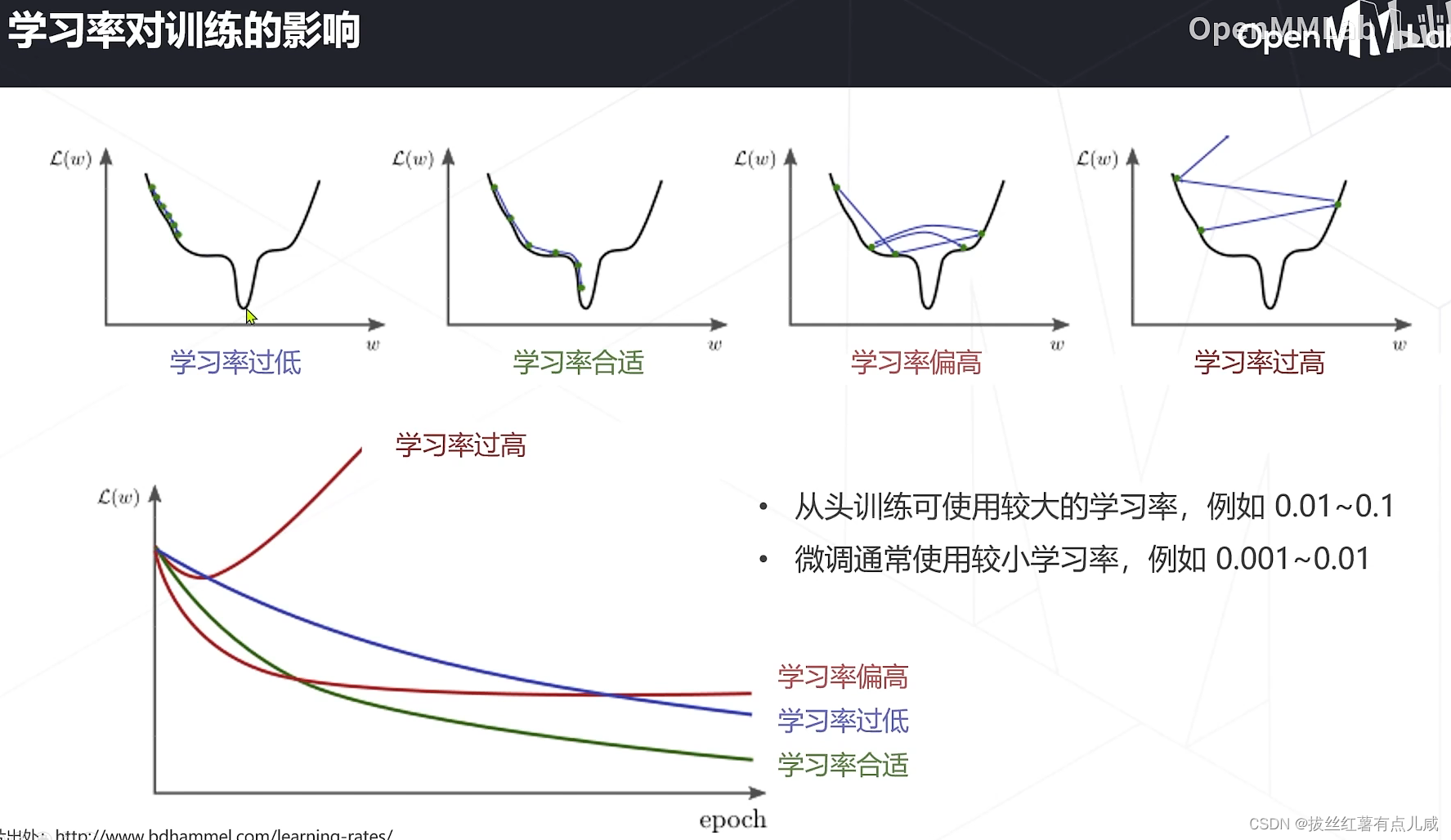
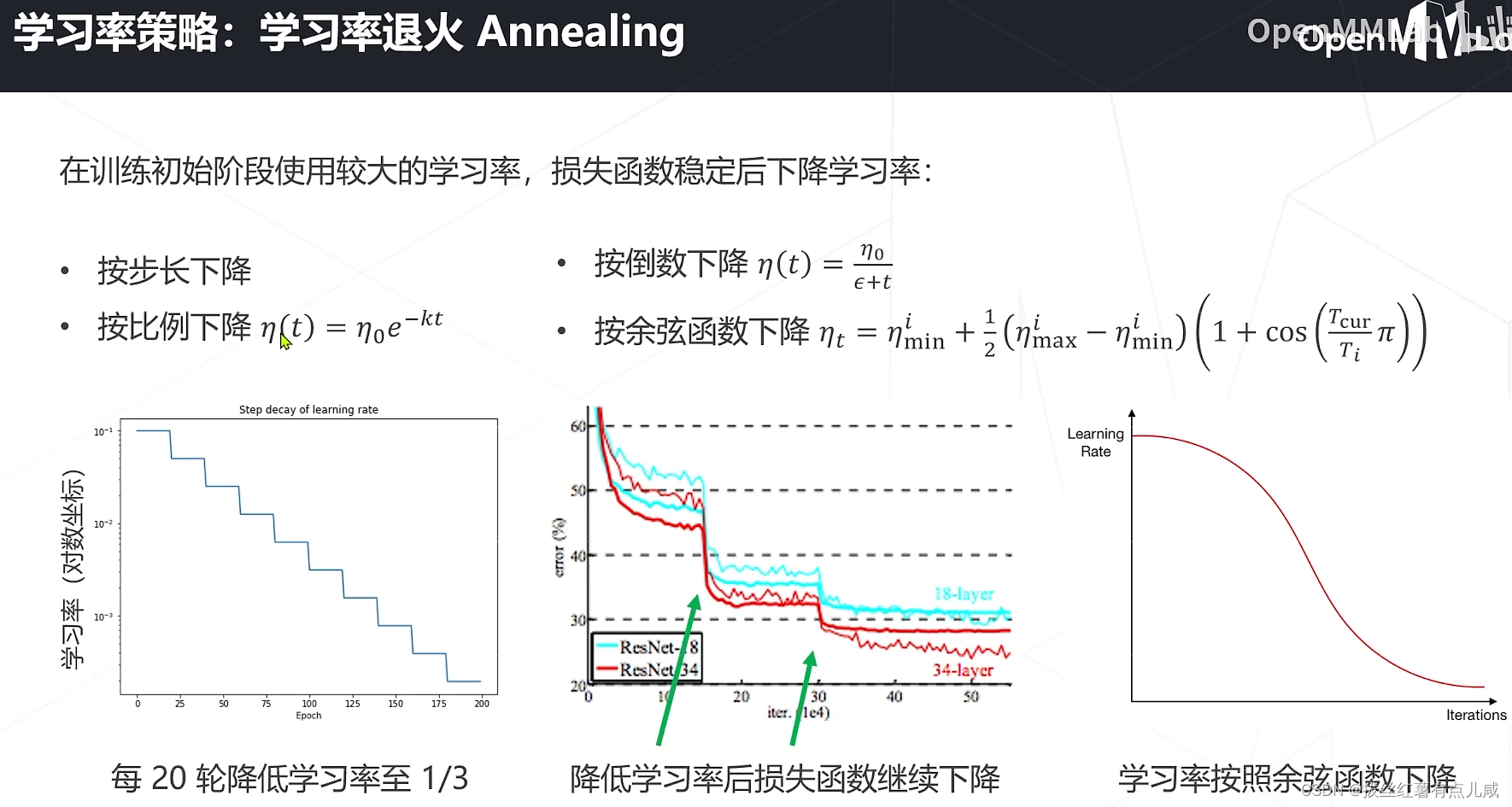
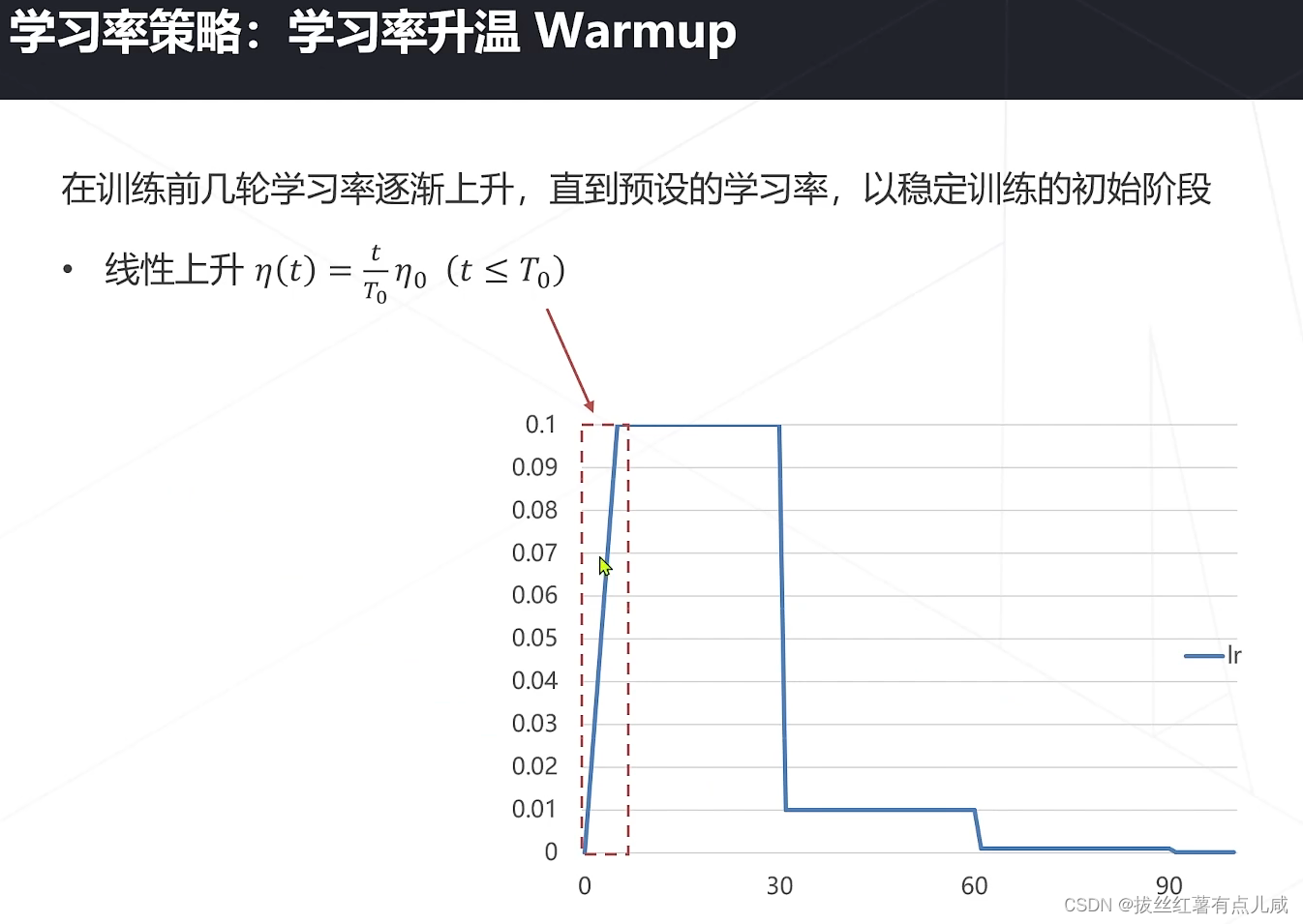

是一个经验结论。

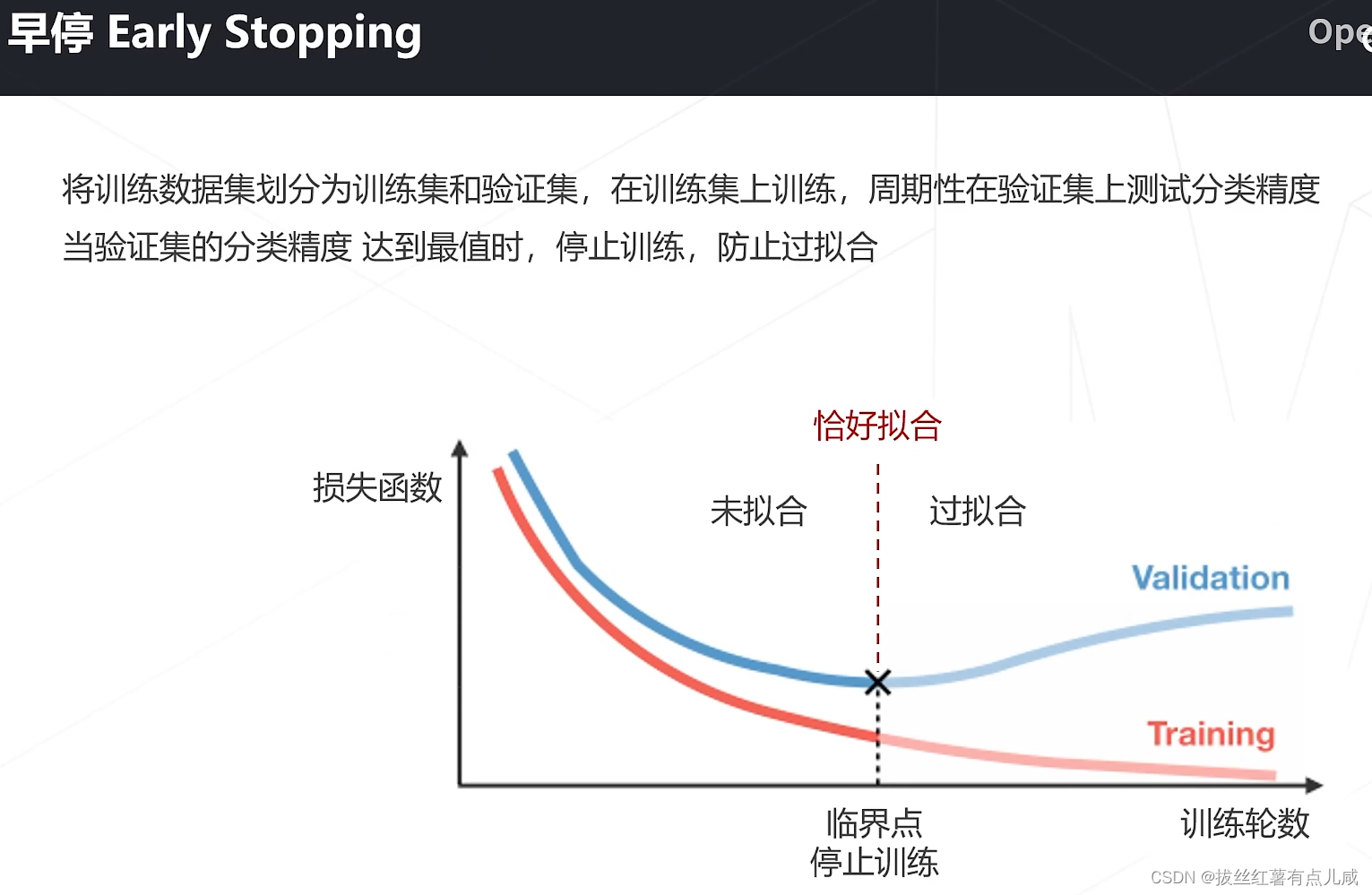
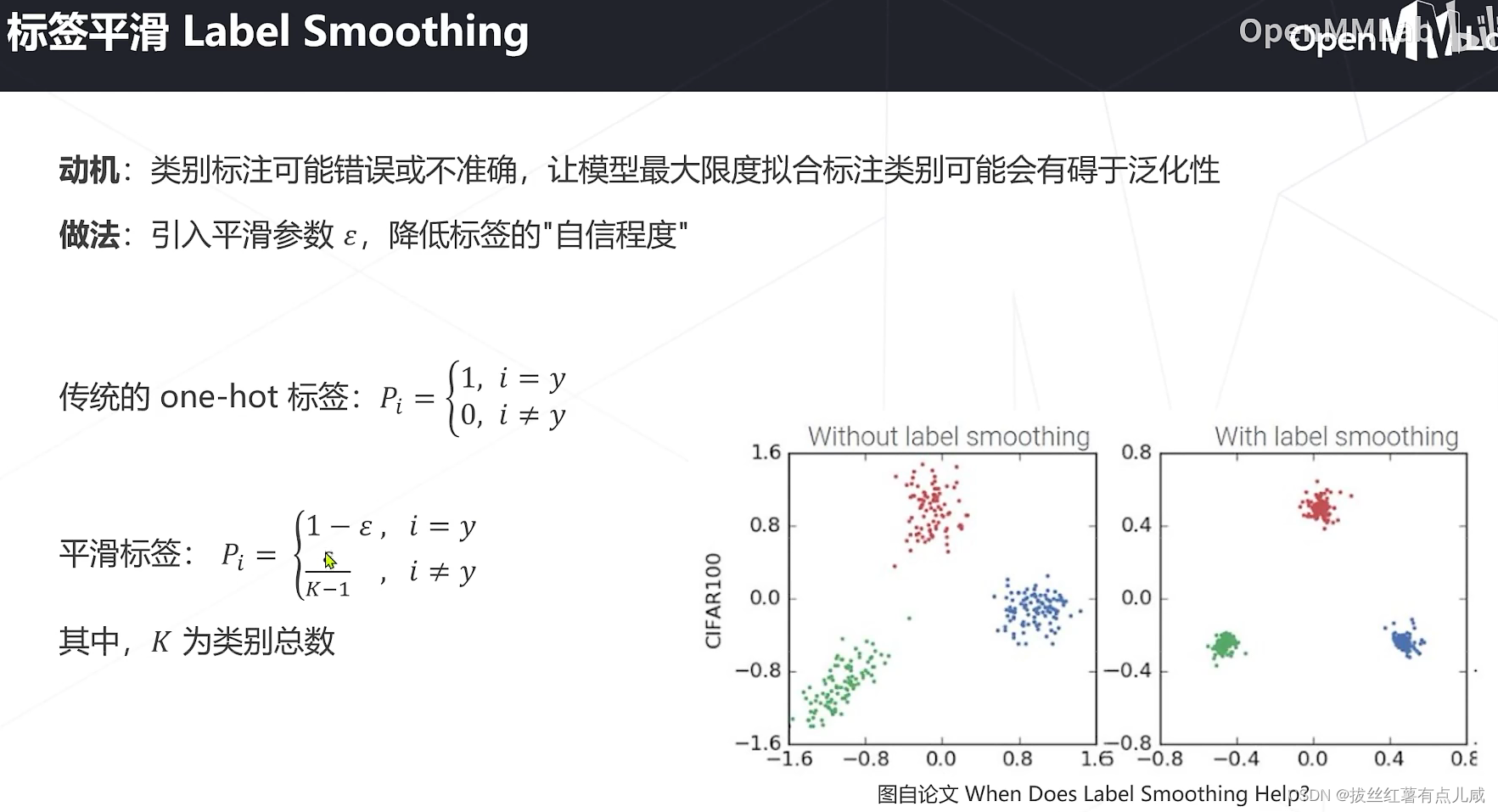
数据增强


像素级别/2
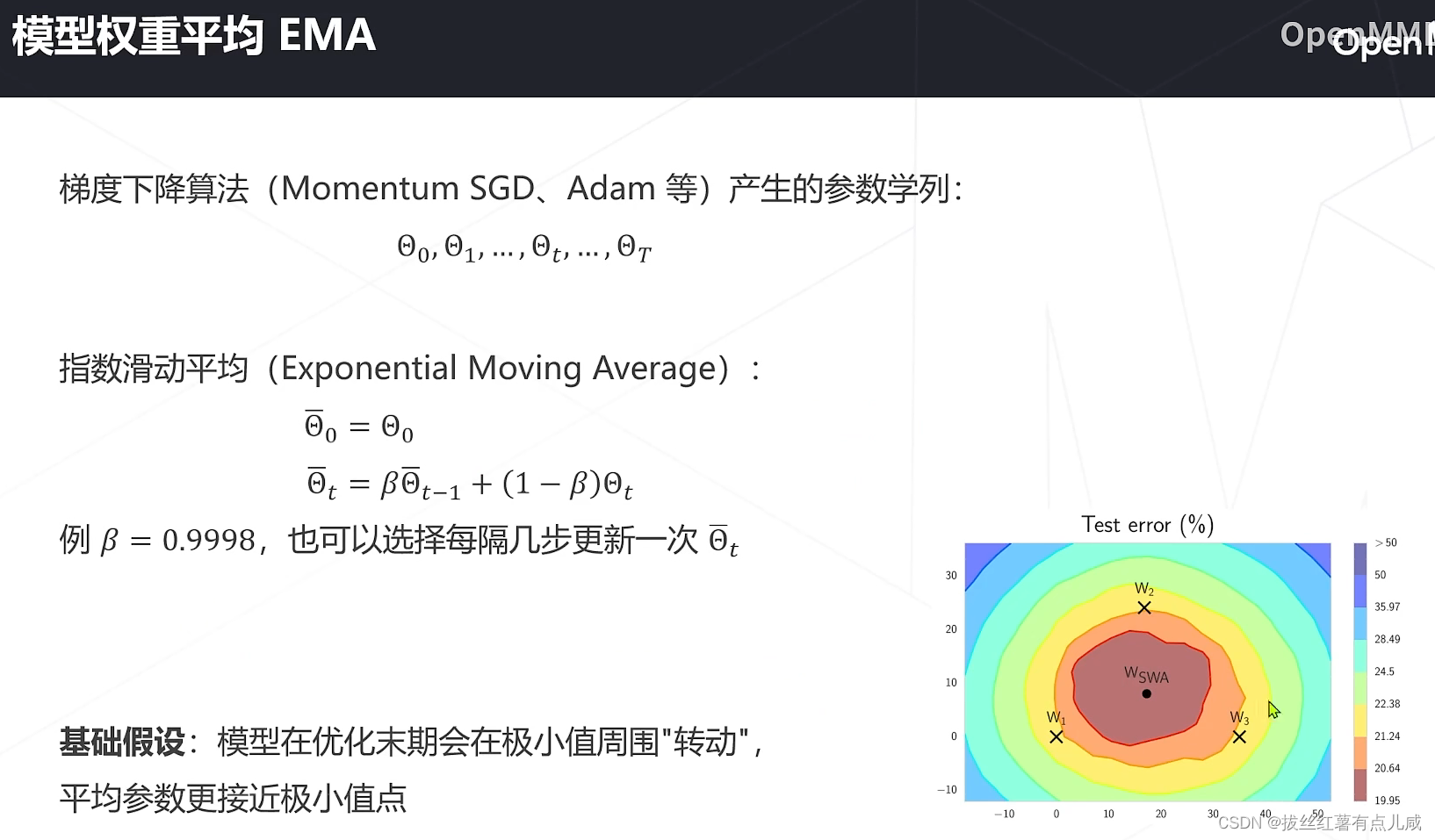
自监督学习
自监督学习:基于无标注的数据学习
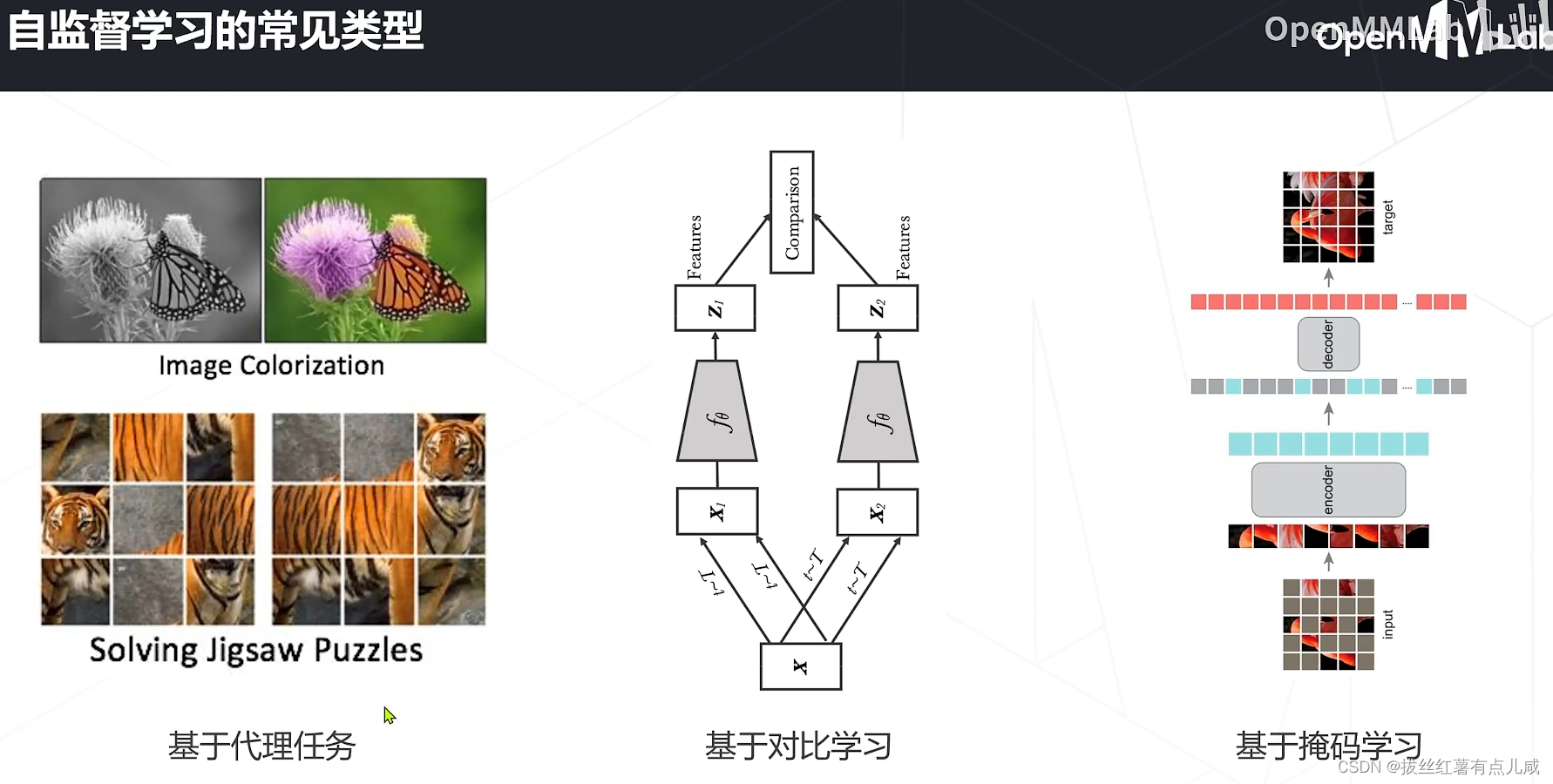
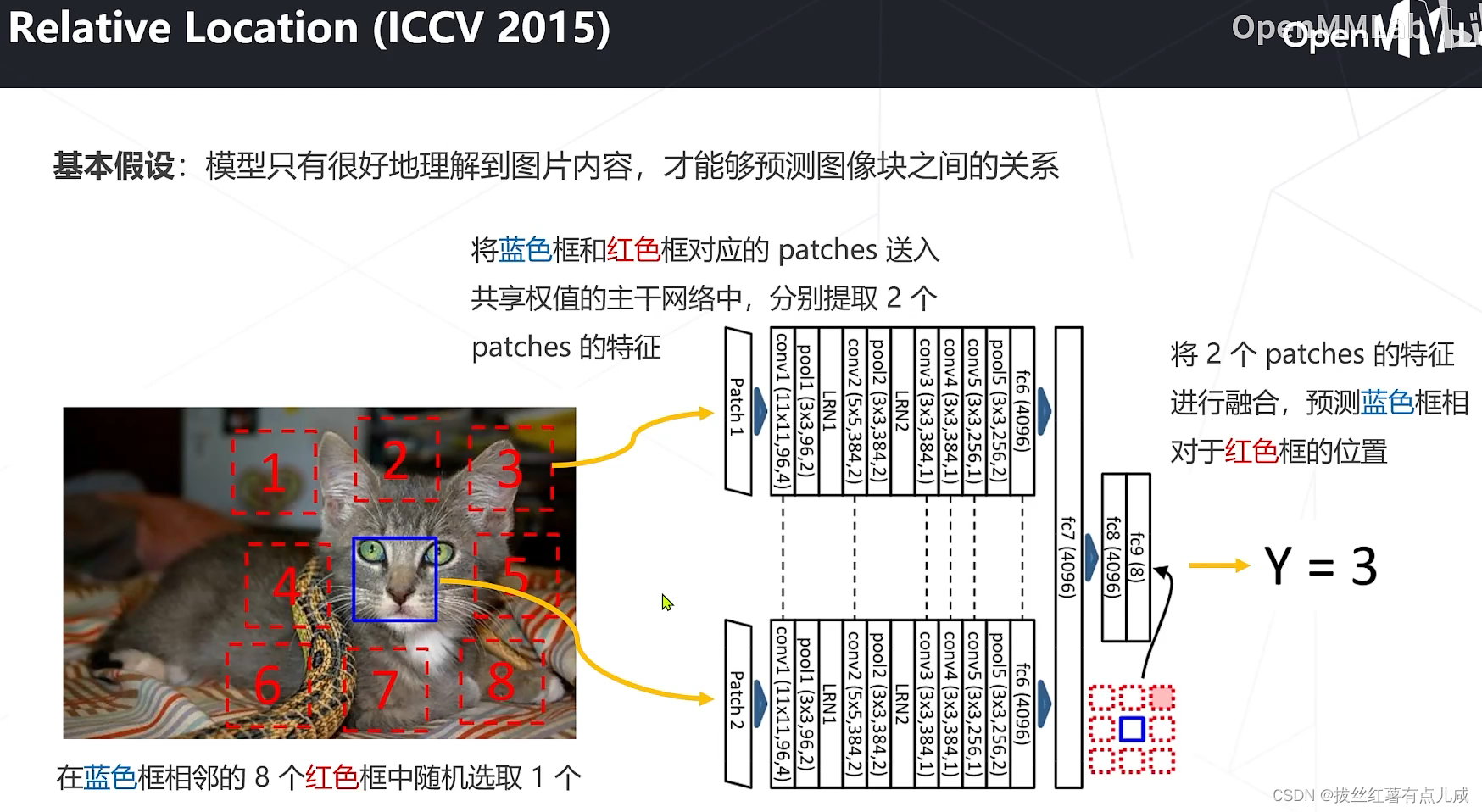
基于代理任务
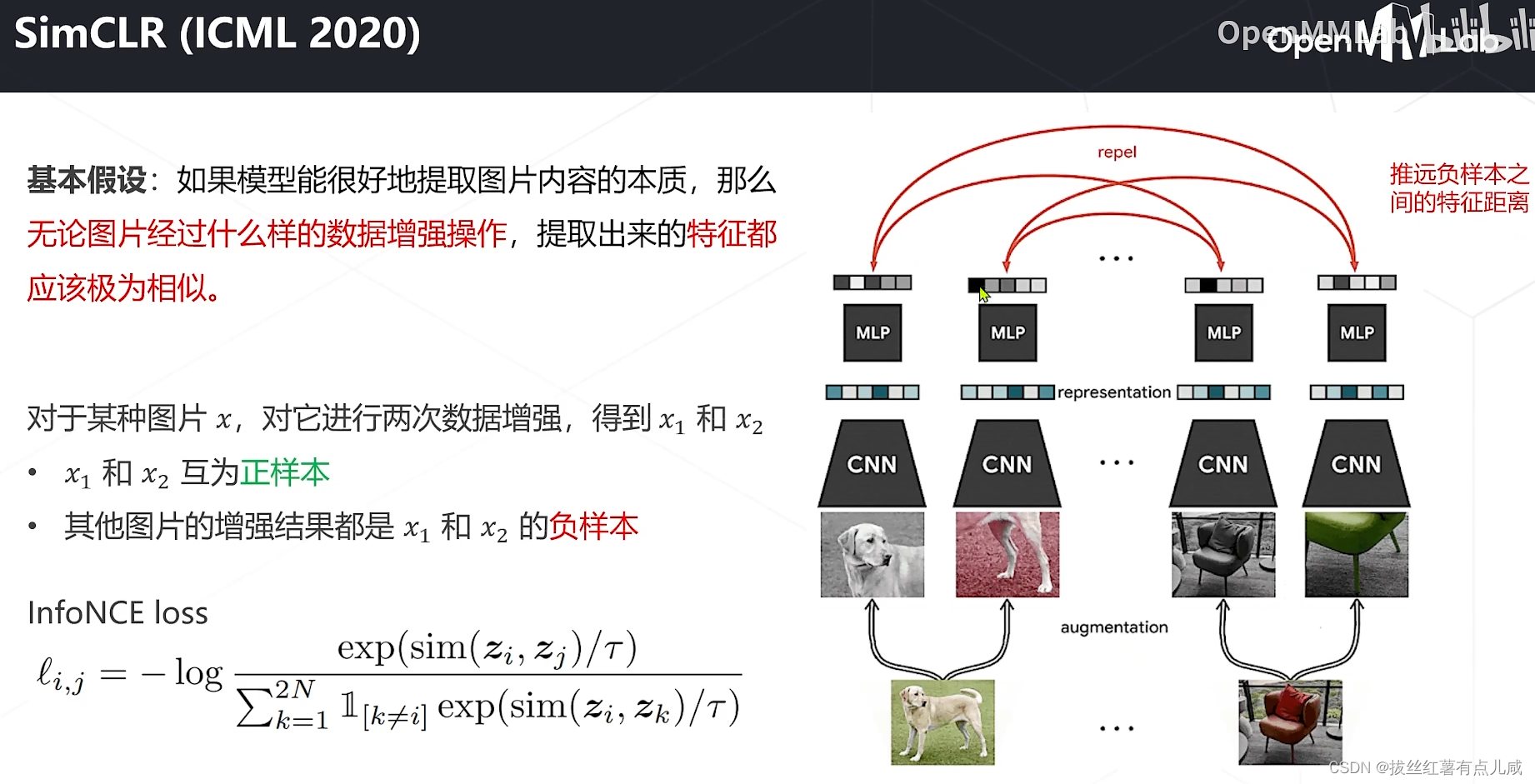
基于对比学习
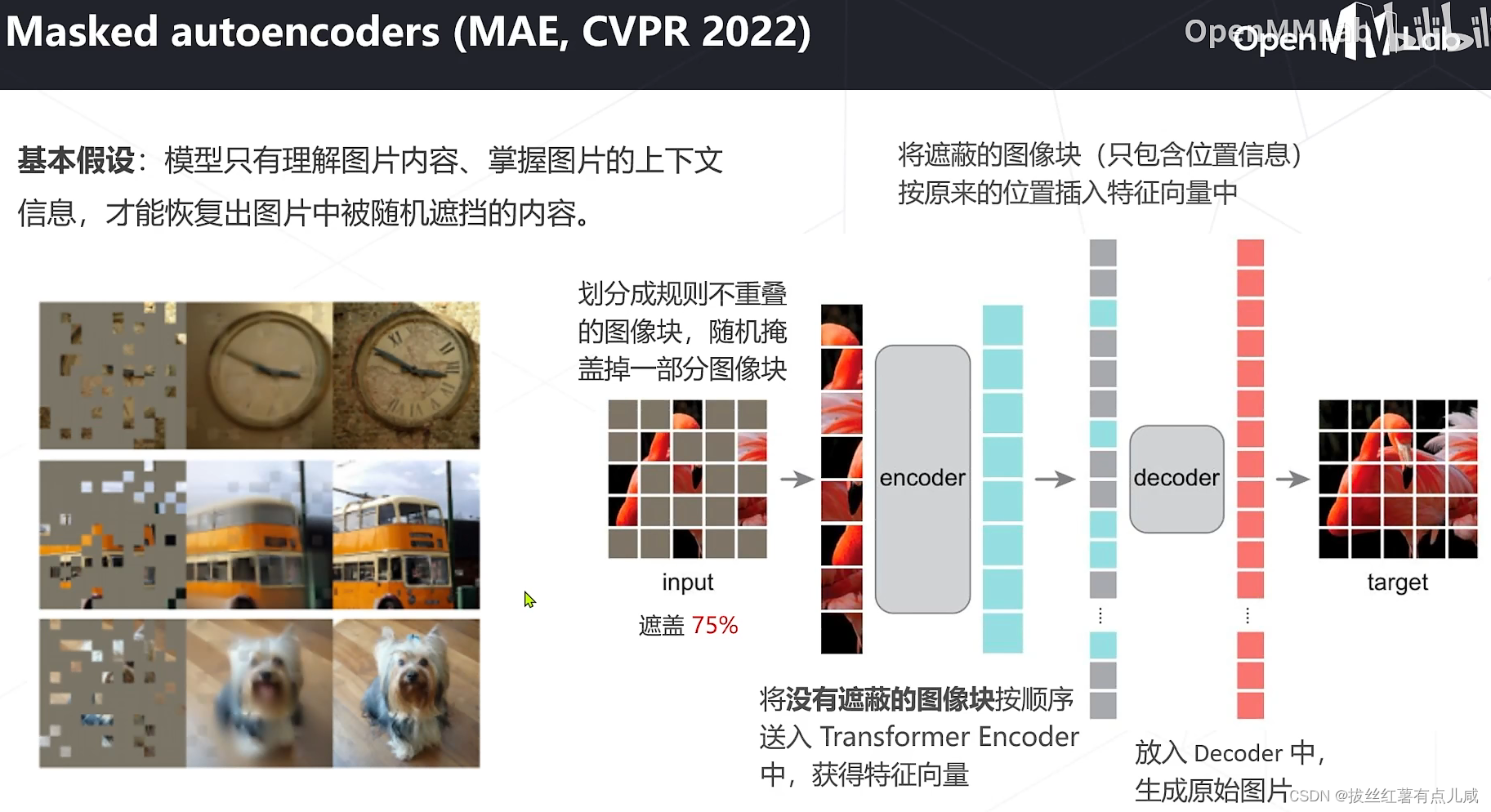
基于掩码学习
















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









