







解决一个问题》:常用的L2正则化是什么?
L0 范数为神魔是NP-hard问题?
L0范式是什么?
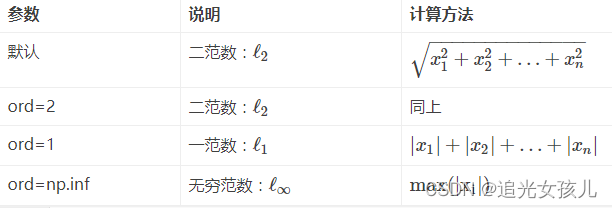
常用范数
L0范数是指向量中非0的元素的个数
L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
L2范数: ||W||2。它也不逊于L1范数,它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。
L1 norm就是绝对值相加,又称曼哈顿距离
L2 norm就是欧几里德距离
基于监督学习的目标函数:
其中,前一项是样本预测值与真实值之间的误差(最小化误差),后一项是正则化函数约束模型使其尽量简单(规范化参数)
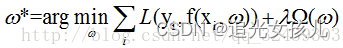
转载:正则
-
为什么实现参数的稀疏?
简化模型、避免过拟合;参数变少使模型具有更好的可解释性。 在很多情况下,一个模型中真正重要的参数并不多,如果考虑所有参数均起作用,这样的模型只拟合了训练数据,对测试数据变得没有泛化能力。 -
为什么参数值越小模型越简单?
越复杂的模型,越是会尝试对所有样本进行拟合,甚至包含了一些异常样本点,这种模型容易造成在较小的区间里预测值产生较大的波动,这个波动反映在区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,参数值会很大。
————————————————
版权声明:本文为CSDN博主「Jasonus_Chou」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_32439303/article/details/71709408
1. L0正则化
L0正则化的值是模型参数中非零参数的个数。
使用L0正则可得到稀疏的参数以此来防止过拟合。从直观上看,利用非零参数的稀疏性可以进行特征选择实现特征稀疏。
虽然L0正则优势很明显,但求解困难属于NP问题,因此一般情况下**引入L0正则的最近凸优化L1正则(方便求解)来近似求解并同样可实现稀疏效果。**



-
L1正则化(Lasso问题)
L1正则化的值是各个参数的绝对值之和。 **L1正则化之所以可以防止过拟合,是因为其范数是参数绝对值之和,而参数大小与模型复杂度成正比**,最小化L1范数可降低模型复杂度。 -
L2正则化(Ridge问题)
L2正则化的值是各个参数的平方和的开方值。 **L2正则使得参数中每个元素都很小接近于0(仅仅接近,但不为0),这就导致了所有参数都很小**,与L1类似得参数小则模型复杂度低,可有效防止过拟合。 -
Lasso 与 Ridge 对比
Lasso 和 Ridge 问题可分别表示为如下: 将模型空间限制在参数w的二维情况: 在 (w1,w2) 平面上可以画出目标函数的等高线,而约束条件为平面上半径为C的一个规则化球(norm ball):等高线与norm ball首次相交的地方就是最优解: 从上图可知,**对于L1-ball,L1在和每个坐标轴相交的地方都有“角”出现,L1-ball有很大几率与L1交于四个角,即在坐标轴上相遇,因为坐标轴在某一维度为0,从而可以产生稀疏。而等高线与L2-ball相交在坐标轴的几率就很小了**。
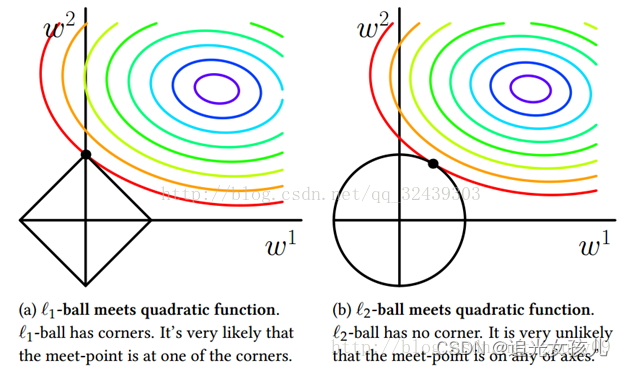
总结:L1趋向于产生少量特征,其它特征均为0;而L2会选择更多趋于0的特征。Lasso适合特征选择,Ridge适合规则化。
————————————————
版权声明:本文为CSDN博主「Jasonus_Chou」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_32439303/article/details/71709408
















 6755
6755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











