







 本文探讨了自然语言处理中对抗学习的目的和对抗训练,解释了embedding的概念,并详细介绍了对抗训练的不同方法,如FGM、PGD、FreeAT和FreeLB。同时,对比了对抗训练与对比学习的区别,强调了两者在模型鲁棒性和表示学习中的作用。
本文探讨了自然语言处理中对抗学习的目的和对抗训练,解释了embedding的概念,并详细介绍了对抗训练的不同方法,如FGM、PGD、FreeAT和FreeLB。同时,对比了对抗训练与对比学习的区别,强调了两者在模型鲁棒性和表示学习中的作用。
文章目录
思维导图链接:https://www.processon.com/mindmap/64159f9ff502f062b5d616be
1 对抗学习的目的是什么?
是为了让模型更鲁棒,对噪声更加的不敏感。
在实现这一点上,有对抗防御、对抗攻击和对抗训练。
对抗防御是识别出更多的样本
对抗攻击是为了构造更多的样本
对抗训练是将样本添加到模型中,以提高模型的鲁棒性
2 embedding是什么?
embedding是词的表示的一种,一般是可以互相替换的词之间的相似度是比较高的。
大概还是和最初的训练objective 有关,一般的Word embedding的训练是根据自监督方式完成,即预测下一个字
如果两个字是可以同时接在下一个字后面的话,相似度理应高一些。比如:我喜欢你和我讨厌你。
参考链接:https://spaces.ac.cn/archives/4122
3 对抗训练
深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。
原文链接:https://spaces.ac.cn/archives/7234
最好还是看原文,讲的很透彻。
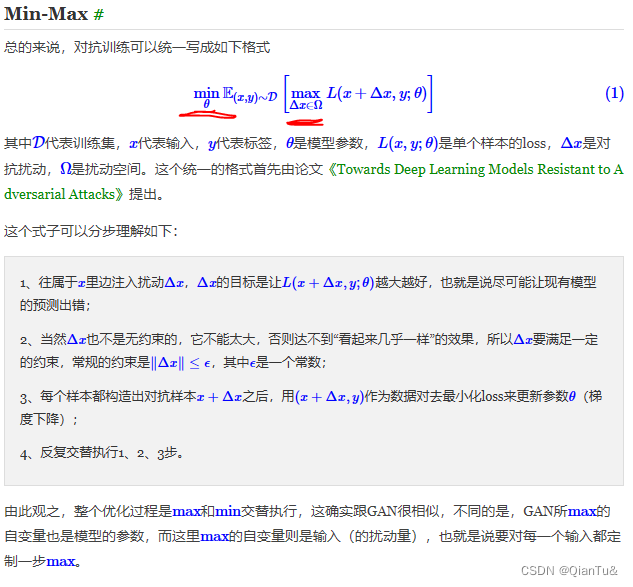


问题
1.FGM从思想上来说,我理解它的意思是,在原始输入样本x上加对抗r,但这个对抗肯定没法在原始token上加,所以就加在E = nn.word_embedding(x) = x * W_emb上,所以简单描述应该是x_adv = x * W_emb + r;
但从你的FGM的代码实操来看,似乎是将扰动r加在了embedding层的权重W_emb上,即x_adv’ = x * (W_emb + r)
= x * W_emb + x * r,似乎扰动r被多加了(x-1)倍?当然,这种略带玄学的东西本就不该十分一丝不苟,因为好不好用应该是实践说了算,不过我担心是我理解有误,所以请教一下这个问题~
1 如果加在bias的位置的话,反向传播的话,加不加都不会产生任何影响,这时候FGM就没有意义了;
2 为什么不能加?严格来说,NLP里面就没有真正的对抗样本,因为真正的对抗样本是需要加了扰动之后仍然能够在vocab中有对应的index,而NLP里面很难做到。
2.此外,再问个更小白的问题——我理解必须先算出原始embedding对应的loss,才能在此基础上算出embedding空间加扰动r之后的对抗loss,从而反向传播得到grad以进行参数更新。但我不理解的是,为何第二次backward()要在第一次backward()基础上进行?即最终得到的grad,是由原始loss对应的grad+对抗loss对应的grad加和而得,我个人理解是,模型训练只需要使用更难更容易出大loss的对抗样本即可,那为何还要保留
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











