






 在4-3090上使用ChatGLM-6B-PT模型进行微调时遇到GPU显存不足的问题,由于其他GPU已被占用。通过修改ds_train_finetune.sh脚本,设置CUDA_VISIBLE_DEVICES=1和--num_gpus=1来指定GPU:1进行训练,但初始尝试未成功。查阅Deepspeed文档后,尝试使用hostfile和--include参数,但因SSH连接问题失败。最终通过删除hostfile和仅使用--include=localhost:1解决了单GPU训练的问题,成功在GPU:1上进行微调。
在4-3090上使用ChatGLM-6B-PT模型进行微调时遇到GPU显存不足的问题,由于其他GPU已被占用。通过修改ds_train_finetune.sh脚本,设置CUDA_VISIBLE_DEVICES=1和--num_gpus=1来指定GPU:1进行训练,但初始尝试未成功。查阅Deepspeed文档后,尝试使用hostfile和--include参数,但因SSH连接问题失败。最终通过删除hostfile和仅使用--include=localhost:1解决了单GPU训练的问题,成功在GPU:1上进行微调。
在4-3090对ChatGLM-6B-PT微调, 由于gpu:0, gpu:2, gpu:3都被占用, 导致微调显存不足
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 23.70 GiB total capacity; 8.87 GiB already allocated; 79.81 MiB free; 8.88 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
只能选择在gpu:1上微调模型, 问题是deepspeed脚本ds_train_finetune.sh默认是全卡跑的, 可以看到运行时提示
[INFO] [launch.py:249:main] Setting CUDA_VISIBLE_DEVICES=0, 1, 2, 3
这是由于ds_train_finetune.sh中, 默认num_gpus=4所有卡全开
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=4 --master_port $MASTER_PORT main.py \
省流, 查阅官方文档 Getting Started - DeepSpeed
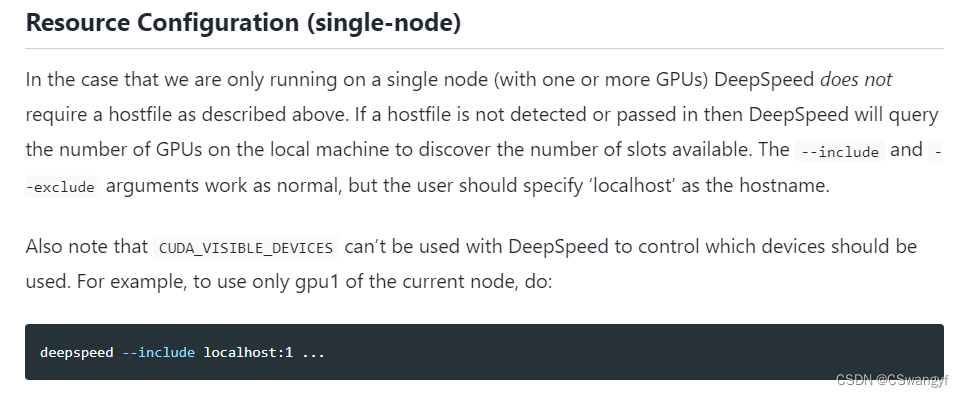
有详细介绍单节点选择指定gpu进行训练的配置, 只需要在ds_train_finetune.sh中配置
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --include="localhost:1" --master_port $MASTER_PORT main.py \这样即可选择在本地机器指定gpu:1进行模型微调
后面这些内容是因为没看全文档导致废了半天精力
有考虑修改为
LR=1e-4
CUDA_VISIBLE_DEVICES=1
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=1 --master_port $MASTER_PORT main.py \
但没有用, 虽然指定了只有一张卡微调, 但是默认还是在gpu:0上跑, 之前的设定CUDA_VISIBLE_DEVICES=1被重写了, 观察运行时提示信息可以看到
[INFO] [launch.py:249:main] Setting CUDA_VISIBLE_DEVICES=0
查阅deepspeed官方文档, 有写对于多机训练可以指定每个机器使用的gpu
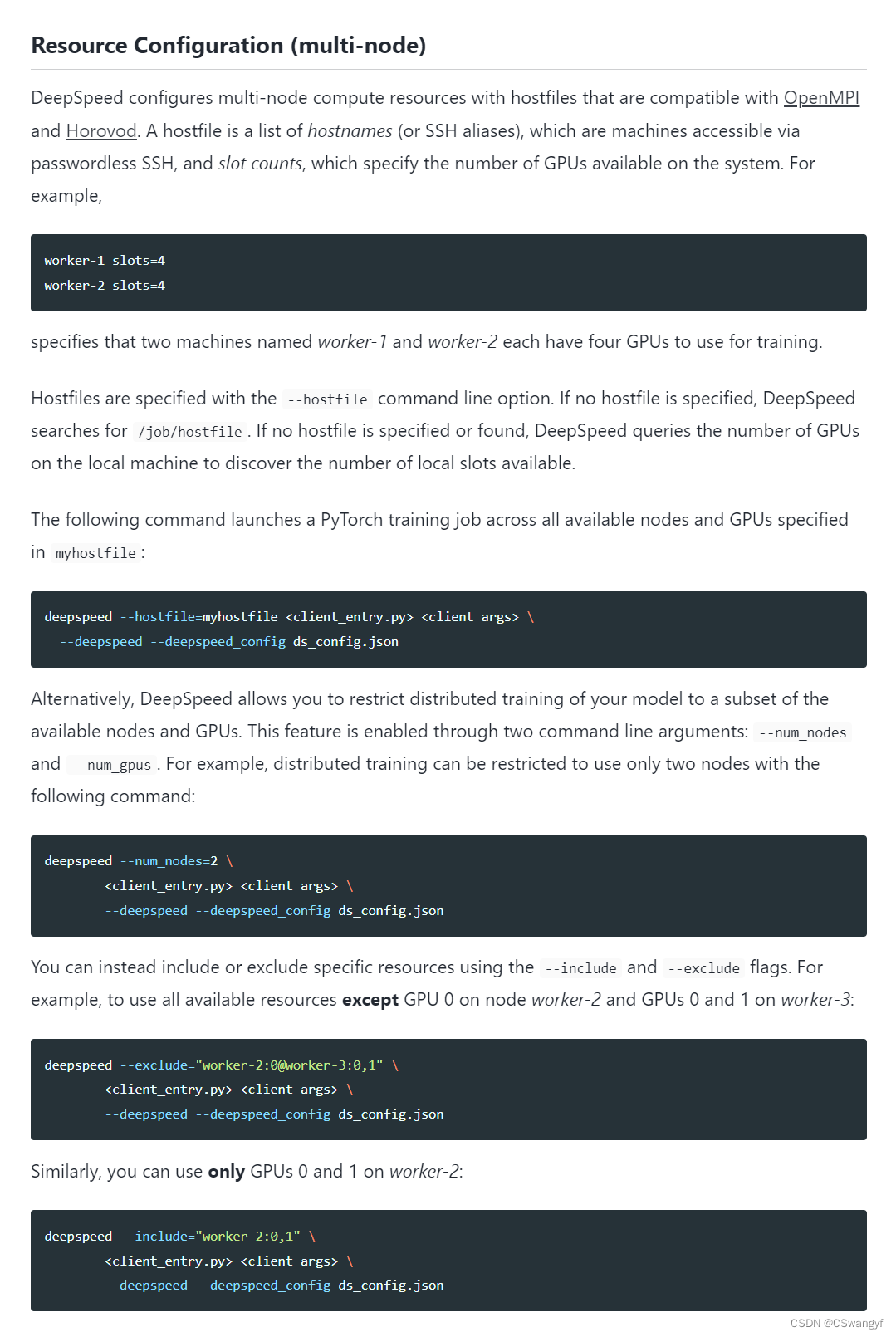
尝试按照这个思路增加hostfile并配置--hostfile --include
touch hostfile
vim hostfilehostfile内容
host slots=4修改ds_train_finetune.sh
vim ds_train_finetune.shds_train_finetune.sh前三行
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --hostfile=hostfile --include="host:1" --master_port $MASTER_PORT main.py \报错无法通过ssh连接host, 因为host不是一个主机名
然后考虑查看本机主机名
hostname得到主机名43090
43090
修改hostfile内容和ds_train_finetune.sh前三行
43090 slots=4LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --hostfile=hostfile --include="43090:1" --master_port $MASTER_PORT main.py \仍然报错无法通过ssh连接43090, 因为是自己远程连接了自己, 我灵机一动考虑用本地连接, 把两个文件的43090都改成localhost, 因为本地连接是可以ssh localhost连接的
RuntimeError: Using hostfile at hostfile but host=43090 was not reachable via ssh. If you are running with a single node please remove hostfile or setup passwordless ssh.
localhost slots=4LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --hostfile=hostfile --include="localhost:1" --master_port $MASTER_PORT main.py \不出意外的话, 是要出意外了, 仍然报错
RuntimeError: Using hostfile at hostfile but host=localhost was not reachable via ssh. If you are running with a single node please remove hostfile or setup passwordless ssh.
突然我注意到报错信息最后一句话
If you are running with a single node please remove hostfile or setup passwordless ssh.
本地连接我用啥hostfile? 我立马删掉hostfile文件和ds_train_finetune.sh中的--hostfile=hostfile
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --include="localhost:1" --master_port $MASTER_PORT main.py \程序运行结束, 查看运行提示信息, 我真的狠狠的泪目了
[INFO] [launch.py:249:main] Setting CUDA_VISIBLE_DEVICES=1
显示是在指定gpu:1上进行的微调, 终于可以放心的nohup挂起了
nohup bash ds_train_finetune.sh > nohup.log 2>&1 &如果出现显存溢出情况, 可以将ds_train_finetune.sh中的per_device_train_batch_size调成1
--per_device_train_batch_size 1 \

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









