







五、无模型控制
1.介绍
无模型预测:估计一个未知MDP的价值函数
无模型控制:优化一个未知MDP的价值函数
无模型控制的应用
一些可以建模成MDP的例子:电梯、侧方位停车、证券投资管理、船舶操舵、机器人行走
对于大多数这些问题,会有下列之一的情况:
- MDP模型是未知的,但可以采样得到经验
- MDP模型是已知的,但过于复杂,过于繁琐
无模型控制可以解决这些问题
在轨/离轨学习
在轨学习(On-policy)
- 在工作中学习,边打边学
- 从 π \pi π中得到的经验学习策略 π \pi π
离轨学习(Off-policy)
- 站在巨人的肩膀上,看棋谱
- 从 μ \mu μ中得到的经验学习策略 π \pi π
2.在轨蒙特卡罗控制
基于动作价值函数的广义策略迭代
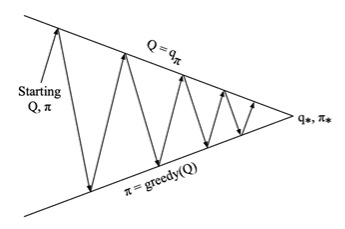
策略评估 蒙特卡罗策略评估, Q = q π Q=q_\pi Q=qπ
策略优化 贪婪策略优化? π ′ ( s ) = argmax a ∈ A Q ( s , a ) \pi^{\prime}(s)=\underset{a \in \mathcal{A}}{\operatorname{argmax}} Q(s, a) π′(s)=a∈AargmaxQ(s,a)
ϵ − G r e e d y \epsilon-Greedy ϵ−Greedy探索
当我们使用 Q 函数的时候,策略完全取决于 Q 函数。给定某一个状态,我们就穷举所有的动作,采取让 Q 值最大的动作,但这并不是一个好的数据收集方式
假设我们在状态 s s s采取动作 a 2 a_2 a2,它得到的值是正的奖励, Q ( s , a 2 ) Q(s,a_2) Q(s,a2)就会比其他动作的 Q Q Q值要大。在采取动作的时候,谁的 Q Q Q值最大就采取谁,所以之后永远都只会采取 a 2 a_2 a2,其他的动作就再也不会被采取了,这就会有问题。
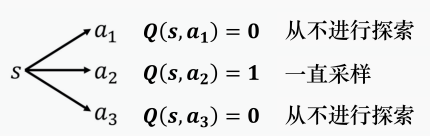
所以要使用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy方法。
-
确保持续探索的最简单想法
-
所有 m m m个动作都以非零概率进行尝试
-
以 1 − ϵ 1-\epsilon 1−ϵ的概率选择贪婪动作
-
以 ϵ \epsilon ϵ的概率随机选择动作
π ( a ∣ s ) = { ϵ / m + 1 − ϵ if a ∗ = argmax a ∈ A Q ( s , a ) ϵ / m otherwise \pi(a \mid s)= \begin{cases}\epsilon / m+1-\epsilon & \text { if } a^*=\underset{a \in \mathcal{A}}{\operatorname{argmax}} Q(s, a) \\ \epsilon / m & \text { otherwise }\end{cases} π(a∣s)=⎩ ⎨ ⎧ϵ/m+1−ϵϵ/m if a∗=a∈AargmaxQ(s,a) otherwise
GLIE(greedy in the Limit with Infinite Exploration)
有限的时间里进行无限可能的探索
- 所有的状态-动作对都被探索了无数次
lim k → ∞ N k ( s , a ) = ∞ \lim _{k \rightarrow \infty} N_k(s, a)=\infty k→∞limNk(s,a)=∞
- 策略趋同于贪婪的策略
lim k → ∞ π k ( a ∣ s ) = 1 ( a = argmax a ′ ∈ A Q k ( s , a ′ ) ) \lim _{k \rightarrow \infty} \pi_k(a \mid s)=\mathbf{1}\left(a=\underset{a^{\prime} \in \mathcal{A}}{\operatorname{argmax}} Q_k\left(s, a^{\prime}\right)\right) k→∞limπk(a∣s)=1(a=a′∈AargmaxQk(s,a′))
例如,如果 ϵ k = 1 k \epsilon _k=\frac{1}{k} ϵk=k1(k为探索的episode数目),则 ϵ − G r e e d y \epsilon-Greedy ϵ−Greedy为GLIE
GLIE蒙特卡罗控制
采样策略 π \pi π的第 k k k轮episode: S 1 , A 1 , R 2 , … , S T ∼ π {S_1,A_1,R_2,\dots,S_T} \sim \pi S1,A1,R2,…,ST∼π
对于episode中的每个状态
S
t
S_t
St和动作
A
t
A_t
At
N
(
S
t
,
A
t
)
←
N
(
S
t
,
A
t
)
+
1
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
1
N
(
S
t
,
A
t
)
(
G
t
−
Q
(
S
t
,
A
t
)
)
\begin{aligned} & N\left(S_t, A_t\right) \leftarrow N\left(S_t, A_t\right)+1 \\ & Q\left(S_t, A_t\right) \leftarrow Q\left(S_t, A_t\right)+\frac{1}{N\left(S_t, A_t\right)}\left(G_t-Q\left(S_t, A_t\right)\right) \end{aligned}
N(St,At)←N(St,At)+1Q(St,At)←Q(St,At)+N(St,At)1(Gt−Q(St,At))
基于新的动作价值函数优化策略
ϵ
←
1
k
π
←
ϵ
−
g
r
e
e
d
y
(
Q
)
\epsilon \leftarrow \frac{1}{k} \\ \pi \leftarrow \epsilon-greedy(Q)
ϵ←k1π←ϵ−greedy(Q)
定理: GLIE蒙特卡罗控制会收敛到最佳的动作价值函数,
Q
(
s
,
a
)
→
q
∗
(
s
,
a
)
Q(s,a) \rightarrow q_*(s,a)
Q(s,a)→q∗(s,a)
3.在轨时序差分学习
与蒙特卡罗(MC)相比,时序差分(TD)学习有几个优点
- 更低的方差
- 在线
- 不完整的序列
自然的想法是:在我们的控制循环中使用TD而不是MC
- 将TD应用于 Q ( S , A ) Q(S,A) Q(S,A)
- 使用 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略改进
- 更新每一个时间步
使用Sarsa更新动作价值函数
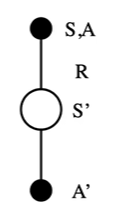
q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
R
t
+
1
+
γ
q
π
(
S
t
+
1
,
A
t
+
1
)
∣
S
t
=
s
,
A
t
=
a
]
\begin{aligned} & q_\pi(s, a)=\mathbb{E}_\pi\left[G_t \mid S_t=s, A_t=a\right] \\ & =\mathbb{E}_\pi\left[R_{t+1}+\gamma q_\pi\left(S_{t+1}, A_{t+1}\right) \mid S_t=s, A_t=a\right] \end{aligned}
qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]
Q ( S , A ) ← Q ( S , A ) + α ( R + γ Q ( S ′ , A ′ ) − Q ( S , A ) ) Q(S, A) \leftarrow Q(S, A)+\alpha\left(R+\gamma Q\left(S^{\prime}, A^{\prime}\right)-Q(S, A)\right) Q(S,A)←Q(S,A)+α(R+γQ(S′,A′)−Q(S,A))
在轨策略控制中的Sarsa算法

Sarsa收敛于最优动作价值函数, Q ( s , a ) → q ∗ ( s , a ) Q(s,a) \rightarrow q_*(s,a) Q(s,a)→q∗(s,a),满足以下条件:
- 任何时候的策略 π t ( a ∣ s ) \pi_t(a \mid s) πt(a∣s)符合GLIE特性
- 步长系数 α t \alpha_t αt满足:
∑ t = 1 ∞ α t = ∞ ∑ t = 1 ∞ α t 2 < ∞ \begin{aligned} & \sum_{t=1}^{\infty} \alpha_t=\infty \\ & \sum_{t=1}^{\infty} \alpha_t^2<\infty \end{aligned} t=1∑∞αt=∞t=1∑∞αt2<∞
4.离轨学习之Q学习
离轨学习
目标策略:用来学习的策略,要进行学习的智能体(玩游戏的菜鸟)
行为策略:生成行动样本的策略,实际操作的智能体(玩游戏的高手)
评估目标策略 π ( a ∣ s ) \pi(a\mid s) π(a∣s)以计算 V π ( s ) V_\pi(s) Vπ(s)或 q π ( s , a ) q_\pi(s,a) qπ(s,a)
同时遵循行为策略
μ
(
a
∣
s
)
\mu(a \mid s)
μ(a∣s)
{
S
1
,
A
1
,
R
2
,
…
,
S
r
}
∼
μ
\{S_1, A_1, R_2, \dots, S_r\} \sim \mu
{S1,A1,R2,…,Sr}∼μ
通过行为策略来更新
v
π
v_\pi
vπ和
q
π
q_\pi
qπ
为什么这很重要?
- 通过观察人类或其他智能体来学习
- 重用从旧策略 π 1 , π 2 , … , π t − 1 \pi_1,\pi_2,\dots,\pi_{t-1} π1,π2,…,πt−1生成的经验
- 在遵循探索性策略的同时学习最优策略,探索性是指行为策略产生者还在继续进行操作,可供目标策略学习者去学习
Q-学习
现在考虑基于动作价值 Q ( s , a ) Q(s,a) Q(s,a)的离轨学习
使用行为策略 A t ∼ μ ( ⋅ ∣ S t ) A_t \sim \mu(\cdot \mid S_t) At∼μ(⋅∣St)选择下一个动作,产生 R t + 1 R_{t+1} Rt+1与 S t + 1 S_{t+1} St+1
考虑基于替代策略 π \pi π的后续动作 A ′ ∼ π ( ⋅ ∣ S t ) A^\prime \sim \pi(\cdot \mid S_t) A′∼π(⋅∣St)
并将
Q
(
S
t
,
A
t
)
Q(S_t,A_t)
Q(St,At)更新为替代策略动作的价值
Q
(
S
t
,
A
t
)
←
Q
(
S
t
,
A
t
)
+
α
(
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
′
)
−
Q
(
S
t
,
A
t
)
)
\left.Q\left(S_t, A_t\right) \leftarrow Q\left(S_t, A_t\right)+\alpha ( R_{t+1}+\gamma Q\left(S_{t+1}, A^{\prime}\right)-Q\left(S_t, A_t\right)\right)
Q(St,At)←Q(St,At)+α(Rt+1+γQ(St+1,A′)−Q(St,At))
在Sarsa中,
A
′
A^\prime
A′和
A
t
A_t
At都是“我自己”干的。
在Q学习中, A ′ A^\prime A′是目标策略也就是“我自己”干的, A t A_t At是行为策略“别人”干的
使用Q-学习的离轨控制
现在允许行为和目标策略都得到优化
目标策略
π
\pi
π是贪婪的
w
.
r
.
t
.
w.r.t.
w.r.t.
Q
(
s
,
a
)
Q(s,a)
Q(s,a)
π
(
S
t
+
1
)
=
argmax
a
′
Q
(
S
t
+
1
,
a
′
)
\pi(S_{t+1})=\underset{a^{\prime}}{\operatorname{argmax}} Q\left(S_{t+1}, a^{\prime}\right)
π(St+1)=a′argmaxQ(St+1,a′)
行为策略
μ
\mu
μ是
ϵ
−
g
r
e
e
d
y
\epsilon-greedy
ϵ−greedy的
w
.
r
.
t
.
w.r.t.
w.r.t.
Q
(
s
,
a
)
Q(s,a)
Q(s,a)
然后Q-Learning目标简化为,计算
G
t
G_t
Gt:
R
t
+
1
+
γ
Q
(
S
t
+
1
,
A
′
)
=
R
t
+
1
+
γ
Q
(
S
t
+
1
,
argmax
a
′
Q
(
S
t
+
1
,
a
′
)
)
=
R
t
+
1
+
max
a
′
γ
Q
(
S
t
+
1
,
a
′
)
\begin{aligned} & R_{t+1}+\gamma Q\left(S_{t+1}, A^{\prime}\right) \\ = & R_{t+1}+\gamma Q\left(S_{t+1}, \underset{a^{\prime}}{\operatorname{argmax}} Q\left(S_{t+1}, a^{\prime}\right)\right) \\ = & R_{t+1}+\max _{a^{\prime}} \gamma Q\left(S_{t+1}, a^{\prime}\right) \end{aligned}
==Rt+1+γQ(St+1,A′)Rt+1+γQ(St+1,a′argmaxQ(St+1,a′))Rt+1+a′maxγQ(St+1,a′)
目标策略和行为策略共享
Q
Q
Q,行为策略带有探索,目标策略利用行为策略产生的
R
t
+
1
R_{t+1}
Rt+1和
S
t
+
1
S_{t+1}
St+1,通过贪婪方法找到使
Q
Q
Q最大的
a
′
a^\prime
a′,然后来更新
Q
Q
Q
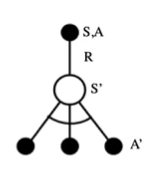
Q
(
S
,
A
)
←
Q
(
S
,
A
)
+
α
(
R
+
γ
max
a
′
Q
(
S
′
,
a
′
)
−
Q
(
S
,
A
)
)
Q(S, A) \leftarrow Q(S, A)+\alpha\left(R+\gamma \max _{a^{\prime}} Q\left(S^{\prime}, a^{\prime}\right)-Q(S, A)\right)
Q(S,A)←Q(S,A)+α(R+γa′maxQ(S′,a′)−Q(S,A))
Q-Learning离轨控制算法

第五步中,根据从Q得到的策略,这个策略是行为策略,选择了动作A,得到了 R R R和 S ′ S^\prime S′,这个 R R R和 S ′ S^\prime S′都是和行为策略有关,然后根据这个 S ′ S^\prime S′去遍历所有动作(贪婪方法,也就是目标策略),找到使 Q Q Q最大的动作 A ′ A^\prime A′,然后来更新 Q Q Q,这个 A ′ A' A′不会影响行为策略的下一步,只是用来更新 Q Q Q的。这个 Q Q Q是行为策略和目标策略共享的。
这个过程就是:行为策略一直在执行,目标策略就在不停地更新自己,同时把自己的一些想法告诉行为策略,行为策略也在提高。
5.参考资料
强化学习基础 北京邮电大学 鲁鹏 强化学习基础 (本科生课程) 北京邮电大学 鲁鹏_哔哩哔哩_bilibili
深度强化学习 台湾大学 李宏毅 DRL Lecture 1_ Policy Gradient (Review)_哔哩哔哩_bilibili
蘑菇书EasyRL datawhalechina/easy-rl: 强化学习中文教程(蘑菇书),在线阅读地址:https://datawhalechina.github.io/easy-rl/















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









