







 本文概述了基于策略的深度强化学习方法,如Actor-Critic架构下的A3C和A2C,以及它们如何结合深度神经网络。讨论了TRPO和PPO的改进,以及确定性策略梯度(DPG)和双层DQN(DDPG)的应用。
本文概述了基于策略的深度强化学习方法,如Actor-Critic架构下的A3C和A2C,以及它们如何结合深度神经网络。讨论了TRPO和PPO的改进,以及确定性策略梯度(DPG)和双层DQN(DDPG)的应用。
基于策略的深度强化学习
分类
基于值函数的RL
-
学习值/动作-值函数逼近器,一种间接法,目标是找动作,但通过Q值来确定哪个动作带来的Q最大。
V θ ( s ) ≈ V π ( s ) Q θ ( s , a ) ≈ Q π ( s , a ) V_\theta(s) \approx V^\pi(s) \\ Q_\theta(s,a) \approx Q^\pi(s,a) Vθ(s)≈Vπ(s)Qθ(s,a)≈Qπ(s,a) -
隐式的策略(贪婪策略等)
基于策略的RL
没有价值函数,学习一个策略逼近器 π θ ( s , a ) \pi_\theta(s,a) πθ(s,a)
基于Actor-Critic的RL
学习价值逼近器,也要学习策略逼近器
A3C A2C
回顾Actor-Critic
Actor-Critic包含两个部分
Actor演员,
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s),它的作用是采取动作使Critic评论家满意的策略
J
(
θ
)
=
E
s
∼
p
,
π
θ
[
π
θ
(
a
∣
s
)
Q
Φ
(
s
,
a
)
]
∂
J
(
θ
)
∂
θ
=
E
π
θ
[
∂
log
π
θ
(
a
∣
s
)
∂
θ
Q
Φ
(
s
,
a
)
]
\begin{gathered} J(\theta)=\mathbb{E}_{s \sim p, \pi_\theta}\left[\pi_\theta(a \mid s) Q_{\Phi}(s, a)\right] \\ \frac{\partial J(\theta)}{\partial \theta}=\mathbb{E}_{\pi_\theta}\left[\frac{\partial \log \pi_\theta(a \mid s)}{\partial \theta} Q_{\Phi}(s, a)\right] \end{gathered}
J(θ)=Es∼p,πθ[πθ(a∣s)QΦ(s,a)]∂θ∂J(θ)=Eπθ[∂θ∂logπθ(a∣s)QΦ(s,a)]
Critic评论家,
Q
Φ
(
s
,
a
)
Q_\Phi(s,a)
QΦ(s,a),它的作用是学会准确估计演员策略所采取动作价值的值函数,使用TD Error进行更新。
Q
Φ
(
s
,
a
)
≃
r
(
s
,
a
)
+
γ
E
s
′
∼
p
(
s
′
∣
s
,
a
)
,
a
′
∼
π
θ
(
a
′
∣
s
′
)
[
Q
Φ
(
s
′
,
a
′
)
]
Q_{\Phi}(s, a) \simeq r(s, a)+\gamma \mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right), a^{\prime} \sim \pi_\theta\left(a^{\prime} \mid s^{\prime}\right)}\left[Q_{\Phi}\left(s^{\prime}, a^{\prime}\right)\right]
QΦ(s,a)≃r(s,a)+γEs′∼p(s′∣s,a),a′∼πθ(a′∣s′)[QΦ(s′,a′)]
∇ θ J ( θ ) = E π θ [ ∇ θ log π θ ( s , a ) G t ] R E I N F O R C E = E π θ [ ∇ θ log π θ ( s , a ) Q w ( s , a ) ] Q A c t o r − C r i t i c = E π θ [ ∇ θ log π θ ( s , a ) A w ( s , a ) ] 优势 A c t o r − C r i t i c = E π θ [ ∇ θ log π θ ( s , a ) δ ] T D A c t o r − C r i t i c = E π θ [ ∇ θ log π θ ( s , a ) δ e ] T D ( λ ) A c t o r − C r i t i c \begin{aligned} \nabla_\theta J(\theta) & =\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) G_t\right] \quad REINFORCE \\ & =\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) Q_{\mathrm{w}}(s, a)\right] \quad Q Actor-Critic\\ & =\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) A_{\mathbf{w}}(s, a)\right] \quad 优势Actor-Critic\\ & =\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) \delta\right] \quad TD Actor-Critic\\ & =\mathbb{E}_{\pi_\theta}\left[\nabla_\theta \log \pi_\theta(s, a) \delta e\right] \quad TD(\lambda) Actor-Critic \end{aligned} ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)Gt]REINFORCE=Eπθ[∇θlogπθ(s,a)Qw(s,a)]QActor−Critic=Eπθ[∇θlogπθ(s,a)Aw(s,a)]优势Actor−Critic=Eπθ[∇θlogπθ(s,a)δ]TDActor−Critic=Eπθ[∇θlogπθ(s,a)δe]TD(λ)Actor−Critic
A3C
如何将基于策略的RL方法和深度神经网络有效地结合在一起?
DQN使用的是经验回放技术,来减少数据之间的相关性,因为每个样本可能是不同策略所产生的,但是标准的策略梯度方法是On-Policy的,需要根据当前的策略来采样数据。
所以基于策略梯度的方法是无法采用经验回放的,只能采用并行训练的方法来减少数据相关性
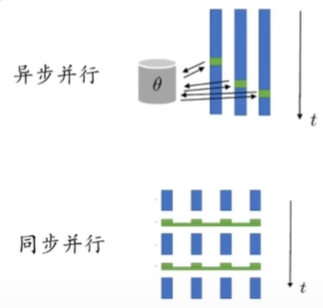
异步并行是每个线程并行收集 ( s i , a i , r i , s i ′ ) {(s_i,a_i,r_i,s_i^\prime)} (si,ai,ri,si′),让数据一定程度上是独立同分布的,各自累计梯度更新参数,各个线程可能运行不同的步数后再去更新策略函数
同步并行是每个线程并行收集 ( s i , a i , r i , s i ′ ) {(s_i,a_i,r_i,s_i^\prime)} (si,ai,ri,si′),同步累计梯度更新参数,各个线程在相同步数后去更新策略函数。
A2C
A3C的异步更新会导致有时不同线程中的Actor将使用不同版本的策略,因此累积更新的方向将不是最优的。
A2C是一种同步更新的方法
等待各个线程完成自己的任务,再计算各个线程的梯度平均值,然后对参数进行更新
每一次迭代中并行的actor将均执行同一策略,这种训练方式理论上会收敛更快
A2C已被证明在能够实现与A3C相同或更好的性能得同时,更有效地利用GPU,并且能够适应更大的批量batch_size大小
A2C网络的公式如下:
∇
R
ˉ
θ
≈
1
N
∑
n
=
1
N
∑
t
=
1
T
n
(
r
t
n
+
V
π
(
s
t
+
1
n
)
−
V
π
(
s
t
n
)
)
∇
log
p
θ
(
a
t
n
∣
s
t
n
)
\nabla \bar{R}_\theta \approx \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n}\left(r_t^n+V_\pi\left(s_{t+1}^n\right)-V_\pi\left(s_t^n\right)\right) \nabla \log p_\theta\left(a_t^n \mid s_t^n\right)
∇Rˉθ≈N1n=1∑Nt=1∑Tn(rtn+Vπ(st+1n)−Vπ(stn))∇logpθ(atn∣stn)
还可以使用n-步回报来减少方差,是将梯度前面的优势由单步变为多步的。用来平衡是否有偏和方差高低。
Off-policy 策略梯度
A3C和A2C均是On-policy。
On-policy是根据策略 π \pi π产生的样本来学习关于 π \pi π的相关知识
Off-policy是根据另一个策略 μ \mu μ产生的样本来学习关于 π \pi π的相关知识
Off-policy的优势在于:1.可重复利用历史样本,数据利用率更高,2.利用行为策略交互收集数据,适用性更好。
那么想要将策略梯度转为Off-Policy的,可以使用重要性采样来实现。
E
x
∼
p
(
x
)
[
f
(
x
)
]
=
∫
p
(
x
)
f
(
x
)
d
x
=
∫
q
(
x
)
q
(
x
)
p
(
x
)
f
(
x
)
d
x
=
∫
q
(
x
)
p
(
x
)
q
(
x
)
f
(
x
)
d
x
=
E
x
∼
q
(
x
)
[
p
(
x
)
q
(
x
)
f
(
x
)
]
\begin{aligned} E_{x \sim p(x)}[f(x)] & =\int p(x) f(x) d x \\ & =\int \frac{q(x)}{q(x)} p(x) f(x) d x \\ & =\int q(x) \frac{p(x)}{q(x)} f(x) d x \\ & =E_{x \sim q(x)}\left[\frac{p(x)}{q(x)} f(x)\right] \end{aligned}
Ex∼p(x)[f(x)]=∫p(x)f(x)dx=∫q(x)q(x)p(x)f(x)dx=∫q(x)q(x)p(x)f(x)dx=Ex∼q(x)[q(x)p(x)f(x)]
策略梯度的优化目标是:
J
(
θ
)
=
E
τ
∼
p
θ
(
τ
)
[
r
(
τ
)
]
J(\theta)=E_{\tau \sim p_\theta(\tau)}[r(\tau)]
J(θ)=Eτ∼pθ(τ)[r(τ)]
其中
p
θ
(
τ
)
p_\theta(\tau)
pθ(τ)是目标策略
π
θ
(
τ
)
\pi_\theta(\tau)
πθ(τ)产生的概率分布,
p
ˉ
(
τ
)
\bar{p}(\tau)
pˉ(τ)是行为策略所产生的概率分布
J
(
θ
)
=
E
τ
∼
p
ˉ
(
τ
)
[
p
θ
(
τ
)
p
ˉ
(
τ
)
r
(
τ
)
]
J(\theta)=E_{\tau \sim \bar{p}(\tau)}\left[\frac{p_\theta(\tau)}{\bar{p}(\tau)} r(\tau)\right]
J(θ)=Eτ∼pˉ(τ)[pˉ(τ)pθ(τ)r(τ)]

TRPO(Trust region policy optimization)
策略梯度的步长更新是 θ = θ + α ∇ θ J ( θ ) \theta = \theta + \alpha \nabla_\theta J(\theta) θ=θ+α∇θJ(θ)
策略梯度对学习率敏感,训练过程中容易出现策略崩塌。
策略梯度算法的更新步长很重要
步长太小,导致更新效率低下
步长太大,导致参数变动太大,采集到的数据的分布会随策略的更新而变化,导致可能无法从bad policy恢复
TRPO的思想上选择合适的步长,使得每次更新得到的新策略所实现的回报值单调不减。
信赖域(Trust Region)方法是更高级的步长更新方法,指在该区域内更新,策略所实现的回报值单调不减。
具体实现上是要找到一个替代函数,该函数要满足以下条件:
- 是 J ( θ ) J(\theta) J(θ)的一个下界函数
- 在当前策略处逼近 J ( θ ) J(\theta) J(θ)
- 当替代函数的值提升时, J ( θ ) J(\theta) J(θ)单调不减
- 容易优化
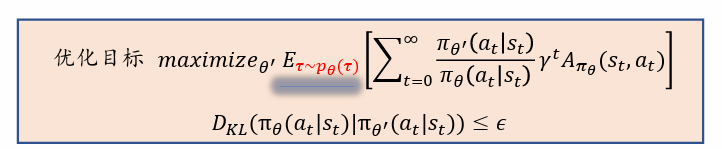
PPO
PPO在TRPO的基础上,自适应地调整KL惩罚因子,使得策略在trust region内更新
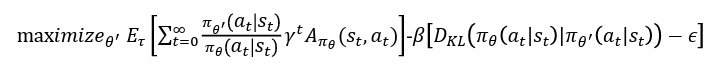
DPG/DDPG
确定性策略梯度: a = π θ ( s ) a=\pi_\theta(s) a=πθ(s)
直接给定当前状态下确定性的动作
找到使Q函数最大的动作
这两种方法的特点就是给出一个确定性的动作,而不是给出一个动作的概率分布
DPG

DDPG
DDPG结合了DQN和DPG,DQN用于高维输入离散动作空间,DPG用于低维输入连续动作空间。
使用了DQN的两种技术:Experience Replay和Target Network
对于critic和actor均有Target Network,采用软更新的方式
θ
−
←
τ
θ
+
(
1
−
τ
)
θ
−
w
−
←
τ
w
+
(
1
−
τ
)
w
−
τ
≪
1
\theta^{-} \leftarrow \tau \theta+(1-\tau) \theta^{-} \quad w^{-} \leftarrow \tau w+(1-\tau) w^{-} \quad \tau \ll 1
θ−←τθ+(1−τ)θ−w−←τw+(1−τ)w−τ≪1
θ
−
\theta^-
θ−为目标actor网络参数,
w
−
w^-
w−为目标critic网络参数
为了充分探索,利用添加噪声产生探索性动作
π
θ
′
(
s
)
=
π
θ
(
s
)
+
N
,
N
是噪声
\pi^\prime_\theta(s)=\pi_\theta(s)+\mathcal N, \quad \mathcal N是噪声
πθ′(s)=πθ(s)+N,N是噪声
算法流程:
Actor当前网络: a = π θ ( s ) a=\pi_\theta(s) a=πθ(s),根据当前状态 s s s选择当前执行的确定性动作 a a a,用于和环境交互生成 s ′ s^\prime s′,r
Critic当前网络:估计当前Q值 Q w ( s , a ) Q_w(s,a) Qw(s,a)
Critic目标网络:估计target Q值, r + γ Q w − ( s ′ , a ′ ) r+\gamma Q_{w^-}(s^\prime,a^\prime) r+γQw−(s′,a′)
Actor目标网络:
a
′
=
π
θ
−
(
s
′
)
a^\prime=\pi_{\theta^-}(s^\prime)
a′=πθ−(s′),根据经验回放池中采样的下一个状态
s
′
s^\prime
s′选择动作
a
′
a^\prime
a′,估计target Q值
D
Q
N
:
Q
w
(
s
,
a
)
−
(
r
+
γ
max
a
′
Q
w
−
(
s
′
,
a
′
)
)
D
D
P
G
:
Q
w
(
s
,
a
)
−
(
r
+
γ
Q
w
−
(
s
′
,
π
θ
−
(
s
′
)
)
)
\begin{aligned} &DQN:\quad Q_w(s, a)-\left(r+\gamma \max _{a^{\prime}} Q_{w^{-}}\left(s^{\prime}, a^{\prime}\right)\right) \\ &DDPG: \quad Q_w(s, a)-\left(r+\gamma Q_{w^{-}}\left(s^{\prime}, \pi_{\theta^{-}}\left(s^{\prime}\right)\right)\right) \end{aligned}
DQN:Qw(s,a)−(r+γa′maxQw−(s′,a′))DDPG:Qw(s,a)−(r+γQw−(s′,πθ−(s′)))
参考资料
RLChina2022 【RLChina 2022】理论课五:深度强化学习 张启超_哔哩哔哩_bilibili

















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









