







通过深度各向异性扩散的深度引导超分辨率
1. 摘要
使用 RGB 图像的指导执行深度图像的超分辨率是一个涉及多个领域的问题,例如机器人、医学成像和遥感。虽然深度学习方法在这个问题上取得了良好的成果,但最近的工作强调了将现代方法与更正式的框架相结合的价值。在这项工作中,本文提出了一种新颖的方法,它将引导各向异性扩散与深度卷积网络相结合,并推进了引导深度超分辨率的最新技术。现代网络的上下文推理能力增强了扩散的边缘转移/增强特性,并且严格的调整步骤保证了对源图像的完美遵守。本文在引导深度超分辨率的三个常用基准中取得了前所未有的结果。与其他方法相比,在较大规模(例如×32 缩放)下性能增益最大。所提出方法的代码 1 可用于提高本文结果的可重复性。
2. Intro
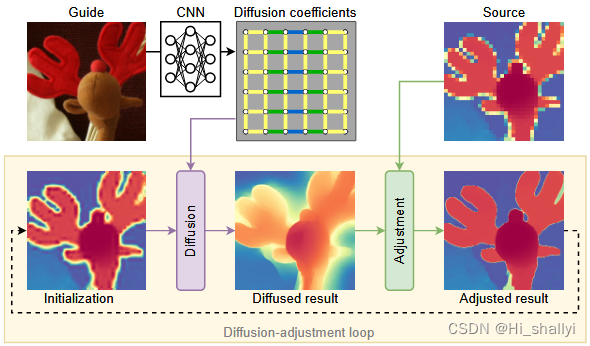
通过找到约束各向异性扩散过程的平衡状态对低分辨率深度图像进行图像超分处理。学习的扩散系数有利于物体内的平滑深度并抑制不连续性处的扩散。它们源自具有神经特征提取器的guide,该神经特征提取器guide通过扩散过程的反向传播进行训练。
3. 方法
首先描述用于引导超分辨率的扩散调整框架,然后解释如何将深度学习集成到该框架中。后一部分介绍利用引导图像中的高级上下文来找到扩散算子的最佳系数。
3.1 扩散调节
首先先解释一下什么是各异向性扩散:各向异性扩散(Anisotropic diffusion)是迭代执行边缘感知滤波的一种形式,最初提出的目的是执行区域内平滑,同时避免区域间平滑。(简化理解:利用卷积/滤波操作检测边缘区域,并进行区域内部平滑操作)
过滤的方式类似于求解具有各向异性(即空间变化)扩散权重的离散热方程。从单独的(共同配准的)引导图像计算这些扩散权重的想法已经在边缘增强 [23] 和语义分割 [2, 4] 的背景下进行了探索。
给定输入:源图像(单通道图像)和一张引导图像
(其中C为通道数,为3或更大);论文方法的第一步是使用 S 的上采样版本来初始化
。正如稍后将展示的,
的精确初始化对最终结果几乎没有影响。然后可以将扩散步骤定义为:
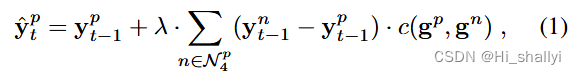
:表示位置 p 处
的像素值(对于
也类似)
:表示像素 p 的 4 个邻域
注意,此结构将图像中的所有像素连接成一个(平面)图。 λ 是一个严格正的超参数,用于调节更新并确保稳定性。当使用连接时,应设置为 λ <
。函数
根据guild图中的值生成相邻像素对的扩散系数。论文借鉴了【30】中的做法,令
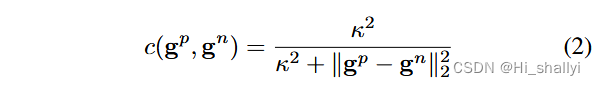
其中 是调节
中梯度敏感性的超参数。请注意,c 是对称的,
。传统(非引导)各向异性扩散是上述公式的特例,其中
。
(简化理解:公式1的迭代过程就是针对图像中的每个像素来说(像素级别),图像
的像素p在邻域方向上的梯度×系数,这个系数是图像
中像素p和对应邻域梯度平方的倒数,理解时先不考虑超参,然后求和再×超参λ)
当应用于单个图像时,各向异性扩散具有边缘增强特性 [30]。在引导扩散中,这个扩散权重/扩散系数c是根据单独的引导图像计算的,扩散过程将边缘从引导转移到目标图像 [2,4,23]。这是促使其在引导深度超分辨率框架中使用的属性:扩散能够精确地恢复上采样结果中的深度不连续性。
(简化理解:边缘检测的常规操作是计算邻域间的梯度,梯度变化大代表这个地方处于边缘位置;然后作者在这个基础上乘上一个从引导图片来计算而来的扩散系数c,从而可以检测引导图像中的目标区域而不是检测边缘)
就其本身而言,扩散并不考虑源图像 S 提供的约束。即,通过迄今为止引入的机制,当时,
将接近像素值 为
的恒定图像,从而丢失所有信息。为了将输出与源图像 S 联系起来,每个扩散步骤后面都跟着一个调整步骤,以恢复与 S 的兼容性。这样做可以保证每次迭代的输出,因此也保证了平衡
对于S 的上采样是有效的。
调整是通过简单地重新缩放 的patch来完成的,这样,当下采样到源分辨率时,它们与 S 完全匹配。更正式地说,调整步骤可以写为
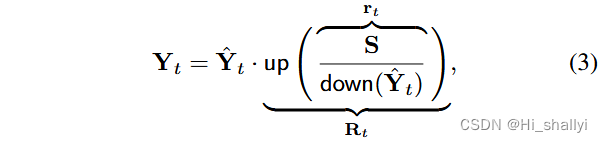
其中 down 表示线性下采样算子,up 表示最近邻上采样。和
是不同尺度下的调整比率。经过此调整步骤后,可以保证目标在较低尺度上与源匹配,即
。该方法的说明如图 2 所
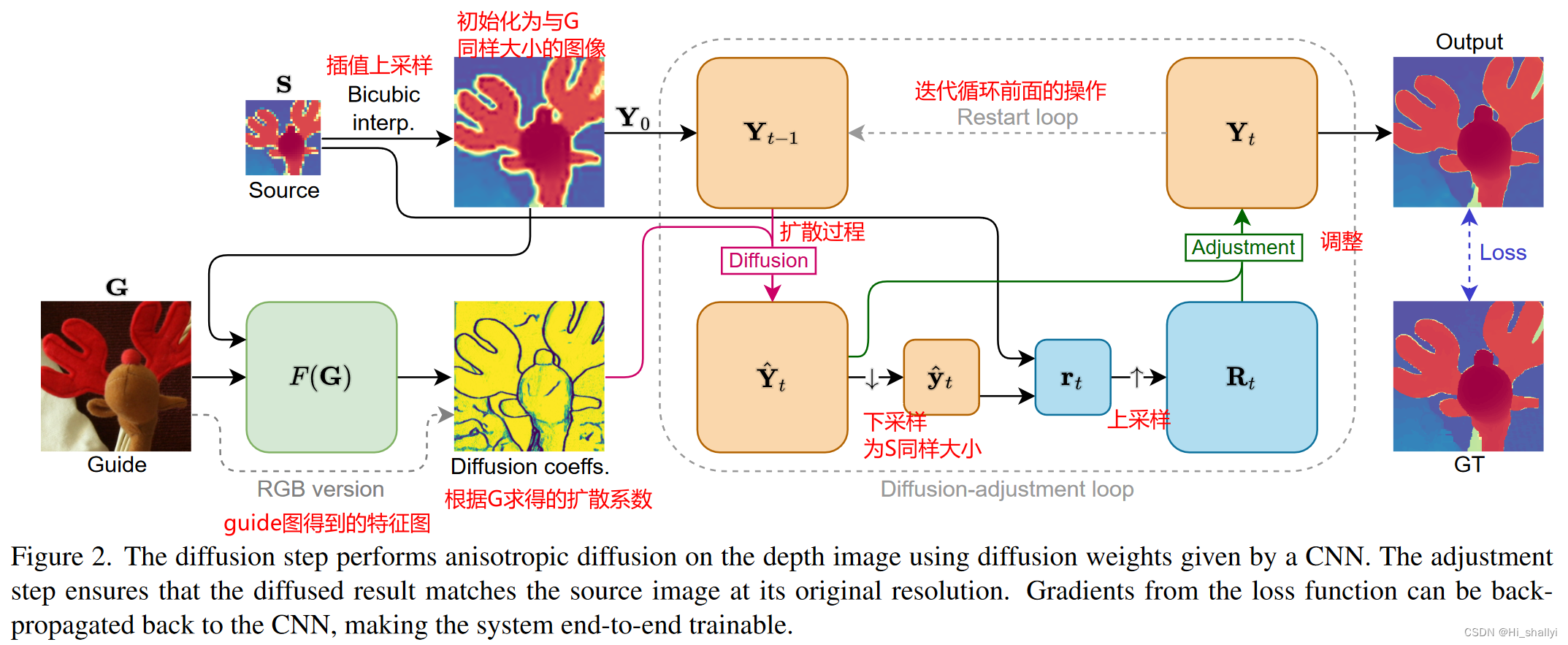
图2注:扩散步骤使用 CNN 给出的扩散权重对深度图像执行各向异性扩散。调整步骤确保漫射结果与源图像的原始分辨率相匹配。损失函数的梯度可以反向传播回 CNN,使系统可以进行端到端训练。
此外,在图 3中还展示了针对一维示例的扩散过程的演变实例。扩散信号中的梯度在波导中的梯度较低的地方快速消散,但扩散(几乎)在波导的边缘处停止。在整个过程中保持与源 S 的一致性。
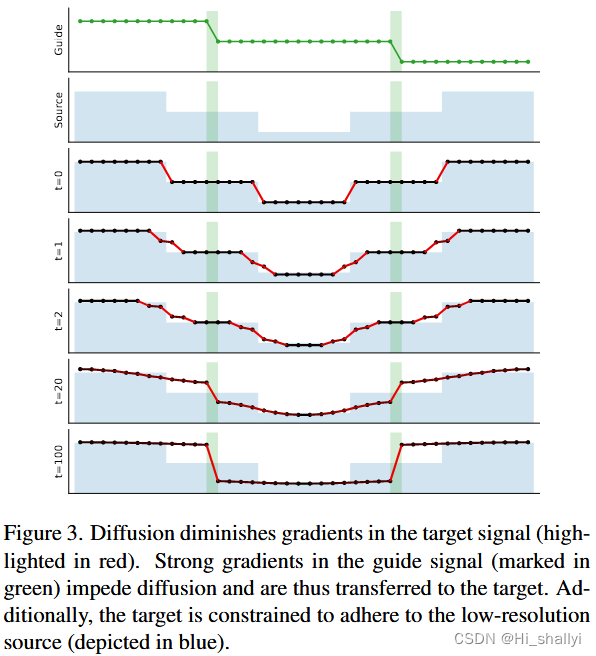
图3注:扩散减小了目标信号的梯度(以红色突出显示)。引导信号中的强梯度(以绿色标记)会阻碍扩散,从而转移到目标。此外,目标被限制为遵循低分辨率源(以蓝色表示)。
3.2 深度特征引导下的各向异性扩散
最近的工作表明,使用 CNN 在大感受野上提取的上下文特征可以极大地提高基于低阶图的超分辨率 [5]。论文的一个主要信息是,当与图上的扩散相结合时,这个想法会更加make sence.
设为神经特征提取器。在本文的实验中,F 是一个 U-Net [33],具有在 ImageNet [7] 上预训练的 ResNet-50 [12] 主干网络,C2 = 64,但可以使用任何其他神经架构,只要输出的空间维度与输入的内容相匹配。虽然 F 可以直接应用于 RGB 引导 G,但论文将上采样源 up(S) 连接为第四个通道,以支持基于粗略深度线索的对象分离,因此 C1 = 4。
先前将引导各向异性扩散与深度学习联系起来的工作 [2, 4] 仅限于将其用作推理时的后处理步骤,因为内存需求过高,并且迭代导致梯度消失/爆炸的风险算法的性质。作者发现实际上可以使用以下方案通过扩散过程传播梯度:
- 在扩散开始之前论文只计算一次
并冻结它们。这与早期的尝试相反,早期的尝试将引导图片 G 与 Y 一起扩散,并且必须在每次迭代时更新
- 论文仅通过最后的
扩散调整迭代来反向传播梯度(实际上
)。即,在训练期间,特征提取器接收来自扩散过程后期的训练信号。
通过这些修改,可以有效地将梯度一直反向传播到特征提取器 F,并端到端地训练整个管道。此外,请注意方程式(2)中的也是可训练的,因此不需要手动选择。
在训练时,论文在计算梯度迭代之前使用随机数量的无梯度迭代。论文将 定义为训练时没有梯度更新的最大迭代次数,将
定义为有梯度的迭代次数。作者发现这种随机化有助于加快推理时的收敛速度(请参阅补充材料)。为了进行推理,论文使用常数
迭代。使用最后一次
迭代来计算梯度的基本原理是,论文对系统的稳态平衡感兴趣,因此需要大量迭代。论文在第 4 节中研究了
和
的影响以及相关的计算成本,发现
> 1024 几乎没有增益,在该设置下系统仍然可以在单个 GPU 上进行训练。最后,论文指出,虽然该算法需要相对大量的迭代(论文发现 8000 是一个合适的数字),但扩散和调整算子非常轻量级且可并行化,因此,论文的算法仍然比其他算法更快优化方法。
4. 实验
数据集:Middlebury、NYUv2、DIML
4.1实验步骤
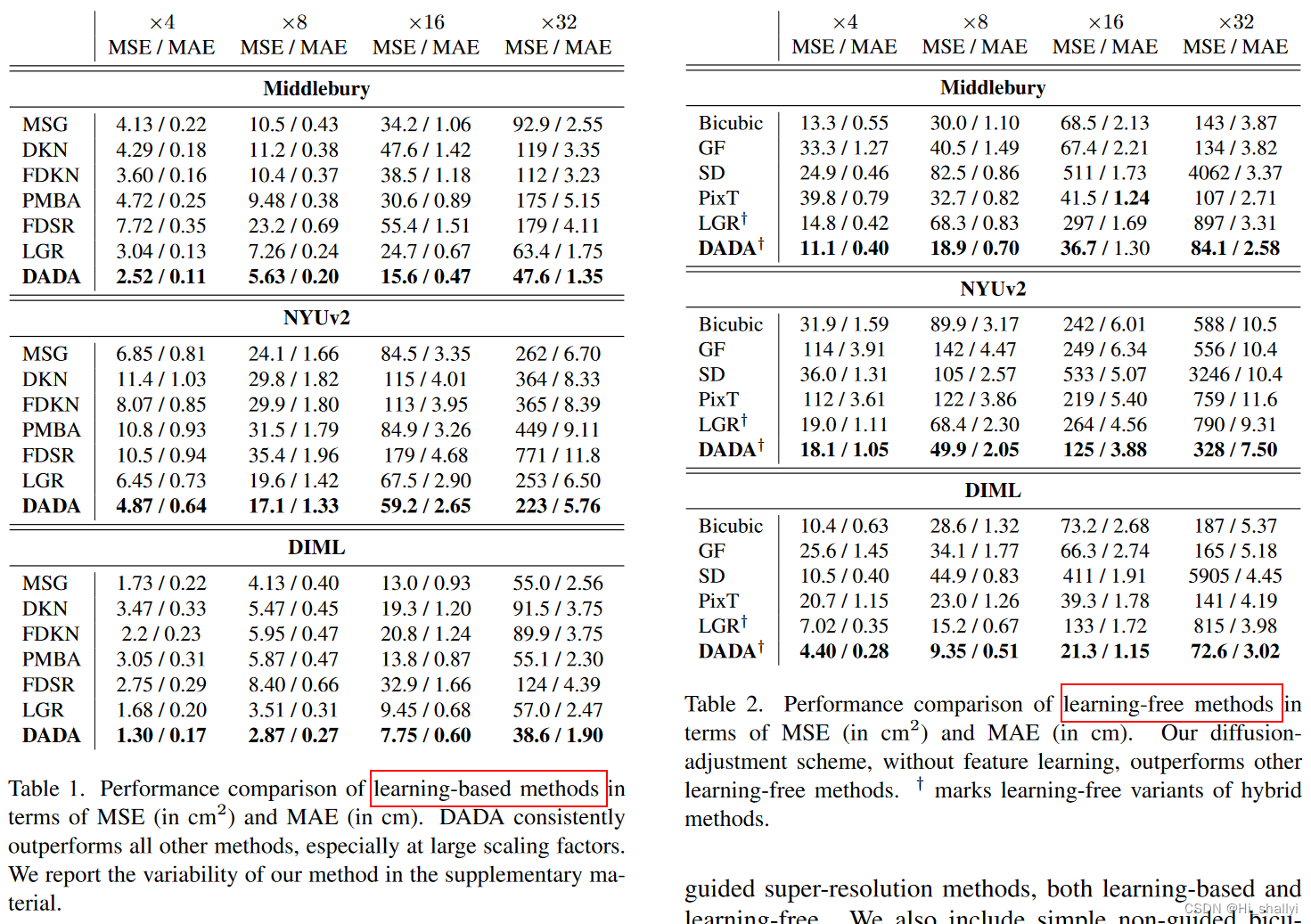
作者将深度各向异性扩散调整网络(DADA)与广泛的、有代表性的引导超分辨率方法(基于学习和非学习)进行比较。作者还包括简单的非引导双三次上采样(Bicubic)[17]作为基线和健全性检查。作者考虑的基于学习的方法有MSGNet(MSG)[15]、Deformable Kernel Network(DKN)[18]、Fast Deformable Kernel Network(FDKN)[18]、Fast Depth Super-Resolution(FDSR)[13]、PMBANet (PMBA) [47] 和学习图正则化器 (LGR) [5]。论文评估中的免学习方法包括引导过滤 (GF) [11]、静态/动态过滤 (SD) [10]、Pixtransform (PixT) [6] 和基于原始数据而不是学习到的特征的 LGR [5] 版本指南中的 RGB 值。以大致相同的方式,论文还使用从原始 RGB 值导出的扩散权重来运行扩散调整方案。对于×4到×16的上采样因子,分数直接取自[5],对于×32的比例,作者自己生成了所有结果,遵循[5]中描述的设置并使用他们的开源代码库。误差指标作者使用了预测深度图像的均方误差 (MSE) 和平均绝对误差 (MAE)。
作者的实验是使用 PyTorch [28] 进行的,使用 L1 损失函数训练所有方法,包括作者自己的方法。有关训练超参数的更多详细信息将在补充材料和代码中提供,以确保可重复性。对于 DADA 的免学习变体,论文设置 κ = 0.03(参见方程(2))。
4.2 实验结果
论文方法DADA与基于学习的方法和基于非学习的方法在指标MSE、MAE上的对比结果:
根据引导图片G的原始RGB值和深度特征计算得到的扩散矩阵/扩散系数C:

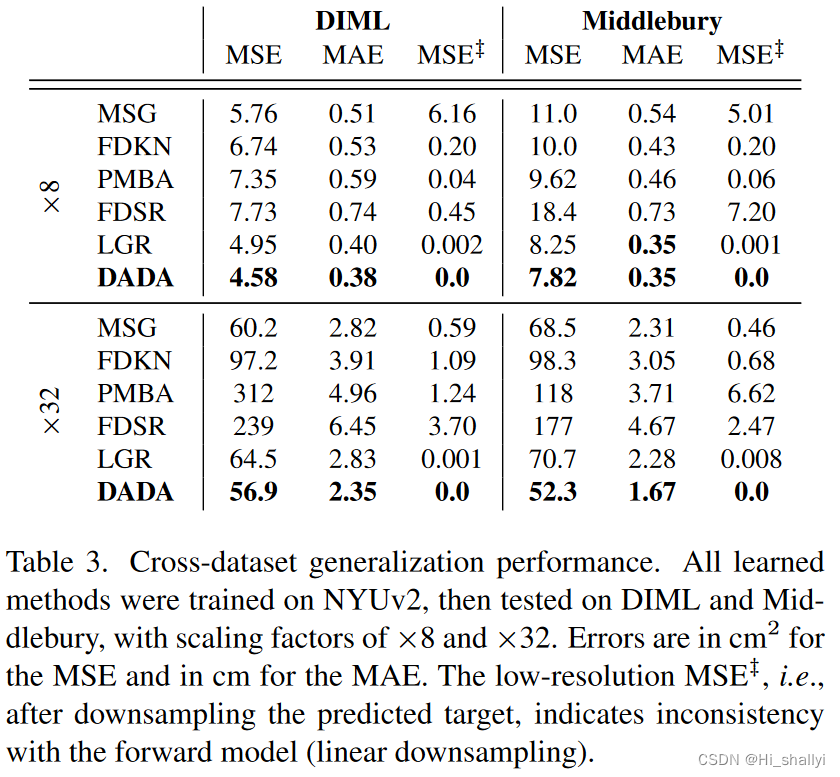
4.3 跨数据集泛化性能对比:
跨数据集泛化性能。所有学习到的方法在NYUv2上进行训练,然后在DIML和米德尔伯里上进行测试,缩放因子分别为× 8和× 32。MSE的误差单位为cm2,MAE的误差单位为cm。低分辨率MSE ć,即对预测目标进行降采样后,表示与前向模型(线性降采样)不一致。
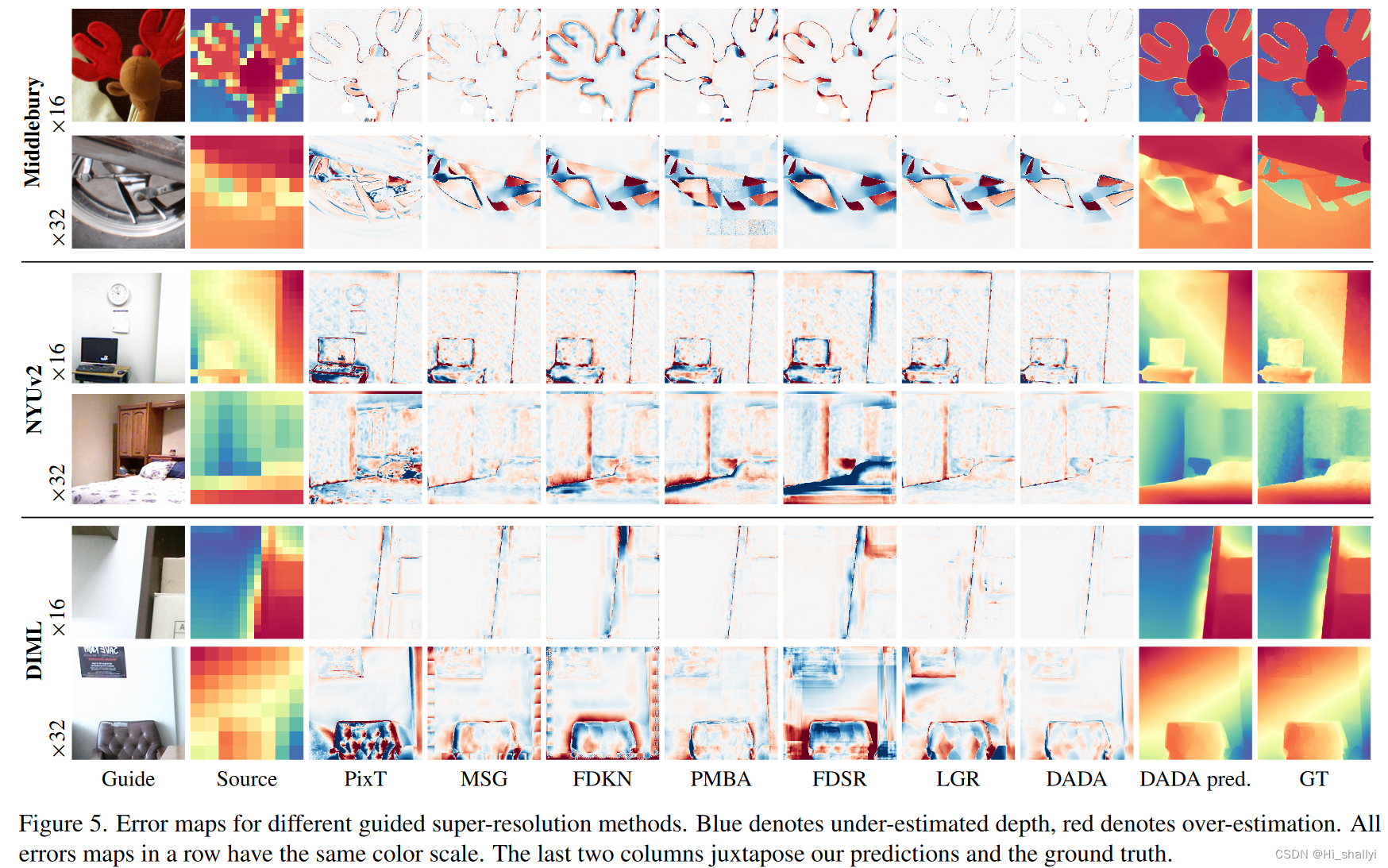
4.4 定性分析:
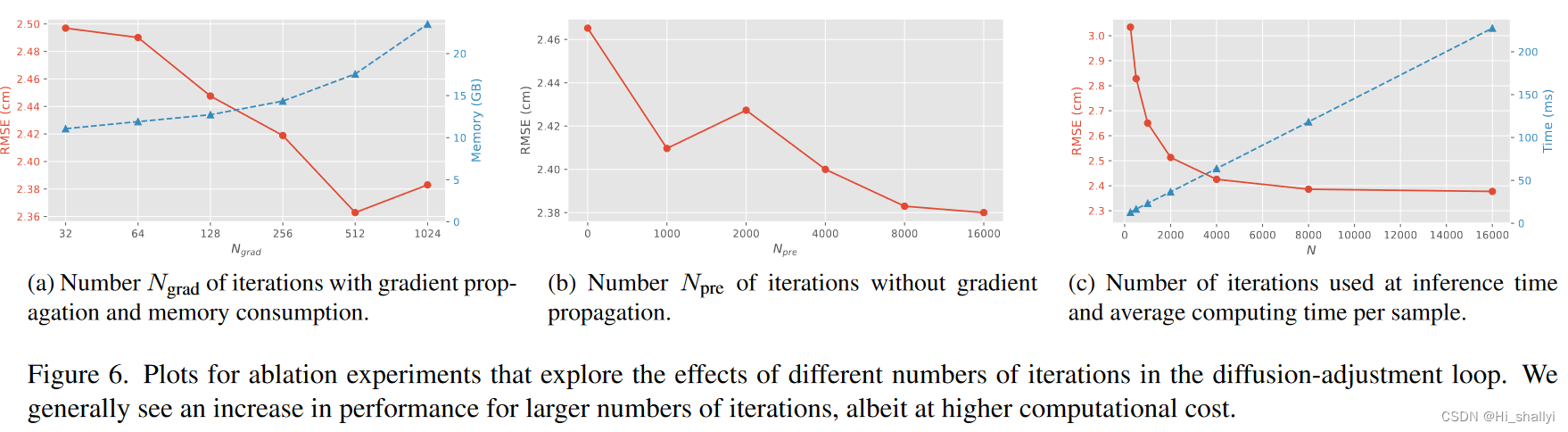
4.4 消融实验
绘制用于消融实验的图,探究扩散-调节回路中不同迭代次数的影响。一般情况下,迭代次数越多,性能越好,但计算成本也越高。















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









