







动机
目前的单目深度估计方法受主干网络分辨率的影响。训练数据的分辨率一本是几百×几百,而目前先进的相机上千万的像素分辨率。将当前方法直接扩展到高分辨率受到计算资源的限制。目前也有一些方法尝试解决这个gap:
(1)Guided Depth Super-Resolution (GDSR):使用高分辨率的RGB图像和低分辨率的深度图,深度超分辨。
(2)隐函数方法,如SMDNet,Nerf等,将场景或特征建模为一个隐函数,可以计算任意位置的0深度。
(3)BoostingDepth提出的基于切片的方法。整张图下采样和原分辨率的切片分别估计深度,然后统一处理合并切片。
作者主要提出BoostingDepth的一些缺点,尺度不一致、融合网络缺少有效全局引导。
提出了PatchFusion,端到端的基于切片的高分辨率深度估计方法。
方法
需要注意的是:这里深度估计的上下文(context),指的是估计出深度信息所必要的周围的信息,如纹理梯度等。
在低分辨率的数据集上训练预训练模型,然后用于切片的高分辨率深度估计。
融合模型
(1)Global Scale-Aware Estimation
将高分辨率图像降采样到模型原始分辨率,然后得到粗深度图Dc。
(2)Local Fine-Depth Estimation
将原始图像切片成模型输入相同或相近的分辨率,然后分片预测深度,得到Df,但是这样做忽略了全局信息,得到的分片深度图有伪影或者偏移。
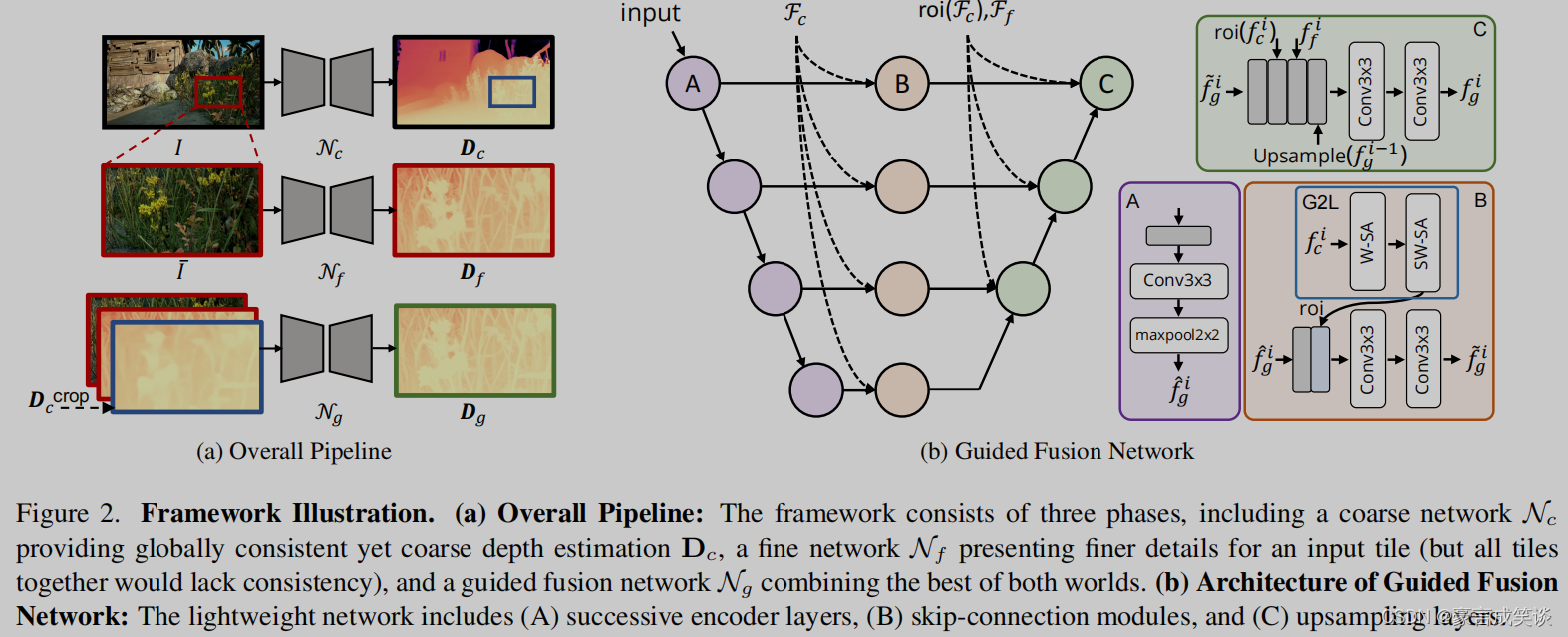
(3)Fusion and Guided Fusion Network
如图2中b所示,
G2L模块:如下图所示,保留全局的上下文。基于swintansformer,经过一个localized windows for self-attention (W-SA), which is then followed by shifted window attention for inter-window interactions (SW-SA).
输入是原始图像和对应的粗深度图的裁剪。模块A是简单的卷积层和池化的堆叠,输入原始分辨率图像的切片的堆叠,Dc和Df,(图a中最下面那个Ng就是b Guided Fusion Network)。模块A的输出和粗糙特征Fc输入模块B,Fc经过G2L模块,得到的特征,由于粗糙特征分辨率小,因此参考了mask-rcnn中的roi操作,将低分辨率的特征和高分辨率的切块特征对齐。然后再经过两个卷积。模块c的输入为B的输出,直接对粗糙特征使用roi,Ff和低尺度上采样。
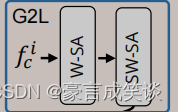
一致性感知训练和推断
训练
理论上,图四中重叠部分的特征和深度应该一致。因此计算重叠部分的损失如公式4所示。

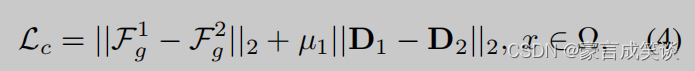
推断
如图10所示,P=16已经可以覆盖全部区域,并且在表1中表示为FP=16,但是这样分块不能发挥模型的全部潜力,并且前面的公式4也就没用了。因此设计了一个P=49的划分。另外一个改进是额外随机划分128个块,这些块随后和深度Dc和Df一起输入融合网络。
损失
尺度不变对数损失+0.1Lc(公式4)

实验
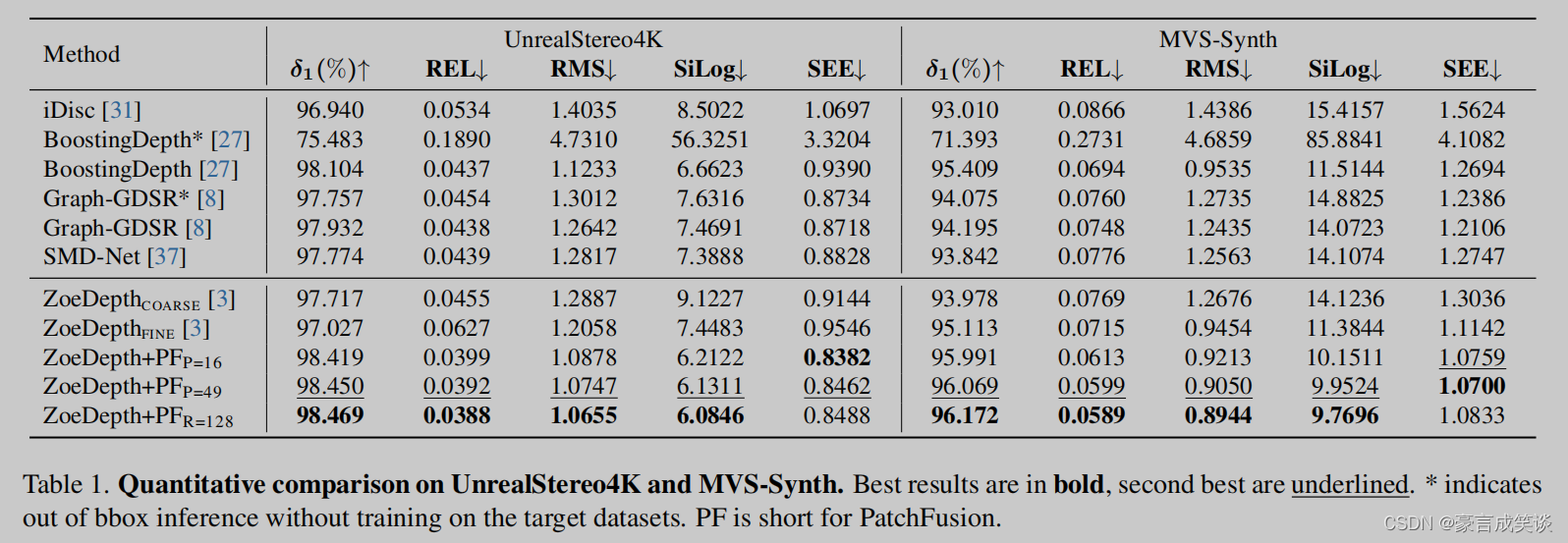
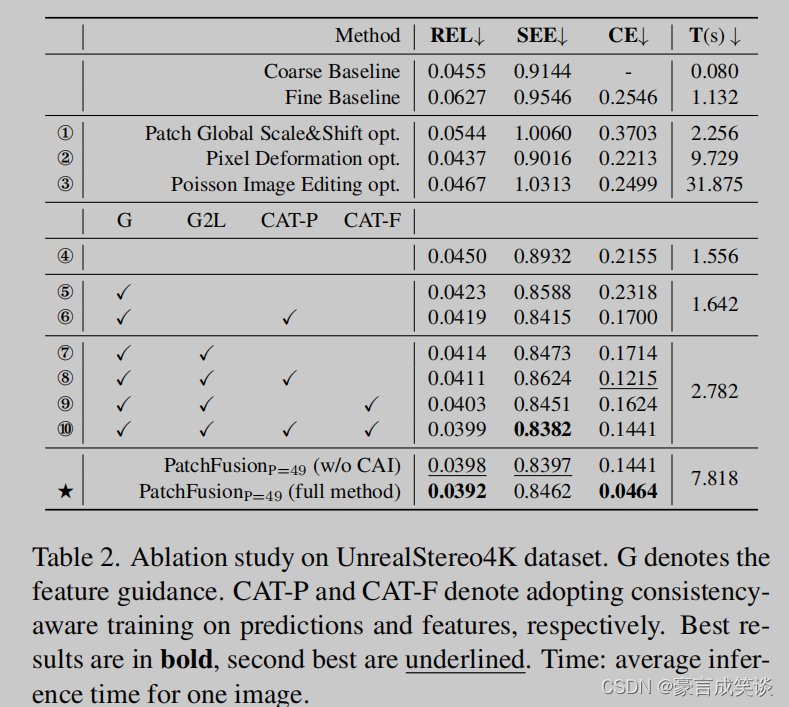
自对比实验1,2,3是和其他后处理策略的比较。
CAT-P和CAT-F是计算Lc时分别用特征和深度损失。
CAI表示是使用额外随机的切块。


















 2412
2412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









