







第2章 数据采集
本章学习目标
- 理解云计算及大数据的基本概念
- 掌握数据科学应用的工作流程
- 掌握浏览器的工作原理
- 熟知HTML语言的常用标记及http通信协议
- 熟悉web数据获取的基本原理及采集方法
- 初步掌握正则表达式,并能运用Python的正则表达式来解析网页数据
2.1 云计算与大数据
大数据催生云计算,从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式云计算架构。
2.1.1云计算(Cloud Computing)
云计算的产生背景:当前的主流信息系统在使用过程当中,不仅需要购买操作系统、平台软件、应用软件等,还需要很多配套的硬件实施及专业人员的运行维护,企业规模扩大时,还需要对软硬件设备进行升级以满足不断扩大的需求,特别是大型企事业单位,这些软硬件设备并不是他们的核心需求,而仅仅是作为工具来完成工作,提高工作效率而已。从个人的角度来看,使用计算机需要安装不同的软件,软件安装多了不仅系统运行慢,而且还需要一定的专业知识才能正确安装软件,且很多软件还需要购买序列号、注册等一系列流程,安装完成了甚至有可能使用频率极低。因此,如果有公司提供这些服务给客户租用,从使用者的角度来看,仅在使用时支付少量的租金即可满足相关需求。这就如同电力公司、煤气公司、自来水公司一样,由它们集中统一供给,并不需要每家每户自备发动机、水井等实施。云计算的最终目的就是将计算、服务和应用作为一种公共实施提供给使用者,使用者就像使用水电煤那样方便快捷。
云计算是分布式计算的一种,指的是通过网络“云”将巨大的数据计算处理程序分解成无数个小程序,然后,通过多部服务器组成的系统进行处理和分析这些小程序得到结果并返回给用户。云计算早期,简单地说,就是简单的分布式计算,解决任务分发,并进行计算结果的合并。因而,云计算又称为网格计算。通过这项技术,可以在很短的时间内(几秒种)完成对数以万计的数据的处理,从而达到强大的网络服务。
云计算是一个技术性很强的抽象概念,对云计算的解释有很多种描述,准确解释其内涵并不容易,云计算安全联盟CAS(Cloud Security Alliance)的解释如下:云计算的本质是一种服务提供模型,通过这种模型可以随时随地、按需的通过网络访问共享资源池的资源,这个资源池的资源内容包括计算资源、网络资源、存储资源等,这些资源能够动态的分配和调整,在不同的用户之间;灵活切换划分。凡是符合这些特征的IT服务都可以称为云计算服务。CAS的解释很好地描述了云计算的本质,美国国家标准和技术研究院即NIST(National Institute of Standards and Technology)则给出了一个云计算定义的标准“The NIST Definition of Cloud Computing / NIST Special Publication 800-145”,英文原文如下:The NIST Definition of Cloud Computing
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. This cloud model is composed of five essential characteristics, three service models, and four deployment models.
中文意译:云计算是一种能够通过网络以便利的、按需付费的方式获取计算资源(包括网络、服务器、存储、应用和服务等)并提高其可用性的模式,这些资源来自一个共享的、可配置的资源池,并能够以最省力和无人干预的方式获取和释放。这种模式具有5个基本特征,还包括3种服务模式和4种部署模式。NIST的定义如图2-1所示:
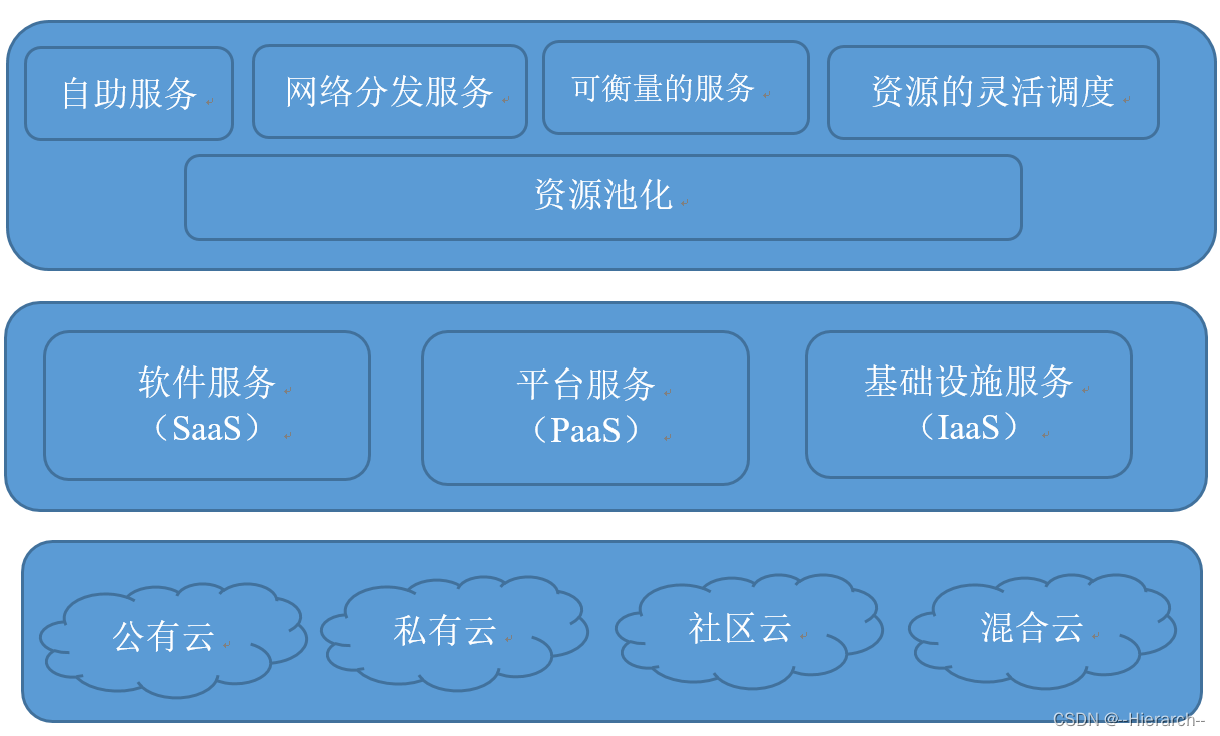
图2-1 NIST的云计算定义
从NIST的定义可知,云计算的服务类型分为三类,即基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。以下是这三种服务的描述如下:
(1)软件即服务(SaaS) (Software as a Service)
软件即服务是面向软件消费者的服务,用户无需安装即可使用云计算平台提供的软件。SaaS服务提供商将应用软件统一部署在服务器上,用户通过互联网按需订购应用软件,服务提供商根据客户定制的软件数量、使用时间等因素来收费,并通过浏览器向客户提供软件服务。,如Salesforce的CRM管理系统, Google的Gmail服务等。
(2)平台即服务(PaaS) (Platform as a Service)
平台即服务是面向软件开发者的服务,平台即服务把开发环境作为一种服务来提供,为开发人员提供通过互联网构建应用程序和服务的平台。PaaS为开发、测试和管理软件应用程序提供按需开发环境。云计算平台提供硬件, OS, 编程语言, 开发库, 部署工具, 帮助软件开发者更快的开发软件服务,如Google APP Engine、Salesforce的force.com平台等。
(3)基础设施即服务(IaaS)(Infrastructure as a Service)
基础设施即服务是一种通过网络按需提供给对所有设施的利用,包括处理、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序。这是一种托管型硬件方式,用户付费使用厂商的硬件设施。如Amazon的Web服务(AWS)、IBM的BluedCloud便是将基础设施作为服务出租。
2.1.2大数据(Big Data)
随着云计算时代的来临,大数据(Big data)吸引了越来越多的关注。麦肯锡全球研究对大数据所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。大数据的特色在于对海量数据的挖掘,它必须依托云计算的分布式处理、分布式数据库、云存储和虚拟化技术。大数据和云计算的联系如表2-1所示:
表2-1 大数据与云计算
| 云计算服务 | 大数据应用场景 | 实际应用 |
| 软件即服务(SaaS) | 分布式数据挖掘 | Mahout |
| 平台即服务(PaaS) | 分布式处理 | MapReduce、JobKeeper |
| 分布式数据库 | Hbase、数据立方 | |
| 基础设施即服务(IaaS) | 云存储 | HDFS、cStor |
| 虚拟化 | VMware、OpenStack |
大数据与云计算是相辅相存的关系,云计算为大数据提供了弹性可拓展的基础设备,是产生大数据的平台之一,另外物联网、移动互联网等新兴云计算方式的出现,更将助力于大数据革命,让大数据发挥出更大的影响力。
大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。结构化的数据的存储和排列是很有规律的,这对查询和修改等操作很有帮助。如数据库中的表。
半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。半结构化数据,属于同一类实体可以有不同的属性,即使他们被组合在一起,这些属性的顺序并不重要。常见的半结构数据有XML或者HTML格式。
非结构化数据:顾名思义,就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式。例如语音,视频都是非结构化的数据。

图2-2 大数据处理的流程
从上图可以看出,使用相关工具,对不同结构的数据源进行抽取和集成,按照一定的标准规范统一存储数据,数据使用人员利用数据分析技术对数据进行分析为决策提供支持。通过物联网产生、收集海量的数据存储于云平台,再通过大数据分析,甚至更高形式的人工智能为人类生产活动及生活所需提供更好的服务,这必将是第四次工业革命进化的方向。
2.2 超文本标记语言及传输协议
网站是由网页组成的,网页是构成网站的基本元素,是承载各种数据应用的平台,网页是一个包含HTML标签的纯文本文件,它可以存放于全球任意一台Web服务器中,网页要通过网页浏览器来阅读,在浏览网页时,需要在客户端通过网页浏览器向Web服务器发送请求,并接收来自Web服务器的响应。
2.2.1HTML超文本标记语言
超文本是一种信息的组织方式,它通过超级链接将文本中的文字、图表与其他信息媒体相关联。这些相互关联的信息可能在同一文本中,也可能在其他文件中,或地理位置相距遥远的某台计算机上的文件,使分布在不同位置的信息资源能够以随机方式进行连接,便于信息的查找和检索。编写超文本的语言HTML(Hyper Text Markup Language)称为超文本标记语言,是一种标识性的语言,它包括一系列标签,通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。HTML文本是由HTML命令组成的描述性文本,HTML命令可以说明文字,图形、动画、声音、表格、链接等。用HTML编写的超文本文档称为HTML文档,以.htm或.html作为扩展名,能独立于各种操作系统平台(如UNIX, Windows等)。
阅读HTML文本通常使用浏览器进行解释,浏览器是一种软件,它可以显示网页服务器或者文件系统的HTML文件内容,且用户可以与这些文件交互。浏览器主要通过HTTP协议与网页服务器交互并获取网页,这些网页由URL指定,文件格式通常为HTML,并由MIME在HTTP协议中指明。大部分的浏览器不仅支持htm或html格式,还支持JPEG、PNG、GIF等图像格式,并且能够扩展支持众多插件(plug-ins)。
2.2.2HTTP超文本传输协议
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW: World Wide Web )服务器传输超文本到本地浏览器的传送协议,它采用TCP/IP通信协议来传递数据(HTML 文件,图片文件,查询结果等),是一个属于应用层的面向对象的协议,由于其具有简捷、快速的特点,http协议广泛使用于分布式超媒体信息传输。
HTTP协议工作架构为客户端-服务器模式,客户端通过浏览器输入URL(网址)后向WEB服务器发送所有请求,Web服务器根据接收到的客户端请求后,向客户端发送响应信息,基本的工作模式如图2-所示。
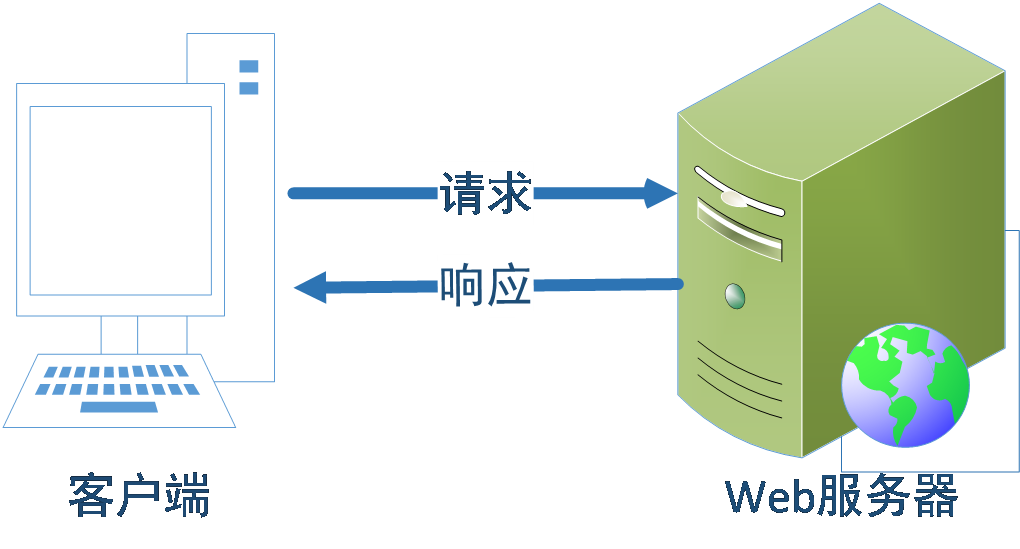
图2-3 http的客户端服务器工作模式
客户向服务器请求服务时,只需传送请求方法和路径,请求方法常用的有GET、HEAD、POST,每种方法规定了客户端与服务器联系的类型不同。每次连接只处理一个请求,服务器处理完客户端的请求,在客户端收到的应答后,即断开连接,这种通信方式可实现快速通信,节省数据传输时间。
URL是互联网上用来标识某一处资源的地址,HTTP使用统一资源定位符即URL(Uniform Resource Locator)来建立连接和传输数据。
新华网URL常用组成部分示例:
http://www.xinhuanet.com/politics/2020-06/18/c_1126127582.htm
“http:”为URL的协议部分为,这代表网页使用的是HTTP协议,“//”为分隔符。
“www.xinhuanet.com”为URL的.域名部分:,也可以使用IP地址作为域名使用。
“/politics/2020-06/18/”为虚拟目录部分,从域名后的第一个“/”开始到最后一个“/”为止,虚拟目录不是URL必须的部分。
“c_1126127582.htm”为文件名部分,文件名也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名。
用户在浏览器中输入网址并回车后便向Web服务器发送了一个HTTP请求,后续详细的工作流程如图2-4所示:
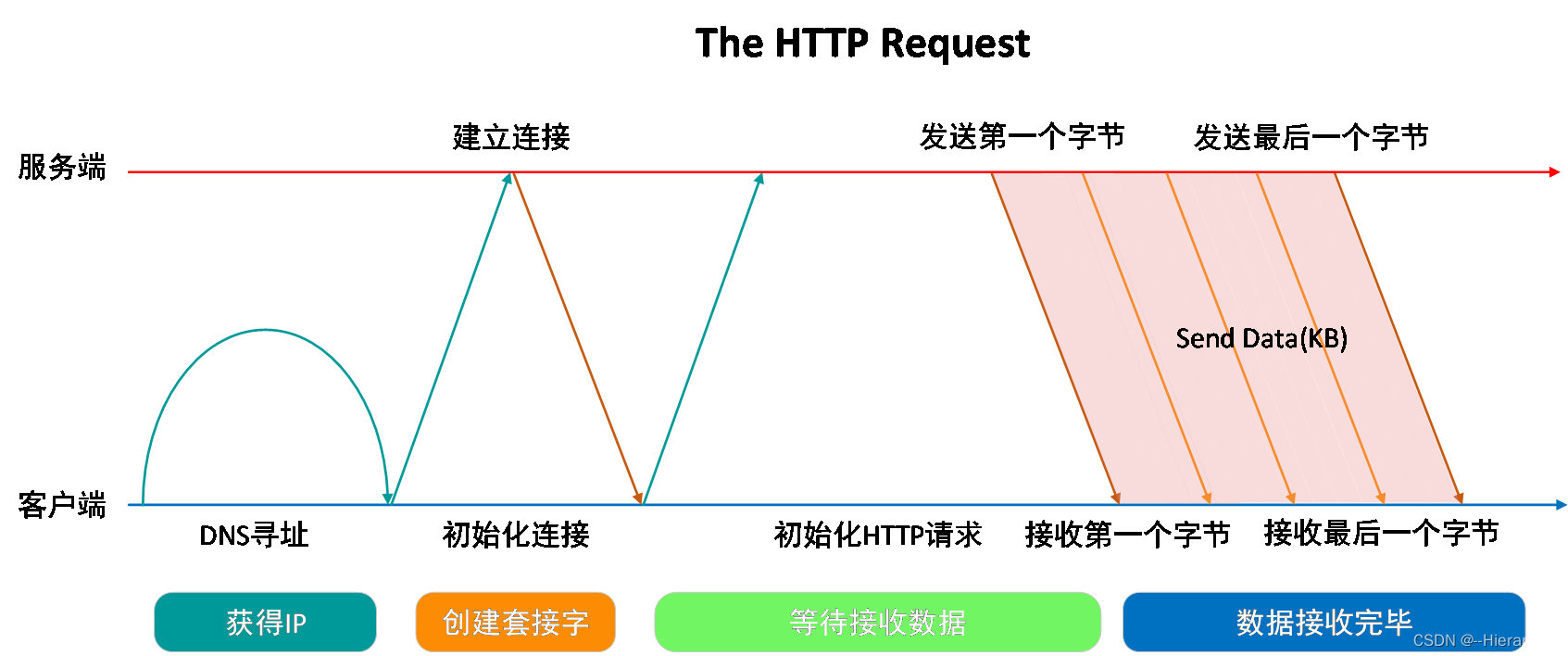
图2-4 http请求详细过程
首先浏览器通过DNS域名解析到服务器IP;
客户机通过TCP/IP协议建立到服务器的TCP连接;
客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档;
服务器向客户机发送HTTP协议应答包,如果请求的资源包含有动态语言内容,服务器会调用动态语言解释引擎负责处理“动态内容”,并将处理后的数据返回给客户端;
客户机与服务器断开,客户端解释HTML文档,在客户端屏幕上渲染图形结果;
一个简单的网页浏览就这样实现了,看似复杂,原理其实很简单,需要注意的是客户机与服务器之间的通信是非持久的,当服务器发送应答后就与客户端断开连接,等待下一次请求。
2.3简单网络爬虫原理
大数据的快速发展向我们展示了一个新的商业机会,每天面对Web网站及社交媒体的海量数据,如何利用技术手段采集这些数据并获取其商业价值呢?一个通用化的大数据处理框架,主要分为下面几个方面:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。
互联网存储有海量的数据,要想发挥这些数据的价值就必须进行数据分析,而数据分析的起点便是数据采集,人工采集显然无法适应海量数据,这就需要工具,网络爬虫便是一款高效获取数据的工具。网络爬虫(Web crawler)也称为(Web spider),它是通过脚本或者程序向服务器请求浏览网页,利用返回的网页信息的来提取数据。
网络数据采集是指通过网络爬虫或网站公开 API 等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。在互联网时代,网络爬虫主要是为搜索引擎提供最全面和最新的数据。在大数据时代,网络爬虫更是从互联网上采集数据的有利工具。目前市面上各种网络爬虫工具已经有上百种,大体分为三类:分布式网络爬虫工具,如 Nutch; Java 网络爬虫工具,如 Crawler4j、WebMagic、WebCollector;非 Java 网络爬虫工具,如 Scrapy(基于 Python 语言开发)。Google、百度等搜索引擎公司都是全天候地利用网络蜘蛛在互联网上爬行和抓取网页信息,并存入原始网页数据库。
网络爬虫访问web页面的过程类似普通用户使用浏览器访问其页面,即B/S模式,先向页面提出访问请求,服务器接受其访问请求并返回HTML代码后,抓取某个指定网页的数据并进行数据提取后保存于本地,一个简单爬虫的架构如图2-5所示:

图2-5 简单网络爬虫架构图
Python网络爬虫的实现可用脚本模仿浏览器向网站服务器发出网页浏览请求,服务器检验成功后返回网页信息,分析网页并提取所需的数据,保存数据。通常使用request库来发起请求,使用BeautifulSoup库和正则表达式来解析网页并提取数据,数据可根据需求保存为txt、csv、xlsx等格式文件。
大量的网络爬虫服务请求会造成服务器压力过大,使得网页响应速度变慢,影响网站的正常运行。所以网站一般会检验请求头里面的User-Agent(相当于身份识别)来判断发起请求的是不是机器人,通常可以通过自己设置User-Agent进行简单伪装,有些网站设置robots.txt来声明对爬虫的限制,如http://www.baidu.com/robots.txt ,通常我们应当遵守此规则。关于robots.txt 请查看The Web Robots Pages 。
2.4 正则表达式
正则表达式(regular expression)是由一些特定字符及其组合所组成的字符串表达式,用来对目标字符串进行过滤操作。正则表达式采用基本符号,以单个字符、字符集集合、字符范围、字符之间的组合等形式组成模板,然后用这个模板与所搜索的字符串进行匹配。
正则表达式通常被用来检索查找、替换那些符合某个模式(规则)的文本,如创建在文本中查找电子邮件或手机号码匹配模式、数据(格式)验证、替换字符内容以及提取字符串内容等。
使用正则表达式步骤:寻找规律;使用正则符号表示规律;提取信息,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。正则表达式对字符串的匹配模式有精确匹配(非贪婪匹配)和贪婪匹配两种模式。Python处理正则表达式的标准库为re。re库的核心函数如表2-2所示:
表2-2 re的核心函数
| 函数 | 说明 |
| compile() | 将正则表达式的字符串转化为Pattern匹配对象 |
| match() | 将输入的字符串从头开始对输入的正则表达式进行匹配,一直向后直到遇到无法匹配的字符或者到达字符串末尾,将立即返回None,否则获取匹配结果 |
| search() | 将输入的字符串整个扫描,对输入的正则表达式进行匹配,获取匹配结果,否则输出None |
| split() | 按照能够匹配的字符串作为分隔符,将字符串分割后返回一个列表 |
| findall() | 搜索整个字符串,返回一个列表包含全部能匹配的子串 |
| finditer() | 与findall方法作用类似,以迭代器的形式返回结果 |
| sub() | 使用指定内容替换字符串中匹配的每一个子串内容 |
标准函数的使用范式如下:
1.compile(pattern, flag=0),编译正则表达式pattern,然后返回一个正则表达式对象。
2.match(pattern, string, flag=0),函数描述:只从字符串的最开始与pattern进行匹配,匹配成功返回匹配对象(只有一个结果),否则返回None。
3. search(pattern, string, flag=0),与match()工作的方式一样,但是search()不是从最开始匹配的,而是从任意位置查找第一次匹配的内容。如果所有的字串都没有匹配成功,返回None,否则返回匹配对象。
4. findall(pattern, string [,flags]),查找字符串中所有出现的正则表达式模式,并返回一个匹配列表。
5. split(pattern, string, maxsplit=0, flags=0),参数 maxsplit 指定切分次数, 函数使用给定正则表达式寻找切分字符串位置,返回包含切分后子串的列表,如果匹配不到,则返回包含原字符串的一个列表。
6. sub(pattern, repl, string, count=0, flags=0),将正则表达式 pattern 匹配到的字符串替换为 repl 指定的字符串, 参数 count 用于指定最大替换次数。
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。Python中正则表达常用基本符号如表2-3所示:
表2-3正则表达式中常见的基本符号
| 基本符号 | 解释 |
| . | 匹配除了换行符(\n)以外的任意一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。 |
| ^ | 匹配开始位置,多行模式下匹配每一行的开始 |
| $ | 匹配结束位置,多行模式下匹配每一行的结束 |
| * | 匹配前一个元字符0到多次 |
| + | 匹配前一个元字符1到多次 |
| ? | 匹配前一个元字符0到1次 |
| {m,n} | 匹配前一个元字符m到n次 |
| \\ | 转义字符,跟在其后的字符将失去作为特殊元字符的含义,例如\\.只能匹配.,不能再匹配任意字符 |
| [] | 字符集,一个字符的集合,可匹配其中任意一个字符 |
| | | 逻辑表达式 或 ,比如 a|b 代表可匹配 a 或者 b |
| (...) | 分组,默认为捕获,即被分组的内容可以被单独取出,默认每个分组有个索引,从 1 开始,按照"("的顺序决定索引值 |
| \d | 匹配一个数字, 相当于 [0-9] |
| \D | 匹配非数字,相当于 [^0-9] |
| \w | 匹配数字、字母、下划线中任意一个字符, 相当于 [a-zA-Z0-9_] |
| \W | 匹配非数字、字母、下划线中的任意字符,相当于 [^a-zA-Z0-9_] |
| \s | 匹配任意空白字符, 相当于 [ \t\n\r\f\v] |
| \S | 匹配非空白字符,相当于 [^ \t\n\r\f\v] |
示例:如国内的固定电话号码的格式位区号3~5位,号码5~8位,正则表达式可设计为:’\d{3,5}\-\d{5,8}’或者r’d{3,5}-d{5-8}’。
一个完整的正则表达式应用示例如图2-6所示:
图2-6 正则表达式应用示例
上例列出了match、search、findall三个函数的用法,findall与match和search不同,findall函数查找所有的匹配结果并返回一个所有无重复匹配的列表,如果没找到匹配结果则返回一个空的列表。
代码如下:
import re
s="我是沈9哥,出生于1999年9月29日,我住在上海市奉贤区奉浦大道123号,6号楼309房间!"
pattern=re.compile('\d+') #匹配1或多个数字
result1=re.match(pattern,s)
result2=re.search(pattern,s)
result3=re.findall(pattern,s)
print(result1)
print(result2)
print(result3)
2.5数据采集的实践应用
网络爬虫是目前常用的数据采集工具,虽然大部分技术人员都会选择现成的http代理IP爬虫软件,但如果自己能够编写代码,就可以根据目标网站内容以量身定制的方式行数据采集,数据的采集将更加高效精准。用Python编制简单网络爬虫可以先用request来获取网页信息,然后采用正则表达式从网页中提取所需信息。
2.5.1HTML语言的应用
在文本编辑器中输入html代码,然后将文件另存为.htm或者.html格式文件,用浏览器打开后可按F12键查看源码。
1.新建一个文本文件,复制下面的代码并粘贴到文本文件中,并将“某人”换成你自己的名字,如图2-7所示。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>某人的网页</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
<a href="https://www.sbs.edu.cn/">超级链接到上海商学院</a>
</body>
</html>
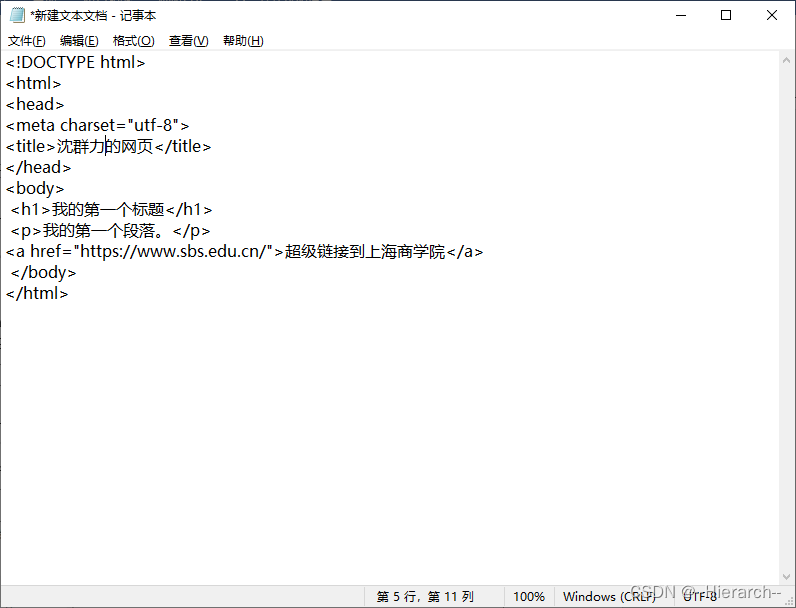
图2-7 文本文件中的html源代码
2.将文件另存为html格式的文件,如图2-8所示
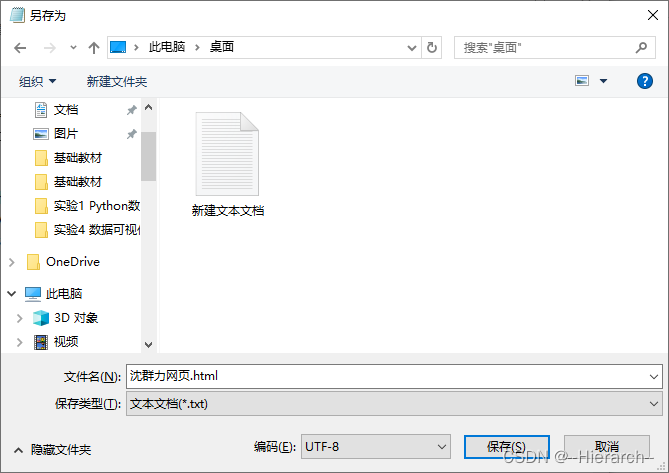
图2-8 另存为.html格式文件
3.用浏览器打开上述html格式文件,按F12键可开启调试模式查看HTML文件的组成标签。如图2- 9所示:

图2-9 浏览器中查看html文件
查看网页的标题和内容,理解html的原理。
代码解释:
<!DOCTYPE html> 声明为 HTML5 文档
<html> 元素HTML 页面的根元素
<head> 元素包含文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。
<title> 元素描述整个文档的标签
<body> 元素包含可见的页面内容
<h1> 元素定义文本中的大标题
<p> 元素定义文本中的段落
<a href="https://www.sbs.edu.cn/">表示文本中的超级链接
提示: "链接文本" 不必一定是文本。图片或其他 HTML 元素都可以成为链接。
2.5.2网页源码的下载
网络爬虫的一个重要功能是利用requests库来向网页服务器发送请求,服务器检查通过后将网页下载到本地,不同的语言有不同的编码方式,对中文简体网页来说,编码设置方式不正确尽管可以下载,但会显示乱码,可以通过浏览器查看网页源码中头文件(head部分)的charset的设置。
1.浏览器中输入上海市人民政府 上海市政府网站,在网页上右击从快捷菜单中选择“查看源”命令查看网页源码,源码开始部分可以看到charset=”gb2312”,表示该网页使用的是gb2312编码。如图2-10所示

图2-10 网站源码的查看
2.Jupyter Notebook中新建一个python文件,并输入如下代码:
import requests #导入requests库
urlAddress='http://www.shanghai.gov.cn/' #将网址赋值给变量url
htmlPage=requests.get(urlAddress) #利用requests库的get方法发起网页浏览请求,并将服务器返回的内容赋值给变量html
htmlPage.encoding = 'gb2312' #网页中文简体编码,将编码方式设定为gb2312,其他网页也有可能是UTF-8\gbk等,避免乱码
print(htmlPage.text) #屏幕显示
运行结果如图2-11所示:

图2-11 网页源码的获取
下载网页,首先需要导入requests库,然后使用get方法来发起网页请求,并将网站返回的网页信息存储在变量html中,不同的网站编码可能不同,如果编码设置不正确显示出来的结果有可能会出现乱码。
2.5.3用正则表达式解析网页
网页源码中包含的信息太多,还需要通过数据筛选来提取我们所想要的数据信息,可以设定一个规则来进行数据筛选即通过正则表达式来对网页进行解析,从而提取到自己所想要的数据。如新浪网左上角都有一些每天的新闻,想要获取这些新闻的标题及链接网址,就可以参照标题源码的数据特征来设计正则表达式,例如:.*?(匹配所有内容),正则表达式'<title>(.*?)</title>'就可以将网页的标题爬取下来。
1.浏览器中输入www.sina.com.cn ,打开新浪首页,查看右侧的新闻栏,如图2-12所示。

图2-12 新浪首页
复制浏览器中的网址可以得到新浪网 ,说明网页访问采用的是https通信协议。
2.在网页上右击从快捷菜单中选择“查看源”命令查看网页源码,在头文件里可以看到编码方式为utf-8。
3.网页源码的提取:在图2-10中新浪首页源码中可以看到右侧的新闻标题中“2020年全国计划招聘40余万名教师 希望是你”,(每天都会更新实验时复制一段当天的新闻标题即可)这段源码显示了标题新闻即链接的统一格式,我们抓取新浪标题新闻及链接等数据则需要利用这段代码来设计一个正则表达式,在源码中找到相关源码并复制:
<li><a target="_blank" href="https://news.sina.com.cn/c/2020-06-18/doc-iircuyvi9164465.shtml">2020年全国计划招聘40余万名教师 希望是你</a></li>
改写上述源码称为正则表达式如下:
regularExp =R'''<a target="_blank" href="https://.*?.shtml" class="linkNewsTopBold">.*?</a>'''
解释:开头字母r及R都可以,这是为了避免转义,使用原始字符串,.*?中的.表示匹配除换行符以外的任意字符,*表示匹配任意个数的字符包括0个,?表示开启非贪婪匹配模式。
标题新闻的源码信息如图2-13所示:

图2-13 标题新闻的数据格式
4.Jupyter Notebook中新建一个python文件,并输入下面的代码:
import requests
import re #导入re库,正则表达式
urlAddress='https://www.sina.com.cn/' #新浪首页通过https协议访问
htmlPage=requests.get(urlAddress)
htmlPage.encoding = 'utf-8' #源码里新浪编码格式:<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
#print(html.text)
#新浪标题新闻格式<li><a target="_blank" href="https://news.sina.com.cn/c/2020-06-18/doc-iircuyvi9164465.shtml">2020年全国计划招聘40余万名教师 希望是你</a></li>
regularExp=R'''<a target="_blank" href="https://.*?.shtml">.*?</a>''' #利用新闻标题源码设计正则表达式
pattern=re.compile(regularExp) #把常用的正则表达式编译成正则表达式对象,方便调用及提高效率
pageData=pattern.findall(htmlPage.text) #通过findall函数在html的文本即text中找到满足条件的字符串
print(pageData)
上述代码便是在python中利用一个正则表达来对网页中的数据进行解析提取,实现了一个简单爬虫的基本功能,运行结果如图2-14所示:
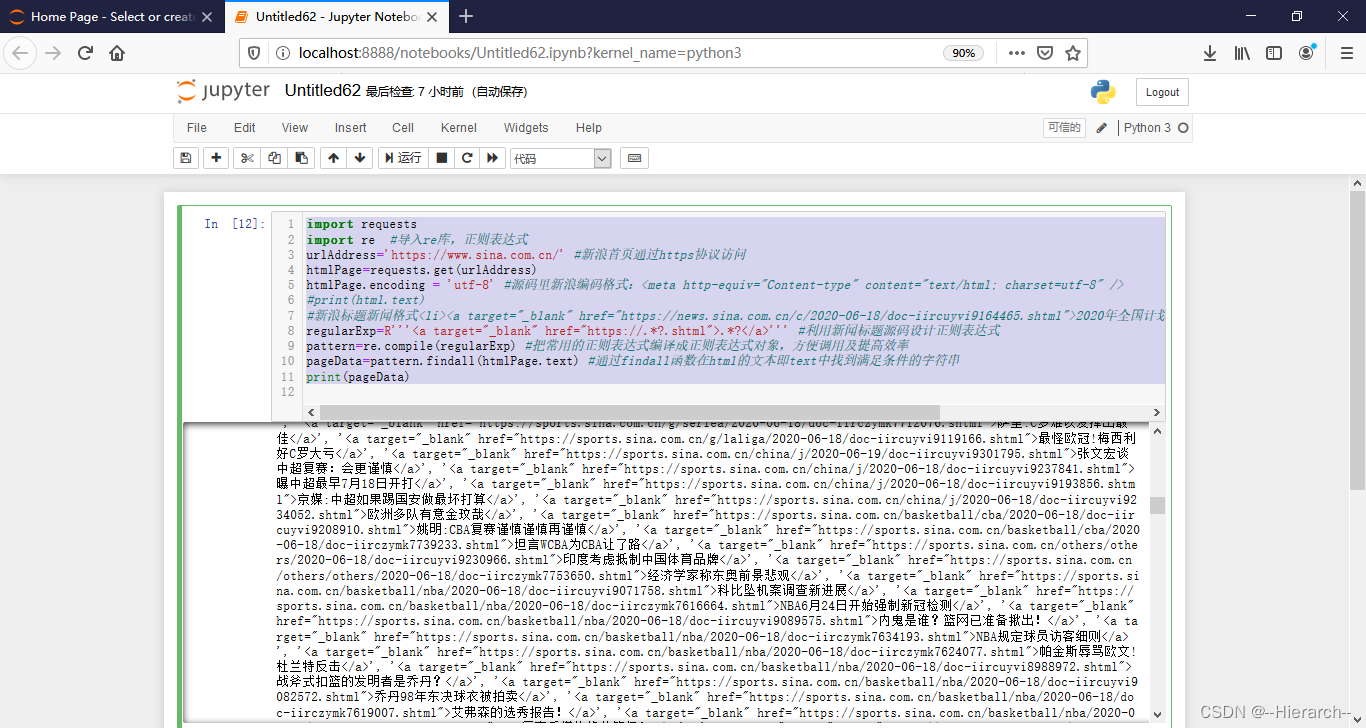
图2-14 抓取的标题新闻
从上面的示例可以看出,我们根据网页数据的特点,利用正则表达式来设计一个句法规则字符串,用于匹配与所给定规则字符串相似的数据信息,从而达到数据筛选的目的,获取我们想要的数据。利用正则表达式实现的简单爬虫仅适用于静态网页,复杂的爬取还需要调用第三方库。
本示例中爬取的数据可以写进相关文件中并存储于磁盘中,为后面数据分析提供数据源,这些内容在后面的章节中学习。
2.6本章小结
大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。大数据催生云计算,大数据与云计算是相辅相存的关系,云计算为大数据提供了弹性可拓展的基础设备,是产生大数据的平台之一。通过物联网产生、收集海量的数据存储于云平台,再通过大数据分析为人类生产活动及生活所需提供服务是未来工业发展的方向。最通俗的大数据处理框架便是:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。网络数据采集主要通过网络爬虫或网站公开 API 等方式来获取。正则表达式是由一些特定字符及其组合所组成的字符串表达式,用来对目标字符串进行过滤操作。网络爬虫的原理:用脚本模仿浏览器向网站服务器发出request请求,利用返回的网页信息提取数据。提取数据时需要先查看HTML源码,研究网页数据的基本特征,然后设计正则表达式来过滤数据,获取自己想要的数据。
2.7课后习题
1.单选题
(1)按照NIST的定义,下列服务不属于云计算提供的服务为( )
A.基础设施即服务(IaaS) B.平台即服务(PaaS) C.软件即服务(SaaS) D. 请求服务(request)
(2)以下( )属于非结构化数据
A. excel表格中数据 B.数据库中数据 C.视频 D.XML格式数据
(3)正则表达式常用符号中()表示单个字符。
A. . B. ? C. * D.+
(4)Python中使用正则表达式前需要导入( )库。
A. math B. re C. requests D.jieba
(5) URL是互联网上用来标识某一处资源的地址,https://www.sbs.edu.cn/xxgks/ztjs/index.htm中www.sbs.edu.cn属于URL的( )部分。
A.协议部分 B.虚拟目录 C.文件名 D.域名
2.填空题
(1) 是通过脚本或者程序向服务器请求浏览网页,利用返回的网页信息的来提取数据。
(2)通常大数据包括 、 、 三类数据。
(3) 是由一些特定字符及其组合所组成的字符串表达式,用来对目标字符串进行过滤操作。
(4)HTML中文称为 ,HTTP的中文称为 。
(5) 是由一些特定字符及其组合所组成的字符串表达式,用来对目标字符串进行过滤操作。
3.实践操作题
(1)新建一个.htm格式的文件,文档标签用你的学号加姓名,文档内容标题“???自我简介”,文档内容写上“我叫???,出生于????年,按中国的生肖我属?,来自于中国??省??市(县),目前在上海商学院????专业就读,上海商学院的校训为:厚德博学,经世济民!很高兴能和来之五湖四海的同学共同生活学习在这里,今天我以上商为荣,明天上商以我为荣,上商是我家,文明建设靠大家!”,并解释说明所使用的标记符号。(?用你的相关信息替代,可以参照其它网页的源码,给文字添加些你喜欢的颜色)
(2)编写一个简单程序,并显示同济大学主页的源码信息,首行用print语句输出(“我是+你的姓名+同学,我学会了如何用python程序查看网页源码!”)。
(3)修改程序,采集人民网(人民网_网上的人民日报)首页上部图片循环播放的当天标题新闻及链接网址,首行用print语句输出(“这是+你的姓名+同学用python设计的入门级爬虫!”)。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









