







前言
在具身智能领域,视觉 - 语言 - 动作(VLA)模型是机器人技术发展关键。但现有 VLA 模型在动作生成策略上问题突出:
自回归方法量化动作离散化,破坏动作连续性,影响高精度操作;
扩散方法依赖预训练视觉 - 语言模型特征提取,动态推理能力不足。且多智能体协作时,难以突破单任务局限实现动态协同;
本文以松灵PiPER机械臂和Franka Research 3机械臂为实验载体,通过HybridVLA框架,实现智能体间动态协同,从而有效克服现有VLA模型在动作生成策略及多智能体协作方面存在的困难。
技术框架与核心参数
机器人实验载体
松灵PiPER机械臂:
6轴自由度设计
松灵夹爪
英特尔 D435
Franka Research 3机械臂:
7自由度设计
前端Franka夹爪
技术框架
HybridVLA框架:融合扩散与自回归策略
协同训练方案
协同动作集成机制
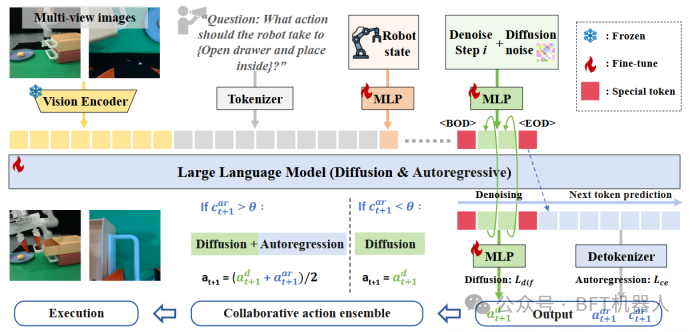
图2:HybridVLA框架。无论采用何种形式,输入数据都会被编码并连接到我们格式化的令牌序列中。为了将扩散集成到LLM中,HybridVLA同时将去噪时间步长和噪声动作投影到令牌序列中。标记标记<BOD>(扩散开始)和<EOD>(扩散结束)旨在弥合这两种生成方法。通过采用协作训练来明确地整合来自两种生成方法的知识,这两种动作类型相互强化,并自适应地组合在一起以控制机器人手臂。对于HybridVLA的输出,通过迭代去噪生成连续动作,而自回归生成离散动作,所有这些都在下一个令牌预测过程中进行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









