







前言
如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一
- 且个人认为,如果只是单纯针对叠衣服这个任务,个人认为还是VLA会表现的更好些
- 加之我其实很早就关注到了HybridVLA,只是一直没来得及解读它
故本文便来解读这个HybridVLA
且一如既往的,我在解读的时候 并不一会严格按照原论文的原始顺序、原始内容来,比如我把原论文中的:引言和相关工作 合二为一,如此,在避免一些论文名称重复出现的同时(因为引言与相关工作经常会提到同一篇论文、同一个领域的工作),使得本文的解读更加紧凑
第一部分 HybridVLA:统一视觉-语言-动作模型中的协同扩散与自回归
1.1 HybridVLA的提出背景与定义
1.1.1 引言与相关工作
第一,传统的机器人操作主要依赖于基于状态的强化学习
- 4-Learning dexterous in-hand manipulation
- 23- End-to-end affordance learning for robotic manipulation
- 42- Robotic grasping using deep reinforcement learning
- 109-Mastering visual continuous control: Improved data-augmented reinforcement learning
而相较之下,最新的方法
- 9-Rt-1
- 14-Diffusion policy
- 20-Mobile aloha
- 92- Behavioral cloning from observation
将视觉观测融入模仿学习
而这,得益于近年来VLM的迅猛发展
- 3-Flamingo
- 5- Qwen-vl
- 21-Llama-adapter v2
- 27-Sam2point: Segment any 3d as videos in zero-shot and promptable manners
- 41-Mme-cot: Benchmarking chain-of-thought in large multimodal models for reasoning quality, robustness
- 50- Llava-next-interleave:Tackling multi-image, video, and 3d in large multimodal models
- 51-Blip-2
- 58-Visual instruction tuning
- 112-Llama-adapter
- 113-Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems?
- 114- Mavis: Mathematical visual instruction tuning with an automatic data engine
VLM由于通过在互联网规模的图像-文本对上进行预训练,在指令跟随和常识推理方面展现出了卓越的能力,从而在近期出现了一系列研究,在VLM的推理能力基础上,将其应用于机器人操作领域
- 53-Crayonrobo: Toward generic robot manipulation via crayon visual prompting
- 59- Self-corrected multimodal large language model for end-to-end robot manipulation
- 106-Autonomous interactive correction mllm for robust robotic manipulation
- 107-Naturalvlm: Leveraging fine-grained natural language for affordance-guided visual manipulation
第二,在VLM的基础上,已有多项研究将VLM扩展为VLA模型,比如
- 一些研究 通过直接调用VLM已有的能力——无需微调VLM
1- Do as i can, not as i say
7-Rt-h: Action hierarchies using language.
18-Palm-e: An embodied multimodal language model
34-Voxposer: Composable 3d value maps for robotic manipulation with language models
35-Rekep
即可使机器人能够理解语言和视觉观测,并自动生成任务(动作)计划
- 且VLA模型可以利用VLM固有的推理能力,预测低层次的SE(3)位姿,且将连续动作量化为离散区间,并用这些区间替换大型语言模型(LLMs)中的部分词汇
RT2[10]将7自由度动作量化为离散区间,以实现自回归位姿预测
另还有56-Manipllm: Embodied multimodal large language model for object-centric robotic manipulation
这些自回归方法模仿VLMs的下一个token预测,有效地利用了其大规模预训练知识,同时保留了推理能力
尽管此类方法实现了通用的操作技能[47-Openvla],但量化过程破坏了动作姿态的连续性[97-Diffusion-vla: Scaling robot foundation models via unified diffusion and autoregression]即,自回归方法中的量化会破坏动作的连续性 - 另一方面,为了支持连续动作预测,一些VLA方法引入了策略头(如MLP或LSTM[25]),将LLM输出的嵌入向量转换为连续动作姿态——并采用回归损失进行模仿学习
33-Manipvqa: Injecting robotic affordance and physically grounded information into multi-modal large language models
54-Vision-language foundation models as effective robot imitators
60-Robomamba
100- Unleashing large-scale video generative pretraining for visual robot manipulation
然而,这些回归方法忽视了策略头的可扩展性,并未结合概率性动作表示(动作表征)
总之,VLA模型使机器人能够理解视觉观测和语言条件,从而生成具有泛化能力的控制动作。因此,有效利用VLM的内在能力,开发适用于动态环境中稳定操作的VLA模型至关重要[55-Towards generalist robot policies: What matters in building vision-language-action models]
第三,在内容生成领域,扩散模型已取得显著成功,比如
- 28-Can we generate images with cot? let’s verify and reinforce image generation step by step,带有CoT的图像生成
- 31-DDPM
- 32-Video diffusion models
- 73-Scalable diffusion models with transformers,即DiT
- 80-High-resolution image synthesis with latent diffusion models,即stable diffusion的奠基论文
受扩散模型在内容生成[31,32,73,80]领域成功的启发,扩散策略已被应用于机器人学,包括
- 强化学习[2,96]
- 模仿学习[14, 72,75,79,104],即被引入到机器人模仿学习中
14-Diffusion policy
45-3d diffuser actor: Policy diffusion with 3d scene representations
上面的这两个:3D DiffusionActor[45]和DP3[14]采用扩散模型来解析点云数据
72- Imitating human behaviour with diffusion models
75- Consistency policy: Accelerated visuomotor policies via consistency distillation
79- Goal-conditioned imitation learning using scorebased diffusion policies
104-Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic
manipulation
110-3d diffusion policy,即DP3 - 抓取
88-Relational pose diffusion for multi-modal rearrangement
94- Se (3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion
102-Learning score-based grasping primitive for human-assisting dexterous grasping - 和运动规划
38-Planning with diffusion for flexible behavior synthesis
82-Edmp: Ensemble-of-costs-guided diffusion for motion planning
此外,Octo[91]和RDT-1B[61]则通过在Transformer模型中加入扩散头,以预测灵活的动作
再进一步,发展出来了扩散VLA,与回归式确定性策略头不同,π0[8]、CogACT [52] 和 DiVLA[97] 在大型视觉语言模型VLM之后引入了扩散头,利用概率性噪声去噪机制进行动作预测
具体而言,为了将扩散机制与VLM集成
- π0[8] 增加了一个扩散专家头,通过流匹配生成动作
- 而 TinyVLA [98] 则在轻量级VLM之后引入了一个简单的扩散头
- CogACT[52] 和DiVLA [97] 分别将推理与动作预测解耦,分别由VLM和注入的扩散头负责
详见此文:《一文速览CogACT及其源码剖析:把OpenVLA的离散化动作预测换成DiT,逼近π0(含DiT的实现)》
尽管基于扩散的VLA方法实现了精确的操作控制,但扩散头与VLM是独立运行的,仅依赖VLM提取的特征作为输入条件。因此,这种方式未能充分发挥VLM的推理能力
——总之,在这些方法中,扩散头作为一个独立模块,仅依赖于LLM提取的特征来确定动作条件,从而限制了其对VLM预训练知识和推理能力的利用
除机器人领域外,在一般的多模态场景中
- 一些工作
22- Seed-x: Multimodal models with unified multi-granularity comprehension and generation
99-Janus: Decoupling visual encoding for unified multimodal understanding and generation
103-Vila-u: a unified foundation model integrating visual understanding and generation
105-Show-o: One single transformer to unify multimodal understanding and generation
共同解决多模态理解与生成问题 - 而另一些工作
12-Diffusion forcing: Next-token prediction meets full-sequence diffusion
115- Monoformer: One transformer for both diffusion and autoregression
116- Transfusion: Predict the next token and diffuse images with one multi-modal model
则将扩散机制引入自回归Transformer中
与以往在保持图像与语言生成各自质量的基础上进行结合的方法不同,HybridVLA 提出了一种面向机器人领域的协同训练方案,将基于扩散的动作生成无缝融入到单个 LLM 中的自回归动作生成中
1.1.2 HybridVLA:根据不同任务灵活切换是扩散预测,还是自回归预测
鉴于上述优点与局限性,一个问题随之产生:“如何优雅地构建一个统一的VLA模型,使其能够无缝整合自回归与扩散策略的优势,而不仅仅是简单地将二者拼接?”
为实现这一目标,来自北大、BAAI、港中文的研究者提出了HybridVLA
- 其对应的论文为:HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
其对应的作者为
Jiaming Liu1,2∗ , Hao Chen3 ∗ , Pengju An1,2† , Zhuoyang Liu1 † , Renrui Zhang3 ‡ , Chenyang Gu1,2, Xiaoqi Li1 , Ziyu Guo3 , Sixiang Chen1,2, Mengzhen Liu1,2, Chengkai Hou1,2, Mengdi Zhao2 , KC alex Zhou1 , Pheng-Ann Heng3 , Shanghang Zhang1,2 - 使VLM同时具备扩散和自回归动作预测能力,从而能够在多样且复杂的操作任务中实现稳健执行
与以往基于扩散的视觉语言动作(VLA)方法[8-π0,52-CogACT]不同,这些方法通常在大语言模型(LLM)后附加独立的扩散头
而HybridVLA则如图1所示,将扩散建模无缝集成到单一LLM的自回归下一个token预测过程中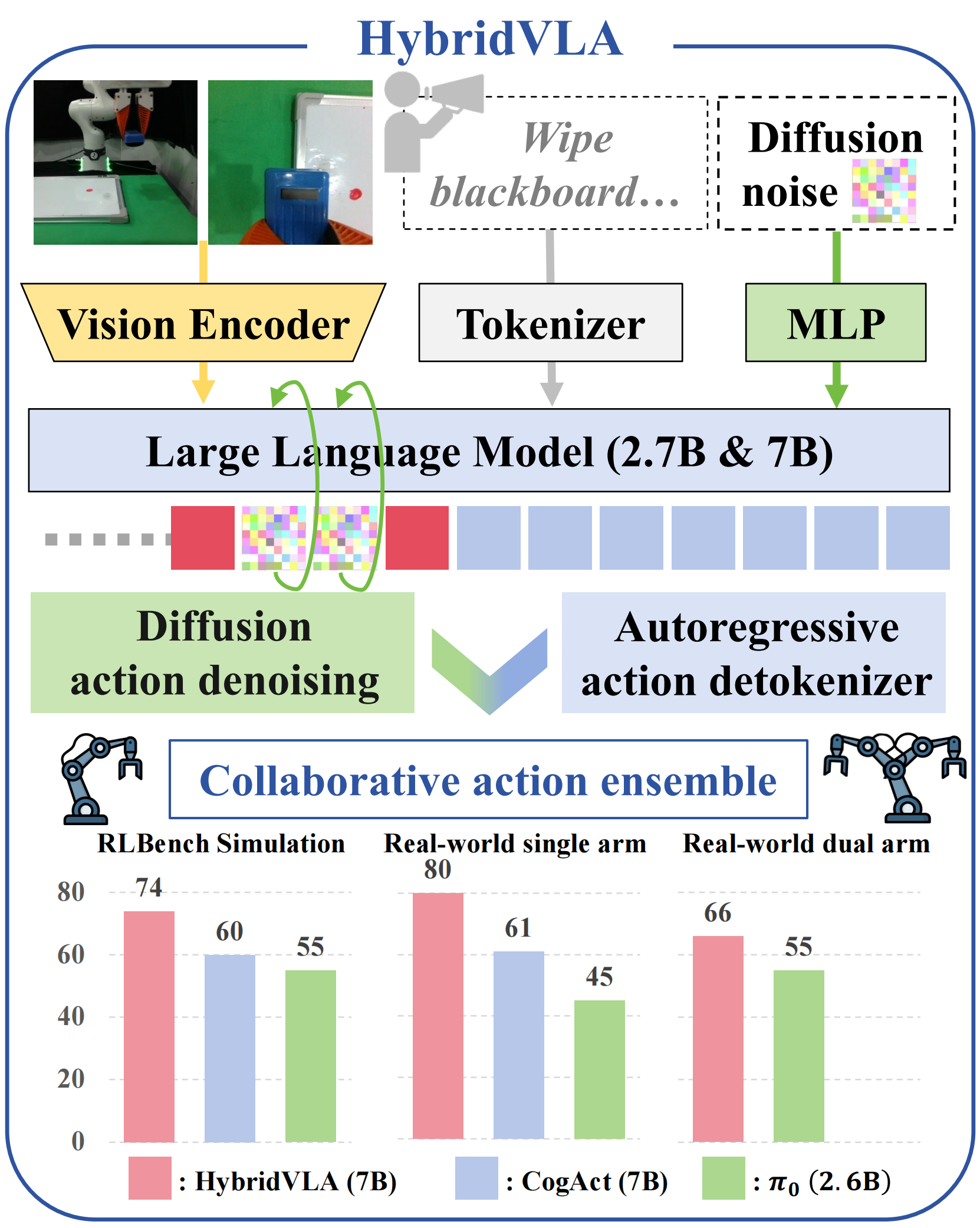
具体而言,作者引入了一种协同训练方案,将扩散噪声动作编码为连续向量,并将其投影到LLM的词嵌入空间
- 为确保在结合两种生成方法时的一致性,token序列构建旨在系统性地组织多模态输入、扩散动作和自回归动作token,并通过专用token符将它们关联起来
通过这种设计,作者观察到两种动作预测不仅能够相互强化,而且在不同任务上表现各异。例如,扩散预测在复杂任务中表现出色,而自回归预测则在需要丰富语义理解的任务中更为优越 - 如此,通过一种协同动作集成机制,根据自回归动作token的置信度自适应融合两种预测,从而提升操作的鲁棒性
为提升HybridVLA的泛化能力,作者采用了分阶段训练方法[8-π0],首先进行大规模预训练,随后在下游任务上进行微调,如图1顶部所示

除了以预训练视觉语言模型(VLM)[44-Prismatic vlms: Investigating the design space of
visually-conditioned language models]的参数进行初始化外,他们的模型还在大规模、多样化、跨形态的机器人数据集上进一步预训练,包括Open X-Embodiment[69]、DROID[46]和ROBOMIND[101],涵盖了76万条轨迹和超过1万小时的A800 GPU训练时间
- 随后,HybridVLA在高质量的仿真数据[36-Rlbench: The robot learning benchmark & learning environment]和自采集的真实世界数据上进行微调
- 且为优化推理速度,他们还引入了HybridVLA-dif,其在训练过程中融合了扩散和自回归生成,但在推理阶段仅依赖于基于扩散的动作,推理速度可达9.4Hz
1.2 HybridVLA的完整方法论
现有的基于扩散的VLA方法[8,52,97]通常在VLM之后附加一个独立的扩散头,利用VLM提取的特征作为扩散过程的条件
然而,这些方法未能充分利用VLM通过大规模互联网预训练所获得的内在推理能力
相比之下,HybridVLA为单一LLM同时赋予扩散和自回归动作生成能力
问题陈述
- 在时刻
,每个演示由图像观测
、语言描述
以及当前机器人状态
组成。作者的模型
旨在预测动作
以控制机器人手臂,其可表述为
- 按照[47,52],动作
每个7 自由度动作包括
)
)
)
- 真实值(GT)和模型预测的动作均在SE (3) 中,具体表述为
1.2.1 HybridVLA 架构:视觉编码器 + LLM
该系统提供两种模型规模,分别采用 2.7B 和 7B 大型语言模型(LLM)。参照文献 [47- Openvla],HybridVLA 继承了源自 Prismatic VLMs [44] 的基础架构,并充分利用其互联网规模的预训练参数
- 视觉编码器
HybridVLA 利用强大的视觉编码器组合,如DINOv2 [70] 和SigLIP [111],以捕捉丰富的语义特征和
B 和N 分别表示批量大小和token 维度
这些特征在通道维度上拼接,形成,随后通过投影层投射到LLM 的词嵌入中
至于HybridVLA(2.7B),则仅使用CLIP[77] 模型作为其视觉编码器。在处理多视角图像时,共享的视觉编码器提取特征,然后在token 维度上拼接 - LLM
HybridVLA 采用7B LLAMA-2 [93] 作为LLM,负责多模态理解与推理。语言提示通过预训练的分词器被编码到嵌入空间,然后与视觉tokens 拼接,并输入到LLM 中。其他专门设计的LLM输入将在下一节中介绍
输出的tokens 则通过两种方式进行处理
)通过去噪过程生成,其中MLP 将tokens 映射到动作空间
)生成通过detokenizer [47] 实现,同时计算动作tokens 的平均置信度(
),作为协同动作集成的引导因子
对于HybridVLA (2.7B),其工作流程与HybridVLA (7B) 相同,但使用2.7B Phi-2[39] 作为LLM
在下一节中,将介绍如何同时赋予单一LLM 扩散与自回归动作生成能力
1.2.2 协同训练方案
直接在单一大语言模型(LLM)中结合扩散和自回归姿态预测,会带来诸如不稳定性以及下一个 token 预测不一致等问题
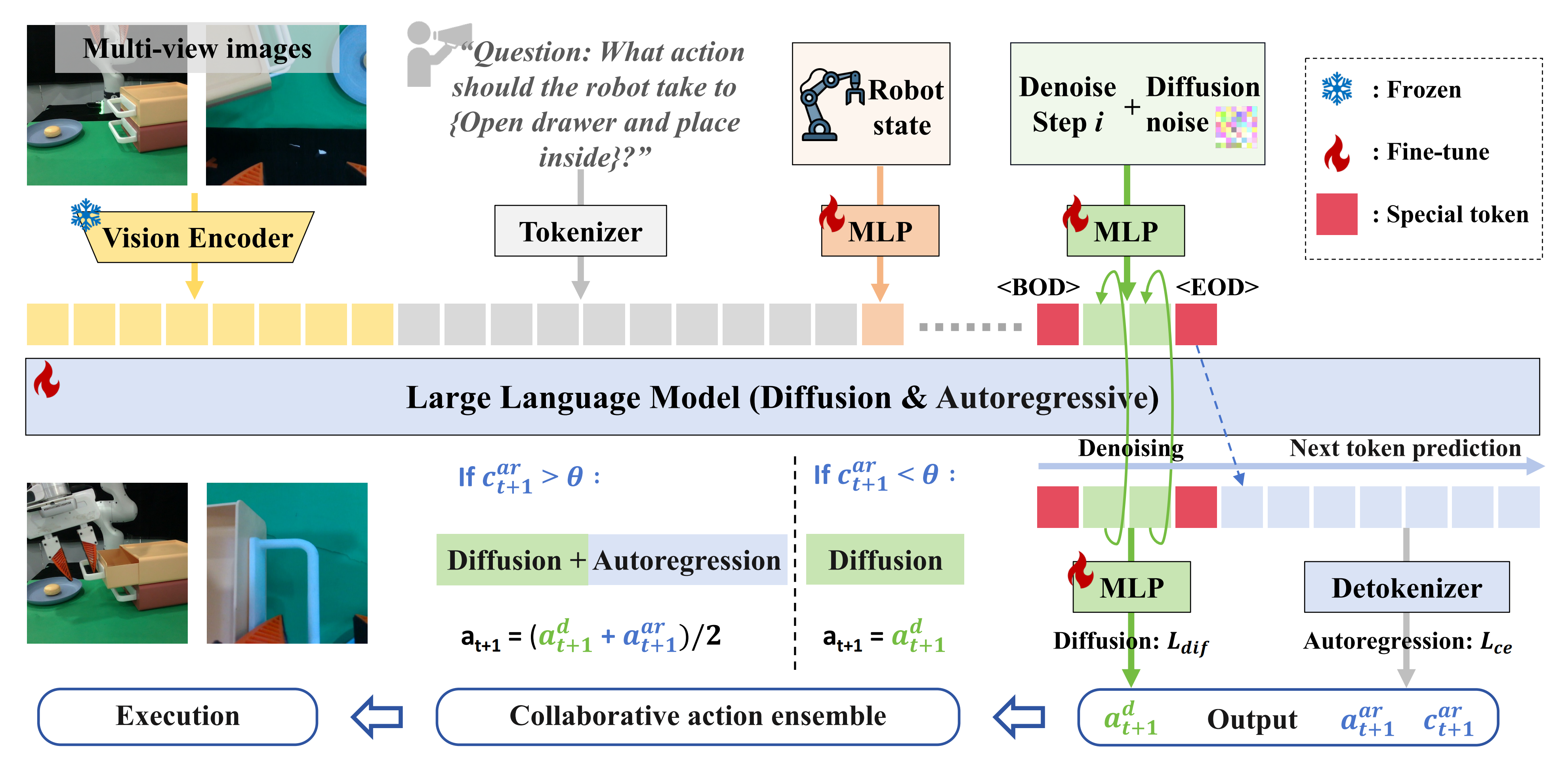
因此,作者提出了一种协同训练方案,涵盖了 token 序列构建设计、混合目标以及结构化训练阶段。Token序列构建设计
如图2 所示,在训练过程中,输入的token 序列包括:视觉token、语言token,还包括:机器人状态、扩散噪声、自回归动作token
- 对于机器人状态
作者将其集成到LLM 中,以增强动作生成的时序一致性。作者没有将机器人状态离散化并与语言查询合并[56](表1类型3)
而是采用可学习的MLP 将机器人状态直接映射到词嵌入空间,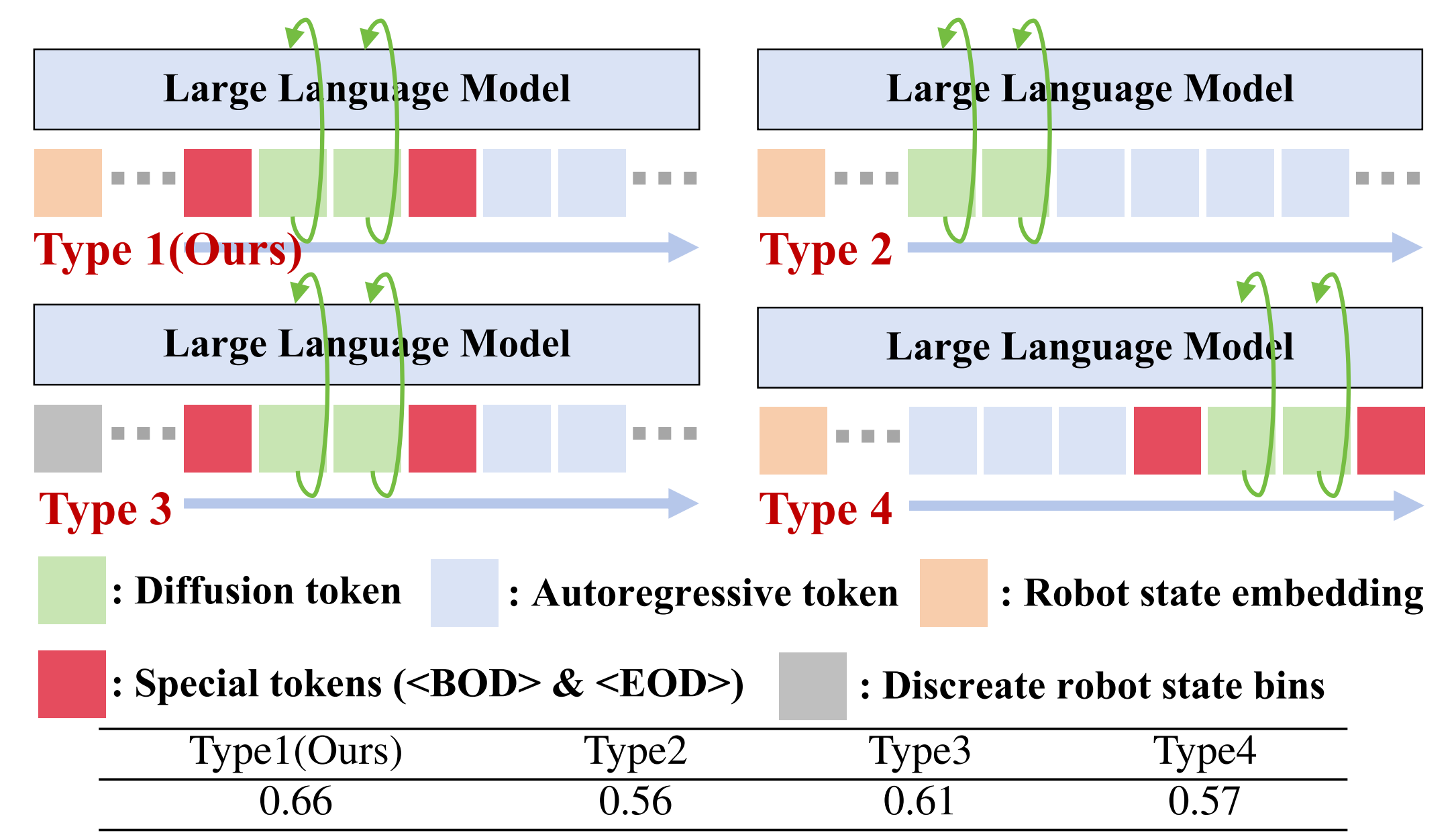
这样做的动机在于,扩散动作token 是在后续的下一个token 预测过程中生成的,使用所有先前的token 作为条件。引入离散的机器人状态可能会对连续动作的扩散预测产生负面影响 - 对于扩散动作
作者通过扩散去噪过程进行预测,条件依赖于前面的token。去噪步骤和带噪动作
通过MLP 投射到LLM 的词嵌入中,表示为连续向量
此外,为了在单一序列中无缝连接前面的多模态token、扩散token 以及后续的离散token,我们引入了特殊的扩散开始<BOD>和扩散结束<EOD>token 来包裹扩散token
这一设计不仅明确了扩散与自回归生成之间的边界,还防止了下一个token 预测过程中的混淆,例如扩散token 直接预测被mask 的离散token(表1 类型2) - 对于自回归动作
将末端执行器的位姿离散化为若干区间,并替换部分LLM [47]中的词汇表,随后将其分词为一系列离散token
由于下一个token预测的内在机制,在训练阶段会同时输入问题和答案(离散动作GT)到LLM中,而在推理阶段则仅输入问题
如果将自回归预测置于扩散token之前,将导致动作GT泄漏,从而成为扩散训练的条件(见表1类型4)
因此,将扩散token显式置于前方,为后续的自回归生成提供连续知识
对于混合目标,为了同时训练扩散和自回归动作生成,需要两个不同的损失函数
- 对于扩散部分,遵循之前的扩散策略[14],最小化VLA 模型预测噪声(
) 与真实噪声(
) 之间的均方误差
损失函数定义如下
其中,
表示条件
此外,为了确保机器人手臂的稳定行为[61],未使用classifier-free guidance[30] - 对于自回归部分,采用交叉熵损失(Lce) 对离散输出进行监督
通过作者设计的token 序列表达方式,以上这两种损失可以无缝结合,实现协同惩罚,定义如下:
之后,便是结构化训练阶段
在加载了预训练的VLM参数后,HybridVLA经历了两个结合多种目标的训练阶段:
- 首先是在开源机器人数据上进行大规模预训练
在预训练阶段,在来自Open X-Embodiment [69]、DROID [46]、ROBOMIND [101]等的35个数据集上对HybridVLA进行了5个epoch的训练
预训练数据集包含76万条机器人轨迹,总计3300万帧 - 然后在自采集的仿真和真实世界数据上进行微调
由于数据集之间存在差异预训练仅依赖于单一的二维观测,而微调则根据下游任务的不同,依赖于单一或多视角观测。预训练数据集的详细信息见附录A
1.2.3 协作动作集成
在推理过程中,给定视觉、语言和机器人状态输入,HybridVLA 同时采用扩散方法和自回归方法生成动作,然后对动作进行集成,以实现更稳定的执行
- 自回归动作
如图2所示
自回归生成在特殊token之后开始。与文献[47,56]类似,7自由度或14自由度动作的生成过程与大语言模型中的文本生成过程高度相似
与以往的自回归VLA方法不同,HybridVLA的自回归生成还基于扩散token中动作固有的连续性,这一方法在消融实验中表现优于独立自回归方法 - 扩散动作
当生成扩散动作时,作者在前置条件token后添加特殊token ⟨BOD⟩,以指示模型应执行去噪过程
具体而言,作者采用DDIM [89] 采样,并设置采样步数为n。在HybridVLA 中,作者发现将扩散过程整合到下一个token 预测过程中,不仅通过充分利用VLM 的推理能力和预训练知识提升了动作精度,还减轻了在减少推理去噪步数时(例如,n = 4)的性能下降,如消融实验所示
为加速采样过程,作者在扩散token 前引入KV 缓存,仅在初始采样步骤中转发条件信息、去噪时间步和纯噪声
在后续步骤中,重复利用第一次传递中缓存的key 和value,仅迭代转发时间步和噪声。这一策略消除了冗余计算并提升了推理速度
此后是集成动作
在采用他们的协作训练方案获得两种类型的动作后,作者在实证中观察到两个现象
- 不同类型的动作在不同任务中表现出不同的性能
基于扩散的预测在精确操作类任务中表现优异,如Phone on base和Close laptop lid
而自回归预测在需要场景语义推理的任务中表现更好,如Water plants 和Frame offhanger - 自回归动作token 的置信度可以作为动作质量的可靠指标。在超过80 % 的成功测试样本中,自回归动作token 的平均置信度超过0.96。定量评估结果见附录B.1 和B.2
因此,如图2 末尾所示
作者使用自回归token 的平均置信度(
比如如果置信度超过θ (θ = 0.96)——即自回归动作(
否则,作者仅依赖扩散动作来控制机器人
此外,为了加速推理,HybridVLA-dif 在推理过程中仅依赖基于扩散的动作生成,但在训练过程中仍协同学习两种动作生成方式,以增强相互促进作用
// 待更


















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











