







在自然语言处理(NLP)中,去停用词是一个重要的预处理步骤。停用词是指在文本中频繁出现但对于文本分析没有太多实际意义的词汇,如英语中的“the”、“is”、“and”等,以及中文中的“的”、“了”、“和”等。以下是关于去停用词的详细介绍:
一、停用词的定义
停用词是在信息检索和文本处理过程中被忽略的词语,它们通常是高频出现且缺乏实际含义的词汇。这些词汇对于文本的含义分析没有太大贡献,且会占据大量的存储空间和计算资源。停用词都是人工输入、非自动化生成的,生成后会形成一个停用词表。
二、去停用词的作用
①提高处理效率:停用词通常是频繁出现的功能词或无实际意义的词语,剔除停用词可以简化文本数据,降低数据维度,从而减小计算负担并提高处理效率。
②减少噪声:剔除停用词可以减少文本中的噪声,使得后续的文本分析更加准确和有效。
③突出关键信息:通过剔除停用词,可以使得文本中的关键词更加突出,有助于提取和理解文本的主题和关键信息。
④优化模型性能:在自然语言处理任务中,如文本分类、情感分析、主题建模等,去停用词可以提高模型的准确性和效率。
三、具体步骤
Step1:加载停用词表
(推荐使用哈工大停用词表,不仅有常用停用词还有一些常见标点符号)
with open('哈工大停用词表.txt', encoding='utf-8') as f: # 打开停用词表
con = f.readlines()
stop_words = set() # 集合可以去重
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
stop_words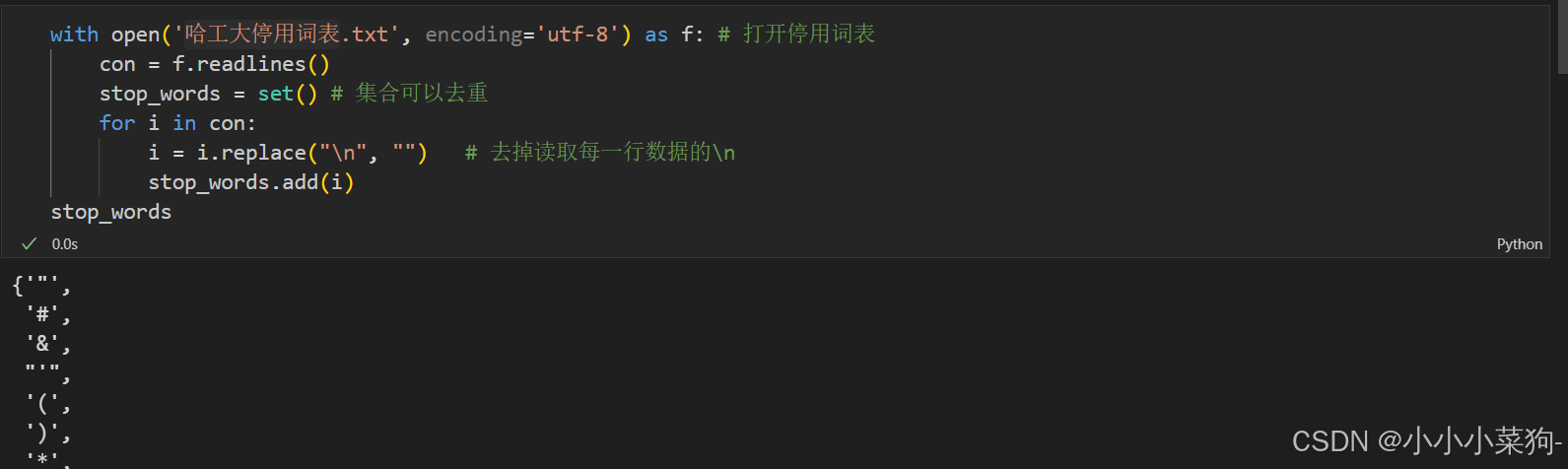
Step2:去除停用词
(代码逻辑很简单就是在分词中循环寻找不在停用词表中的词)
import jieba
text3 = '中午我去看了部电影,实在太好看了!'
result = []
for word in jieba.lcut(text3):
if word not in stop_words:
result.append(word)
result
result2 = []
for word in result:
if word not in stop_words and len(word) > 1:
result2.append(word)
result2Step3:经过Step2,可以看到,像“去”“看”“部”这样的词语队并没有什么价值,需要我们加条件去除,代码逻辑就是判读字的长度是否大于1,去除停用词后的语句是不是更有价值了呢?

四,代码封装
为了便于应用,将去除停用词封装成一个函数,用时只需要调用即可
import jieba
def word_cut(text):
jieba.initialize() # 初始化jieba
# 文本分词
seg_list_exact = jieba.lcut(text)
result_list = []
# 读取停用词库
with open('哈工大停用词表.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
# 去除停用词并且去除单字
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
return result_listword_cut('中午我去看了部电影,实在太好看了!')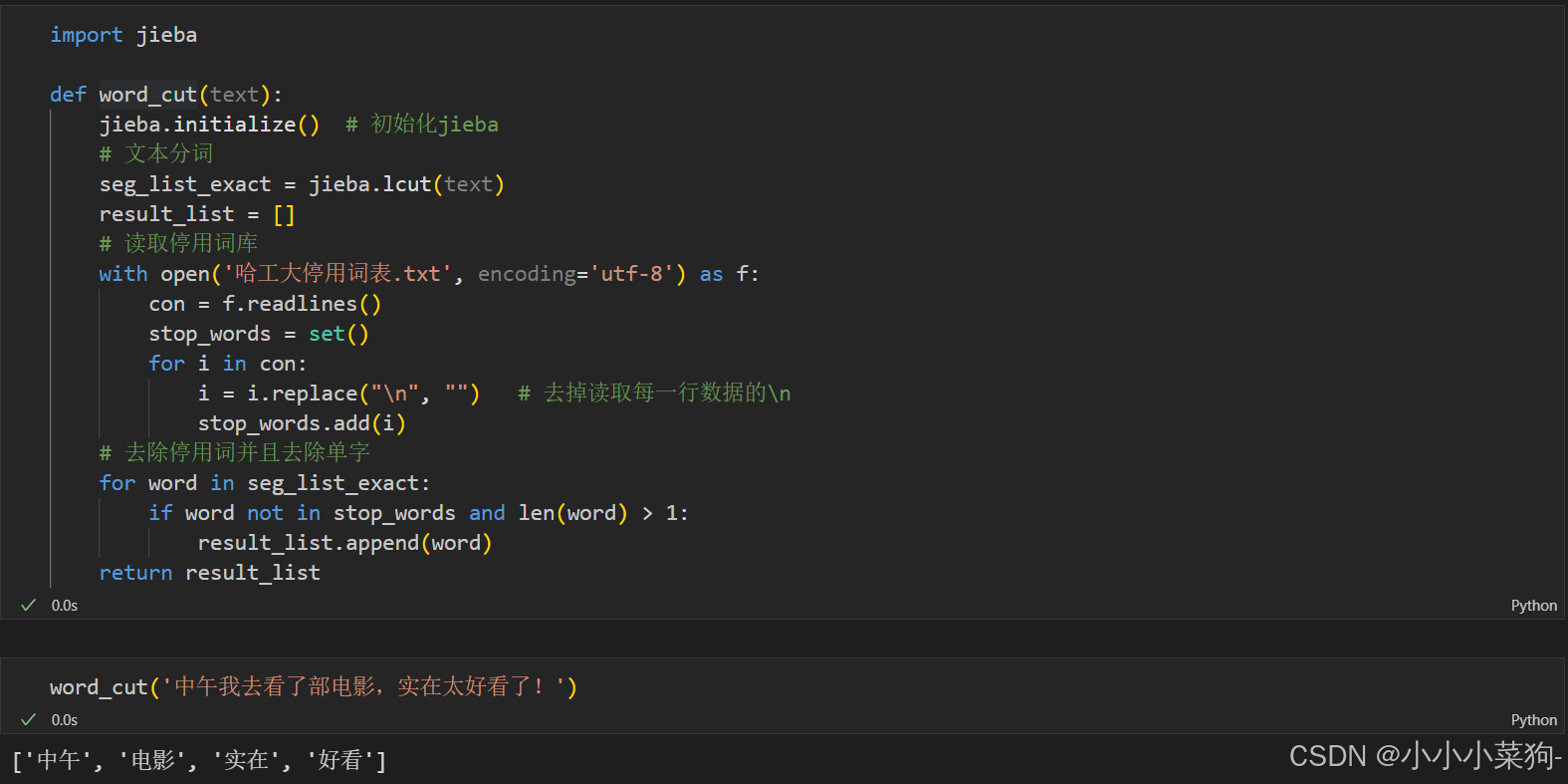


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









