






Flash Attention 介绍
FlashAttention 是一种优化的自注意力(Self-Attention)机制,主要用于加速 Transformer 模型的计算,同时降低显存占用。它是由 Tri Dao 等人 在 2022 年提出的,核心思想是通过 块稀疏计算(block-sparse computation)和 I/O 高效优化(I/O-aware optimizations) 来提高计算效率。
Flash Attention 安装
为方便演示,我在AutoDL上新创建了一个实例,配置如下:

这里需要注意的是python、pytorch、cuda的版本,根据这三者的版本,到flash-attention release 中寻找合适的版本。
我的环境为python==3.10 / torch==2.1.2 / cuda 11.8,因此选择下图这个版本(其他版本也可以选)
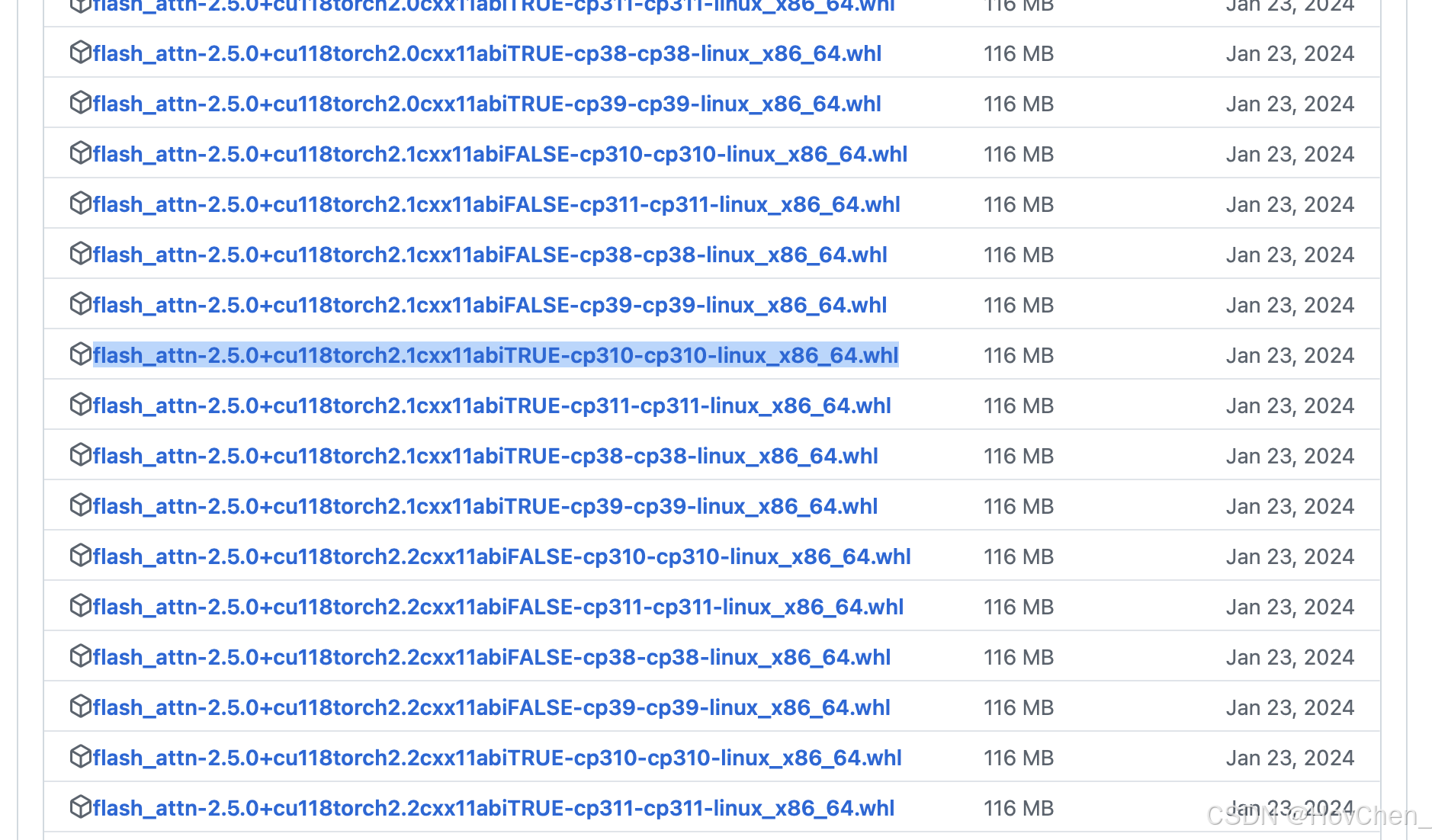
复制链接,在服务器的终端输入wget + 链接,即可下载到当前目录下。
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.0/flash_attn-2.5.0+cu118torch2.1cxx11abiTRUE-cp310-cp310-linux_x86_64.whl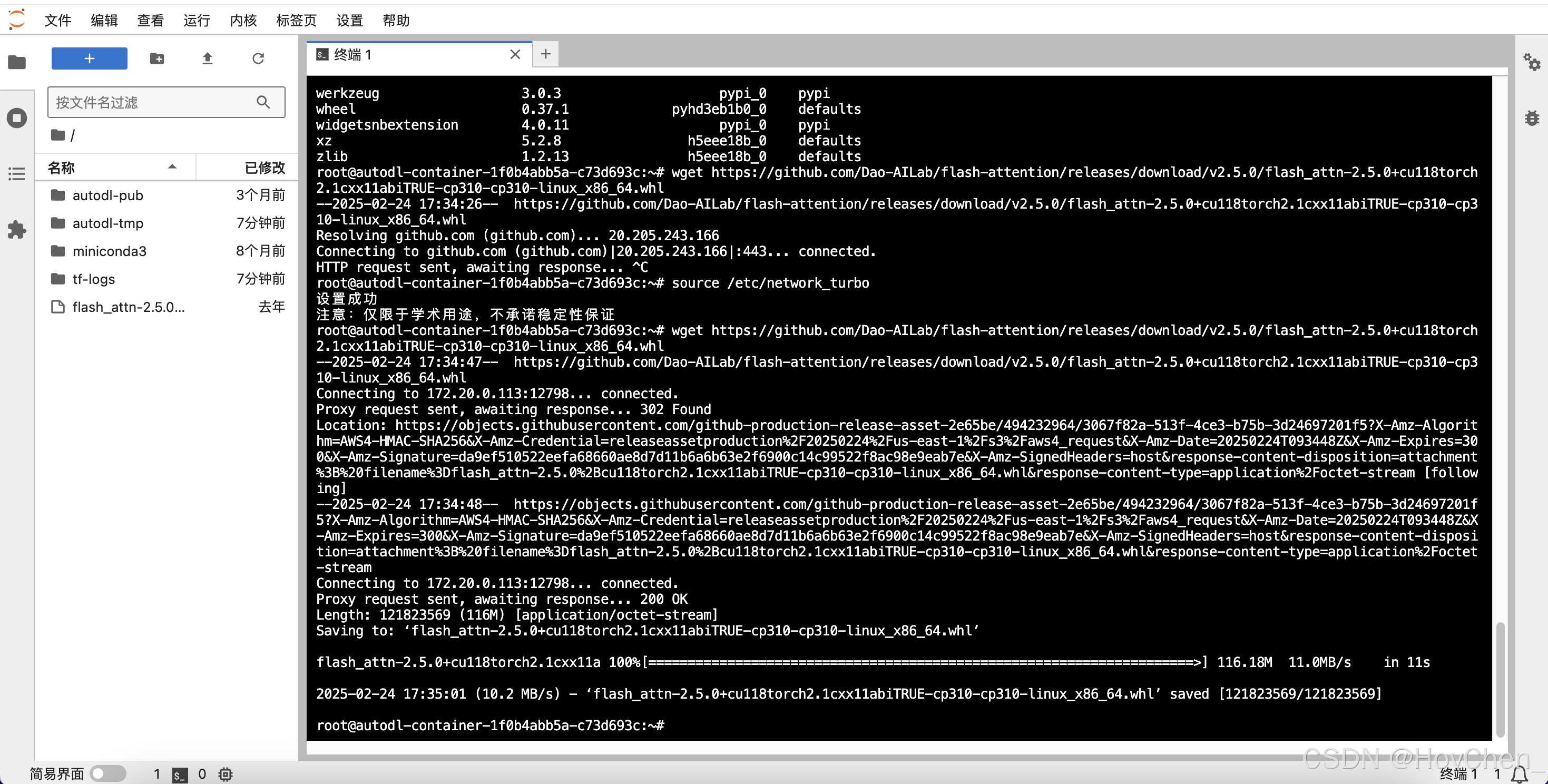
在终端输入pip install + 文件名(含后缀),即可安装完成。
pip install flash_attn-2.5.0+cu118torch2.1cxx11abiTRUE-cp310-cp310-linux_x86_64.whl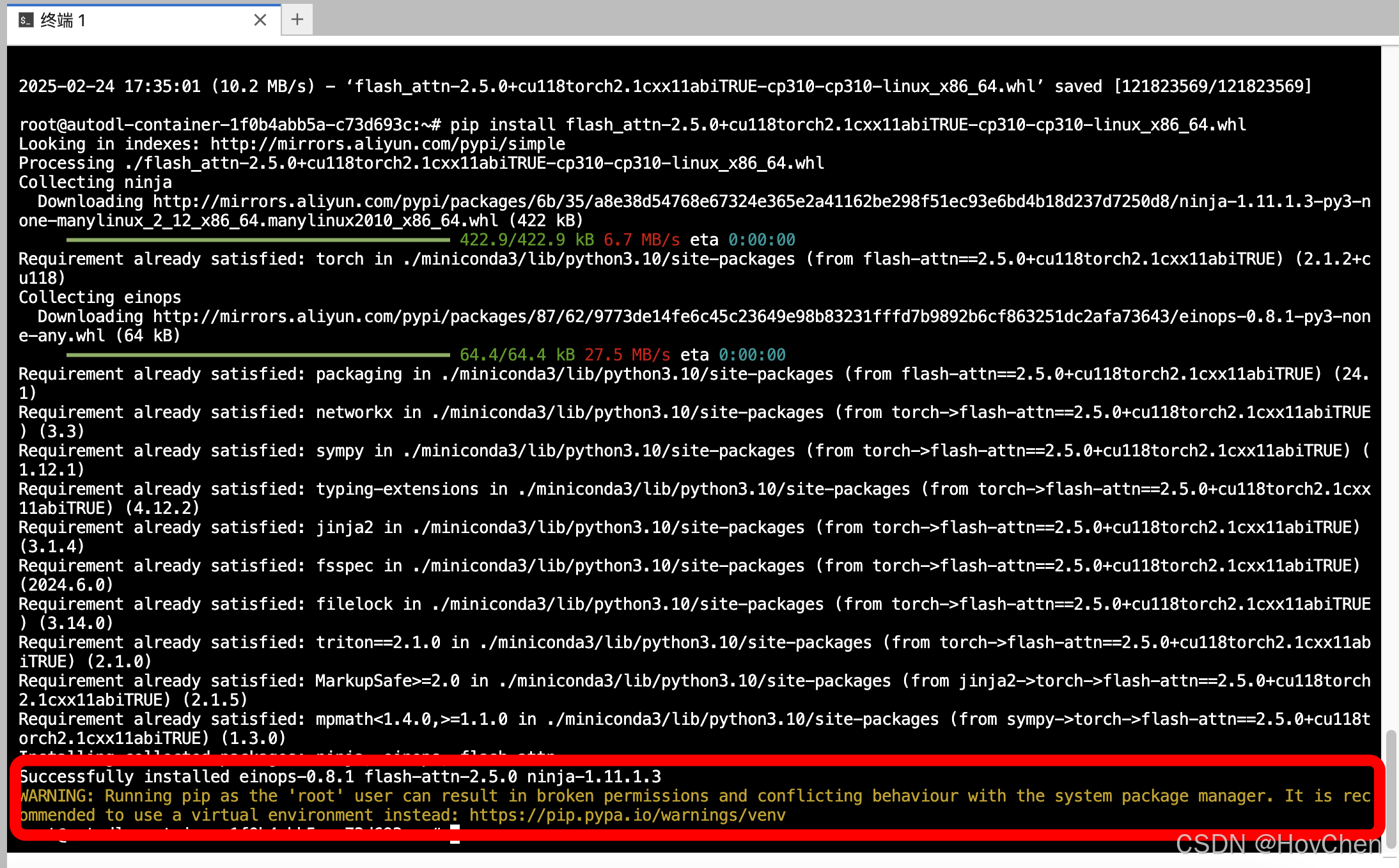
如果觉得本文对你有用的话,欢迎关注+收藏!


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











