







📣 前言
• 👓 可视化主要使用 plotly
• 🔎 数据处理主要使用 pandas
• 🕷️ 数据爬取主要使用 requests
• 👉 本文是我自己在和鲸社区的原创
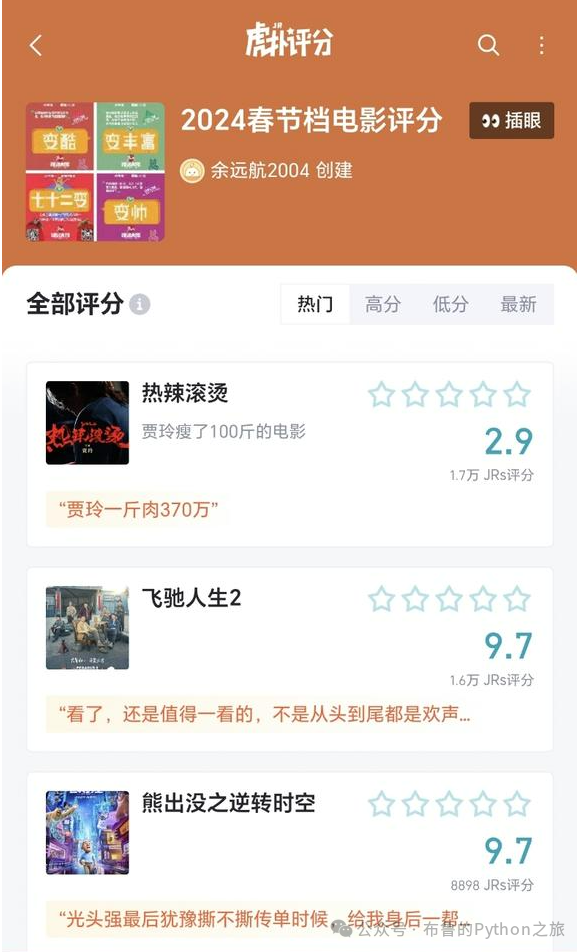
今天这篇文章将给大家介绍【Python数据可视化虎扑春节档电影口碑评论】 案例。
Step 1. 导入模块
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.express as px
import jieba
import re
from stylecloud import gen_stylecloud
from IPython.display import Image # 用于在jupyter lab中显示本地图片
Step 2. 评分数据概览
数据下载:关注公众号,回复关键词【虎扑春节档】
df =pd.read_excel(r"/home/mw/input/hupumovie5128/春节档-评分_240227_1709000662.xlsx")
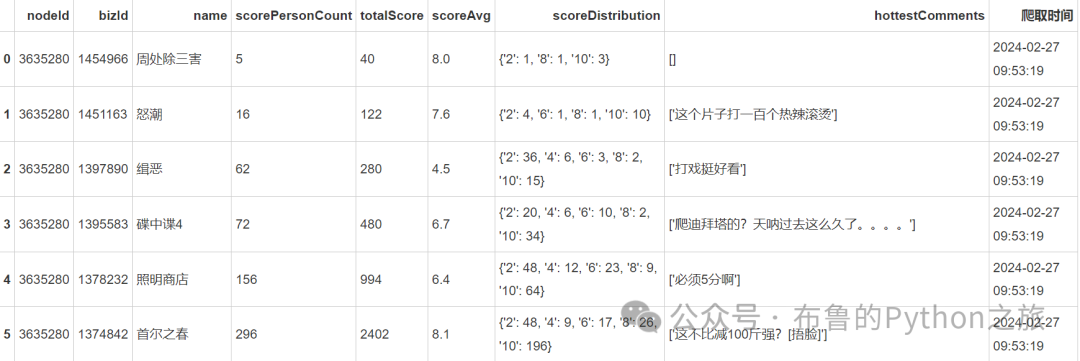
df.head(10)
输出结果:
average_score = df['scoreAvg'].mean()
median_score = df['scoreAvg'].median()
mode_score = df['scoreAvg'].mode().iloc[0]
print(average_score)
print(median_score)
print(mode_score)
输出结果:
6.5588235294117645
7.5
9.7
电影评分的平均值、中位数和众数:
平均评分:约为 6.56
中位数评分:7.5
众数评分:9.7
Step 3.数据分析可视化
3.1 2024年电影票房虎扑评分挡位人数分布
score_distribution_sum = {}
for index, row in df.iterrows():
score_distribution = eval(row['scoreDistribution']) # Convert string to dictionary
for score, count in score_distribution.items():
if score in score_distribution_sum:
score_distribution_sum[score] += count
else:
score_distribution_sum[score] = count
# Create a dataframe for score distribution
score_distribution_df = pd.DataFrame(list(score_distribution_sum.items()), columns=['评分', '人数'])
score_distribution_df.sort_values(by='评分', inplace=True)
score_distribution_df.reset_index(drop=True, inplace=True)
score_distribution_df
评分分布的数据如下:
10分: 31,412人
2分: 19,262人
4分: 1,653人
6分: 1,707人
8分: 2,235人
fig = px.bar(score_distribution_df, x='评分', y='人数',
title='2024年电影票房虎扑评分挡位人数分布', text='人数')
# 更新字体样式
fig.update_layout(
template="plotly_white",
font=dict(
# family="stcaiyun",
size=14,
color="#000000"
)
)
fig.show()
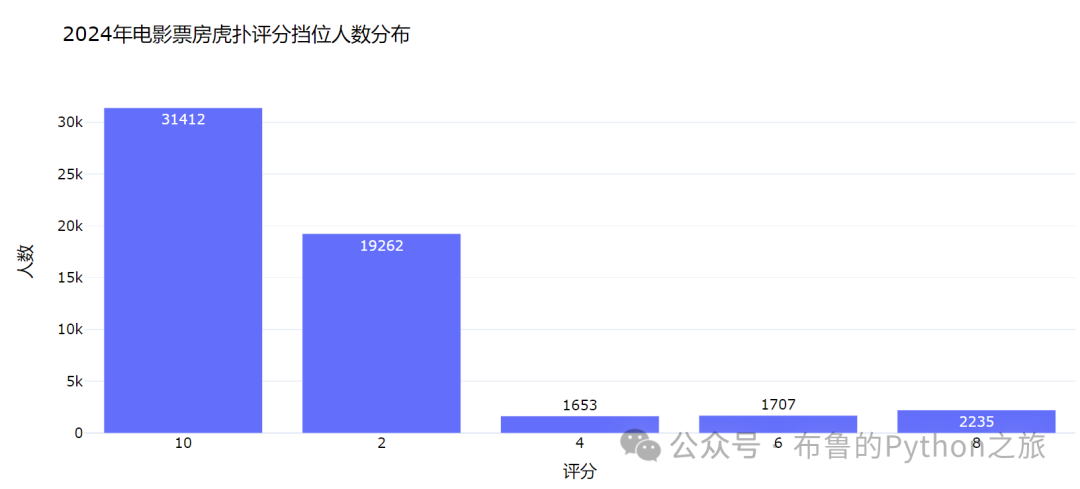
上图展示了不同评分的分布情况。从图中可以看出,10分是最常见的评分,其次是2分。其他评分(4分、6分和8分)的分布相对较少。
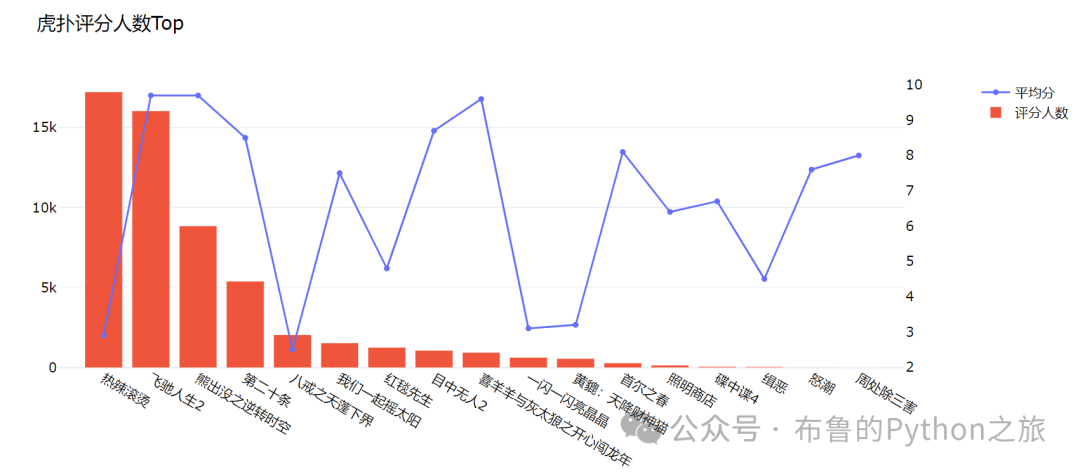
3.2 虎扑评分人数Top
df_sorted = df.sort_values(by='scorePersonCount', ascending=False).head(20)
输出结果:
3.3 热评词云
iimport ast
hottestComments = df["hottestComments"].tolist()
hots = []
for hottestComment in hottestComments:
hottestComment = ast.literal_eval(hottestComment)
for h in hottestComment:
hots.append(h)
title_content = ','.join(hots)
cut_text = jieba.cut(title_content)
result = ' '.join(cut_text)
# 读入停用词表
exclude = []
with open(r"D:\文档\中文停用词库.txt", 'r') as f:
lines = f.readlines()
for line in lines:
exclude.append(line.strip())
# 添加停用词
exclude.extend([""])
gen_stylecloud(
text=result, size=(1000, 800), max_words=500, max_font_size=80, font_path='simhei.ttf',
icon_name='fas fa-smile', output_name='春节档.png',
# background_color='#05243F',
custom_stopwords=exclude,
)
Image(filename='春节档.png')
输出结果:

Step 4. 春节档评论数据概览
数据下载:查看文章末尾获取。
df1 =pd.read_excel(r"/home/mw/input/hupumovie5128/春节档-评论_240227_1709000672.xlsx")
df1.head(10)

print("——" * 10)
print('数据集存在重复值个数:')
print(df1.duplicated().sum())
print("——" * 10)
print('数据集缺失值情况:')
print(df1.isna().sum())
print("——" * 10)
print('数据集各字段类型:')
print(df1.dtypes)
print("——" * 10)
print('数据总体概览:')
print(df1.info())`
输出结果:
————————————————————
数据集存在重复值个数:
0
————————————————————
数据集缺失值情况:
bizId 0
name 0
commentId 0
commentUserId 0
commentUserName 0
commentContent 36
lightCount 0
blackCount 0
score 0
publishTime 0
爬取时间 0
dtype: int64
————————————————————
数据集各字段类型:
bizId int64
name object
commentId int64
commentUserId int64
commentUserName object
commentContent object
lightCount int64
blackCount int64
score int64
publishTime object
爬取时间 object
dtype: object
————————————————————
数据总体概览:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5659 entries, 0 to 5658
Data columns (total 11 columns):
bizId 5659 non-null int64
name 5659 non-null object
commentId 5659 non-null int64
commentUserId 5659 non-null int64
commentUserName 5659 non-null object
commentContent 5623 non-null object
lightCount 5659 non-null int64
blackCount 5659 non-null int64
score 5659 non-null int64
publishTime 5659 non-null object
爬取时间 5659 non-null object
dtypes: int64(6), object(5)
memory usage: 486.4+ KB
None
movie_type_couns = df1['name'].value_counts().reset_index()
movie_type_couns.rename(columns={"index": "电影名称", "name": "评论数"}, inplace=True)
movie_type_couns
输出结果:
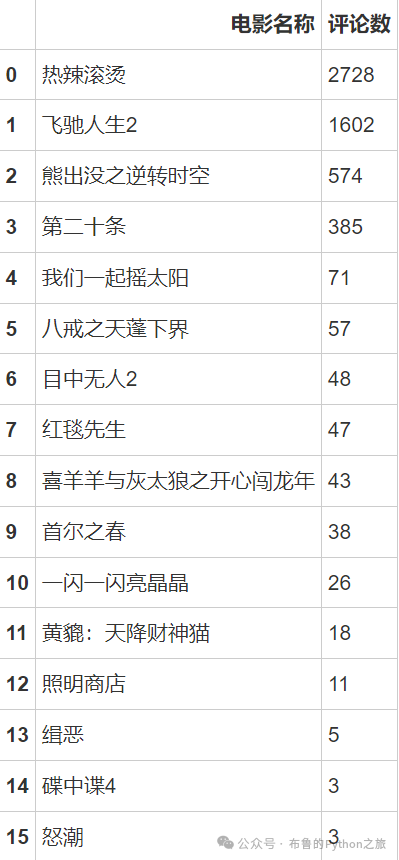
4.1 虎扑-春节档电影评论数分布
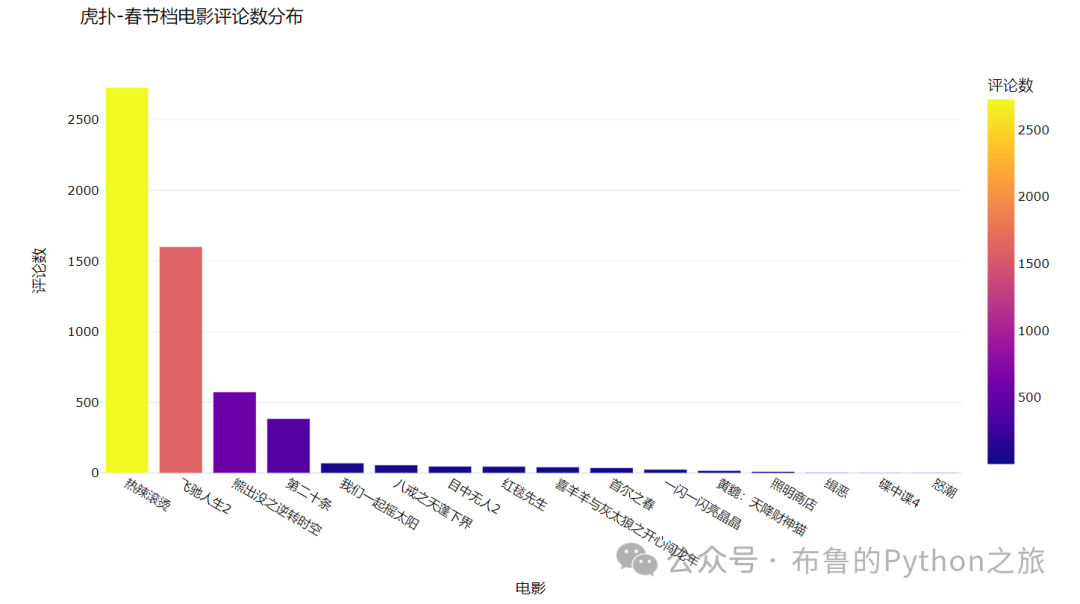
4.2 虎扑-评论数分布

4.3 热辣滚烫词云分布

4.4 飞驰人生2词云分布

完整代码👇
https://www.heywhale.com/mw/project/65dd883dd0681f06ab67a272
ps:访问链接点击【在线运行】即可查看完整代码,且不需要担心环境配置问题
数据获取方式
关注公众号,回复关键字获取
- END -
👆 关注**「布鲁的Python之旅」**第一时间收到更新















 4294
4294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









