







 该论文基于CoGAN,提出假设来自不同域但语义相同的图像拥有相同的潜在向量。通过共享的高层网络E1和E2捕获语义,然后解码生成特定表现形式。整体损失函数结合了VAE、GAN和Cycle损失,用于无监督的图像转换。实验效果展示了这种方法在不同条件下的图像转换能力。
该论文基于CoGAN,提出假设来自不同域但语义相同的图像拥有相同的潜在向量。通过共享的高层网络E1和E2捕获语义,然后解码生成特定表现形式。整体损失函数结合了VAE、GAN和Cycle损失,用于无监督的图像转换。实验效果展示了这种方法在不同条件下的图像转换能力。
总说
这篇论文是基于CoGAN的,下面是总体结构图:
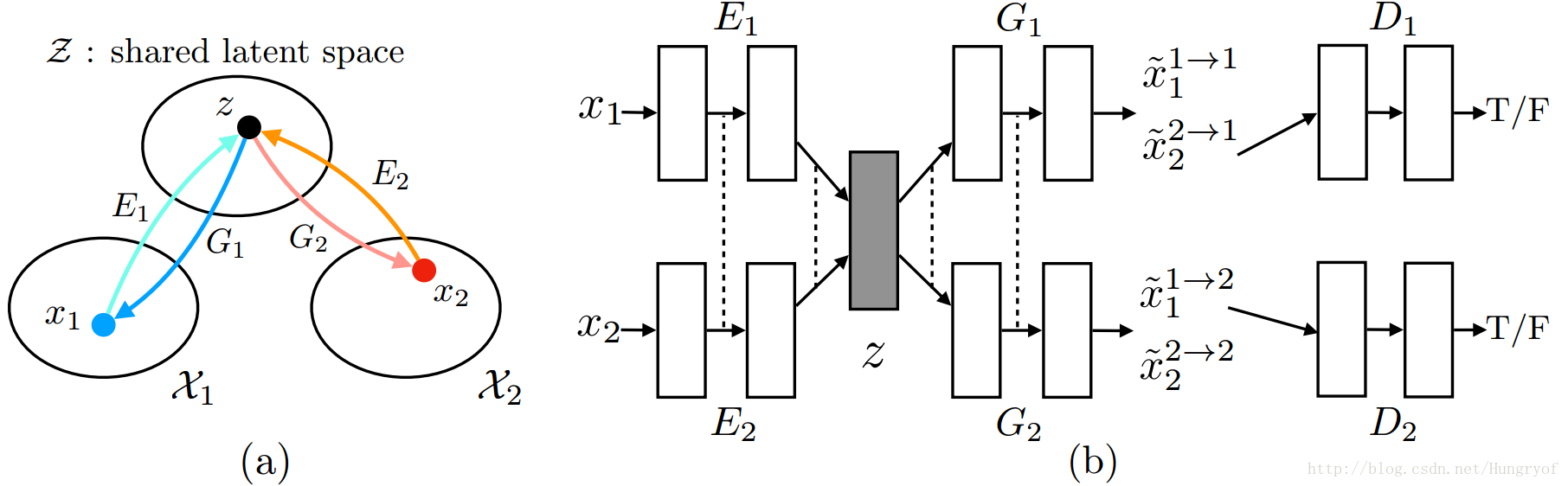
文章假设来自两个不同domain的同种语义的图片具有相同的latent vector。比如白天的上海滩与黑夜的上海滩,都是上海滩(高层语义一致,即latent vector一致),而这种语义特征再经过解码成具体的表现形式(底层网络用于语义的具体表现形式)。
因此网络设计如下:
E1 和 E2 的高层网络进行共享(具有相同的语义),得到相同的语义表达 z 之后,再进行解码。解码也最开始也要进行共享,一论文中的一个例子是,如果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









