







 文章详细介绍了CUDA编程模型,包括线程通过grid-block-thread结构的组织和内存层次结构,如全局内存和共享内存。同时,探讨了GPU硬件结构,如SM硬件、核心和内存分级,并讨论了CUDA程序的优化点,如一个core同时执行多个warp和一个SM同时执行多个block,以提高GPU性能。
文章详细介绍了CUDA编程模型,包括线程通过grid-block-thread结构的组织和内存层次结构,如全局内存和共享内存。同时,探讨了GPU硬件结构,如SM硬件、核心和内存分级,并讨论了CUDA程序的优化点,如一个core同时执行多个warp和一个SM同时执行多个block,以提高GPU性能。
目录
最近在搞性能优化,一个是想把cpu上的一些操作放到NVIDIA GPU上,另外还要分析程序在GPU上的性能。这些需要涉及CUDA编程,以及理解GPU内部各硬件性能参数;因此很有必要弄清楚CUDA编程模型与GPU硬件结构的关系。说明一下,这只是我综合网上资料的个人理解哈~~
这篇文章循序渐进主要解决以下疑问:
1、CUDA编程模型为什么要这么设计?
2、CUDA编程模型与GPU硬件结构的关系?
一、CUDA编程模型
首先简单回顾CUDA编程模型,要理解的两个关键点:线程管理和内存管理。
1、线程管理
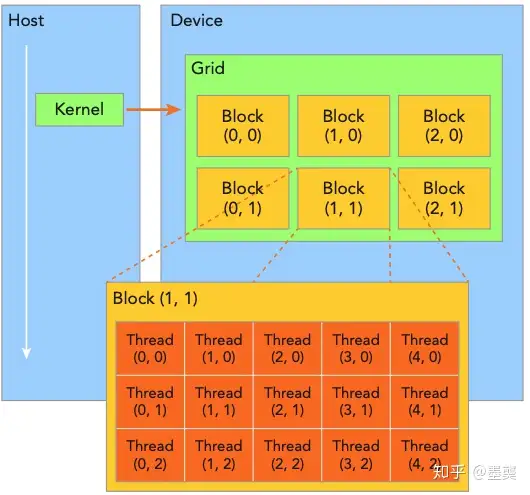
该模型从逻辑上将thread通过grid-block-thread结构组织起来(如下图所示,图片来自
),当核函数在主机端启动时,它的执行会移动到设备,此时设备中会产生大量线程,每个线程都执行相同的核函数指令。

2、内存管理
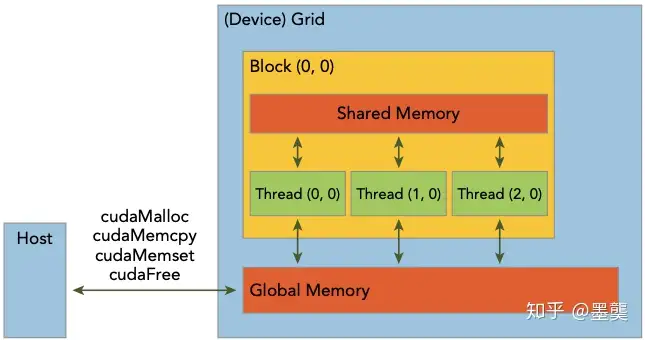
CUDA编程模型从GPU架构中抽象出一个内存层次结构,下图展示了一个简化的结构(图片来自于
),主要包含两部分:全局内存(类似于CPU中的系统内存)、共享内存(类似于CPU中的缓存)。

二、GPU硬件结构
NVIDIA显卡PCB电路板上的芯片主要可以分为三类,以Quadra K620显卡举例,如下图卡PCB电路板上的芯片主要可以分为三类:
1)GPU芯片,也是整张显卡的核心,负责执行计算任务
2)DDR3存储芯片,其在显卡中相对与GPU的地位相当于电脑中内存条对于CPU,只是放在了显卡上专供GPU使用,也就是俗称的显存
3)时钟、电源等其他辅助功能的芯片

1、SM硬件
GPU芯片是由成百上千的SM(Streaming Multiprocessor)硬件组成的,而SM是由一些(一般4个)core组成的,core相当于一个cpu核。为什么会有SM这样一个层次结构呢?笔者估计SM是硬件层面提升运算能力的最基本单位,比如想把GPU做大(目的提升运算能力),只要在gpu芯片上不断地重复光刻SM这样的结构就可以了。
以Volta GV100中SMM的内部结构为例(如下图,图片来自),看看一个SM主要包含了哪些硬件(最核心的):
1)4个core,每个core里面有FP64、INT、FP32、Tensor Core等计算器阵列,以及Register(寄存器)、本地内存(这里看不到);
2)Shared Memory(共享内存),与4个core通过线路连接;

2、硬件逻辑抽象
我们现在可以将GPU主板结构抽象出来,将FP64、INT、FP32、Tensor Core这些计算器阵列抽象成一个计算器阵列,并且从逻辑上结合gpu线程管理以及内存管理,得到的硬件逻辑图如下,下面来解释这张图。

首先来看GPU芯片,GPU芯片是由成百上千的SM单元组成的,这些SM单元都可以通过L2 cache和DDR3芯片进行数据交换;其次SM单元由4个core单元、寄存器、共享内存组成,寄存器被core数量等分(比如这里4个core,寄存器大小被等分为4分),所有的core都可以与共享内存进行数据交换。
2.1 共享内存的逻辑划分
GPU不同于CPU的一个特点是线程切换是极其迅速的,这是因为每个线程和线程块使用的资源是直接基于硬件资源(共享内存、寄存器)保存的,而不是先把寄存器内存保存到内存,再从内存加载新线程的信息到寄存器然后再执行。
共享内存根据block的大小被均分为m分,这里的block size其实就是一个block里面所有的thread占用的资源大小,然后SM在这m个block区域切换(如黑色箭头指向)执行每个block里面的所有线程。
2.2 寄存器的逻辑划分
线程在硬件上执行的时候其实是通过grid-block-warp-thread这样的结构管理,中间的一层warp可以理解成一束、一捆,一个warp一般有32个线程。至于为什么会有warp这个单位,原因是warp是每个core执行的线程数量单位,也就是说每个core一次只能同时执行warp个(一般32个)线程。
寄存器首先被core数量等分(比如这里4个core,寄存器大小被等分为4分),每个core寄存器根据warp(一般32个线程)占用资源的大小等分为n份。因此每个core寄存器都驻留了n个warp,这样可以保证每一个core都可以在多个warp之间切换执行(如黑色箭头指向)以提高性能。这样提升性能的原因是:core会在当前warp处于某些等待时(比如当前warp内的线程在读取global mem,这需要数百个时钟),那这时会切换一个新的warp进行执行,从而可以显著提升硬件利用率和执行性能。
2.3 GPU内存分级
GPU内存被分为了全局内存(Global memory)、本地内存(Local memory)、共享内存(Shared memory)、寄存器内存(Register memory)、常量内存(Constant memory)、纹理内存(Texture memory)六大类。这六类内存都是分布在在RAM存储芯片或者GPU芯片上,他们物理上所在的位置,决定了他们的速度、大小以及访问规则。
全局内存:位于片外存储体中(这里DDR3芯片),容量大、访问延迟高、传输速度较慢。
本地内存:主要是用来解决当寄存器不足时的场景,即在线程申请的变量超过可用的寄存器大小时,nvcc会自动将一部数据放置到片外存储体里面。注意,局部内存设置的过程是在编译阶段就会确定。
常量内存:为了解决一个warp内多线程的访问相同数据的速度太慢的问题(多线程不能同时访问同一块内存),通过特殊的常量内存缓存(constant cache)进行缓存读取,常量内存为只读内存。
纹理内存:根据图像、纹理数据结构的规律设计出来的专用内存。
共享内存:上文有提过,其访问速度仅次于寄存器,特点是一个线程块(Block)中的所有线程都可以访问,主要存放频繁修改的变量。
寄存器:用来存储一些线程的暂存数据。寄存器的速度是访问中最快的,但是它的容量较小。
3、CUDA程序的一些优化点
基本原则是把GPU用满:一个core同时执行多个warp,一个SM能够同时执行多个block。
3.1 一个core可以同时执行多个warp
一个core需要有足够多的warp才能够进行并发和切换,而实际分配到的warp数量受限于线程占用资源大小、寄存器大小、每个block的warp总数。寄存器大小一般是固定不变的,如果每个block的warp数量足够多,每个线程占用的资源越小,则实际分配到的warp数量越多;如果每个block的warp数量太少,则实际分配到的warp数量可能也比较少。
3.2 一个SM能够同时执行多个block
一个SM需要有足够多的block才能够进行并发和切换,才能保证尽可能多的SM被利用上,而实际分配到的block数量受限于block占用资源大小、共享内存大小、block总数。共享内存大小一般是固定不变的,如果block数量足够多,每个block占用的资源越小,则实际分配到的block数越多;如果总的block数太少,则实际分配到的block数量也可能比较少。















 2869
2869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}