







在机器学习和统计学中,偏度(Skewness)指的是实值随机变量(Variables)的概率分布的不对称性的度量。本质上,它表明分布与正态分布的偏离程度,正态分布是对称的,没有偏度。偏度可以分为两种类型:
- 正偏度(Postive Skewness or Right Skewness):也称为右偏度,发生在分布的右侧尾部比左侧长或更厚时。在这种分布中,均值和中位数将大于众数。
- 负偏度(Nagative Skewness or Left Skewness):也称为左偏度,发生在分布的左侧尾部比右侧长或更厚时。在这些分布中,均值和中位数将小于众数。
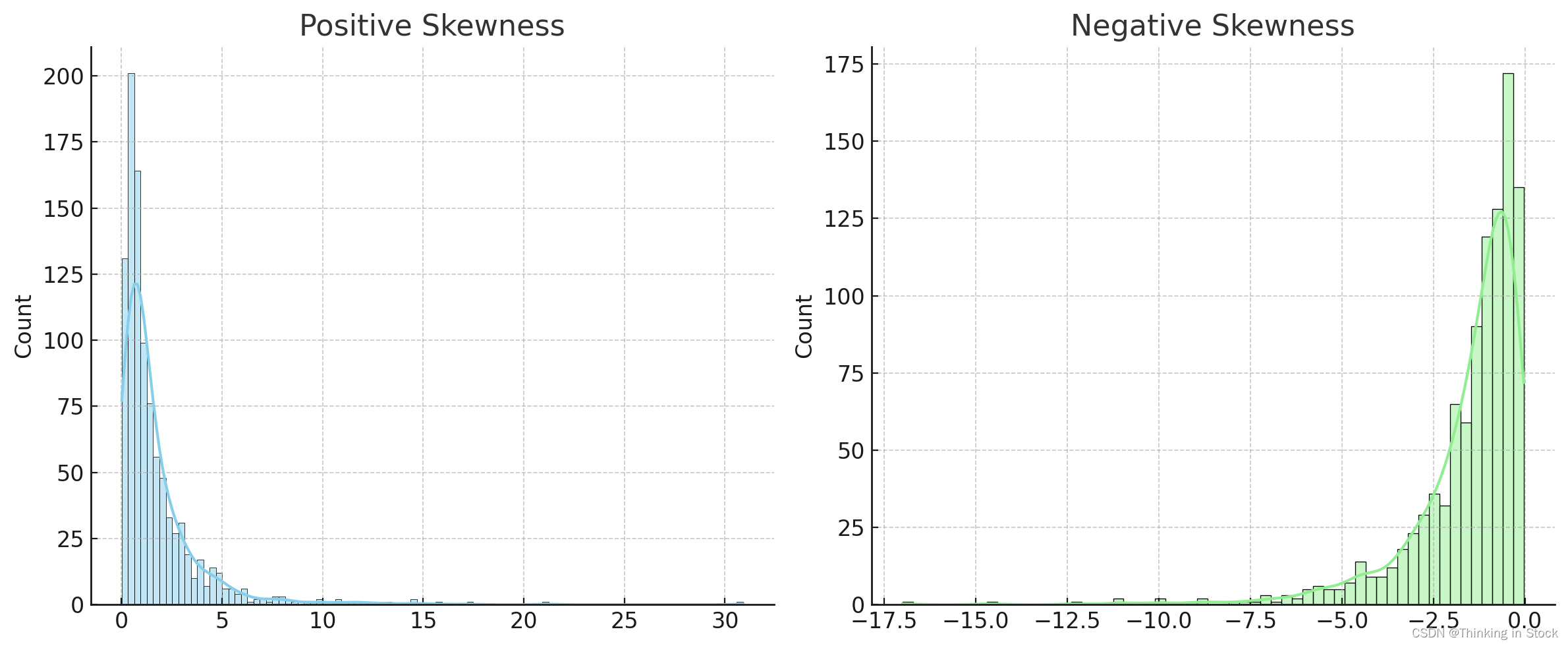
处理偏度很重要,因为许多机器学习模型假设特征遵循正态分布。
偏度以几种方式影响模型训练,主要是因为许多机器学习算法对数据分布有基本假设。以下是解决偏度重要性的几个原因:
1. 正态性假设
许多算法,特别是基于线性模型的算法,假设特征遵循正态分布。像线性回归、逻辑回归和线性判别分析这样的算法假设每个特征都遵循高斯分布(正态分布)。偏度违反了这一假设,可能导致模型性能不佳。
2. 模型准确性
偏态数据会影响模型的准确性。例如,在正偏态分布中,异常值的存在或向右的长尾可能导致模型偏向于更高的值,误表示数据的实际情况。这可能导致对较低端值的预测不准确,特别是对值的预测。
3. 对学习过程的影响
偏态的存在可以通过影响参数的估计来影响学习过程。例如,在偏态分布中,均值和方差更容易受到异常值的影响,这可能导致在重度依赖这些统计数据的模型中产生偏置的参数估计。
4. 对梯度下降的影响
对于使用梯度下降作为优化算法的模型(如神经网络和许多集成方法),偏态数据可能导致梯度下降收敛速度更慢。偏态的特征空间可以创建一个延长的、不均匀的错误表面,使算法更难有效地找到全局最小值。
5. 对模型评估指标的影响
在回归问题中,目标变量的偏态特别是可能导致评估指标的解释出现问题。例如,像RMSE(均方根误差)这样的指标可能过度受到偏态部分产生的大错误的影响,给出模型性能的扭曲视图。
让我们通过一个假设的例子来说明偏度如何影响模型的准确性,具体来说是在预测房价的背景下——这是一个常见的回归问题。
背景
想象我们正在构建一个机器学习模型来预测房价,基于各种特征,如大小、卧室数量、位置等。在这些特征中,假设我们数据集中的房屋大小分布呈正偏态,意味着有一些非常大的房屋显著增加了平均大小。
偏度的影响
1. 模型训练:在训练阶段,模型可能会因为偏度而难以准确地学习房屋大小和价格之间的关系。少数非常大的房屋可能会不成比例地影响模型,导致它过高估计大小对价格的影响。这是因为模型试图最小化整体误差,而大的值(异常值)可能会引入显著的误差,模型将尝试补偿这种误差。
2. 预测准确性:当模型用于预测新房屋的价格时,它的预测可能会偏向于对平均大小以上的房屋给出更高的估值,即使这些房屋并不像训练集中的异常值那么大。相反,模型可能会低估较小的房屋,因为它已经“学到”更大的大小与更高的价格有强烈的相关性,由于偏度。
例子
假设我们的偏态数据集有房屋大小从800到10,000平方英尺不等,大多数房屋在1,200到3,000平方英尺之间,但有几座豪宅在8,000到10,000平方英尺范围内。这些豪宅的存在使数据偏斜,导致平均大小增高。
如果我们的模型在不解决偏度的情况下训练于这些偏态数据,可能会以两种方式表现不佳:
- 过高估计:对于中等大小的房屋,可能预测出过高的价格,认为它们因为大小而接近豪宅的价值。
- 低估:它可能会低估典型或较小的房屋,因为它将它们视为与被豪宅拉高的平均大小相差太远。
如何缓解偏度的影响
为了减轻偏度对模型训练的影响,数据科学家通常采用各种转换技术(如对数变换、Box-Cox变换等)使数据更加“正常”。这些转换有助于稳定方差,使数据更对称,从而帮助模型更好、更有效地学习。
此外,选择对偏度或异常值不太敏感的算法,如基于树的方法(随机森林、梯度提升机),也是处理偏态数据时的一种策略。最后,稳健的缩放和规范化技术也有助于最小化偏度对模型训练的影响。
以下是几种处理偏度的策略:
1. 对数变换
对数变换可用于减少正偏度分布的偏度。这种转换对于处理跨越多个数量级的数据很有用。如果数据集包含非正值,则必须添加一个常数。
import numpy as np
import pandas as pd
# Assuming df is your DataFrame and 'skewed_feature' is the column you want to transform.
df['log_transformed'] = np.log(df['skewed_feature'] + 1) # Adding 1 to avoid log(0)
2. 平方根变换
平方根变换可用于减少右偏度。它的效果比对数变换弱,但可以应用于零值,与对数变换不同,对数变换不能直接应用于零或负值。
import pandas as pd
df['sqrt_transformed'] = np.sqrt(df['skewed_feature'])
3. 立方根变换
立方根变换有效地处理正偏度和负偏度,因为它可以应用于负值。
import pandas as pd
df['cbrt_transformed'] = np.cbrt(df['skewed_feature'])
4. Box-Cox变换
Box-Cox变换是一种参数变换,需要输入数据为正。它包括一个参数lambda (λ),该参数在一个范围内变化,选择使λ的似然性最高的变换。它非常有效地纠正偏度,但要求数据为正。
from scipy import stats
import pandas as pd
# Box-Cox Transformation requires positive data. Hence, check if all values are greater than 0.
if (df['skewed_feature'] > 0).all():
df['box_cox_transformed'], _ = stats.boxcox(df['skewed_feature'])
else:
print("Box-Cox Transformation requires all values to be positive.")
5. 功率变换(Yeo-Johnson)
Yeo-Johnson变换扩展了Box-Cox变换以支持正负值,使其对不同的数据集更具通用性。
from sklearn.preprocessing import PowerTransformer
import pandas as pd
# Yeo-Johnson Transformation
pt = PowerTransformer(method='yeo-johnson')
# Reshape data for the transformer
df['yeo_johnson_transformed'] = pt.fit_transform(df['skewed_feature'].values.reshape(-1, 1))
6. 分位数变换
分位数变换通过展开最频繁的值,将特征变换为遵循指定分布,如正态分布。它是一种非线性变换,能够很好地处理异常值。
from sklearn.preprocessing import QuantileTransformer
import pandas as pd
qt = QuantileTransformer(output_distribution='normal', random_state=0)
df['quantile_transformed'] = qt.fit_transform(df['skewed_feature'].values.reshape(-1, 1))
实现
在实现这些变换时,重要的是要将它们应用于训练数据,然后使用相同的参数转换测试数据或任何新数据点,以确保模型输入的一致性。
选择处理偏度的正确方法取决于数据的性质和正在使用的机器学习模型的具体要求。在应用这些变换之前和之后可视化数据的分布,以更好地理解它们的效果,通常很有帮助。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











