 TF-IDF原理、应用及代码实现:权重调整与文本相似性度量,
TF-IDF原理、应用及代码实现:权重调整与文本相似性度量,








TF-IDF (Term Frequency-Inverse Document Frequency) 是一种用于信息检索与文本挖掘的统计方法,用来评估一个词对于一个文件集或一个语料库中的其中一份文件的重要性。它是一种常用于文本处理和自然语言处理的权重计算技术。
原理
TF-IDF 由两部分组成:词频(TF),文档频率(DF)和逆文档频率(IDF)。每一部分的计算方法如下:
-
词频(TF, Term Frequency):指某一个给定的词语在该文件中出现的频率。这个数字通常会被标准化(通常是词频除以文章总词数),以防止它偏向长的文件。(即使某一特定的词语在长文件中出现频率较高,其实该词语可能并不重要。

-
文档频率(DF): 是文本挖掘和信息检索中的一个基本概念,特别是在计算 TF-IDF(词频-逆文档频率) 时经常被用到。尽管通常在TF-IDF计算中讨论DF的倒数,但单独理解它也同样重要。定义为包含词 t 的文档数目,在语料库 D 中。它衡量一个词在整个语料库中的普遍性或稀有性。
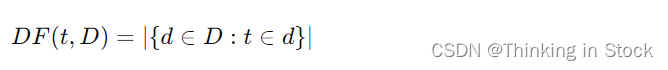
-
逆文档频率(IDF, Inverse Document Frequency):这是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











