






1.网络总体结构
Mask2former是一种基于Transformer的神经网络模型,可用于语言建模、机器翻译、文本生成等NLP任务。其原理是将输入序列中的一部分词汇(称为“掩码”)替换成特殊的掩码标记,然后利用Transformer来预测这些掩码标记所代表的词汇。这个过程可以看作是一种填空题,模型需要根据上下文来推断并填写正确的词汇。在模型训练过程中,通过对不同数量和位置的掩码进行预测和评估,可以有效地提高模型的表现能力。整个模型的训练过程分为两个阶段,第一阶段是利用掩码预测生成目标序列,第二阶段则是利用已生成的序列来预测掩码,从而让生成的序列更加符合原始文本的内容和语法结构。
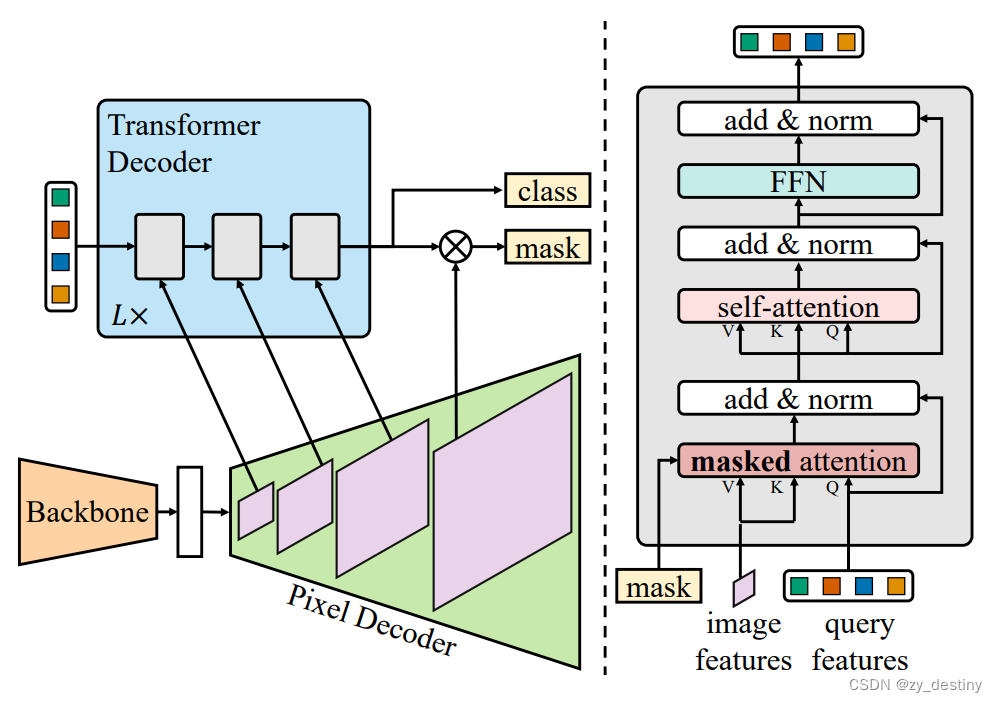
Mask2Former网络结构如上图所示,和mask-rcnn一样,mask2former采用mask classification的方式来进行分割。mask-rcnn和mask2former在如何生产二值mask上的做法不同。mask-rcnn是通过bounding boxes的方式来表示,使得mask-rcnn无法进行semantic segmentaion任务。而Mask2Former参考了Detr的做法,将这些二值mask用一组C维的特征向量来表示(object query),这样就可以用transformer decoder,通过一组固定的query来进行训练。
2.Mask2Former主要创新点
Mask2Former是一种新型的图像分割模型,其创新点主要包括以下几个方面:
使用Transformer结构进行图像分割:Mask2Former采用了Transformer结构来捕获图像中的全局关系,避免了传统卷积神经网络(CNN)在处理大量像素时出现的信息丢失问题。
联合学习实例分割和语义分割:Mask2Former采用了一种联合学习的方法,同时进行实例分割和语义分割。这种方法能够提高模型的准确度,同时降低了模型训练和推理的时间成本。
引入并行机制:Mask2Former使用了并行机制,提高了模型的训练效率和推理速度,同时降低了显存的占用。
支持多种尺度和分辨率:Mask2Former支持对多个尺度和分辨率图像的分割,使得模型能够胜任更多的应用场景。
2.1Mask Attention模块
在Mask2Former网络中,Mask Attention模块的作用是通过注意力机制来学习当前位置与其他位置之间的依赖关系,同时考虑输入序列中的掩码信息。这个模块可以帮助模型在处理序列中存在缺失值的情况下更好地理解和处理输入,同时减小了模型的计算复杂度。因此,Mask Attention模块可以帮助改进模型的鲁棒性和泛化能力,提高模型性能。
2.2High-resolution features模块
High-resolution features模块是Mask2Former网络中的一个模块,其作用是从低分辨率的特征图中提取高分辨率的特征。由于低分辨率的特征图在语义信息方面表现优秀,但分辨率较低,在目标区域细节方面表现较差,因此需要通过High-resolution features模块将它们转换成高分辨率的特征图,以便更好地捕捉目标区域的细节信息。该模块使用卷积和反卷积操作,通过增加特征图的宽和高,来增加特征图的分辨率。通过这种方式,Mask2Former网络可以更准确地检测和分割目标,并提高模型的精度。
2.3Optimization improvements优化策略
Mask2Former网络中的Optimization improvements主要作用是优化网络训练的过程,提高模型的训练速度和准确性。
具体来说,Mask2Former网络中的Optimization improvements包括两个方面的改进。一方面是使用了新的学习率调整策略,即基于梯度动量的学习率调整策略,可以更好地控制学习率的大小和梯度的变化,从而提高训练的稳定性和收敛速度;另一方面是引入了基于Adam优化算法的LAMB优化器,可以更好地解决梯度消失或爆炸的问题,提高网络的训练效果。
通过这些改进,Mask2Former网络在语义分割和目标检测等任务中取得了较好的结果,证明了优化算法对于深度学习模型训练的重要性。
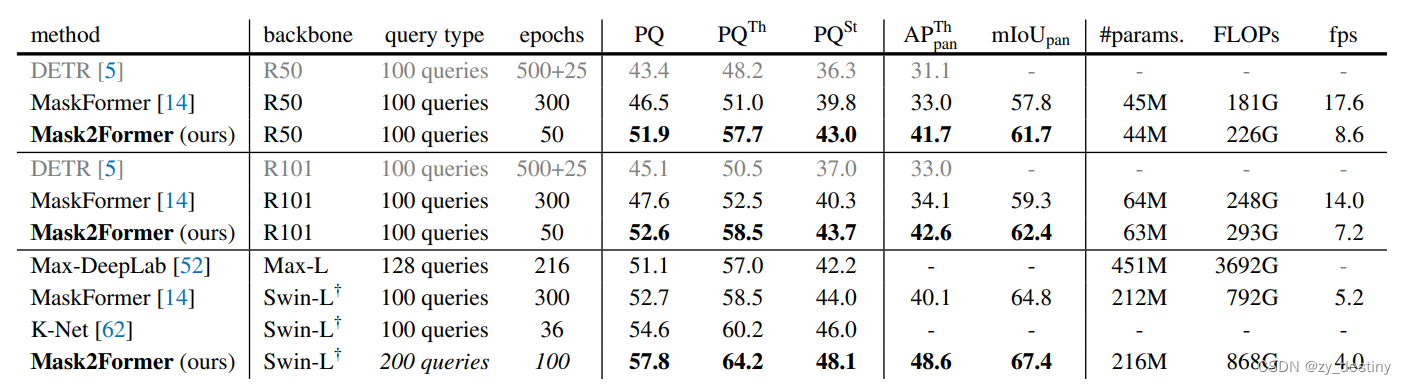
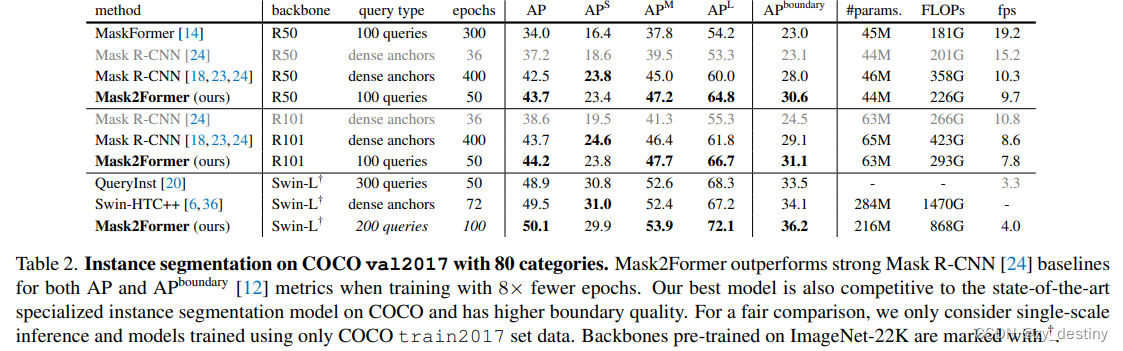
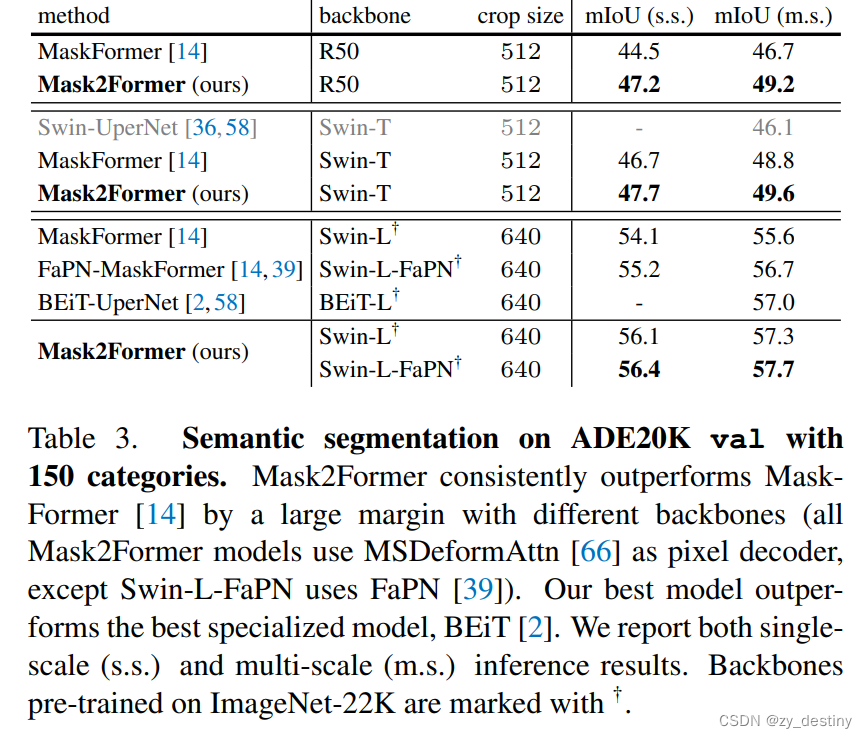
3.实验结果

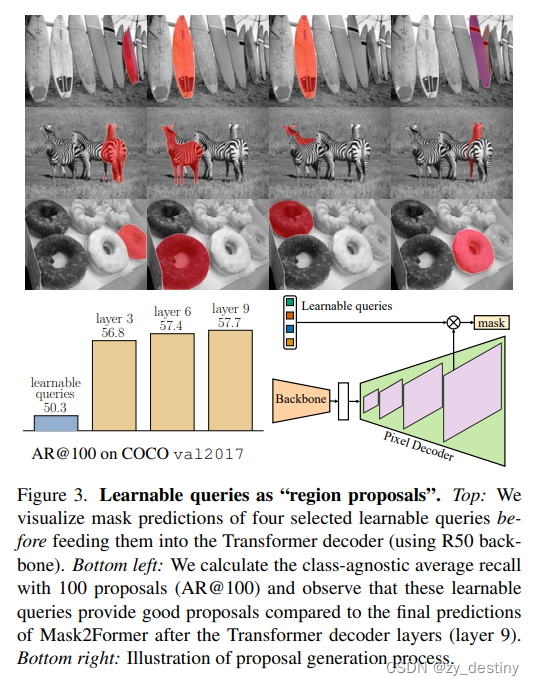
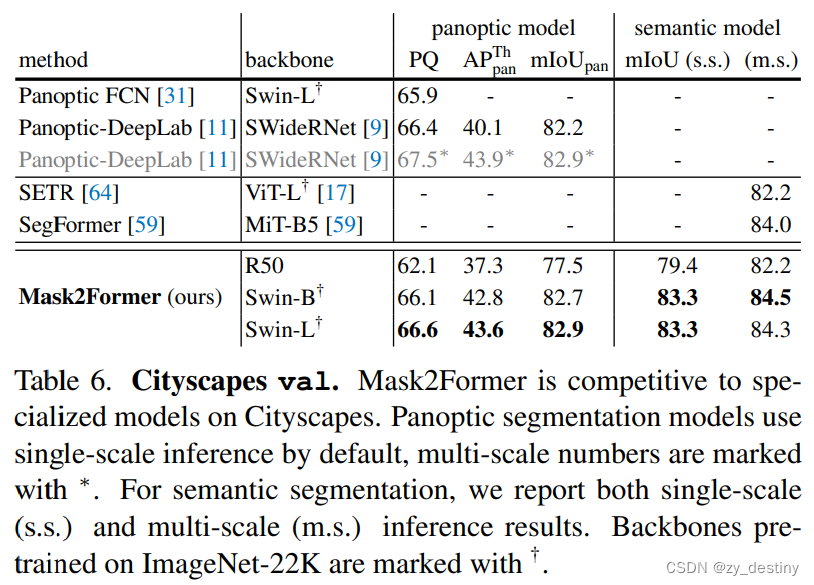
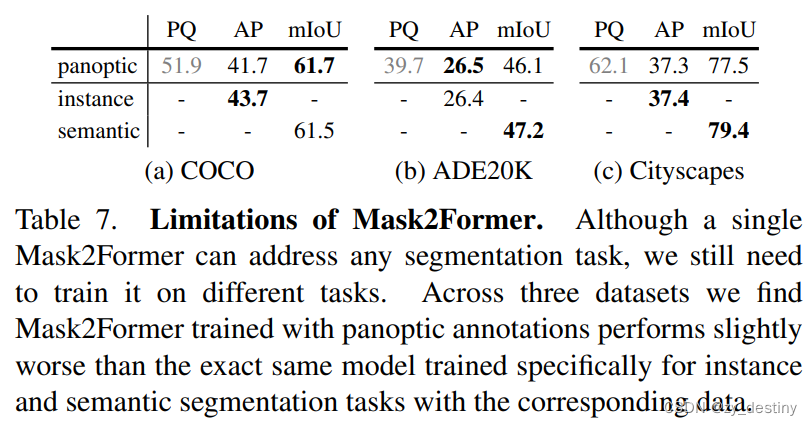
4.代码
Mask2Former网络是一种用于图像分割的神经网络,它可以将输入的图像中的每个像素分配到其相应的类别中。下面是用Python语言编写Mask2Former网络的一般步骤:
导入必要的库和模块。
import torch
import torch.nn as nn
import torch.nn.functional as F
定义网络的主体结构。
class Mask2Former(nn.Module):
def __init__(self, in_channels, out_channels, hidden_channels):
super(Mask2Former, self).__init__()
self.conv1 = nn.Conv2d(in_channels, hidden_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(hidden_channels)
self.conv2 = nn.Conv2d(hidden_channels, hidden_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(hidden_channels)
self.conv3 = nn.Conv2d(hidden_channels, out_channels, kernel_size=1)
实现前向传播函数。
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.conv3(x)
return x
创建损失函数。
loss_fn = nn.CrossEntropyLoss()
创建优化器。
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
循环训练和测试网络。
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(images)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
# 在测试集上测试网络
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print("Epoch [{}/{}], Loss: {:.4f}, Accuracy: {:.2f}%".format(epoch+1, num_epochs, loss.item(), accuracy))
这里的train_loader和test_loader是数据集的迭代器,用于训练和测试网络。可以使用PyTorch内置的数据集加载器(例如torchvision.datasets.ImageFolder)或自己编写数据集加载器。
这些步骤是实现Mask R-CNN算法的基本流程,在实际应用中还需要根据实际情况进行调整和优化。
文章写到这里,博主为读者朋友准备了完全可自学的人工智能自学资源包(如图)
均已打包放在GZH,需要的同学直接按图片方式拎取!!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









