







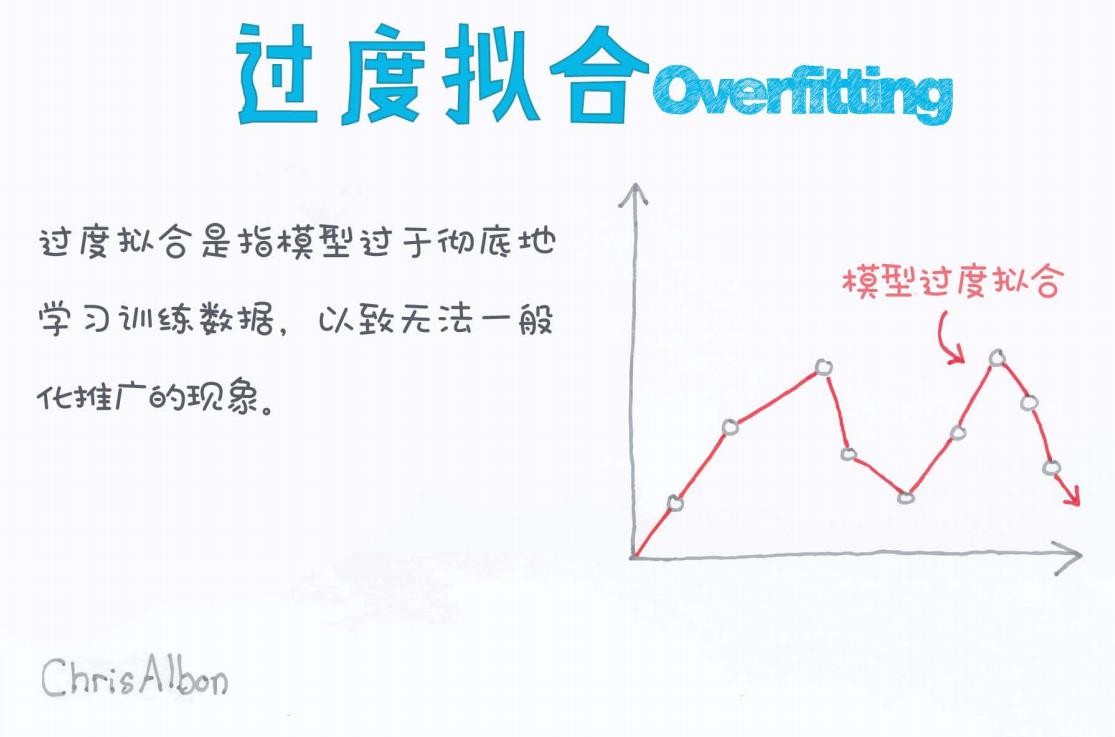
什么是过度拟合(Overfitting)?
1. 过度拟合的定义
过度拟合(Overfitting)是指机器学习模型在训练数据上表现得非常好,但在新数据(测试集)上的表现很差。原因是模型把训练数据的特征甚至噪声都记住了,导致泛化能力差。
2. 公式理解
假设数据分布:
y = f(x) + ϵ
正常目标: 找到一个接近 f(x) 的函数 h(x),使得:
尽可能小,同时在未知数据上表现良好。
但过拟合的现象是:

导致训练误差极低,测试误差极高。
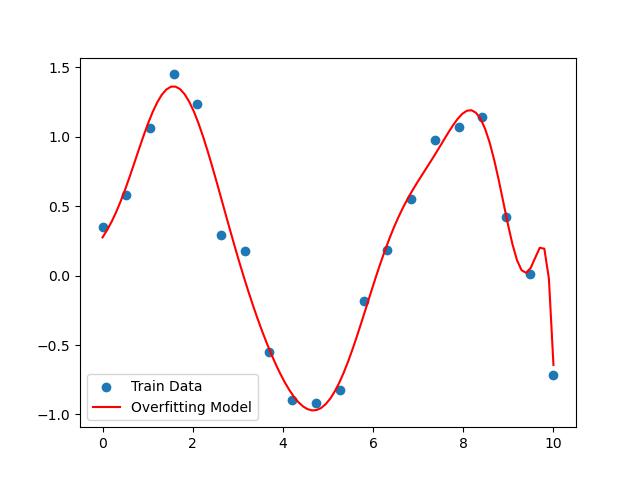
4. 代码实战演示(Python)
数据集:sin曲线 + 噪声
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 构造数据
np.random.seed(0)
X = np.linspace(0, 10, 20)
y = np.sin(X) + np.random.normal(0, 0.2, 20)
# 训练高阶多项式模型
poly = PolynomialFeatures(degree=15)
X_poly = poly.fit_transform(X.reshape(-1, 1))
model = LinearRegression()
model.fit(X_poly, y)
# 预测
X_test = np.linspace(0, 10, 100)
X_test_poly = poly.transform(X_test.reshape(-1, 1))
y_pred = model.predict(X_test_poly)
# 可视化
plt.scatter(X, y, label='Train Data')
plt.plot(X_test, y_pred, color='r', label='Overfitting Model')
plt.legend()
plt.show()
5. 如何避免 Overfitting?
| 方法 | 思路 | 技术实现 |
|---|---|---|
| 简化模型 | 降低复杂度 | 减少特征、多项式降阶 |
| 增加数据 | 增强泛化 | 数据扩充、数据增强 |
| 正则化 | 惩罚复杂度 | L1 / L2 正则 |
| 交叉验证 | 提高可靠性 | K-Fold CV |
| 提前停止 | 防止过拟合 | Early Stopping |
| Dropout | 随机丢弃神经元 | 深度学习常用 |
6. 小结
过度拟合是机器学习模型中的重要陷阱。它提醒我们:模型不在于追求训练集的完美拟合,而在于对未知数据的良好预测。

















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









