






目录
目录
2、准确率(Accuracy)正确率,是最常用的分类性能指标。
一.knn算法概述
KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。
KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
KNN算法是一种非常特别的机器学习算法,因为它没有一般意义上的学习过程。它的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中特征最相近的数据(最近邻)的分类标签。
一般而言,我们只选择样本数据集中前k个最相似的数据,这就是KNN算法中K的由来,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的类别,作为新数据的分类。
二.代码编写
1.导入
导入实验所需的数据集和所需要的python库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#读取数据集
iris_data = pd.read_csv("D:\\jiqixuexi\\pythonProject\\.venv\\iris.csv")2.读取特征值
x_data = iris_data[['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']].values
y_data = iris_data[['Species']].values3.生成随机测试集和训练集
#生成介于0.6和0.9之间的随机测试集大小
test_size = np.random.uniform(0.6, 0.9)
#将数据集分为测试集和训练集
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=test_size, random_state=42,stratify=y_data)4.书写knn算法
首先计算测试集数据与训练集数据之间的欧式距离
计算欧式距离的数学原理:
欧氏距离是常用的距离度量方法,定义为两点之间的直线距离;曼哈顿距离是指两点在坐标系上的绝对轴距总和。
找到最近k个数据的索引
获取这k个索引
使用投票法确认测试样本的预测标签
将预测结果添加到列表中
def predict_knn(x_train, x_test, y_train, y_test, k):
y_pred = []
for test_point in x_test:
distances = [euclidean_distances(test_point, train_point) for train_point in x_train]
#计算测试样本与训练样本的距离
nearest_indices = np.argsort(distances)[:k]
#找到距离最近的k个邻居的索引
nearest_labels = [y_train[i] for i in nearest_indices]
#获取最近邻居的标签
pred_label = max(set(np.array(nearest_labels).flatten()), key=np.array(nearest_labels).flatten().tolist().count)
#使用投票法确定测试样本的预测标签
y_pred.append(pred_label)
#将预测结果添加到列表中
return y_pred
def euclidean_distances(x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2))
5.计算不同k值下knn算法的准确率并输出
#初始化最高准确率和对应的k值
best_accuracy = 0
best_k = None
#调用knn预测函数
k_values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for k in k_values:
y_pred = predict_knn(x_train, x_test, y_train, y_test, k)
#计算分类准确率
accuracy = accuracy_score(y_test, y_pred)
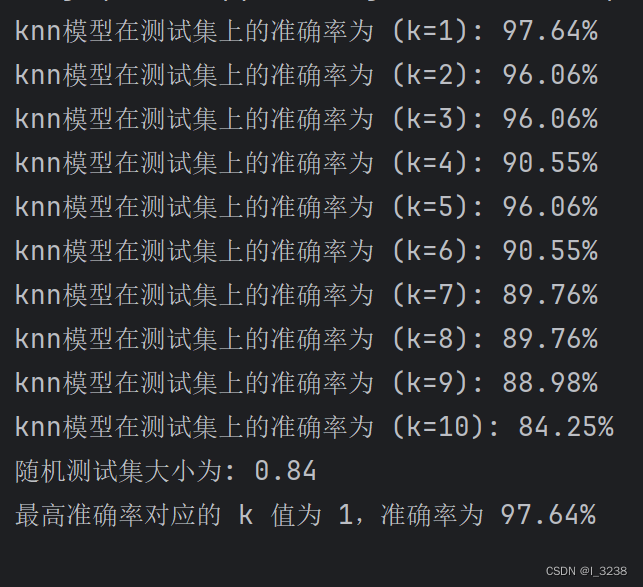
print("knn模型在测试集上的准确率为 (k={}): {:.2f}%".format(k, accuracy * 100))
#更新最高准确率和对应的k值
if accuracy > best_accuracy:
best_accuracy = accuracy
best_k = k
#输出测试集大小
print("随机测试集大小为: {:.2f}".format(test_size))
#输出最高准确率及其对应的k值
print("最高准确率对应的 k 值为 {},准确率为 {:.2f}%".format(best_k, best_accuracy * 100))
三.运行结果分析
1.编写代码时遇上的问题
1.运行结果一直保持不变,原因是我将训练集与测试集没有随机分配大小,导致每次数据都一样。
2.样本数据集过小,所以测试集中的样本可能与训练集中的某些样本非常相似,甚至相同。这就导致了在测试集上的预测准确率很高,甚至达到100%。这种情况下,模型在测试集上的表现并不能真正反映其在未知数据上的泛化能力。
四.实验心得
knn算法的优缺点
优点
1、KNN可以处理分类问题,同时天然可以处理多分类问题,比如鸢尾花的分类
2、简单,易懂,同时也很强大,对于手写数字的识别,鸢尾花这一类问题来说,准确率很高
3、KNN还可以处理回归问题,也就是预测
缺点
1、效率低,因为每一次分类或者回归,都要把训练数据和测试数据都算一遍,如果数据量很大的话,需要的算力会很惊人,但是在机器学习中,大数据处理又是很常见的一件事
2、对训练数据依赖度特别大,虽然所有机器学习的算法对数据的依赖度很高,但是KNN尤其严重,因为如果我们的训练数据集中,有一两个数据是错误的,刚刚好又在我们需要分类的数值的旁边,这样就会直接导致预测的数据的不准确,对训练数据的容错性太差
五.参考
六.第三次实验补充
一、分类模型评估指标及其计算方式
1、混淆矩阵
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的 预测类别,每一列代表实例的 真实类别。
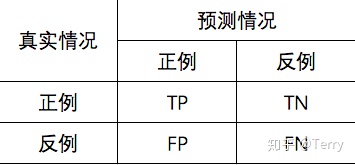
1.真正(True Positive , TP):被模型预测为正的正样本。
2.假正(False Positive , FP):被模型预测为正的负样本。
3.假负(False Negative , FN):被模型预测为负的正样本。
4.真负(True Negative , TN):被模型预测为负的负样本。
1.真正率(True Positive Rate,TPR)或灵敏度(sensitivity)
TPR=TP/(TP+FN) ===> 正样本预测结果数 / 正样本实际数
2.真负率(True Negative Rate, TNR)或特指度/特异度(specificity)
TNR = TN /(TN + FP) ===> 负样本预测结果数 / 负样本实际数
3.假正率 (False Positive Rate, FPR)
FPR = FP /(FP + TN) ===> 被预测为正的负样本结果数 /负样本实际数
4.假负率(False Negative Rate , FNR)
FNR = FN /(TP + FN) ===> 被预测为负的正样本结果数 / 正样本实际数
2、准确率(Accuracy)正确率,是最常用的分类性能指标。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
即正确预测的正反例数 /总数
3、错误率(Error rate)
正确率与错误率是分别从正反两方面进行评价的指标,两者数值相加刚好等于1。正确率高,错误率就低;正确率低,错误率就高。
Error rate = (FP+FN)/(TP+FN+FP+TN)
即错误预测的正反例数/总数
4、精确率(Precision)
只针对预测正确的正样本,表现为预测为正的里面有多少真正是正的。可理解为查准率。
Precision = TP/(TP+FP)
即正确预测的正例数 /实际正例总数
5、召回率(Recall)
召回率表现出在实际正样本中,分类器能预测出多少。与真正率相等,可理解为查全率。
Recall = TP/(TP+FN)
即正确预测的正例数 /实际正例总数
6、ROC曲线
ROC曲线,又称 感受性曲线。
X轴:假正率(FPR)(1-TNR)(1-specificity)
Y轴:真正率(TPR)(sensitivity)
ROC曲线离对角线越近,模型的准确率越低。
7、AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积(ROC的积分),通常大于0.5小于1。随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。AUC值(面积)越大的分类器,性能越好。
8、PR曲线
PR曲线的横坐标是精确率P,纵坐标是召回率R。评价标准和ROC一样,先看平滑不平滑(越平滑越好)。
AP面积的不会大于1。PR曲线下的面积越大,模型性能则越好。性能优的模型应是在召回率(R)增长的同时保持精度(P)值都在一个较高的水平,而性能较低的模型往往需要牺牲很多P值才能换来R值的提高。
二.ROC曲线和PR曲线的差异
1.ROC曲线
ROC曲线的纵坐标为TPR,真正率,其实也是召回率。分母为所有实际正样本。
ROC曲线的纵坐标为FPR,假正率,是预测错误的负样本(实际为负样本,预测成正样本,所以分子是FP)在所有实际负样本中的占比。
优点:
1.TPR关注所有正样本,FPR关注所有负样本,所以比较适合评估分类器的整体性能。
2.TPR与FPR都不依赖于类别的具体分布,不会随类别分布的改变发生变化。
缺点:
1.因为ROC曲线不依赖类别的具体分布,所以有时候反倒会成为缺点。假设负样本N增加了很多,但是曲线却没发生变化,相当于系统内产生了大片的FP样本。在一些最关心正样本预测准确性的场景,这样就会有问题。
2.如果有类别不平衡的情况,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。例如在实际的广告这种场景中,N样本远远大于P样本,FP即使增加很多,因为TN的数量太大,FPR的值改变也很小。结果是虽然大量负样本被错判成正样本,在ROC曲线上却无法直观体现出来。(当然在做CTR预估的时候,我们会用降采样等手段降低负样本的数量)
2.PR曲线
PR曲线中的P,指的是precision,一般称为精准率,或者查准率。TPR与FPR,分母针对的都是实际正样本,实际负样本。
PR曲线的纵坐标,就是Precision,横坐标是Recall,或者说是TPR。
由此可见,PR曲线的两个轴关注的都是正样本。如果是类别不平衡问题,我们关注的又都是正样本,这种情况下,PR曲线要比ROC曲线更好一些。
三.代码编写
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_curve, auc
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
# 读取数据集
iris_data = pd.read_csv("D:\\jiqixuexi\\pythonProject\\.venv\\iris.csv")
x_data = iris_data[['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']].values
y_data = iris_data[['Species']].values
# 对类别标签进行编码
label_encoder = LabelEncoder()
y_data_encoded = label_encoder.fit_transform(y_data.flatten())
# 生成介于0.6和0.9之间的随机测试集大小
test_size = np.random.uniform(0.6, 0.9)
# 将数据集分为测试集和训练集
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data_encoded, test_size=test_size, random_state=42, stratify=y_data_encoded)
def predict_knn(x_train, x_test, y_train, y_test, k):
y_pred = []
for test_point in x_test:
distances = [euclidean_distances(test_point, train_point) for train_point in x_train]
# 计算测试样本与训练样本的距离
nearest_indices = np.argsort(distances)[:k]
# 找到距离最近的k个邻居的索引
nearest_labels = [y_train[i] for i in nearest_indices]
# 获取最近邻居的标签
pred_label = max(set(nearest_labels), key=nearest_labels.count)
# 使用投票法确定测试样本的预测标签
y_pred.append(pred_label)
# 将预测结果添加到列表中
return y_pred
def euclidean_distances(x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2))
# 初始化最高准确率和对应的k值
best_accuracy = 0
best_k = None
# 调用knn预测函数
k_values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for k in k_values:
y_pred = predict_knn(x_train, x_test, y_train, y_test, k)
# 计算分类准确率
accuracy = accuracy_score(y_test, y_pred)
print("knn模型在测试集上的准确率为 (k={}): {:.2f}%".format(k, accuracy * 100))
# 更新最高准确率和对应的k值
if accuracy > best_accuracy:
best_accuracy = accuracy
best_k = k
# 输出测试集大小
print("随机测试集大小为: {:.2f}".format(test_size))
# 输出最高准确率及其对应的k值
print("最高准确率对应的 k 值为 {},准确率为 {:.2f}%".format(best_k, best_accuracy * 100))
# 初始化字典来存储每个 k 值下的预测结果
y_preds = {}
# 调用knn预测函数,并存储每个 k 值下的预测结果
for k in k_values:
y_pred = predict_knn(x_train, x_test, y_train, y_test, k)
y_preds[k] = y_pred
# 计算 ROC 曲线和 AUC
plt.figure(figsize=(8, 6))
for k in k_values:
fpr, tpr, thresholds = roc_curve(y_test, y_preds[k], pos_label=1) # 假设1是正例的标签
auc_k = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f'k={k}, AUC={auc_k:.4f}')
plt.title('ROC Curve') # 标题
plt.xlabel('FPR', fontsize=14) # x轴标签
plt.ylabel('TPR', fontsize=14) # y轴标签
plt.legend(fontsize=12) # 图例
plt.show()该代码计算了多个k值下的fpr和tpr,并画出不同k值下的roc曲线。















 1641
1641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









