






Lightgbm模型在信贷预测的过程中,对数据的要求:
1.对不规范数据处理,比如特殊字符等,对缺失值进行填充
2.数据不需要分箱,变量可以是类别型
3.变量变换
4.允许异常值存在
对参数的要求:
1.超参数优化,使用 LightGBMTuner 来调整超参数。
2.模型参数优化,使用GridSearchCV。
模型效果验证使用AUC、KS、PSI指标评估。
1.AUC。AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。 AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。 AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。 一句话来说,AUC值越大的分类器,正确率越高。
2.KS。KS:用以评估模型对好、坏客户的判别区分能力,计算累计坏客户与累计好客户百分比的最大差距 <20% : 差;20%-40% : 一般;41%-50% : 好 ;51%-75% : 非常好;>75% : 过高,需要谨慎的验证模型
3.PSI。PSI反映了验证样本在各分数段的分布与建模样本分布的稳定性。在建模中,我们常用来筛选特征变量、评估模型稳定性。稳定性是有参照的,因此需要有两个分布——实际分布(actual)和预期分布(expected)。其中,在建模时通常以训练样本(In the Sample, INS)作为预期分布,而验证样本通常作为实际分布。验证样本一般包括样本外(Out of Sample,OOS)和跨时间样本(Out of Time,OOT)。公式:PSI = SUM( (实际占比 - 预期占比)* ln(实际占比 / 预期占比) )。PSI数值越小,两个分布之间的差异就越小,代表越稳定。0~0.1 稳定性好,0.1~0.25略不稳定,大于0.25 不稳定,说明模型不能用。
(一)数据预处理,先将训练数据和缺失数据结合到一起进行变量不规范值处理,使用sql。
'''数据读取'''
train_df = pd.read_csv(r"D:\new_job\KAGGLE\lightgbm\train_1.csv", index_col=0, low_memory=False)
test_df = pd.read_csv(r"D:\new_job\KAGGLE\lightgbm\test_1.csv", index_col=0, low_memory=False)
df = pd.concat([train_df.drop(['Credit_Score'], axis=1), test_df])
# print(df.shape)
# print(df.head())
# print(df.isnull().sum())select *,replace(Age,'_','') Age_1,
replace(Annual_Income,'_','') Annual_Income_1,
replace(Num_of_Delayed_Payment,'_','') Num_of_Delayed_Payment_1,
replace(Changed_Credit_Limit,'_','') Changed_Credit_Limit_1,
replace(Outstanding_Debt,'_','') Outstanding_Debt_1,
left(Credit_History_Age,2) Credit_History_Age_1,
char_length(Type_of_Loan)- char_length(replace(Type_of_Loan,',','')) + 1 Num_of_Loan_1,
replace(Amount_invested_monthly,'__10000__','') Amount_invested_monthly_1,
replace(Monthly_Balance,'__-333333333333333333333333333__','') Monthly_Balance_1
from test;(二)大部分缺失值处理使用中位数进行缺失值填充的方法,对于部分类别型变量先变成浮点型进行中位数填充,再转换成类别型变量,包括Credit_Mix,Payment_Behaviour,Monthly_Balance。
'缺失值用中位数填充'
df['Monthly_Inhand_Salary'] = df['Monthly_Inhand_Salary'].fillna(df['Monthly_Inhand_Salary'].median())
df['Amount_invested_monthly'] = df['Amount_invested_monthly'].fillna(df['Amount_invested_monthly'].median())
df['Num_of_Delayed_Payment'] = df['Num_of_Delayed_Payment'].fillna(df['Num_of_Delayed_Payment'].median())
df['Changed_Credit_Limit'] = df['Changed_Credit_Limit'].fillna(df['Changed_Credit_Limit'].median())
df['Num_Credit_Inquiries'] = df['Num_Credit_Inquiries'].fillna(df['Num_Credit_Inquiries'].median())
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Credit_History_Age'] = df['Credit_History_Age'].fillna(df['Credit_History_Age'].median())
df['Num_of_Loan'] = df['Num_of_Loan'].fillna(0)
df['Monthly_Balance'] = df['Monthly_Balance'].fillna(df['Monthly_Balance'].median())
df['Annual_Income'] = df['Annual_Income'].fillna(df['Annual_Income'].median())
df['Interest_Rate'] = df['Interest_Rate'].fillna(df['Interest_Rate'].median())
df['Num_Credit_Card'] = df['Num_Credit_Card'].fillna(df['Num_Credit_Card'].median())
df['Num_Bank_Accounts'] = df['Num_Bank_Accounts'].fillna(df['Num_Bank_Accounts'].median())
print(df.isnull().sum())'将Credit_Mix转换为浮点类型、转换数据和插值数据'
df['Credit_Mix'] = df['Credit_Mix'].map({'Good':0, 'Standard':1, 'Bad':2})
df.astype({'Credit_Mix': 'float64'})
df['Credit_Mix'] = df['Credit_Mix'].fillna(df['Credit_Mix'].median())
df['Credit_Mix'] = df['Credit_Mix'].map({0:'Good', 1:'Standard', 2:'Bad'})
df.astype({'Credit_Mix': 'object'})
'Payment_Behaviour中的缺陷被替换为 NaN,数据类型被转换为浮点型,数据值。'
import numpy as np
df['Payment_Behaviour'] = df['Payment_Behaviour'].map({'High_spent_Large_value_payments':0,
'High_spent_Medium_value_payments':1,
'High_spent_Small_value_payments':2,
'Low_spent_Large_value_payments':3,
'Low_spent_Medium_value_payments':4,
'Low_spent_Small_value_payments':5})
df['Payment_Behaviour'] = df['Payment_Behaviour'].replace('!@9#%8', np.NaN)
df.astype({'Payment_Behaviour': 'float64'})
df['Payment_Behaviour'] = df['Payment_Behaviour'].fillna(df['Payment_Behaviour'].median())
df['Payment_Behaviour'] = df['Payment_Behaviour'].map({0:'High_spent_Large_value_payments',
1:'High_spent_Medium_value_payments',
2:'High_spent_Small_value_payments',
3:'Low_spent_Large_value_payments',
4:'Low_spent_Medium_value_payments',
5:'Low_spent_Small_value_payments'})
df.astype({'Payment_Behaviour': 'object'})
'Monthly_Balance中缺失的数据将替换为 NaN,数据类型将转换为浮点型,并转换数据'
import numpy as np
df['Monthly_Balance'] = df['Monthly_Balance'].replace('__-333333333333333333333333333_', np.NaN)
df['Monthly_Balance'] = df['Monthly_Balance'].astype(float)
df['Monthly_Balance'] = df['Monthly_Balance'].fillna(df['Monthly_Balance'].median())(三)选择变量,去除Customer_ID 和 SSN等客户唯一标识值,并将变量进行变量变换
df = df[['Month', 'Age', 'Annual_Income', 'Monthly_Inhand_Salary', 'Num_Bank_Accounts',
'Num_Credit_Card', 'Interest_Rate', 'Num_of_Loan', 'Delay_from_due_date',
'Num_of_Delayed_Payment', 'Changed_Credit_Limit', 'Num_Credit_Inquiries',
'Credit_Mix', 'Outstanding_Debt', 'Credit_Utilization_Ratio',
'Payment_of_Min_Amount', 'Total_EMI_per_month', 'Amount_invested_monthly',
'Payment_Behaviour', 'Monthly_Balance','Credit_History_Age']]
'变量变化。'(四)模型训练及参数调优
1.模型超参数调优,使用lightgbmTuner优化参数。超参数调整(或优化)是确定可最大化模型性能的超参数的正确组合的过程,超参数的选择决定了训练的效率。超参数优化好之后,使用gridsearch进行参数优化。
'''使用梯度提升gbdt进行学习。先使用 LightGBMTuner 来调整超参数。'''
# from sklearn.model_selection import StratifiedKFold
# import numpy as np
# from sklearn.model_selection import GridSearchCV
# import lightgbm as lgb
# X_train = train_df.drop(['Credit_Score'], axis=1).to_numpy()
# y_train = train_df['Credit_Score'].to_numpy()
#
# model = lgb.LGBMClassifier(boosting_type='gbdt', lambda_l1=0.0, lambda_l2=0.0,
# num_leaves=42,feature_fraction=0.7, bagging_fraction=1.0, bagging_freq=0)
# params = {'min_child_samples': list(np.arange(2, 30, 2)),
# 'learning_rate': [0.01, 1, 0.1],
# 'n_estimators': [20, 40],
# 'max_depth':[5,6,7],
# }
# gscv = GridSearchCV(model,params,cv=3,verbose=2)
# gscv.fit(X_train, y_train)
# print(gscv.best_params_){'objective': 'binary', 'metric': 'auc', 'feature_pre_filter': False, 'lambda_l1': 1.3314318989700526e-07, 'lambda_l2': 8.885599292678549,'num_leaves': 31, 'feature_fraction': 0.8, 'bagging_fraction': 1.0, 'bagging_freq': 0, 'min_child_samples': 20}{'learning_rate': 0.1, 'max_depth': 5, 'min_child_samples': 4, 'n_estimators': 40}
2.模型训练,使用上面的超参数以及参数进行模型训练。
from sklearn import metrics
from sklearn.metrics import roc_curve,roc_auc_score,precision_score,recall_score,log_loss,f1_score
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import auc
from sklearn.preprocessing import StandardScaler
from sklearn.utils import shuffle
X = train_df.drop(['Credit_Score'], axis=1).to_numpy()
target = train_df.Credit_Score
X_train,X_test,Y_train,Y_test = train_test_split(X,target,test_size=0.4)
model = lgb.LGBMClassifier(boosting_type='gbdt', #设置提升类型 rf dart
objective='regression', # 定义的目标函数 binary
lambda_l1=0.0,
lambda_l2=0,
feature_fraction=0.8, # 建树的特征选择比例,也是colsample_bytree,为了降低过拟合。
num_leaves=30, #结果对最终效果影响较大,越大值越好,太大会出现过拟合,
# 由于lightGBM是leaves_wise生长,官方说法是要小于2^max_depth
bagging_fraction=0.9, # 建树的样本采样比例,也是subsample,为了降低过拟合。
bagging_freq=0, # k 意味着每 k 次迭代执行bagging,bagging的频率,0意味着没有使用bagging
min_child_samples=20, #min_data_in_leaf,是一个很重要的参数,它的值取决于训练数据的样本
#个数和num_leaves.将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合。
learning_rate=0.1,
max_depth=5 #设置树深度,深度越大可能过拟合 一般4~10
)
model.fit(X, target)
# LGBMClassifier(bagging_fraction=1.0, bagging_freq=0, boosting_type='dart',
# feature_fraction=0.8, lambda_l1=0.0, lambda_l2=0,
# min_child_samples=16, num_leaves=31)
y_test_v = model.predict(X_test)
y_test_p = model.predict_proba(X_test)[:,1]
3. 模型效果评估。
fpr1,tpr1,threshold = roc_curve(Y_test,y_test_p)
auc_value = auc(fpr1,tpr1)
print('AUC:',roc_auc_score(Y_test, y_test_p))
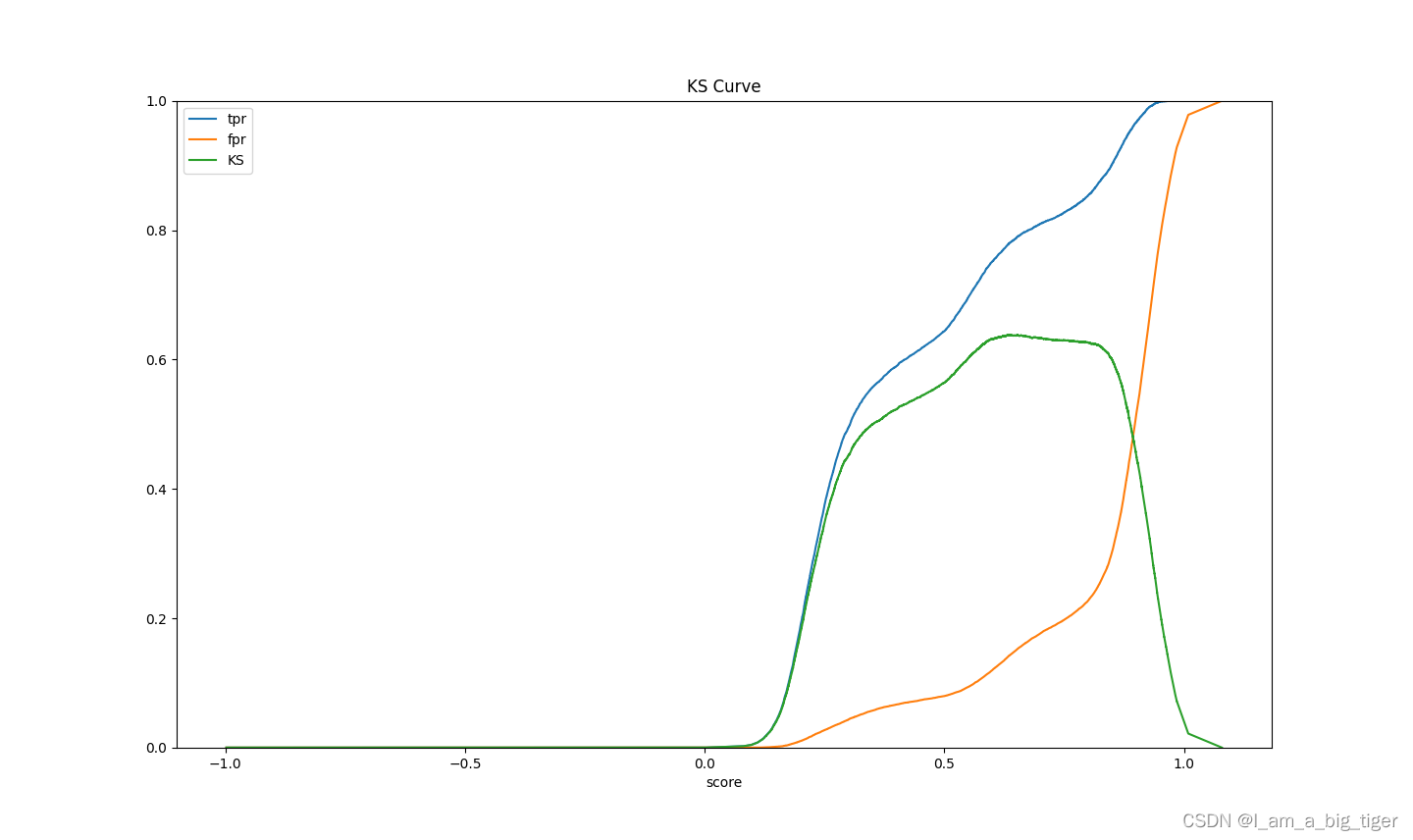
print('KS:',max(tpr1-fpr1))
[LightGBM] [Warning] feature_fraction is set=0.8, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.8
[LightGBM] [Warning] lambda_l1 is set=0.0, reg_alpha=0.0 will be ignored. Current value: lambda_l1=0.0
[LightGBM] [Warning] bagging_fraction is set=0.9, subsample=1.0 will be ignored. Current value: bagging_fraction=0.9
[LightGBM] [Warning] lambda_l2 is set=0, reg_lambda=0.0 will be ignored. Current value: lambda_l2=0
[LightGBM] [Warning] bagging_freq is set=0, subsample_freq=0 will be ignored. Current value: bagging_freq=0
AUC值: 0.895871582847498
KS值: 0.6391368720850105
4.模型稳定性评估。群体稳定性指标PSI(Population Stability Index)是衡量模型的预测值与实际值偏差大小的指标。 PSI = sum((实际占比-预期占比)* ln(实际占比/预期占比))。
#计算psi,将预测01改为预测概率的形式
X_test = test_df.to_numpy()
p_test = model.predict_proba(X_test)
import pandas as pd
import numpy as np
##计算psi
psi,psi_df = cal_psi(y_test_p,p_test,10,'equal_f')
# train_date['predict']:模型训练集预测值或预测分数。
# test_date['y']:模型测试集预测值或预测分数。
# 30:分的组数,可以自己随意定义。
print(psi)PSI: 0.5295*********
模型PSI指标大于0.25,说明模型不能使用,那就下一篇研究如何调优lightgbm模型psi指标。















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









