








信贷违约风险的LightGBM框架
(一) LightGBM概要:
LightGBM(Light Gradient Boosting Machine)是一种梯度提升框架,用于解决机器学习问题,特别是分类和回归问题。它是一种基于树的模型,通过串行训练多颗决策树,并以集成的方式提高预测性能。相较于传统的梯度提升方法。
《LightGBM: A Highly Efficient Gradient Boosting Decision Tree》。该论文由微软亚洲研究院的Guolin Ke、Qi Meng、Thomas Finley、Taifeng Wang、Wei Chen和Weidong Ma于2017年发表在ACM Digital Library上。这篇论文详细介绍了LightGBM的设计思想、算法原理以及性能优势。
基于梯度的单侧采样(GOSS)和独占特征捆绑(EFB)。使用GOSS,我们排除了很大一部分梯度较小的数据实例,仅使用其余部分来估计信息增益。我们证明,由于梯度较大的数据实例在信息增益的计算中起着更重要的作用,GOSS可以用更小的数据量获得相当准确的信息增益估计。使用 EFB,捆绑了互斥功能(即,它们很少同时采用非零值),以减少特征的数量。我们证明了找到独占特征的最优捆绑是NP困难的,但贪婪算法可以实现相当好的近似比(从而可以有效地减少特征的数量,而不会对分割点确定的准确性造成太大损害),LightGBM将传统GBDT的训练过程加快了20倍以上,同时实现了几乎相同的精度
原论文:LightGBM: a highly efficient gradient boosting decision tree(PDF)
梯度提升算法:
在LightGBM中,使用梯度提升算法逐步训练一系列的决策树模型。每一轮迭代都会产生一个新的决策树,该决策树的预测输出与之前模型的预测输出的残差相对应。
假设有一个训练集 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } \{(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\} {(x1,y1),(x2,y2),…,(xn,yn)},其中 x i x_i xi 是特征, y i y_i yi 是真实的目标值。假设已经有了前 t t t 轮迭代的模型预测输出 y ^ t − 1 ( x i ) \hat{y}_{t-1}(x_i) y^t−1(xi),那么第 t t t 轮的模型将拟合残差:
r t i = y i − y ^ t − 1 ( x i ) r_{ti} = y_i - \hat{y}_{t-1}(x_i) rti=yi−y^t−1(xi)
这个残差将被新的决策树拟合。通过将多个决策树的预测结果相加,可以逐步减小残差,从而提高模型的预测性能。
直方图算法
Histogram algorithm应该翻译为直方图算法,直方图算法的基本思想是:先把连续的浮点特征值离散化成 k 个整数,同时构造一个宽度为 k 的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点
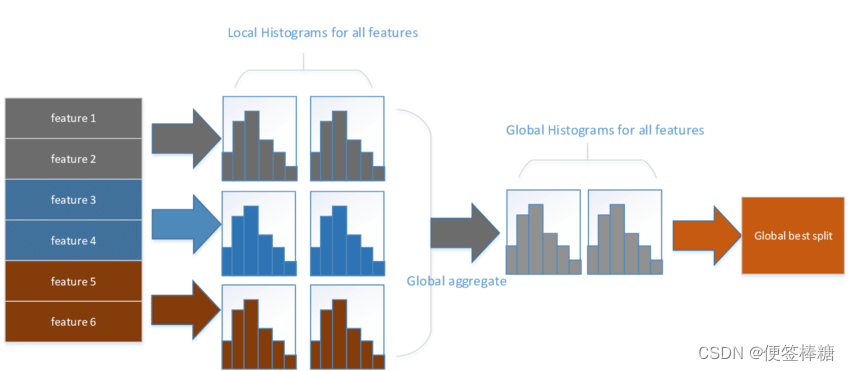
直方图算法简单理解为:首先确定对于每一个特征需要多少个箱子并为每一个箱子分配一个整数;然后将浮点数的范围均分成若干区间,区间个数与箱子个数相等,将属于该箱子的样本数据更新为箱子的值;最后用直方图表示。
决策树的构建:
LightGBM使用基于直方图的算法来高效地构建决策树。在每次分割节点时,LightGBM会选择一个分割点,以最大化信息增益或最小化损失函数。
假设在某个节点上,有一组数据 { x 1 , x 2 , … , x m } \{x_1, x_2, \ldots, x_m\} {x1,x2,…,xm},对应的目标值为 { y 1 , y 2 , … , y m } \{y_1, y_2, \ldots, y_m\} {y1,y2,…,ym}。节点的分割将数据分成两个子集 { x i } i ∈ S \{x_i\}_{i \in S} {xi}i∈S 和 { x i } i ∈ T \{x_i\}_{i \in T} {xi}i∈T,其中 S S S 和 T T T 是分割后的两个子节点。
LightGBM的分割策略可以通过以下公式表示,其中 G G G 表示梯度的和, H H H 表示Hessian矩阵的和:
Gain = 1 2 [ G S 2 H S + λ + G T 2 H T + λ − ( G S + G T ) 2 H S + H T + λ ] − γ \text{Gain} = \frac{1}{2} \left[ \frac{G_S^2}{H_S + \lambda} + \frac{G_T^2}{H_T + \lambda} - \frac{(G_S + G_T)^2}{H_S + H_T + \lambda} \right] - \gamma Gain=21[HS+λGS2+HT+λGT2−HS+HT+λ(GS+GT)2]−γ
在上述公式中, λ \lambda λ 是正则化项, γ \gamma γ 是一个用于控制分割的最小增益的超参数。
叶子分数的更新:
在每个叶子节点上,LightGBM会为该叶子节点分配一个叶子分数,该分数用于进行最终的预测。
对于第 t t t 轮迭代,第 i i i 个样本在叶子节点上的分数更新可以表示为:
y ^ t i = y ^ t − 1 ( x i ) + learning_rate × ∑ j ∈ leaf ( x i ) w t j \hat{y}_{ti} = \hat{y}_{t-1}(x_i) + \text{learning\_rate} \times \sum_{j \in \text{leaf}(x_i)} w_{tj} y^ti=y^t−1(xi)+learning_rate×j∈leaf(xi)∑wtj
其中
y
^
t
−
1
(
x
i
)
\hat{y}_{t-1}(x_i)
y^t−1(xi) 是前
t
−
1
t-1
t−1 轮迭代的预测值,
w
t
j
w_{tj}
wtj 是第
t
t
t 轮的决策树中叶子节点的分数。
(二)实例前言:
本文主要是介绍了一个完整二元分类的数据预处理和建模流程,它加载各种不同的数据文件,执行特征工程,然后使用LightGBM模型进行k-fold交叉验证的训练和预测。最终,它会生成一个特征重要性的图表,并可以生成提交文件。
2.1 数据来源
捷信集团利用各种替代数据(包括电信和交易信息)来预测客户的还款能力。
2.2 数据介绍:
-
application_{train|test}.csv
- 主要数据表,分为训练集(带有目标变量TARGET)和测试集(不带目标变量TARGET)两个文件。
- 包含所有申请的静态数据。每行代表数据样本中的一笔贷款。
-
bureau.csv
- 包括客户先前在其他金融机构获得的所有信用,这些信用已报告给信用局(适用于我们样本中有贷款的客户)。
- 对于样本中的每笔贷款,有与客户在申请日期之前在信用局的信用数量相同的行
-
bureau_balance.csv
- 信用局中先前信用的每月余额。
- 对于每个先前信用报告给信用局的历史月份,表中都有一行数据。即表中的行数为(样本中的贷款数量 * 相关先前信用的数量 * 有历史观测的月份数量)。
-
POS_CASH_balance.csv
- 先前的POS(销售点)和现金贷款的每月余额快照,申请人在Home Credit有这些贷款。
- 对于样本中的每笔贷款,与Home Credit相关的历史月份,表中都有一行数据。即表中的行数为(样本中的贷款数量 * 相关先前信用的数量 * 有历史观测的月份数量)。
-
credit_card_balance.csv
- 先前申请人在Home Credit拥有的信用卡的每月余额快照。
- 对于样本中的每笔贷款,与Home Credit相关的历史月份,表中都有一行数据。即表中的行数为(样本中的贷款数量 * 相关先前信用卡的数量 * 有历史观测的月份数量)。
-
previous_application.csv
- 所有在我们的样本中有贷款的客户的Home Credit贷款的先前申请记录。
- 对于样本中的每笔贷款,都有与之关联的每个先前申请的行数据。
-
installments_payments.csv
- 与样本中的贷款相关的以前发放的信贷的还款历史。
- 表中的每一行代表一个还款或一个逾期还款的付款。一个行数据等于一个分期付款的一次付款,或者一个与样本中的贷款相关的以前Home Credit信贷的一次分期付款。
-
HomeCredit_columns_description.csv
(三)代码流程概述:
- 导入所需的库和模块。
- 定义计时器上下文管理器,用于记录代码块执行的时间。
- 定义函数
one_hot_encoder,用于进行独热编码。 - 定义函数
application_train_test,处理主要的申请数据集。 - 定义函数
bureau_and_balance,处理与贷款申请者有关的历史信用数据。 - 定义函数
previous_applications,处理先前申请数据。 - 定义函数
pos_cash,处理先前申请的 POS(销售点)和现金数据。 - 定义函数
installments_payments,处理分期付款数据。 - 定义函数
credit_card_balance,处理信用卡余额数据。 - 定义函数
kfold_lightgbm,执行k-fold交叉验证的LightGBM模型训练和预测。 - 定义函数
display_importances,绘制特征重要性条形图。 - 定义主函数
main,执行整个机器学习流程。 - 检查脚本是否直接运行,然后调用主函数。
(四)代码思路:
- 导入必要的库和模块
import numpy as np
import pandas as pd
import gc
import time
from contextlib import contextmanager
from lightgbm import LGBMClassifier
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.model_selection import KFold, StratifiedKFold
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
这部分是导入所需的库和模块。 您导入了NumPy和Pandas用于数据处理,gc用于垃圾回收,time用于计时,contextlib中的contextmanager用于创建计时器上下文管理器,LightGBM库用于训练模型,sklearn库用于评估和交叉验证,matplotlib和seaborn用于绘图,以及warnings库用于忽略
2. 定义计时器上下文管理器 timer
@contextmanager
def timer(title):
t0 = time.time()
yield
print("{} - done in {:.0f}s".format(title, time.time() - t0))
这是一个用于计时的上下文管理器。 它会记录代码块执行所花费的时间,并在代码块执行完成后打印出所花费的时间
- 定义函数
one_hot_encoder(df, nan_as_category=True)- 对DataFrame进行独热编码
- 返回独热编码后的DataFrame和新的列名列表
def one_hot_encoder(df, nan_as_category=True):
original_columns = list(df.columns)
categorical_columns = [col for col in df.columns if df[col].dtype == 'object']
df = pd.get_dummies(df, columns=categorical_columns, dummy_na=nan_as_category)
new_columns = [c for c in df.columns if c not in original_columns]
return df, new_columns
这是一个用于对DataFrame中的分类变量进行独热编码的函数。 它将分类变量转换为二进制编码,并返回新的DataFrame以及新增的列
- 定义函数
application_train_test(num_rows=None, nan_as_category=False)- 读取
application_train.csv和application_test.csv数据 - 执行一系列特征工程操作,如编码、处理缺失值、添加新特征
- 返回处理后的DataFrame
- 读取
def application_train_test(num_rows=None, nan_as_category=False):
df = pd.read_csv('../input/application_train.csv', nrows=num_rows)
test_df = pd.read_csv('../input/application_test.csv', nrows=num_rows)
print("Train samples: {}, test samples: {}".format(len(df), len(test_df)))
df = df.append(test_df).reset_index()
df = df[df['CODE_GENDER'] != 'XNA']
for bin_feature in ['CODE_GENDER', 'FLAG_OWN_CAR', 'FLAG_OWN_REALTY']:
df[bin_feature], uniques = pd.factorize(df[bin_feature])
df, cat_cols = one_hot_encoder(df, nan_as_category)
df['DAYS_EMPLOYED'].replace(365243, np.nan, inplace=True)
df['DAYS_EMPLOYED_PERC'] = df['DAYS_EMPLOYED'] / df['DAYS_BIRTH']
# ... 继续添加其他特征工程步骤
del test_df
gc.collect()
return df
- 定义函数
bureau_and_balance(num_rows=None, nan_as_category=True)- 读取
bureau.csv和bureau_balance.csv数据 - 执行特征聚合和衍生操作
- 返回处理后的DataFrame
- 读取
def bureau_and_balance(num_rows=None, nan_as_category=True):
bureau = pd.read_csv('../input/bureau.csv', nrows=num_rows)
bb = pd.read_csv('../input/bureau_balance.csv', nrows=num_rows)
bb, bb_cat = one_hot_encoder(bb, nan_as_category)
bureau, bureau_cat = one_hot_encoder(bureau, nan_as_category)
# ... 进行各种聚合、合并和特征工程步骤
return bureau_agg
- 定义函数
previous_applications(num_rows=None, nan_as_category=True)- 读取
previous_application.csv数据 - 执行特征工程操作,如编码、处理缺失值、添加新特征
- 返回处理后的DataFrame
- 读取
def previous_applications(num_rows=None, nan_as_category=True):
prev = pd.read_csv('../input/previous_application.csv', nrows=num_rows)
prev, cat_cols = one_hot_encoder(prev, nan_as_category=True)
prev['DAYS_FIRST_DRAWING'].replace(365243, np.nan, inplace=True)
# ... 添加其他预处理和特征工程步骤
return prev_agg
- 定义函数
pos_cash(num_rows=None, nan_as_category=True)- 读取
POS_CASH_balance.csv数据 - 执行特征聚合和衍生操:独热编码
- 返回处理后的DataFrame
- 读取
def pos_cash(num_rows=None, nan_as_category=True):
pos = pd.read_csv('../input/POS_CASH_balance.csv', nrows=num_rows)
pos, cat_cols = one_hot_encoder(pos, nan_as_category=True)
# ... 进行特征聚合和衍生
return pos_agg
-
定义函数
installments_payments(num_rows=None, nan_as_category=True)- 读取
installments_payments.csv数据 - 执行特征衍生和聚合操作
- 返回处理后的DataFrame
- 读取
-
定义函数
credit_card_balance(num_rows=None, nan_as_category=True)- 读取
credit_card_balance.csv数据 - 执行特征聚合操作
- 返回处理后的DataFrame
- 读取
-
定义函数
kfold_lightgbm(df, num_folds, stratified=False, debug=False)- 对数据进行k-fold LightGBM训练和预测
- 返回特征重要性的DataFrame
def kfold_lightgbm(df, num_folds, stratified=False, debug=False):
train_df = df[df['TARGET'].notnull()]
test_df = df[df['TARGET'].isnull()]
# ... 执行 k-fold LightGBM 训练和预测
return feature_importance_df
- 定义函数
display_importances(feature_importance_df_)- 绘制特征重要性条形图
def display_importances(feature_importance_df_):
cols = feature_importance_df_[["feature", "importance"]].groupby("feature").mean().sort_values(by="importance", ascending=False)[:40].index
best_features = feature_importance_df_.loc[feature_importance_df_.feature.isin(cols)]
plt.figure(figsize=(8, 10))
sns.barplot(x="importance", y="feature", data=best_features.sort_values(by="importance", ascending=False))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
plt.savefig('lgbm_importances01.png')
显示特征的平均重要性。
- 定义主函数
main(debug=False)- 执行整个机器学习流程,包括数据加载、特征工程和模型训练
if __name__ == "__main__":
submission_file_name = "submission_kernel02.csv"
with timer("Full model run"):
main()
- 检查脚本是否直接运行
- 设置提交文件名
- 调用主函数来运行整个流程
(五) 完整代码:
import numpy as np
import pandas as pd
import gc
import time
from contextlib import contextmanager
from lightgbm import LGBMClassifier
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.model_selection import KFold, StratifiedKFold
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
@contextmanager
def timer(title):
t0 = time.time()
yield
print("{} - done in {:.0f}s".format(title, time.time() - t0))
# One-hot encoding for categorical columns with get_dummies
def one_hot_encoder(df, nan_as_category = True):
original_columns = list(df.columns)
categorical_columns = [col for col in df.columns if df[col].dtype == 'object']
df = pd.get_dummies(df, columns= categorical_columns, dummy_na= nan_as_category)
new_columns = [c for c in df.columns if c not in original_columns]
return df, new_columns
# Preprocess application_train.csv and application_test.csv
def application_train_test(num_rows = None, nan_as_category = False):
# Read data and merge
df = pd.read_csv('../input/application_train.csv', nrows= num_rows)
test_df = pd.read_csv('../input/application_test.csv', nrows= num_rows)
print("Train samples: {}, test samples: {}".format(len(df), len(test_df)))
df = df.append(test_df).reset_index()
# Optional: Remove 4 applications with XNA CODE_GENDER (train set)
df = df[df['CODE_GENDER'] != 'XNA']
# Categorical features with Binary encode (0 or 1; two categories)
for bin_feature in ['CODE_GENDER', 'FLAG_OWN_CAR', 'FLAG_OWN_REALTY']:
df[bin_feature], uniques = pd.factorize(df[bin_feature])
# Categorical features with One-Hot encode
df, cat_cols = one_hot_encoder(df, nan_as_category)
# NaN values for DAYS_EMPLOYED: 365.243 -> nan
df['DAYS_EMPLOYED'].replace(365243, np.nan, inplace= True)
# Some simple new features (percentages)
df['DAYS_EMPLOYED_PERC'] = df['DAYS_EMPLOYED'] / df['DAYS_BIRTH']
df['INCOME_CREDIT_PERC'] = df['AMT_INCOME_TOTAL'] / df['AMT_CREDIT']
df['INCOME_PER_PERSON'] = df['AMT_INCOME_TOTAL'] / df['CNT_FAM_MEMBERS']
df['ANNUITY_INCOME_PERC'] = df['AMT_ANNUITY'] / df['AMT_INCOME_TOTAL']
df['PAYMENT_RATE'] = df['AMT_ANNUITY'] / df['AMT_CREDIT']
del test_df
gc.collect()
return df
# Preprocess bureau.csv and bureau_balance.csv
def bureau_and_balance(num_rows = None, nan_as_category = True):
bureau = pd.read_csv('../input/bureau.csv', nrows = num_rows)
bb = pd.read_csv('../input/bureau_balance.csv', nrows = num_rows)
bb, bb_cat = one_hot_encoder(bb, nan_as_category)
bureau, bureau_cat = one_hot_encoder(bureau, nan_as_category)
# Bureau balance: Perform aggregations and merge with bureau.csv
bb_aggregations = {'MONTHS_BALANCE': ['min', 'max', 'size']}
for col in bb_cat:
bb_aggregations[col] = ['mean']
bb_agg = bb.groupby('SK_ID_BUREAU').agg(bb_aggregations)
bb_agg.columns = pd.Index([e[0] + "_" + e[1].upper() for e in bb_agg.columns.tolist()])
bureau = bureau.join(bb_agg, how='left', on='SK_ID_BUREAU')
bureau.drop(['SK_ID_BUREAU'], axis=1, inplace= True)
del bb, bb_agg
gc.collect()
# Bureau and bureau_balance numeric features
num_aggregations = {
'DAYS_CREDIT': ['min', 'max', 'mean', 'var'],
'DAYS_CREDIT_ENDDATE': ['min', 'max', 'mean'],
'DAYS_CREDIT_UPDATE': ['mean'],
'CREDIT_DAY_OVERDUE': ['max', 'mean'],
'AMT_CREDIT_MAX_OVERDUE': ['mean'],
'AMT_CREDIT_SUM': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_DEBT': ['max', 'mean', 'sum'],
'AMT_CREDIT_SUM_OVERDUE': ['mean'],
'AMT_CREDIT_SUM_LIMIT': ['mean', 'sum'],
'AMT_ANNUITY': ['max', 'mean'],
'CNT_CREDIT_PROLONG': ['sum'],
'MONTHS_BALANCE_MIN': ['min'],
'MONTHS_BALANCE_MAX': ['max'],
'MONTHS_BALANCE_SIZE': ['mean', 'sum']
}
# Bureau and bureau_balance categorical features
cat_aggregations = {}
for cat in bureau_cat: cat_aggregations[cat] = ['mean']
for cat in bb_cat: cat_aggregations[cat + "_MEAN"] = ['mean']
bureau_agg = bureau.groupby('SK_ID_CURR').agg({**num_aggregations, **cat_aggregations})
bureau_agg.columns = pd.Index(['BURO_' + e[0] + "_" + e[1].upper() for e in bureau_agg.columns.tolist()])
# Bureau: Active credits - using only numerical aggregations
active = bureau[bureau['CREDIT_ACTIVE_Active'] == 1]
active_agg = active.groupby('SK_ID_CURR').agg(num_aggregations)
active_agg.columns = pd.Index(['ACTIVE_' + e[0] + "_" + e[1].upper() for e in active_agg.columns.tolist()])
bureau_agg = bureau_agg.join(active_agg, how='left', on='SK_ID_CURR')
del active, active_agg
gc.collect()
# Bureau: Closed credits - using only numerical aggregations
closed = bureau[bureau['CREDIT_ACTIVE_Closed'] == 1]
closed_agg = closed.groupby('SK_ID_CURR').agg(num_aggregations)
closed_agg.columns = pd.Index(['CLOSED_' + e[0] + "_" + e[1].upper() for e in closed_agg.columns.tolist()])
bureau_agg = bureau_agg.join(closed_agg, how='left', on='SK_ID_CURR')
del closed, closed_agg, bureau
gc.collect()
return bureau_agg
# Preprocess previous_applications.csv
def previous_applications(num_rows = None, nan_as_category = True):
prev = pd.read_csv('../input/previous_application.csv', nrows = num_rows)
prev, cat_cols = one_hot_encoder(prev, nan_as_category= True)
# Days 365.243 values -> nan
prev['DAYS_FIRST_DRAWING'].replace(365243, np.nan, inplace= True)
prev['DAYS_FIRST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE_1ST_VERSION'].replace(365243, np.nan, inplace= True)
prev['DAYS_LAST_DUE'].replace(365243, np.nan, inplace= True)
prev['DAYS_TERMINATION'].replace(365243, np.nan, inplace= True)
# Add feature: value ask / value received percentage
prev['APP_CREDIT_PERC'] = prev['AMT_APPLICATION'] / prev['AMT_CREDIT']
# Previous applications numeric features
num_aggregations = {
'AMT_ANNUITY': ['min', 'max', 'mean'],
'AMT_APPLICATION': ['min', 'max', 'mean'],
'AMT_CREDIT': ['min', 'max', 'mean'],
'APP_CREDIT_PERC': ['min', 'max', 'mean', 'var'],
'AMT_DOWN_PAYMENT': ['min', 'max', 'mean'],
'AMT_GOODS_PRICE': ['min', 'max', 'mean'],
'HOUR_APPR_PROCESS_START': ['min', 'max', 'mean'],
'RATE_DOWN_PAYMENT': ['min', 'max', 'mean'],
'DAYS_DECISION': ['min', 'max', 'mean'],
'CNT_PAYMENT': ['mean', 'sum'],
}
# Previous applications categorical features
cat_aggregations = {}
for cat in cat_cols:
cat_aggregations[cat] = ['mean']
prev_agg = prev.groupby('SK_ID_CURR').agg({**num_aggregations, **cat_aggregations})
prev_agg.columns = pd.Index(['PREV_' + e[0] + "_" + e[1].upper() for e in prev_agg.columns.tolist()])
# Previous Applications: Approved Applications - only numerical features
approved = prev[prev['NAME_CONTRACT_STATUS_Approved'] == 1]
approved_agg = approved.groupby('SK_ID_CURR').agg(num_aggregations)
approved_agg.columns = pd.Index(['APPROVED_' + e[0] + "_" + e[1].upper() for e in approved_agg.columns.tolist()])
prev_agg = prev_agg.join(approved_agg, how='left', on='SK_ID_CURR')
# Previous Applications: Refused Applications - only numerical features
refused = prev[prev['NAME_CONTRACT_STATUS_Refused'] == 1]
refused_agg = refused.groupby('SK_ID_CURR').agg(num_aggregations)
refused_agg.columns = pd.Index(['REFUSED_' + e[0] + "_" + e[1].upper() for e in refused_agg.columns.tolist()])
prev_agg = prev_agg.join(refused_agg, how='left', on='SK_ID_CURR')
del refused, refused_agg, approved, approved_agg, prev
gc.collect()
return prev_agg
# Preprocess POS_CASH_balance.csv
def pos_cash(num_rows = None, nan_as_category = True):
pos = pd.read_csv('../input/POS_CASH_balance.csv', nrows = num_rows)
pos, cat_cols = one_hot_encoder(pos, nan_as_category= True)
# Features
aggregations = {
'MONTHS_BALANCE': ['max', 'mean', 'size'],
'SK_DPD': ['max', 'mean'],
'SK_DPD_DEF': ['max', 'mean']
}
for cat in cat_cols:
aggregations[cat] = ['mean']
pos_agg = pos.groupby('SK_ID_CURR').agg(aggregations)
pos_agg.columns = pd.Index(['POS_' + e[0] + "_" + e[1].upper() for e in pos_agg.columns.tolist()])
# Count pos cash accounts
pos_agg['POS_COUNT'] = pos.groupby('SK_ID_CURR').size()
del pos
gc.collect()
return pos_agg
# Preprocess installments_payments.csv
def installments_payments(num_rows = None, nan_as_category = True):
ins = pd.read_csv('../input/installments_payments.csv', nrows = num_rows)
ins, cat_cols = one_hot_encoder(ins, nan_as_category= True)
# Percentage and difference paid in each installment (amount paid and installment value)
ins['PAYMENT_PERC'] = ins['AMT_PAYMENT'] / ins['AMT_INSTALMENT']
ins['PAYMENT_DIFF'] = ins['AMT_INSTALMENT'] - ins['AMT_PAYMENT']
# Days past due and days before due (no negative values)
ins['DPD'] = ins['DAYS_ENTRY_PAYMENT'] - ins['DAYS_INSTALMENT']
ins['DBD'] = ins['DAYS_INSTALMENT'] - ins['DAYS_ENTRY_PAYMENT']
ins['DPD'] = ins['DPD'].apply(lambda x: x if x > 0 else 0)
ins['DBD'] = ins['DBD'].apply(lambda x: x if x > 0 else 0)
# Features: Perform aggregations
aggregations = {
'NUM_INSTALMENT_VERSION': ['nunique'],
'DPD': ['max', 'mean', 'sum'],
'DBD': ['max', 'mean', 'sum'],
'PAYMENT_PERC': ['max', 'mean', 'sum', 'var'],
'PAYMENT_DIFF': ['max', 'mean', 'sum', 'var'],
'AMT_INSTALMENT': ['max', 'mean', 'sum'],
'AMT_PAYMENT': ['min', 'max', 'mean', 'sum'],
'DAYS_ENTRY_PAYMENT': ['max', 'mean', 'sum']
}
for cat in cat_cols:
aggregations[cat] = ['mean']
ins_agg = ins.groupby('SK_ID_CURR').agg(aggregations)
ins_agg.columns = pd.Index(['INSTAL_' + e[0] + "_" + e[1].upper() for e in ins_agg.columns.tolist()])
# Count installments accounts
ins_agg['INSTAL_COUNT'] = ins.groupby('SK_ID_CURR').size()
del ins
gc.collect()
return ins_agg
# Preprocess credit_card_balance.csv
def credit_card_balance(num_rows = None, nan_as_category = True):
cc = pd.read_csv('../input/credit_card_balance.csv', nrows = num_rows)
cc, cat_cols = one_hot_encoder(cc, nan_as_category= True)
# General aggregations
cc.drop(['SK_ID_PREV'], axis= 1, inplace = True)
cc_agg = cc.groupby('SK_ID_CURR').agg(['min', 'max', 'mean', 'sum', 'var'])
cc_agg.columns = pd.Index(['CC_' + e[0] + "_" + e[1].upper() for e in cc_agg.columns.tolist()])
# Count credit card lines
cc_agg['CC_COUNT'] = cc.groupby('SK_ID_CURR').size()
del cc
gc.collect()
return cc_agg
# LightGBM GBDT with KFold or Stratified KFold
# Parameters from Tilii kernel: https://www.kaggle.com/tilii7/olivier-lightgbm-parameters-by-bayesian-opt/code
def kfold_lightgbm(df, num_folds, stratified = False, debug= False):
# Divide in training/validation and test data
train_df = df[df['TARGET'].notnull()]
test_df = df[df['TARGET'].isnull()]
print("Starting LightGBM. Train shape: {}, test shape: {}".format(train_df.shape, test_df.shape))
del df
gc.collect()
# Cross validation model
if stratified:
folds = StratifiedKFold(n_splits= num_folds, shuffle=True, random_state=1001)
else:
folds = KFold(n_splits= num_folds, shuffle=True, random_state=1001)
# Create arrays and dataframes to store results
oof_preds = np.zeros(train_df.shape[0])
sub_preds = np.zeros(test_df.shape[0])
feature_importance_df = pd.DataFrame()
feats = [f for f in train_df.columns if f not in ['TARGET','SK_ID_CURR','SK_ID_BUREAU','SK_ID_PREV','index']]
for n_fold, (train_idx, valid_idx) in enumerate(folds.split(train_df[feats], train_df['TARGET'])):
train_x, train_y = train_df[feats].iloc[train_idx], train_df['TARGET'].iloc[train_idx]
valid_x, valid_y = train_df[feats].iloc[valid_idx], train_df['TARGET'].iloc[valid_idx]
# LightGBM parameters found by Bayesian optimization
clf = LGBMClassifier(
nthread=4,
n_estimators=10000,
learning_rate=0.02,
num_leaves=34,
colsample_bytree=0.9497036,
subsample=0.8715623,
max_depth=8,
reg_alpha=0.041545473,
reg_lambda=0.0735294,
min_split_gain=0.0222415,
min_child_weight=39.3259775,
silent=-1,
verbose=-1, )
clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)],
eval_metric= 'auc', verbose= 200, early_stopping_rounds= 200)
oof_preds[valid_idx] = clf.predict_proba(valid_x, num_iteration=clf.best_iteration_)[:, 1]
sub_preds += clf.predict_proba(test_df[feats], num_iteration=clf.best_iteration_)[:, 1] / folds.n_splits
fold_importance_df = pd.DataFrame()
fold_importance_df["feature"] = feats
fold_importance_df["importance"] = clf.feature_importances_
fold_importance_df["fold"] = n_fold + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(valid_y, oof_preds[valid_idx])))
del clf, train_x, train_y, valid_x, valid_y
gc.collect()
print('Full AUC score %.6f' % roc_auc_score(train_df['TARGET'], oof_preds))
# Write submission file and plot feature importance
if not debug:
test_df['TARGET'] = sub_preds
test_df[['SK_ID_CURR', 'TARGET']].to_csv(submission_file_name, index= False)
display_importances(feature_importance_df)
return feature_importance_df
# Display/plot feature importance
def display_importances(feature_importance_df_):
cols = feature_importance_df_[["feature", "importance"]].groupby("feature").mean().sort_values(by="importance", ascending=False)[:40].index
best_features = feature_importance_df_.loc[feature_importance_df_.feature.isin(cols)]
plt.figure(figsize=(8, 10))
sns.barplot(x="importance", y="feature", data=best_features.sort_values(by="importance", ascending=False))
plt.title('LightGBM Features (avg over folds)')
plt.tight_layout()
plt.savefig('lgbm_importances01.png')
def main(debug = False):
num_rows = 10000 if debug else None
df = application_train_test(num_rows)
with timer("Process bureau and bureau_balance"):
bureau = bureau_and_balance(num_rows)
print("Bureau df shape:", bureau.shape)
df = df.join(bureau, how='left', on='SK_ID_CURR')
del bureau
gc.collect()
with timer("Process previous_applications"):
prev = previous_applications(num_rows)
print("Previous applications df shape:", prev.shape)
df = df.join(prev, how='left', on='SK_ID_CURR')
del prev
gc.collect()
with timer("Process POS-CASH balance"):
pos = pos_cash(num_rows)
print("Pos-cash balance df shape:", pos.shape)
df = df.join(pos, how='left', on='SK_ID_CURR')
del pos
gc.collect()
with timer("Process installments payments"):
ins = installments_payments(num_rows)
print("Installments payments df shape:", ins.shape)
df = df.join(ins, how='left', on='SK_ID_CURR')
del ins
gc.collect()
with timer("Process credit card balance"):
cc = credit_card_balance(num_rows)
print("Credit card balance df shape:", cc.shape)
df = df.join(cc, how='left', on='SK_ID_CURR')
del cc
gc.collect()
with timer("Run LightGBM with kfold"):
feat_importance = kfold_lightgbm(df, num_folds= 10, stratified= False, debug= debug)
if __name__ == "__main__":
submission_file_name = "submission_kernel02.csv"
with timer("Full model run"):
main()
工程总结:















 4179
4179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









