






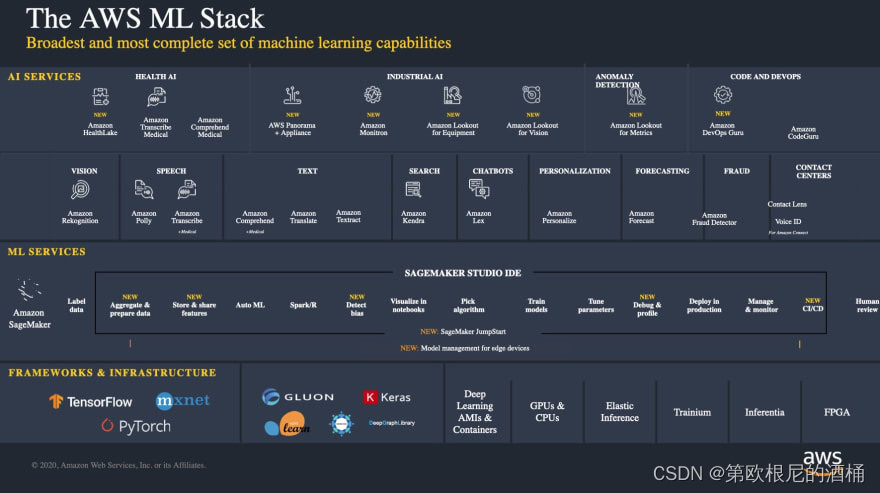
让我们快速了解一下AWS的机器学习技术栈,它几乎提供了解决我们业务问题所需的所有机器学习方面的支持。
物体检测是什么?
物体检测是从图像或视频帧中检测特定类别实例的任务。我们的目标是在图像/视频帧中找出哪里有什么物体。它是其他依赖物体的任务(如分割、图像描述、物体追踪等)的核心。
理解图像识别与图像检测之间的区别非常重要。前者只关心检测物体,而后者旨在检测所需物体的位置。
物体检测是如何工作的?
基于深度学习的物体检测模型有两个部分。编码器接收一张图像作为输入,并通过一系列模块(通常是卷积、BN和最大池化的组合)和层来运行,这些模块和层学会提取用于定位和标记物体的统计特征。编码器的输出随后传递给解码器,解码器预测每个物体的边界框和标签。
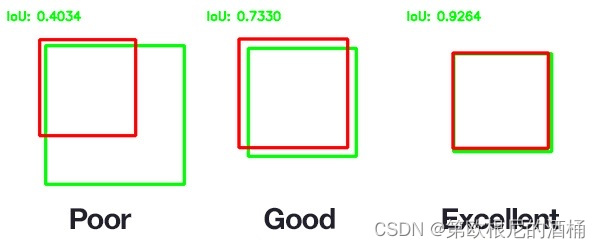
物体检测器输出每个物体的位置和标签,但我们如何知道模型的表现如何?对于物体的位置,最常用的度量标准是交并比(IOU)。给定两个边界框,我们计算交集的面积,并除以并集的面积。这个值的范围从0(无交集)到1(完全重叠)。对于标签,可以使用简单的“正确百分比”。这里有一个例子展示了这一点。
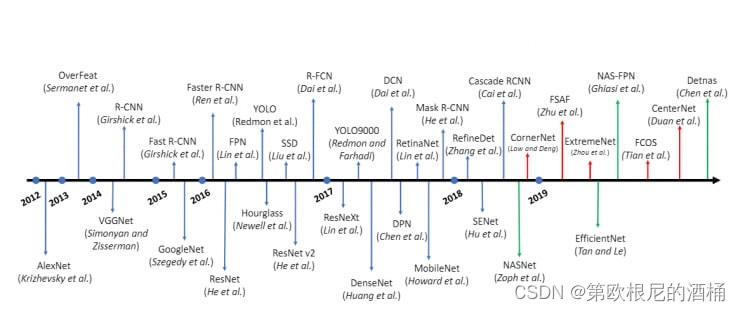
流行的物体检测模型
模型使用二阶段或一阶段物体检测,通常看到一阶段的物体检测更快。二阶段检测器具有高度的定位和物体识别准确性,而一阶段检测器则实现了高速推理。
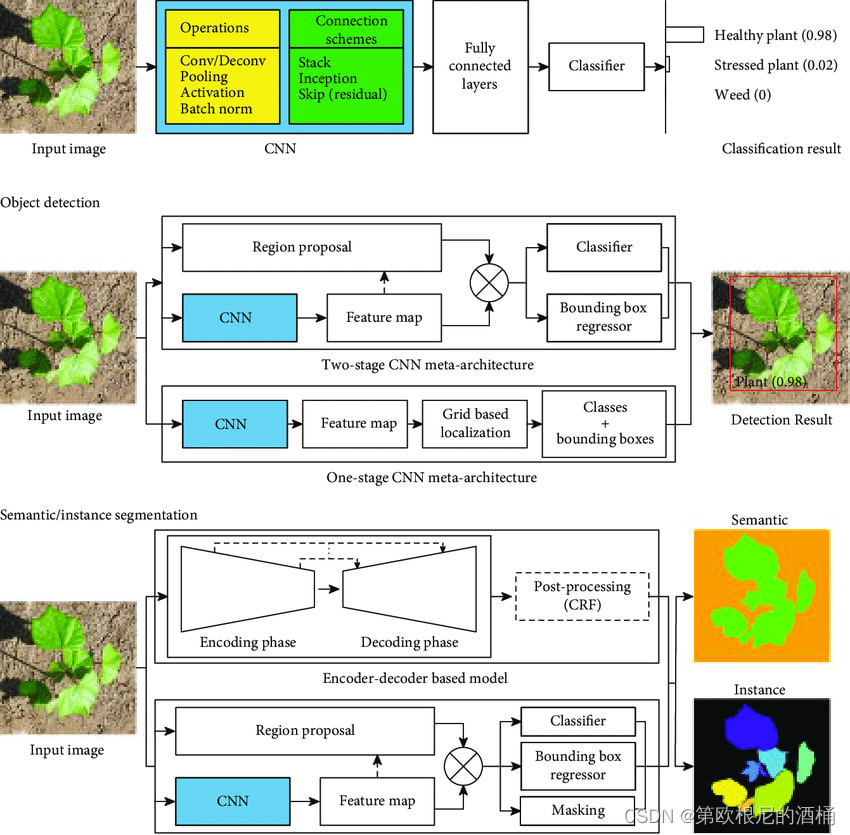
我在这里展示了如何从同一输入图像中,我们可以使用深度学习模型进行分类、检测(一阶段/二阶段)或语义分割。
这里是一些最受欢迎的模型框架
为什么选择Rekognition
物体检测需要相当深入的深度学习和网络设计知识。AWS Rekognition 正是承担了这一繁重的工作,让开发者能够在AWS服务管理深度学习方面的同时,构建无服务器应用。
亚马逊Rekognition图像提供了API来检测物体和场景、检测和分析面部、识别名人、检测不当内容,以及在一系列面部中搜索相似面部,还包括用于管理资源的API。
自定义模型训练
我们可以使用亚马逊Rekognition自定义标签控制台或亚马逊Rekognition自定义标签API来训练模型。您需要为成功训练模型所需的时间付费。通常,训练需要30分钟到24小时才能完成。
自定义标签和为什么选择Rekognition
客户常常提出“亚马逊Rekognition标签对于我的业务需求来说不够具体”的要求,现在让我们理解AWS是如何为这类场景承担繁重工作的。
为了处理上述自定义标签需求,我们有两种方法:
自己动手(DIY)
自定义化需要专业知识和资源来管理
• 深度学习模型训练和微调
• 收集并手动标记成千上万的图像
▪ 易出错且主观,可能导致不一致性
• 完成标记和模型训练可能需要数周时间
亚马逊Rekognition自定义标签
Rekognition自定义标签基于Rekognition现有能力,后者已在许多类别的成千上万图像上进行了训练。我们只需上传一小部分训练图像(通常几百张图像或更少),这些图像特定于我们的用例,通过易于使用的控制台即可。
Rekognition自定义标签自动加载并检查训练数据,选择合适的机器学习算法,训练模型,并提供模型性能指标。
它是定制化的图像分析,可以轻松检测您定义的与我们领域最相关的物体和场景。主要优势是:
• 指导体验创建标记图像
• 无需编码和无需机器学习经验即可训练和评估
• 易于使用的完全托管API
亚马逊Rekognition自定义标签提供了一个简单的端到端体验,您可以从标记数据集开始,亚马逊Rekognition自定义标签会通过检查数据并选择合适的机器学习算法为您构建一个自定义ML模型。在您的模型训练完成后,您可以立即开始用它进行图像分析。如果您想批量处理图像(比如每天或每周一次,或者每天的预定时间),您可以在预定时间启用您的自定义模型。
使用亚马逊Rekognition的示例无服务器解决方案
以下架构取自AWS github,其中解释了我们如何使用亚马逊Rekognition自定义标签构建成本最优的批量解决方案,该解决方案在预定时间启用自定义模型,处理我们的所有图像,然后取消部署我们的资源以避免产生额外成本。
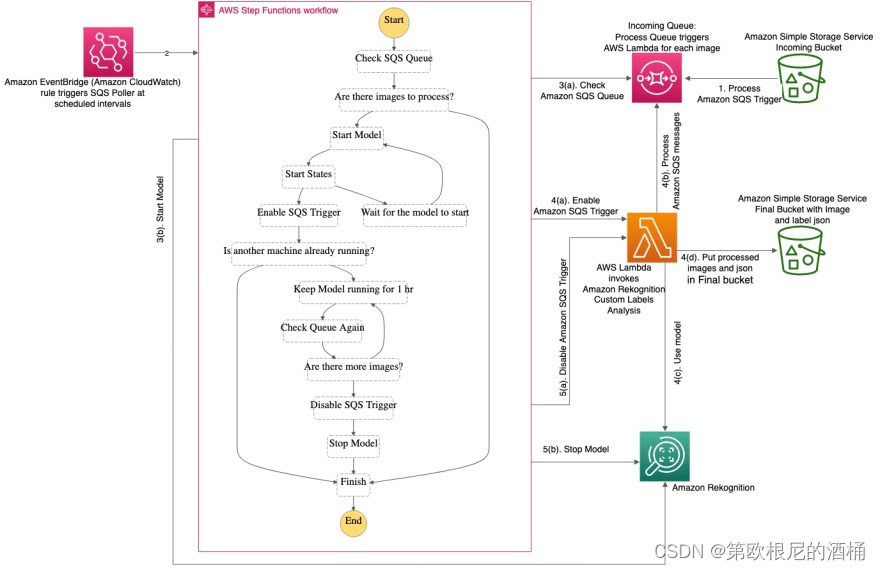
该应用程序创建了一个基于预定义时间表运行的无服务器亚马逊Rekognition自定义标签检测工作流(请注意,默认情况下在部署时启用该时间表)。它展示了Step Functions用于编排Lambda函数和其他AWS资源形成复杂而健壮的工作流的能力,结合了使用Amazon EventBridge的事件驱动开发。
- 当图像存储在Amazon S3桶中时,它触发了一个信息,该信息被存储在Amazon SQS队列中。
- Amazon EventBridge被配置为以一定频率(默认为1小时)触发AWS Step Function工作流。
- 当工作流运行时,它检查Amazon SQS队列中的项目数量。如果队列中没有要处理的项目,工作流结束。如果队列中有要处理的项目,工作流启动亚马逊Rekognition自定义标签模型,并启用Amazon SQS与Lambda函数的集成来处理这些图像。
- 一旦启用了Amazon SQS队列与Lambda的集成,Lambda开始使用亚马逊Rekognition自定义标签处理图像。
- 一旦所有图像处理完成,工作流停止亚马逊Rekognition自定义标签模型并禁用Amazon SQS队列与Lambda函数之间的集成
Rekognition API的关键点
- API操作不会保存任何生成的标签。我们可以通过将这些标签放置在数据库中来保存它们,以及相应图像的标识符。
- Rekognition视频API包括以下功能:
▪ 流媒体视频的实时分析;
▪ 人员识别和路径追踪;
▪ 面部识别;
▪ 面部分析;
▪ 检测物体、场景和活动;
▪ 不当视频检测;以及
▪ 名人识别。 - Rekognition图像API包括以下功能;
▪ 物体和场景检测;
▪ 面部识别;
▪ 面部分析;
▪ 面部比较;
▪ 不安全图像检测;
▪ 名人识别;以及
▪ 图像中的文字。
Rekognition代码示例
此示例显示检测到的面部的预估年龄范围和其他属性,并列出所有检测到的面部属性的JSON。更改photo的值为图像文件名。更改bucket的值为存储图像的Amazon S3桶。
import boto3
import json
# 定义检测面部的函数
def detect_faces(photo, bucket):
# 创建Rekognition客户端
client=boto3.client('rekognition')
# 调用detect_faces方法
response = client.detect_faces(Image={'S3Object':{'Bucket':bucket,'Name':photo}},Attributes=['ALL'])
print('Detected faces for ' + photo)
for faceDetail in response['FaceDetails']:
# 打印检测到的面部的年龄范围
print('The detected face is between ' + str(faceDetail['AgeRange']['Low'])
+ ' and ' + str(faceDetail['AgeRange']['High']) + ' years old')
print('Here are the other attributes:')
# 打印面部详细属性的JSON格式
print(json.dumps(faceDetail, indent=4, sort_keys=True))
# 访问个别面部细节的预测并打印它们
print("Gender: " + str(faceDetail['Gender']))
print("Smile: " + str(faceDetail['Smile']))
print("Eyeglasses: " + str(faceDetail['Eyeglasses']))
print("Emotions: " + str(faceDetail['Emotions'][0]))
# 返回检测到的面部数量
return len(response['FaceDetails'])
def main():
# 图像文件名和存储桶名称
photo='photo'
bucket='bucket'
# 调用detect_faces函数并打印检测到的面部数量
face_count=detect_faces(photo, bucket)
print("Faces detected: " + str(face_count))
if __name__ == "__main__":
main()















 7333
7333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











