







什么是YOLOv7?
YOLOv7 是一款单级实时目标检测器。它于 22 年 7 月被引入 YOLO 家族。根据 YOLOv7 的论文,它是迄今为止最快、最准确的实时目标检测器。YOLOv<> 通过提升其性能来建立一个重要的基准。
本文包含简化的 YOLOv7 论文解释和推理测试。我们将浏览 YOLOv7 GitHub 存储库并测试推理。我们还将看到 YOLOv7 与 YOLO 系列的其他目标检测器的比较。
这篇文章将涵盖哪些内容?
1. YOLOv7架构,有什么新功能?
2. 使用 YOLOv7 进行目标检测
3.YOLOv7 模型和对比分析
4.YOLOv7 Pose:人体姿态估计
YOLO架构概述
YOLOv7 有什么新功能?
YOLOv7 架构
YOLOv7 中可训练的免费赠品袋
YOLOv7实验与结果
mAP 比较:YOLOv7 与其他
FPS 比较:YOLOv7 与其他
YOLOv7 目标检测推理
YOLOv4、YOLOv5-Large和YOLOv7对比
YOLOv7 姿态估计
YOLOv7 姿势先决条件
YOLOv7 姿势代码
YOLOv7 总结
YOLO架构概述
YOLO架构是基于FCNN(全连接神经网络)的。但是,基于 Transformer 的版本最近也被添加到 YOLO 系列中。我们将在另一篇文章中讨论基于 Transformer 的探测器。现在,让我们关注基于 FCNN(全卷积神经网络)的 YOLO 对象检测器。
YOLO框架有三个主要组件。
- 骨干
- 头
- 脖子
Backbone 主要提取图像的基本特征,并将它们通过颈部馈送到头部。Neck 收集 Backbone 提取的特征图并创建特征金字塔。最后,头部由具有最终检测的输出层组成。YOLOv4、YOLOv4和YOLOv5的架构如下表所示。
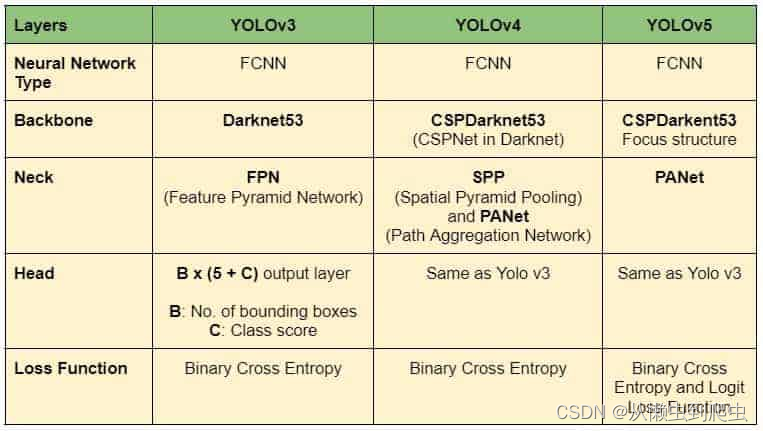
表1:YOLOv3、YOLOv4和YOLOv5模型架构汇总
YOLOv7 有什么新功能?
YOLOv7 通过引入多项架构改革来提高速度和准确性。与 Scaled YOLOv4 类似,YOLOv7 主干网不使用 ImageNet 预训练主干网。相反,这些模型完全使用 COCO 数据集进行训练。这种相似性是可以预料的,因为 YOLOv7 与 Scaled YOLOv4 的作者相同,后者是 YOLOv4 的扩展。YOLOv7 论文中引入了以下主要更改。我们将一一介绍它们。
建筑改革
E-ELAN(扩展高效层聚合网络)
基于串联的模型的模型缩放
可训练的 BoF(免费赠品袋)
计划的重新参数化卷积
粗用于辅助,细用于铅损
YOLOv7 架构
该体系结构派生自 YOLOv4、Scaled YOLOv4 和 YOLO-R。以这些模型为基础,进行了进一步的实验,以开发新的和改进的YOLOv7。
YOLOv7 论文中的 E-ELAN (Extended Efficient Layer Aggregation Network)
E-ELAN 是 YOLOv7 骨干网中的计算块。它从以前对网络效率的研究中获得启发。它是通过分析以下影响速度和准确性的因素来设计的。
- 内存访问成本
- I/O 通道比率
- 元素明智操作
- 激活
- 梯度路径
简单来说,E-ELAN架构使框架能够更好地学习。它基于 ELAN 计算块。在撰写本文时,ELAN论文尚未发表。我们将通过添加 ELAN 详细信息来更新帖子(如果可用)。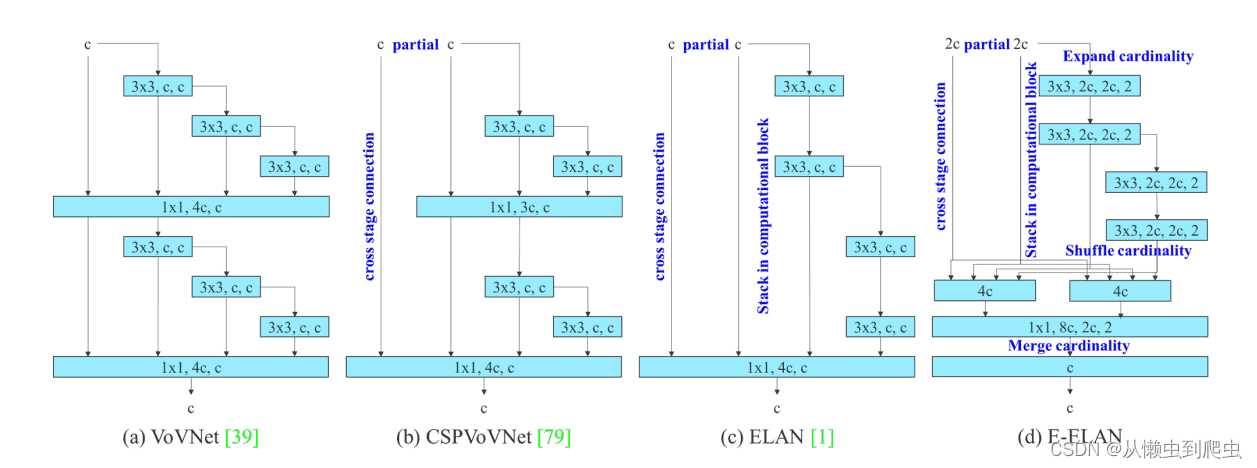
图:E-ELAN和之前关于最大层效率的工作
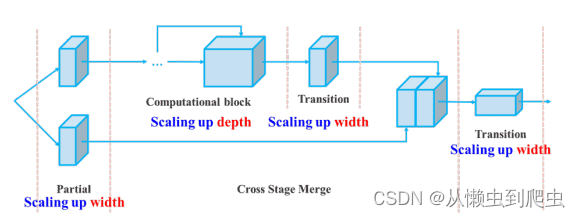
YOLOv7 中的复合模型缩放
不同的应用需要不同的型号。虽然有些需要高度精确的模型,但有些优先考虑速度。执行模型缩放以满足这些要求并使其适合各种计算设备。
缩放模型大小时,将考虑以下参数。
- 分辨率(输入图像的大小)
- 宽度(通道数)
- 深度(层数)
- 阶段(特征金字塔的数量)
NAS(Network Architecture Search,网络架构搜索)是一种常用的模型扩展方法。研究人员使用它来遍历参数以找到最佳比例因子。但是,像 NAS 这样的方法可以进行特定于参数的缩放。在这种情况下,比例因子是独立的。
YOLOv7 论文的作者表明,它可以通过复合模型缩放方法进一步优化。在这里,宽度和深度是以相干方式缩放的,用于基于串联的模型。
YOLOv7 中可训练的免费赠品袋
BoF 或 Bag of Freebies 是在不增加训练成本的情况下提高模型性能的方法。YOLOv7 引入了以下 BoF 方法。
计划的重新参数化卷积
重新参数化是一种在训练后用于改进模型的技术。它增加了训练时间,但改善了推理结果。两种类型的重新参数化用于最终确定模型:模型级和模块级集成。
模型级重新参数化可以通过以下两种方式完成。
- 使用不同的训练数据但相同的设置,训练多个模型。然后对它们的权重进行平均以获得最终模型。
- 取不同时期模型权重的平均值。
最近,模块级重新参数化在研究中获得了很大的关注。在这种方法中,模型训练过程被拆分为多个模块。输出被集成以获得最终模型。YOLOv7 论文中的作者展示了执行模块级集成的最佳方法(如下所示)。
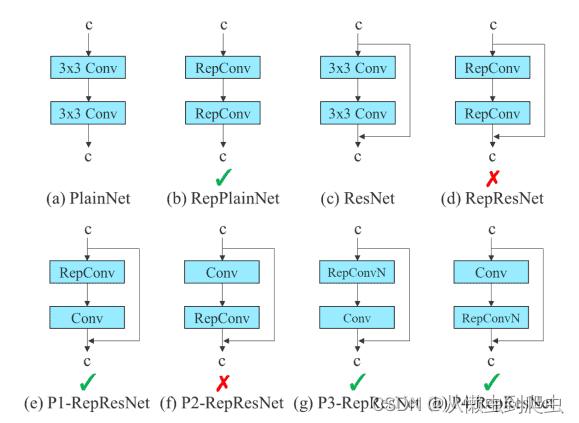
图:重新参数化试验
在上图中,E-ELAN 计算块的 3×3 卷积层被替换为 RepConv 层。我们通过切换或替换 RepConv、3×3 Conv、Identity connection 的位置来进行的实验。上面显示的残差旁路箭头是身份连接。它只不过是一个 1×1 卷积层。我们可以看到有效的配置和无效的配置。在 RepVGG 论文中查看有关 RepConv 的更多信息。
包括 RepConv,YOLOv7 还对 Conv-BN(卷积批处理归一化)、OREPA(在线卷积重参数化)和 YOLO-R 进行重新参数化,以获得最佳结果。我们将在另一篇文章中讨论实现部分。
粗用于辅助,细用于铅损
正如您现在已经知道的那样,YOLO架构由骨干,脖子和头部组成。头部包含预测的输出。YOLOv7 并不局限于单个磁头。它有多个头可以做任何它想做的事。很有趣,不是吗?
然而,这并不是第一次引入多头框架。深度监督是深度学习模型使用的一种技术,它使用多个头部。在 YOLOv7 中,负责最终输出的磁头称为 Lead 磁头。 而用于辅助中间层训练的头部称为辅助头部。
在辅助损失的帮助下,更新了辅助头的重量。它允许深度监督,并且模型学习得更好。这些概念与铅头和标签分配器密切相关。
标签分配器是一种将网络预测结果与真实值一起考虑,然后分配软标签的机制。需要注意的是,标签分配器生成的是软标签和粗标签,而不是硬标签。
引线头引导标签分配器和从粗到细的引线头引导标签分配器
Lead Head Guided Label Assigner 封装了以下三个概念。
- 引线头
- 辅助头
- 软标签分配器
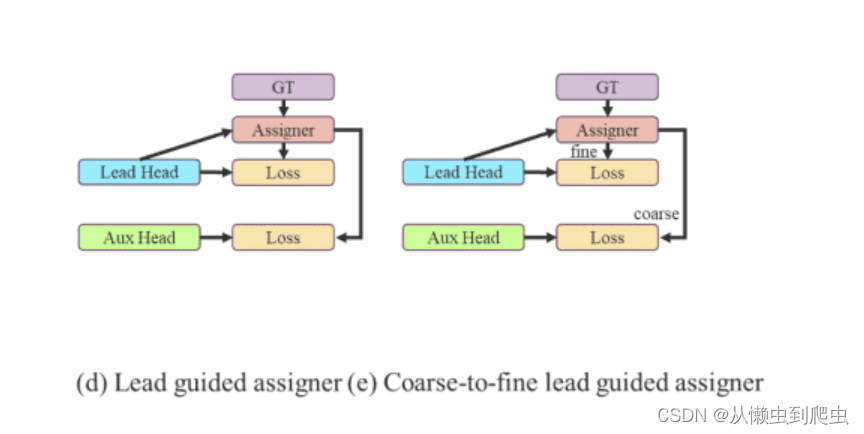
OLOv7 网络中的 Lead Head 预测最终结果。软标签是根据这些最终结果生成的。重要的部分是,根据生成的相同软标签计算引线头和辅助头的损耗。最终,两个头都使用软标签进行训练。如上图左图所示。
有人可能会问,“为什么是软标签? 作者在论文中说得很好:
“之所以这样做,是因为领导头具有较强的学习能力。因此,由此生成的软标签应该更能代表源数据与目标之间的分布和相关性。通过让较浅的辅助头直接学习铅头已经学到的信息,铅头将能够更专注于学习尚未学习的剩余信息。
现在,来到从粗到细的标签,如上图右图所示。在上述过程中,生成了两组软标签。
- 用于训练铅头的精细标签
- 一组用于训练辅助头的粗标签。
精细标签与直接生成的软标签相同。然而,更多的网格被视为生成粗标的正目标。这是通过放宽正样本分配过程的约束来实现的。
YOLOv7实验与结果
所有 YOLOv7 型号在速度和精度方面都超过了以前的目标探测器,范围为 5 FPS 至 160 FPS。下图很好地说明了 YOLOv7 模型与其他模型相比的平均精度 (AP) 和速度。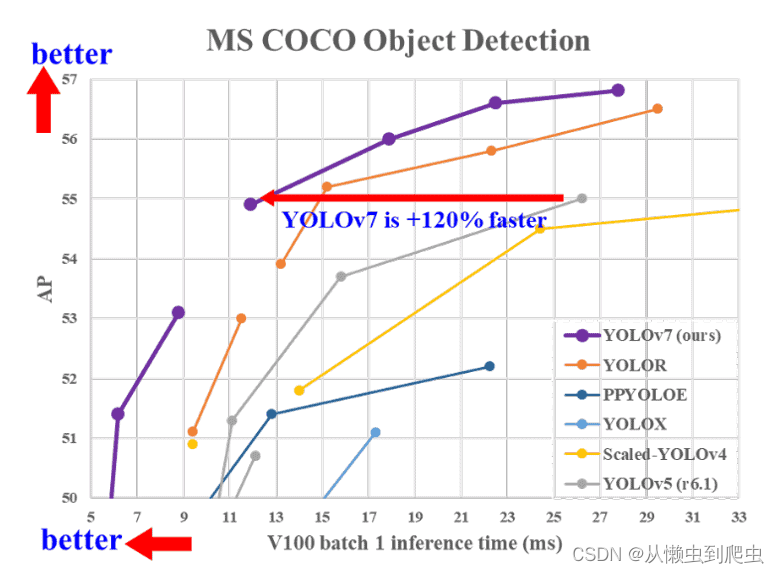
从图中可以清楚地看出,从 YOLOv7 开始,在速度和准确性方面与 YOLOv7 没有竞争。
注意:进一步讨论的结果来自 YOLOv7 论文,其中所有推理实验都是在 Tesla V100 GPU 上完成的。所有 AP 结果均在 COCO 验证或测试集上完成。
mAP 比较:YOLOv7 与其他
下表显示了 YOLOv7 模型与其他基线对象检测器的比较。
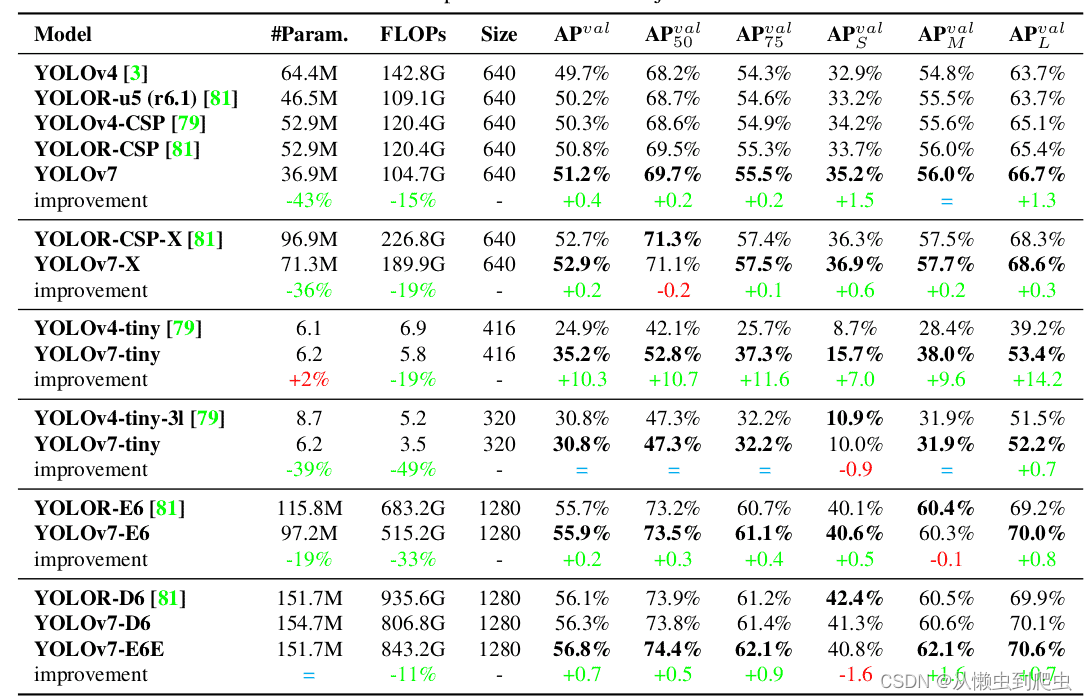
表:YOLOv7 与其他基线模型
上面显示的结果大多是根据一组特定模型的一系列参数组合在一起的。
从 YOLOv7-Tiny 模型开始,它是该系列中最小的模型,只有 6 多万个参数。凭借 35.2% 的验证 AP,它击败了具有类似参数的 YOLOv4-Tiny 模型。
具有近 7 万个参数的 YOLOv37 正态模型提供 51.2% 的 AP。它击败了 YOLOv4 和 YOLOR 的变体,它们很容易拥有更多参数。
YOLO7 系列中较大的型号是 YOLOv7-X、YOLOv7-E6、YOLOv7-D6 和 YOLOv7-E6E。所有这些都击败了具有相似或更少参数的相应 YOLOR 模型,并分别给出了 52.9%、55.9%、56.3% 和 56.8% 的 AP。
现在,YOLOv4 超越的不仅仅是 YOLOv7 和 YOLOR 模型。将验证 AP 与参数在相同范围内的 YOLOv5 和 YOLOv7 模型的验证 AP 进行比较,很明显 YOLOv7 也击败了所有 YOLOv5 模型。
FPS 比较:YOLOv7 与其他
YOLOv2 论文中的表 7 提供了 YOLOv7 与其他模型的 FPS 的综合比较。它还包括 COCO mAP 比较。
已经确定 YOLOv7 在 5 FPS 到 160 FPS 范围内具有最高的 FPS 和 mAP。所有的FPS比较都是在Tesla V100 GPU上完成的。
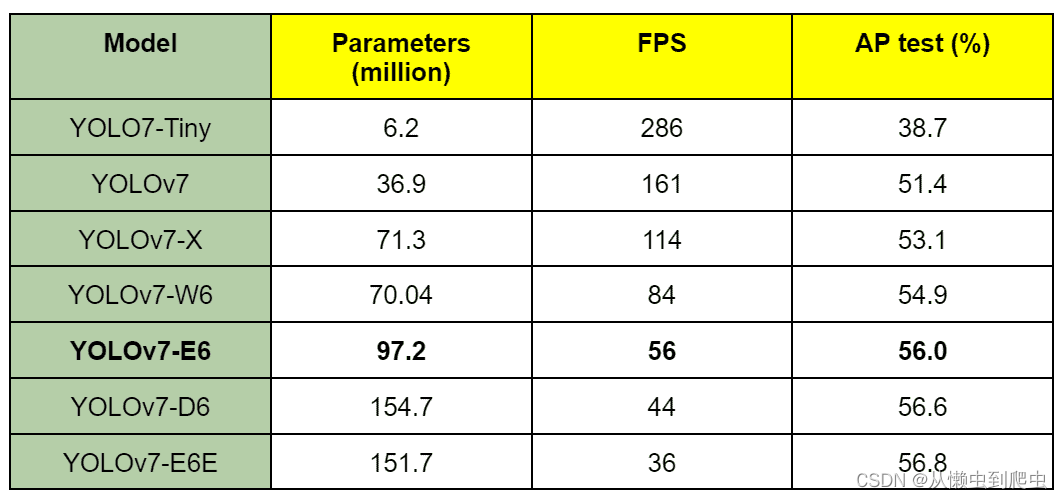
桌子: YOLOv7 型号 FPS 比较
值得注意的是,没有一个 YOLOv7 模型适用于移动设备/移动 CPU(如 YOLOv7 论文中提到的)。
YOLOv7-Tiny、YOLOv7 和 YOLOv7-W6 分别适用于边缘 GPU、普通(消费级)GPU 和云 GPU。
YOLOv7-E6 和 YOLOv7-D6 以及 YOLOv7-E6E 也仅适用于高端云 GPU。
尽管如此,所有 YOLOv7 型号在 Tesla V30 GPU 上的运行速度都超过 100 FPS,这比实时 FPS 还要高。
上述实验证明,YOLOv7模型的性能优于现有的目标检测器。无论是在速度还是准确性方面。
YOLOv7 目标检测推理
现在,让我们进入博客文章中令人兴奋的部分,即使用 YOLOv7 对视频进行推理。我们将使用 YOLOv7 和 YOLOv7-Tiny 模型运行推理。除此之外,我们还将结果与 YOLOv5 和 YOLOv4 模型的结果进行比较。

在这里,我们将对描述以下三种不同场景的三个视频进行推理。
- 第一个视频是测试 YOLOv7 目标检测模型在小型和远处物体上的性能。
- 第二个视频有很多人描绘了一个拥挤的场景。
- 第三个视频是许多YOLO模型(v4、v5和v7)在检测物体时犯相同的一般错误。
此处的 YOLOv7 结果一起显示在所有三个视频的 Tiny 和 Normal 模型中。这将有助于我们以简单的方式比较每个结果的结果。
让我们使用 YOLOv7-Tiny(上)和 YOLOv7(下)模型检查第一个视频的检测推理结果。以下命令用于使用 Tiny 和 Normal 模型运行推理。
python detect.py --source ../inference_data/video_1.mp4 --weights yolov7-tiny.pt --name video_tiny_1 --view-img
python detect.py --source ../inference_data/video_1.mp4 --weights yolov7.pt --name video_1 --view-img
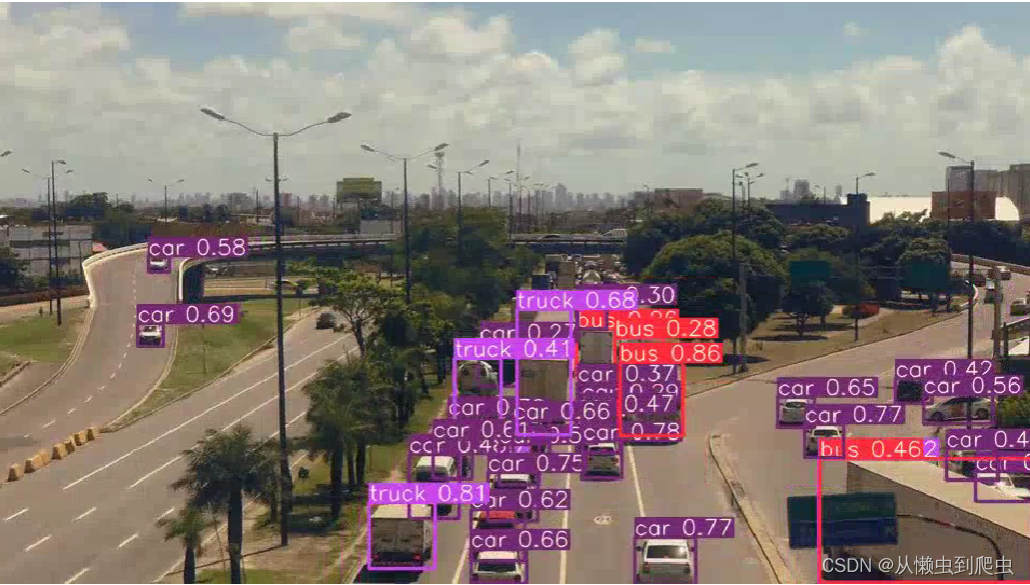 YOLOv7-tiny
YOLOv7-tiny
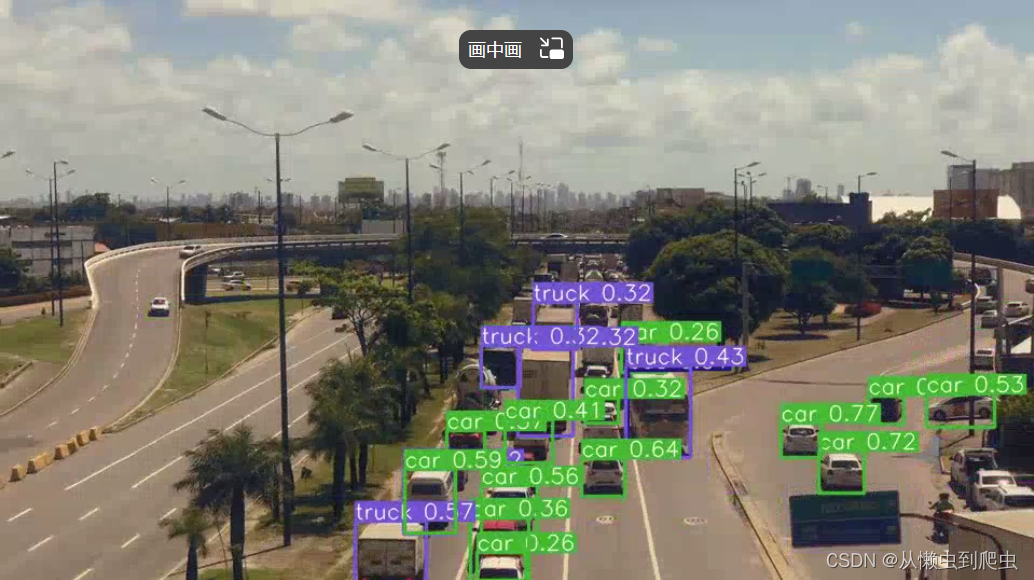 YOLOv7-普通
YOLOv7-普通
我们可以立即看到 YOLOv7-Tiny 模型的局限性。它无法检测汽车、摩托车和距离很远的人。YOLOv7 模型可以更好地检测这些对象。但这还不是故事的全部。虽然 YOLO7-Tiny 的性能不是那么好,但它比 YOLOv7 快得多。虽然 YOLOv7 提供了大约 19 FPS,但 YOLOv7-Tiny 以大约 42 FPS 的速度运行,这远高于实时。
现在,让我们看看第二个视频的结果,它描绘了一个拥挤的场景。我们使用与上述相同的命令,但根据视频路径和名称更改 –source 和 –name 标志的值。
YOLOv7 微型
与 YOLOv7-Tiny 模型相比,YOLOv7 模型可以检测波动更小、更有信心的人。不仅如此,YOLOv7-Tiny还错过了一些红绿灯和远处的人。
让我们在最后一个视频上运行推理,该视频显示了所有 YOLOv7 模型中的一些一般故障案例。

YOLOv7 微型

YOLOv7 普通
我们可以看到两种模型中的一些常见错误:
- 检测其他道路标志作为停车标志。
- 错误地将禁止的道路符号检测为人。
正如我们稍后将看到的,上述两个错误在 YOLOv4 和 YOLOv5 中很常见。
尽管 YOLO7-Tiny 比 YOLOv7 模型犯的错误更多,但它的速度要快得多。平均而言,YOLOv7-Tiny 的运行速度超过 40 FPS,而 YOLOv7 型号的运行速度略高于 20 FPS。
YOLOv4、YOLOv5-Large和YOLOv7模型对比
以下三个视频显示了其中一个视频中 YOLOv4、YOLOv5-Large 和 YOLOv7 模型之间的比较(从上到下)。这将使我们对每个模型在各种场景中的表现有一个适当的定性概念。
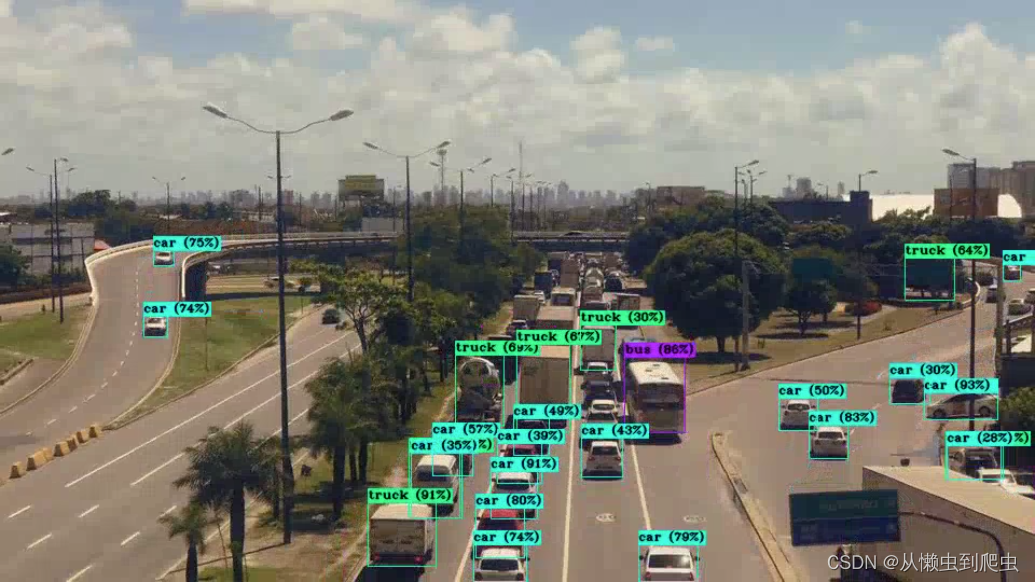 YOLOv4
YOLOv4

YOLOv5-大型
 YOLOv7
YOLOv7
YOLOv7 姿态估计
YOLOv7 是 YOLO 系列中第一个包含人体姿态估计模型的产品。这真的很有趣,因为那里的实时模型很少。
最近,官方存储库也更新了预训练的姿态估计模型。因此,我们不会在这篇文章中介绍细节。稍后将发表一篇关于 YOLOv7 姿态估计模型内部结构的专门文章。在本节中,我们将讨论应用程序部分并观察其工作原理。
YOLOv7 姿势先决条件
首先,请确保您已经克隆了 YOLOv7 GitHub 存储库。现在,在克隆的 yolov7 目录中执行以下命令,下载预训练的姿态估计模型。
YOLOv7 姿势代码
我们需要一个自定义脚本来使用预先训练的模型运行姿态估计推理。让我们在 yolov7 目录中的新 yolov7_keypoint.py 脚本中编写代码。
import matplotlib.pyplot as plt
import torch
import cv2
import numpy as np
import time
from torchvision import transforms
from utils.datasets import letterbox
from utils.general import non_max_suppression_kpt
from utils.plots import output_to_keypoint, plot_skeleton_kpts
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
weigths = torch.load('yolov7-w6-pose.pt')
model = weigths['model']我们导入所有必需的模块并加载预训练的 yolov7-w6-pose.pt 模型,并初始化源视频路径的video_path变量。如果您打算在自己的视频上运行此推理,请相应地更改video_path。
接下来,让我们从磁盘读取视频并创建 VideoWriter 对象以将生成的视频保存在磁盘上。
cap = cv2.VideoCapture(video_path)
if (cap.isOpened() == False):
print('Error while trying to read video. Please check path again')
# Get the frame width and height.
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
# Pass the first frame through `letterbox` function to get the resized image,
# to be used for `VideoWriter` dimensions. Resize by larger side.
vid_write_image = letterbox(cap.read()[1], (frame_width), stride=64, auto=True)[0]
resize_height, resize_width = vid_write_image.shape[:2]
save_name = f"{video_path.split('/')[-1].split('.')[0]}"
# Define codec and create VideoWriter object .
out = cv2.VideoWriter(f"{save_name}_keypoint.mp4",
cv2.VideoWriter_fourcc(*'mp4v'), 30,
(resize_width, resize_height))最后,我们有一个 while 循环贯穿视频中的每一帧。
while(cap.isOpened):
# Capture each frame of the video.
ret, frame = cap.read()
if ret:
orig_image = frame
image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB)
image = letterbox(image, (frame_width), stride=64, auto=True)[0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
image = image.to(device)
image = image.half()
# Get the start time.
start_time = time.time()
with torch.no_grad():
output, _ = model(image)
# Get the end time.
end_time = time.time()
# Get the fps.
fps = 1 / (end_time - start_time)
# Add fps to total fps.
total_fps += fps
# Increment frame count.
frame_count += 1上面的代码:
- 循环遍历每一帧。
- 执行姿态估计。
- 创建输出帧。
- 将 FPS 写入当前生成的帧的顶部。
- 在屏幕上显示生成的帧,并将其写入磁盘。
现在,让我们执行上面的代码进行 YOLOv7 姿态估计。
|

考虑到我们获得的高FPS,结果看起来相当不错。但请注意,我们在这里得到的 60 FPS 仅适用于模型的前向传递。如果我们包括 NMS(非最大抑制)、阈值和注释等后处理,FPS 可能会降低。尽管如此,它仍然令人印象深刻。
YOLOv7 总结
至此,我们结束了对 YOLOv7 的介绍。我希望你喜欢阅读这篇文章。总之,我们涵盖了以下内容。
- YOLO 的总体架构由 Backbone、Neck 和 Head 组成。
- YOLOv7 的架构改革。
- E-ELAN公司
- YOLOv7 中的复合模型缩放
- YOLOv7 中可训练的免费赠品袋。
- YOLOv7 中的重新参数化
- 粗用于辅助,细用于铅损耗
- 如何使用 YOLOv7 GitHub 存储库运行对象检测推理。
- YOLOv7 在速度和准确性方面超越了所有实时目标检测器。
- 帧率:5 – 165
- mAP:51.4% – 56.8%
- YOLOv7 减少了 40% 的参数和 50% 的计算量,但提高了性能。这是一项重大壮举。
- 如何使用 YOLOv7 姿态估计(关键点检测)模型。















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









