






 本文介绍了如何使用Transformer模型,特别是BERT-base-multilingual-uncased,在斯瓦希里语数据集上进行文本分类,通过预处理、数据划分和ktrain工具简化训练过程,探讨了迁移学习和解决多语言挑战的方法。
本文介绍了如何使用Transformer模型,特别是BERT-base-multilingual-uncased,在斯瓦希里语数据集上进行文本分类,通过预处理、数据划分和ktrain工具简化训练过程,探讨了迁移学习和解决多语言挑战的方法。
这里我不会解释Transformer模型是如何工作的,如果想要了解,请看我的其它博客。但为了展示它们在多语言用例上的应用,我将使用斯瓦希里语数据集来训练多语言变压器。你可以从这里获取数据,了解它们是为了解决什么问题而收集的。我假设读者已经具备传统机器学习和深度学习的先决知识。
变压器是什么?
变压器是通过大量数据集训练的转移学习深度学习模型,用于执行自然语言处理领域的不同用例,如文本分类、问题回答、机器翻译、语音识别等。根据维基百科的说法,变压器是采用自我关注机制的深度学习模型,不同地加权输入数据的各个部分的重要性。它们主要用于自然语言处理(NLP)和计算机视觉(CV)领域。
使用小数据集训练深度学习模型更可能面临过拟合问题,因为深度学习对于复杂模式识别至关重要,有许多参数,它们确实需要大量数据集来良好地执行/概括挑战的性质。
使用变压器的优势是可以在来自维基百科和不同书籍收藏的大量语料库上进行训练,这在你用新的数据集验证这个模型时,针对特定问题会更加顺畅。在处理用其他语言(如阿拉伯语、斯瓦希里语、德语情感等)数据集的其他挑战时,我所知道的一些技术包括:
- 将你自己语言的数据翻译成英语,然后使用训练有素的英语模型解决挑战。这取决于你正在尝试解决的问题的性质,或者你认为是否有完美的模型来执行翻译任务。
- 扩充你自己语言的训练数据。这可以通过取一个大型英语数据集,然后将其翻译成你自己的语言来适应你正在解决的挑战的性质,然后与你自己语言的小数据结合,之后对变压器模型进行微调。
- 使用你自己语言的数据重新训练大型模型(变压器),这在自然语言处理中最为人熟知的技术之一是转移学习。
让我们深入本文的主题,我们将训练一个用于斯瓦希里语新闻分类的变压器模型。由于变压器模型庞大,为了简化任务,我们需要选择一个工作包装器。如果你擅长使用PyTorch,你可以使用PyTorch Lightning——一种用于高性能人工智能研究的包装器,来包装变压器,但今天我们将使用来自Tensorflow Python库的ktrain。
ktrain是深度学习库TensorFlow Keras(及其他库)的轻量级包装器,旨在帮助构建、训练和部署神经网络和其他机器学习模型。受fastai和ludwig等机器学习框架扩展的启发,ktrain旨在使深度学习和人工智能更易于访问和应用,无论对于新手还是有经验的从业者。仅需几行代码,ktrain就可以轻松快速地实现。
如果你想了解更多关于ktrain的信息,这里是一个很好的起点。
我推荐使用google colab或kaggle kernel,为了简化任务,这些平台提供的计算能力可以使事情顺利进行。
第一个任务是更新pip并在你的工作环境中安装ktrain。这可以通过运行以下几个命令简单完成。
!pip install -U pip
!pip install ktrain
然后导入所有所需的库,用于预处理文本数据和其他计算目的。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import os
from nltk import word_tokenize
import string
import re
import warnings
warnings.filterwarnings("ignore")
现在是时候加载我们的数据集并检查它们的样子,以及它们包含哪些特征了。
# 加载数据集
df = pd.read_csv("data/Train.csv")
# 总记录
print("Total Records: ", df.shape[0])
# 从顶部预览数据
df.head()
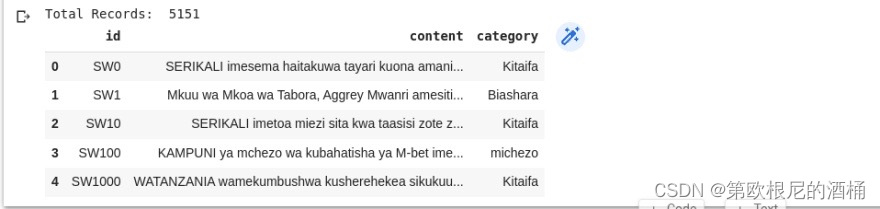
前5行数据
你可以看到数据集有3列:ID 作为每条情感/新闻的唯一标识,content 包含新闻内容,category 包含每条具体新闻/情感的标签。接下来,让我们可视化目标列,以了解数据集中每类新闻的分布情况。
#让我们使用 seaborn 来可视化标签分布情况
plt.figure(figsize=(15,7))
sns.countplot(x='category',data=df)
plt.title("DISTRIBUTION OF LABELS")
plt.show()
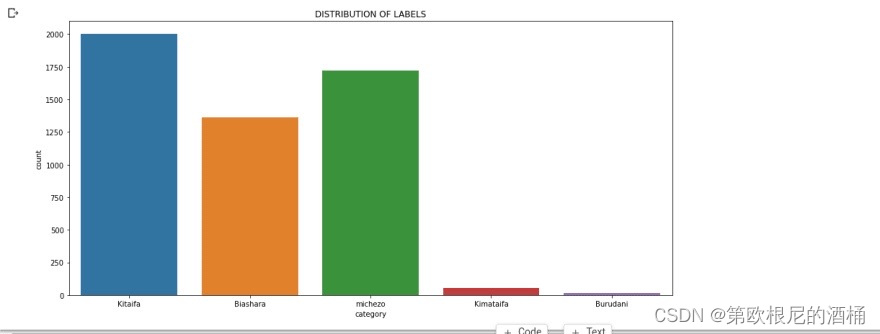
标签分布
可以看到,我们正在处理的数据集包含5个类别(标签),并且分布不均衡,因为收集到的大多数新闻属于“国内”类别,而属于“国际”和“娱乐”类别的新闻相对较少。
因此,在将文本适配到我们的变压器模型之前,我们可以考虑先对文本进行清洗,包括去除标点符号、去除数字、转换为小写、去除不必要的空白、去除表情符号、去除停用词、分词等。我创建了一个 clean_text 函数来执行这些任务。
# 文本清洗函数
def clean_text(sentence):
'''
清理内容列的功能,使其为转换和建模做好准备
'''
sentence = sentence.lower() #把字母转化为小写
sentence = re.sub('‘','',sentence) # 删除经常出现的文本` ‘ `
sentence = re.sub('[‘’“”…,]', '', sentence) # 移除标点符号
sentence = re.sub('[()]', '', sentence) #删除括号
sentence = re.sub("[^a-zA-Z]"," ",sentence) #删除数字并仅保留文本/字母表
sentence = word_tokenize(sentence) # 删除重复的字符 (tanzaniaaaaaaaa to tanzania)
return ' '.join(sentence)
现在,让我们把clean_text函数应用到模型中
df['content'] = df['content'].apply(clean_text)
df.head()
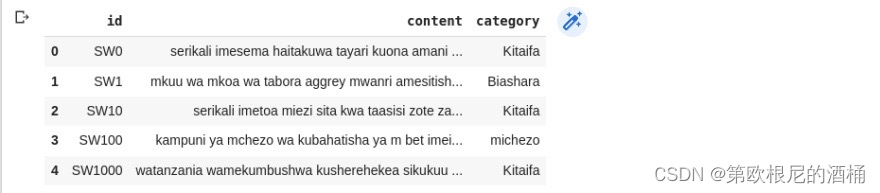
现在您可以注意到我们数据集内容的差异。
然后,让我们将数据集分为训练集和验证集,训练集将用于训练我们的模型和验证集,用于模型验证其在新数据上的性能。
df = df[['category', 'content']]
SEED = 2020
df_train = df.sample(frac=0.85, random_state=SEED)
df_test = df.drop(df_train.index)
len(df_train), len(df_test)
85%的数据集将用于训练模型,15%将用于验证我们的模型,看看是否能很好地概括并评估性能。永远不要忘记设置种子值,以帮助每次获得可预测、可重复的结果。如果我们不设置种子,那么我们在每次调用时都会得到不同的随机数。
在 ktrain 的 Transformer API 中,我们可以选择任何适合我们数据的 Hugging Face transformers 模型。由于我们处理的是斯瓦希里语,我们将使用多语言 BERT,它通常被 ktrain 用于处理非英语数据集,作为替代文本分类器 API 的一部分。但您也可以选择任何其他多语言 transformer 模型。
让我们导入 ktrain 并设置一些模型的常见参数,重要的是要指定您将使用哪种 transformer 模型,然后确保它与您要解决的问题兼容。让我们将我们的 transformer 模型设置为 bert-base-multilingual-uncased 并设置如下参数:
MAXLEN指定每个新闻内容的前 128 个词将被考虑。这个参数可以根据您的机器的计算能力进行调整,要注意,设置得越高意味着您希望覆盖更大的内容,如果您的机器无法处理这样的计算,就会出现资源耗尽的错误,所以请务必考虑这一点。batch_size作为一次迭代中使用的训练示例数量,我们使用 32。learning_rate作为训练期间权重更新的幅度,我们使用 5e-5 的学习率,您也可以调整它来查看您的模型的表现,建议使用较小的值。epochs完成整个训练数据集所需的传递次数,现在让我们使用 3 个周期,这样我们的模型将在几分钟内使用。
import ktrain
from ktrain import text
# 选择合适的transformer使用
MODEL_NAME = 'bert-base-multilingual-uncased'
# 标准超参数
MAXLEN = 128
batch_size = 32
learning_rate = 5e-5
epochs = 3
参数设置后。是时候用斯瓦希里语数据集训练我们的第一个变压器了,指定训练和验证集,让预处理器函数与文本一起工作,然后适合我们的模型,以便它可以从数据集中学习。这个过程可能需要几分钟才能完成,具体取决于您选择的计算能力。
t = text.Transformer(MODEL_NAME, maxlen = MAXLEN)
trn = t.preprocess_train(df_train.content.values, df_train.category.values)
val = t.preprocess_test(df_test.content.values, df_test.category.values)
model = t.get_classifier()
learner = ktrain.get_learner(model, train_data=trn, val_data=val, batch_size=batch_size)
learner.fit(learning_rate, epochs)
终于完成了训练斯瓦希里语数据集的变压器任务,现在是测试我们训练过的斯瓦希里语模型的性能的时候了。

现在你可以看到我们训练有素的模型,准确率为train_set的88.40%和验证集的84.35
我从Train.csv文件中复制了第一个新闻内容,看看斯瓦希里语模型如何与它一起工作,它做了正确的分类,因为句子很长,你可以在笔记本上查看。
让我们尝试用简短的内容预测用于训练该模型的数据集的这些类别(Kitaifa、michezo、Biashara、Kimataifa、Burudani)的范围,然后看看输出是什么。
Swahili = "Simba SC ni timu bora kwa misimu miwili iliyopita katika ligi kuu ya Tanzania"
English = "Simba S.C are the best team for the last two seasons in the Tanzanian Premier League "
如果您想访问本文中使用的完整代码,请前往链接


















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











