







目录
删除movies和users中没在ratings中出现过的数据
图神经网络(Graph Neural Network,GNN)是近年来AI领域一个热门的方向。在推荐系统中,大部分数据都具有图结构,如用户物品的交互信息可以构建为二部图,用户的社交网络和商品信息可以构建为同质图。通过利用图结构反复迭代更新图节点的embedding,就能够最终获得可靠的图节点embedding信息,而这种迭代过程,其实体现的是远距离的节点将信息逐步通过图结构传递信息的过程,所以图结构是可以进行知识传递和补充的[1]。
在之前我一直想对GNN结合推荐系统这块进行学习,但是刚开始的时候陷入了一个困境,就是一直在学习图学习的一些理论知识,如图卷积神经网络(Graph Convolutional Network, GCN)[2]背后严格的数学证明,什么拉普拉斯矩阵、傅里叶变换等等,在这块花了不少的时间,虽然学这些对理解图深度学习确实有帮助,但是死磕理论往往也会导致说起来头头是道,具体解决问题时畏手畏脚的问题。我自己学了一段时间后发现自己理论也没搞得多么精通,具体解决问题时更是一头雾水,所以还是准备结合具体的一些实例展开学习。
本人在这块学习时首先对中科院何向南老师团队的图卷积协同过滤(Neural Graph Collaborative Filtering,NGCF)[3]进行了学习,这篇论文的具体代码实现较为简单,具体来说应该属于谱域图卷积在推荐领域的应用,因为是一篇学术界的论文,个人感觉这个方法如果要在工业界落地应用的话可能还有很多的问题需要解决。之后学习了Inductive Representation Learning on Large Graphs[4]和Graph Convolutional Neural Networks for Web-Scale Recommender Systems[5]两篇斯坦福的论文,这两篇论文分别提出的GraphSAGE和PinSAGE技术可谓是真正在工业界能进行落地应用的技术。其中后者诞生于斯坦福和Pinterest公司合作提出的第一个工业级别(数十亿节点和数百亿边)基于GCN的推荐系统,并在离线评估和AB实验选中取得了不错的效果。个人感觉还是学习一些真正能落地的东西可能会更好,所以准备出一个系列对PinSAGE好好学习从头到尾好好学习一把。
图深度学习目前有两个常用框架DGL和PyG,其中DGL提供了一个实现PinSAGE的example,PyG中好像没有,所以本系列主要针对DGL中PinSAGE算法的实现进行学习分享,既学习算法的同时又学会了DGL,在实践中学习,一举两得。首先开始本系列的第一篇:MovieLens数据集处理,其中包括了数据的读取、切分、图的创建等等,掌握了数据具体的格式才能对算法各个细节掌握的更加透彻。
对于PinSAGE算法具体原理可以先看看论文,也可以参考一下这几位大佬的的文章[6][7][8],在之后我也会结合DGL中的源码实现简略对原理部分进行分享。
MovieLens数据集处理
数据处理这部分主要涉及三个文件:process_movielens1m.py、builder.py、data_utils.py
- process_movielens1m.py:主要负责从磁盘加载文件转成DataFrame格式,并将经过处理后得到的训练图结构数据,验证和测试的稀疏矩阵格式的数据进行缓存。
- builder.py:主要用来构建图结构数据,其中包括了构建节点的方法和添加边的方法。
- data_utils.py:实现了一些具体的切分训练集、验证集、测试集的方法。
数据集格式
知道数据是如何处理的,输入到模型中的数据是什么样的数据格式对于彻底掌握算法模型是很有必要的,下面主要介绍数据的处理,以及如何通过DGL创建图架构的数据。
MovieLens数据集主要包含三个文件:movies.dat,users.dat,ratings.dat
- movies.dat:

每行数据以“::”分隔,分别是:电影编号(movie_id)、电影名称(年份)(title(year))、电影题材(genre)
- users.dat:
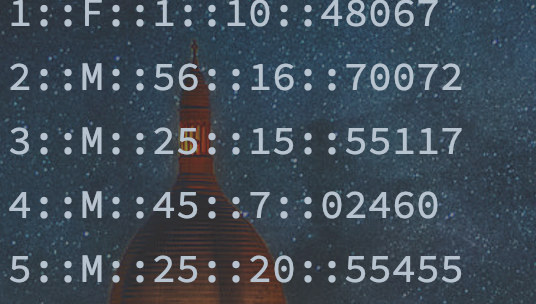
每行数据以“::”分隔,分别是:用户编号、性别、年龄、职业、"zip"(这个字段具体我没查过,感兴趣的同学可以查一下代表什么意思)
- ratings.dat:
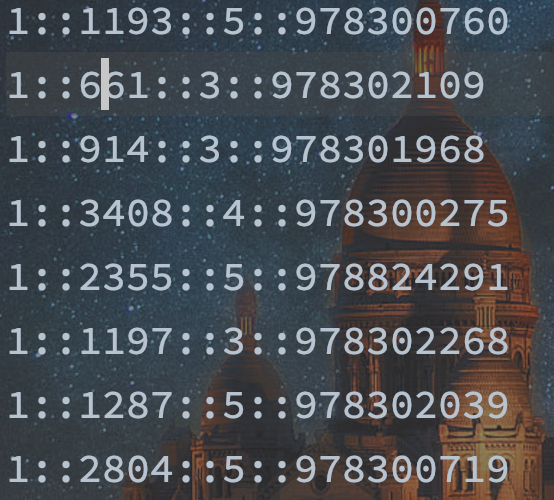
每行数据以“::”分隔,分别是:用户编号、电影编号、评分、评分时间戳
process_movielens1m.py代码详解
读取数据存储为DataFrame
读取movies.dat,users.dat,ratings.dat文件,将数据存储为对应的dataframe格式。
以下面这段代码为例:
with open(os.path.join(directory, "movies.dat"), encoding="latin1") as f:
for l in f:
id_, title, genres = l.strip().split("::")
genres_set = set(genres.split("|"))
# extract year
assert re.match(r".*\([0-9]{4}\)$", title)
year = title[-5:-1]
title = title[:-6].strip()
data = {"movie_id": int(id_), "title": title, "year": year}
'''
eg: {'movie_id': 1, 'title': 'Toy Story', 'year': '1995', "Children's": True,
'Comedy': True, 'Animation': True}
'''
for g in genres_set:
data[g] = True
movies.append(data)
movies = pd.DataFrame(movies).astype({"year": "category"})
可以看到读取movies.dat文件后,主要做的是就是按”::“将每行数据进行切割,同时使用正则表达式判断电影的标题是否符合格式,然后将数据存储为dataframe格式方便后续处理。
删除movies和users中没在ratings中出现过的数据
主要是下面这段代码:
# Filter the users and items that never appear in the rating table.
distinct_users_in_ratings = ratings["user_id"].unique()
distinct_movies_in_ratings = ratings["movie_id"].unique()
users = users[users["user_id"].isin(distinct_users_in_ratings)]
movies = movies[movies["movie_id"].isin(distinct_movies_in_ratings)]
ratings["user_id"].unique()会获得ratings中不重复的user_id,users中只保留这些user_id的相关信息。
创建用户——电影二部图
这个过程主要是通过builder.py这个文件完成的,这个文件中包括PandasGraphBuilder这个类,这个类实现了通过pandas数据结合DGL创建大图的方法。
首先看一下一个使用PandasGraphBuilder创建图的例子:
- 有一个users表:
=========== =========== =======
``user_id`` ``country`` ``age``
=========== =========== =======
XYZZY U.S. 25
FOO China 24
BAR China 23
=========== =========== =======- 有一个games表:
=========== ========= ============== ==================
``game_id`` ``title`` ``is_sandbox`` ``is_multiplayer``
=========== ========= ============== ==================
1 Minecraft True True
2 Tetris 99 False True
=========== ========= ============== ==================- user plays game的关系表:
=========== =========== =========
``user_id`` ``game_id`` ``hours`
=========== =========== =========
XYZZY 1 24
FOO 1 20
FOO 2 16
BAR 2 28
=========== =========== =========
通过PandasGraphBuilder创建user——game二部图,图中节点间关系为play的流程为:
builder = PandasGraphBuilder()
# 创建图中user节点
builder.add_entities(users, 'user_id', 'user')
#创建图中game节点
builder.add_entities(games, 'game_id', 'game')
# 创建'user——game'的关系为'plays'
builder.add_binary_relations(plays, 'user_id', 'game_id', 'plays')
# 创建'game——user'的关系为'palyed-by'
builder.add_binary_relations(plays, 'game_id', 'user_id', 'played-by')
# 调用build方法创建图
g = builder.build()
# 查看用户类型节点数量
g.num_nodes('user')
>>> 3
# 查看'plays'边的数量
g.num_edges('plays')
>>> 4PandasGraphBuilder类解析
这个类是DGL中pinsage这个example下定义的一个类,我目前暂时不清楚其他的example中是否有类似的类,但该类给我们提供了一个通过pandas数据使用DGL创建图的思路,所以可以略微对该类的结构进行一定的了解,熟悉后可以根据我们自己项目中的数据格式也创建类似的工具类实现图结构的定义:
该类主要包括_init_(self)、add_entities(self, entity_table, primary_key, name)、add_binary_relations( self, relation_table, source_key, destination_key, name)、build(self)四个方法,其中:
- _init_(self):该方法主要实现PandasGraphBuilder类的初始化
- add_entities(self, entity_table, primary_key, name):添加节点的方法
- add_binary_relations(self, relation_table, source_key, destination_key, name):添加关系的方法
- build(self):真正创建图的方法。
def build(self):
# Create heterograph
graph = dgl.heterograph(
# (节点,关系,节点)的字典,(节点的数量)
self.edges_per_relation, self.num_nodes_per_type)
return graph- 这个方法中调用的是DGL中创建异构图的方法:heterograph(data_dict,num_nodes_dict=None, idtype=None,device=None),其中参数:
- data_dict:异构图中节点与节点之间关系的字典,具体来说其键是一个三元组(源节点类型,关系类型,目标节点类型),值是一个二元组(torch.tensor,torch.tensor),第一个tensor为源节点id,第二个tensor为目标节点的id,下面举一个源码中官方给出的例子看一眼就懂了:
data_dict =
{('user', 'follows', 'user'): (torch.tensor([0, 1]), torch.tensor([1, 2])),
('user', 'follows', 'topic'): (torch.tensor([1, 1]), torch.tensor([1, 2])),
('user', 'plays', 'game'): (torch.tensor([0, 3]), torch.tensor([3, 4]))}
g = dgl.heterograph(data_dict)可以看到该例里要创建的图中节点有三类“user、topic、game”,关系有三类“user——follows——user”、“user——follows——topic”、“user——plays——game”,其中('user', 'follows', 'user'): (torch.tensor([0, 1]), torch.tensor([1, 2]))的意思是0号user follow 了1号user,1号user follow 了2号user,其余类似。
- idtype:节点类型及数量的字典,如:num_nodes_dict = {'user': 4, 'topic': 4, 'game': 6}
通过以上的举例和分析,其实在PandasGraphBuilder类中最核心的是得到了两个字典:
- self.edges_per_relation:相当于上例中的data_dict,里面具体的数据长这样:
{('user', 'watched', 'movie'): (array([ 0, 0, 0, ..., 6039, 6039, 6039]), array([1104, 639, 853, ..., 548, 1024, 1025])),
('movie', 'watched-by', 'user'): (array([1104, 639, 853, ..., 548, 1024, 1025]), array([ 0, 0, 0, ..., 6039, 6039, 6039]))}- self.num_nodes_per_type:相当于上例中的idtype,里面具体的数据:
{'user': 6040, 'movie': 3706}该类中有一些Pandas处理数据的方法,比如将数据格式转换成category类型的节省存储空间的方法:
src = relation_table[source_key].astype("category")这些处理数据的方式也值得我们学习,有兴趣的同学可以深入学习一下,本文不再赘述。
为创建出来的图中的节点和边赋值
这个主要是通过下面的代码:
# Assign features.
# Note that variable-sized features such as texts or images are handled elsewhere.
a = users["gender"]
b = users["gender"].cat.codes.values
g.nodes["user"].data["gender"] = torch.LongTensor(
# 将所有对象映射为类别数字
users["gender"].cat.codes.values
)
......
g.edges["watched-by"].data["rating"] = torch.LongTensor(
ratings["rating"].values
)
g.edges["watched-by"].data["timestamp"] = torch.LongTensor(
ratings["timestamp"].values
)
切分训练集、验证集、测试集
process_movielens1m.py中切分训练集、测试集、验证集的代码如下,其中有一个mask的技巧值得学习。
train_indices, val_indices, test_indices = train_test_split_by_time(
ratings, "timestamp", "user_id"
)
def train_test_split_by_time(df, timestamp, user):
df["train_mask"] = np.ones((len(df),), dtype=np.bool)
df["val_mask"] = np.zeros((len(df),), dtype=np.bool)
df["test_mask"] = np.zeros((len(df),), dtype=np.bool)
df = dd.from_pandas(df, npartitions=10)
def train_test_split(df):
df = df.sort_values([timestamp])
if df.shape[0] > 1:
df.iloc[-1, -3] = False
df.iloc[-1, -1] = True
if df.shape[0] > 2:
df.iloc[-2, -3] = False
df.iloc[-2, -2] = True
return df
df = (
df.groupby(user, group_keys=False)
.apply(train_test_split)
.compute(scheduler="processes")
.sort_index()
)
print(df[df[user] == df[user].unique()[0]].sort_values(timestamp))
return (
df["train_mask"].to_numpy().nonzero()[0],
df["val_mask"].to_numpy().nonzero()[0],
df["test_mask"].to_numpy().nonzero()[0],
)
切分数据集时的原则是用用户最后交互的数据作为测试,交互时间倒数第二(second-to-last)交互的数据作为验证,其余交互的数据作为训练。作者在注释里面说这样也符合“用过去的数据进行训练去预测未来”的直觉。
有意思的是作者在此处提出的切分数据集的方法:作者往原先的ratings数据集中新加入了三个列(train_mask,val_mask,test_mask),为train_mask赋值为1,val_mask这一列赋值为0,test_mask这一列赋值为0,通过调整1,0值的变化,实现数据集的划分。具体的过程可以通过下面我画的这张图来进行理解:

上面的代码一次返回处理后的数据集中train_mask,val_mask,test_mask不为0的行索引值,需要注意的是在创建这个二部图时ratings数据中每一行的索引编号和图中边的编号是一样的,因此通过train_mask获得的索引值“train_indices”可以对应到接下来的子图的获取中。
获取训练集所需要的子图
首先看DGL中抽取子图的方法:
def edge_subgraph(self, edges, relabel_nodes=True, store_ids=True):
Parameters
----------
edges : Int Tensor or dict[(str, str, str), Int Tensor]
The edges to form the subgraph. Each element is an edge ID. The tensor must have the same device type and ID data type as the graph's.
If the graph is homogeneous, one can directly pass an Int Tensor.Otherwise, the argument must be a dictionary with keys being edge types and values being the edge IDs in the above formats.
relabel_nodes : bool, optional
If True, it will remove the isolated nodes and relabel the incident nodes in the extracted subgraph.
store_ids : bool, optional
If True, it will store the raw IDs of the extracted edges in the ``edata`` of the resulting graph under name ``dgl.EID``; if ``relabel_nodes`` is ``True``, it will also store the raw IDs of the incident nodes in the ``ndata`` of the resulting graph under name ``dgl.NID``.
对于第一个参数edges,如过图是同质图,直接传边的ID就可以,对于异质图,需要传入的是字典类型,其中key是边的类型,值是边的ID。
关于第二个参数relabel_nodes,我个人的理解是当为True时它会对子图的中的节点重新进行编号(父图中的节点的编号依然会被保留,之后会举例子),而且会消除之前没有边进行相连的节点。这个地方给人感觉有点奇怪:不管relabel_nodes是True还是False不应该都是直接按边进行子图抽取吗,这样的话不应该都有消除孤立节点的作用吗?我写了个简单的demo对这个想法进行了测试,发现如果relabel=False的话,抽取出来的子图依然会含有原先父图中孤立的节点。看demo:
import dgl
g = dgl.heterograph({('user', 'plays', 'game'): ([1, 2, 3], [3, 4, 5])})
print("原图:\n",g)
>>>output:
# 可以看见此处因为我们user和game不是从0开始编号的,DGL创建图时帮我们多创建了几个节点user多了个0号节点,game多了个0,1,2号节点
Graph(num_nodes={'game': 6, 'user': 4},
num_edges={('user', 'plays', 'game'): 3},
metagraph=[('user', 'game', 'plays')])
# edge_subgraph默认relabel=True,store_ids=True
sub_g1 = g.edge_subgraph({'plays':(0,2)})
print("relabel_nodes = True 时的子图:\n",sub_g1)
print("查看子图是否对节点重新进行了编号:\n",sub_g1.nodes(ntype='game'))
print("查看子图是否对边重新进行了编号:\n",sub_g1.edges(form='all'))
print("查看子图是否保存了父图中节点信息:\n",sub_g1.ndata[dgl.NID])
print("查看子图是否保存了父图中边信息:\n",sub_g1.edata[dgl.EID])
>>>output:
relabel_nodes = True 时的子图:
Graph(num_nodes={'game': 2, 'user': 2},
num_edges={('user', 'plays', 'game'): 2},
metagraph=[('user', 'game', 'plays')])
查看子图是否对节点重新进行了编号:tensor([0, 1])
# 前两个张量表示端点号,最后一个张量为新边号
查看子图是否对边重新进行了编号:(tensor([0, 1]), tensor([0, 1]), tensor([0, 1]))
查看子图是否保存了父图中节点信息:{'game': tensor([3, 5]), 'user': tensor([1, 3])}
查看子图是否保存了父图中边信息:tensor([0, 2])
sub_g2 = g.edge_subgraph({'plays':(0,1)},relabel_nodes = False)
print("relabel_nodes = False 时的子图:\n",sub_g2)
print("查看子图是否对节点重新进行了编号:\n",sub_g2.nodes(ntype='game'))
print("查看子图是否对边重新进行了编号:\n",sub_g2.edges(form='all'))
print("查看子图是否保存了父图中节点信息:\n",sub_g2.ndata[dgl.NID])
>>>output:
Graph(num_nodes={'game': 6, 'user': 4},
num_edges={('user', 'plays', 'game'): 2},
metagraph=[('user', 'game', 'plays')])
查看子图是否重新进行了编号: tensor([0, 1, 2, 3, 4, 5])
查看子图是否对边重新进行了编号:(tensor([1, 3]), tensor([3, 5]), tensor([0, 1]))
查看子图是否保存了父图中节点信息:{}
查看子图是否保存了父图中边信息:KeyError: '_ID' ----->报错
可以看到:
- relabel_nodes=True时抽取出的子图不再含有父图中的孤立节点,False时子图中依然含有
- relabel_nodes=True时抽取出的子图中对应的game节点重新进行了编号(3,4重新编号为0,1),False时编号依然保留
- relabel_nodes=True时子图保存了父图中节点的编号,False时未保存父图中节点编号(所有的父图中的节点在子图中依然在,当然会保留,区别只是子图中边变少了)
- 不管relabel_nodes为True还是False,子图都会对边重新进行编号
- store_ids = False时,子图中不保存附图中边的信息
Pinsage的训练子图抽取
train_g = build_train_graph(
g, train_indices, "user", "movie", "watched", "watched-by"
)
def build_train_graph(g, train_indices, utype, itype, etype, etype_rev):
train_g = g.edge_subgraph(
{etype: train_indices, etype_rev: train_indices}, relabel_nodes=False
)
# copy features
# 为子图中的节点赋值
for ntype in g.ntypes:
for col, data in g.nodes[ntype].data.items():
train_g.nodes[ntype].data[col] = data
# 为子图中的边赋值
for etype in g.etypes:
for col, data in g.edges[etype].data.items():
train_g.edges[etype].data[col] = data[
train_g.edges[etype].data[dgl.EID]
]
return train_g
在此处构建子图时,二部图边有两种类型,users--watched--movies,movies--watched-by--users。这两种边的类型作为key,值为train_indices。
此处可以看到作者为了保证子图中的节点信息和编信息和父图中的一致,重新对子图中节点的信息做了一次赋值的操作,虽然我在写demo验证的时候,发现不做重新赋值的操作,子图中的信息依然和父图中的保持一致,但是通过网上查阅资料,有说法是抽取子图后可能信息会有不一致的情况,保险起见还是再次进行重新赋值。直接使用==train_g.nodes[ntype].data[col] = data==的原因就是因为relabel_nodes=False时,子图中节点的数量和父图中的一致。
训练集需要构建训练子图,测试集和验证构建一个用户——电影交互的稀疏矩阵就可以。
scipy中coo_matrix的一些用法
coo_matrix是构建稀疏矩阵进行存储的一种高效的方式:
coo_matrix((data, (row, col)), shape=(4, 4)).toarray()
- shape表示稀疏矩阵的形状
- (row,col)表示的是稀疏矩阵中有值的行列的索引值
- data表示对应行列索引下的值时多少
举个例子:
# Constructing a matrix using ijv format
row = np.array([0, 3, 1, 0])
col = np.array([0, 3, 1, 2])
data = np.array([4, 5, 7, 9])
coo_matrix((data, (row, col)), shape=(4, 4)).toarray()
output:
array([[4, 0, 9, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]])
构建训练与验证需要的稀疏矩阵
# Build the user-item sparse matrix for validation and test set.
val_matrix, test_matrix = build_val_test_matrix(
g, val_indices, test_indices, "user", "movie", "watched"
)
def build_val_test_matrix(g, val_indices, test_indices, utype, itype, etype):
n_users = g.num_nodes(utype)
n_items = g.num_nodes(itype)
# 根据边的编号,返回边两端的源节点ID和目标节点ID
val_src, val_dst = g.find_edges(val_indices, etype=etype)
test_src, test_dst = g.find_edges(test_indices, etype=etype)
val_src = val_src.numpy()
val_dst = val_dst.numpy()
test_src = test_src.numpy()
test_dst = test_dst.numpy()
# 生成稀疏矩阵,用户行,物品列,有评分的地方为1
val_matrix = ssp.coo_matrix(
(np.ones_like(val_src), (val_src, val_dst)), (n_users, n_items)
)
# tmp_a = val_matrix.toarray()
test_matrix = ssp.coo_matrix(
(np.ones_like(test_src), (test_src, test_dst)), (n_users, n_items)
)
return val_matrix, test_matrix
其中的g.find_edges(val_indices, etype=etype) 方法是DGL中根据传入边的id返回该边源节点和目标节点的方法。比如:
import dgl
import torch
# 创建个同质图
g = dgl.graph((torch.tensor([0, 0, 1, 1]), torch.tensor([4, 0, 2, 3])))
# 找到边编号为0,2的两条边的源节点和目标节点
g.find_edges(torch.tensor([0, 2]))
output:
(tensor([0, 1]), tensor([4, 2])) # 返回值两个张量,前一个表示源节点,后一个表示目标节点
最后将训练图和验证矩阵、测试矩阵进行缓存。
dgl.save_graphs(os.path.join(out_directory, "train_g.bin"), train_g)
dataset = {
"val-matrix": val_matrix,
"test-matrix": test_matrix,
"item-texts": movie_textual_dataset,
"item-images": None,
"user-type": "user",
"item-type": "movie",
"user-to-item-type": "watched",
"item-to-user-type": "watched-by",
"timestamp-edge-column": "timestamp",
}
with open(os.path.join(out_directory, "data.pkl"), "wb") as f:
pickle.dump(dataset, f)
关于作者:本人目前研二在读,研究方向是推荐系统,对AI领域热门技术有所追求。
想关注后续模型结构分析及具体训练过程的同学可以关注一波我的微信公众号:Dixin_TecStation,或扫下面的二维码进行关注,后续更新会第一时间更新到微信公众号,这上面也会更新但可能会有延迟。
鉴于本人水平有限,内容如有错讹,敬请指正,欢迎大家关注公众号交流 。
















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









