







目录
这一部分是PinSAGE算法中比较重要的一块,我准备通过以下两部分内容进行分析介绍:
- 正负样本采样
- PinSAGE采样
采样
不管是什么样的神经网络模型,正样本和负样本的选取对模型训练的好坏起着至关重要的作用,下面将详细介绍DGL对PinSAGE实现的这个example中是如何选取正负样本的。
正负样本采样
在上篇文章“在工业界落地的PinSAGE图卷积算法原理及源码学习(一)数据处理及图的定义”中我们已经得到了训练图和验证、测试矩阵。对于图模型来说模型训练还需要合理地设置正样本和负样本,在DGL该部分是通过随机游走的采样算法来进行实现的,采样之后得到了正样本对和负样本对。要注意区别此处的随机游走采样算法和之后的PinSAGE游走采样算法的原理是不一样的,用处也是不一样的。具体随机游走算法的原理可以参考这篇文章^[1]^,本系列的文章就不着重去讲算法的原理了,对一些技术我们知道它大概是怎么一回事,我们怎么在实际中能用起来就可以了,当然我也鼓励大家有时间了去深究其背后的数学原理,能弄懂当然是好事了,还是那句话,在实践中学习。
DGL已经帮我们实现好了Random Walk Sampling算法,具体来说,首先在DGL对PinSAGE实现的example中,model.py这个文件定义了PinSAGE这个模型的主要框架及训练和测试验证的方法,在该文件中:
def train(dataset, args):
g = dataset["train-graph"]
item_texts = dataset["item-texts"]
user_ntype = dataset["user-type"]
item_ntype = dataset["item-type"]train方法中传入了之前process_movielens1m.py中最后得到的dataset,并获取到其中的训练图train-graph,user_ntype和item_ntype,之后将这些值传入sampler.py文件中的ItemToItemBatchSampler这个类中:
batch_sampler = sampler_module.ItemToItemBatchSampler(
g, user_ntype, item_ntype, args.batch_size
)注意这个类继承了torch.utils.data下的IterableDataset这个类,这个类专门用来处理一次性加载时无法全部加载到内存的数据,继承这个类需要覆写__iter__这个方法,将来构建出dataloader之后,每执行一次next(datalader)将会生成一个新的batch的数据。
接下来我们来分析ItemToItemBatchSampler这个类的定义,及通过其中的方法如何获得训练所需要的正负样本节点:
class ItemToItemBatchSampler(IterableDataset):
def __init__(self, g, user_type, item_type, batch_size):
self.g = g
self.user_type = user_type
self.item_type = item_type
# 获取'user_type'到'item_type'节点关系类型为'watched'
self.user_to_item_etype = list(g.metagraph()[user_type][item_type])[0]
# 获取'item_type'到'user_type'节点关系类型为'watched-by
self.item_to_user_etype = list(g.metagraph()[item_type][user_type])[0]
self.batch_size = batch_size
def __iter__(self):
while True:
heads = torch.randint(
0, self.g.num_nodes(self.item_type), (self.batch_size,)
)
tails = dgl.sampling.random_walk(
self.g,
heads,
# 这个地方原码注释中给的较为抽象,metapath跟随机游走的长度length这两个参数是互斥的,只能使用一个。当指定了metapath时,随机游走就会按照metapath这个数组中边的顺序进行游走,可以通过metapath*num控制,按照metapath这个顺序执行几次。这地方得到的[batch_size,3],通过[0][:, 2]得到随机游走终点的item的id
metapath=[self.item_to_user_etype, self.user_to_item_etype],
)[0][:, 2]
neg_tails = torch.randint(
0, self.g.num_nodes(self.item_type), (self.batch_size,)
)
mask = tails != -1
yield heads[mask], tails[mask], neg_tails[mask]__iter__(self)这个方法中实现了随机游走采样正负样本的方法,要注意PinSAGE是一个ItemToItem的模型,这个模型认为被用户交互过的item具有相似性,它们属于正样本。未被同一用户交互过的item相互属于负样本。
- 首先通过 torch.randint方法随机的在训练图中选取batch_size个节点作为头结点heads
- 再通过dgl.sampling.random_walk方法进行item节点的随机游走采样,该方法的metapath参数是随机游走的元路径,定义了随机游走时该沿着什么样的路径进行游走。例如首先从item1开始沿着元路径“watched by——watched”游走,item1首先会沿着watched by类型的边游走到user3(这个地方是举例子,也可能是user1或者user4),再沿着watched类型的边游走到item4,此时item1和item4 都是user3交互过的item,所以认为它们存在一定的相似性,item1和item4即是正样本对。随机游走的长度可以通过
[self.item_to_user_etype, self.user_to_item_etype]*num来确定,其它需要注意的地方我已经写到上述代码里的注释中了。要注意通过dgl.sampling.random_walk方法会得到从起点到终点随机游走过程中所有经过的点,所以需要通过切片[:,2]来得到随机游走终点的id,最后tails即为heads对应的正样本 - 相较于正样本对的构造,负样本的构造就简单多了,直接从图中随机出来一批item节点,这个操作存在的问题是可能会将上边得到的某些正样本节点也可能会包括进去,所以在做具体业务时,该部分存在优化的空间
PinSAGE采样的原理及代码实现
PinSAGE采样原理
PinSAGE采样是重要性采样,其基于随机游走采样过程中节点出现的频率来构建子图,如下图:
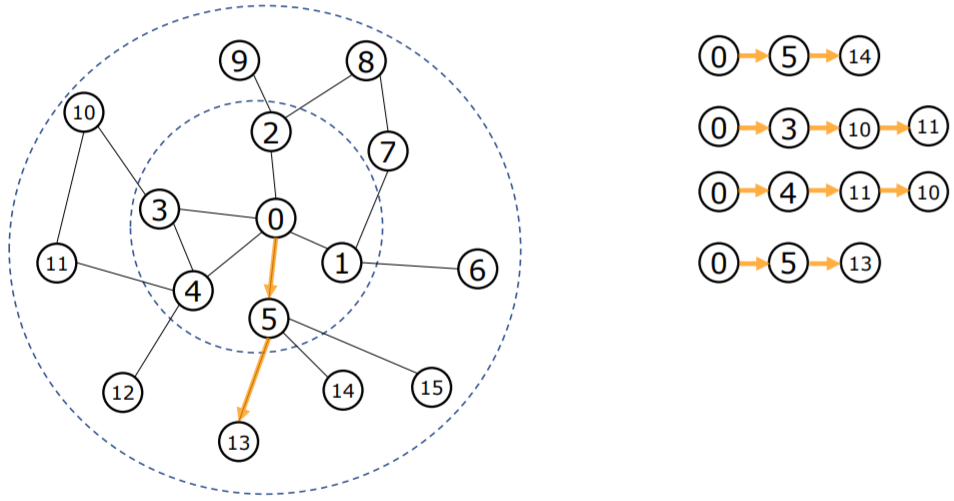
从节点0开始游走四次,第一次游走经过的节点为0——>5——>14,第二次游走经过的节点是0——>3——>10——>11,......,可以看到其中5、10、11、三个节点出现的频率最高,将这三个节点与0号节点相连作为0号节点的虚拟邻居:

以上就是通过PinSAGE随机游走算法构建训练子图的基本原理。要想详细了解该过程以及其与GraphSAGE采样算法的区别的话可以参考这篇文章[2]。
PinSAGE采样实现
DGL中对PinSAGE的实现如下:
- 首先定义NeighborSampler
neighbor_sampler = sampler_module.NeighborSampler(
# 训练图
g,
user_ntype,
item_ntype,
# 2
args.random_walk_length,
# 0.5
args.random_walk_restart_prob,
# 10
args.num_random_walks,
# 3
args.num_neighbors,
# 2
args.num_layers,
)在NeighborSampler的__init__方法中定义了PinSAGESampler器,PinSAGESampler的个数与卷积的层数一致。
self.samplers = [
dgl.sampling.PinSAGESampler(
g,
item_type,
user_type,
# 每次随机游走时游走的长度,每次游走的长度=元路径*基于元路径的次数
random_walk_length,
random_walk_restart_prob,
# 从头节点出发随机游走的次数
num_random_walks,
# 最后游走完得到的邻居节点个数
num_neighbors,
)
for _ in range(num_layers)
]dgl.sampling.PinSAGESampler是DGL中已经实现的PinSAGE采样算法,创建该采样器时各个参数的含义我已在上边代码中添加了对应的注释。对于其中的一部分参数,有必要再展开阐述一下:
- 首先根据DGL中PinSAGESampler源码里的注释:
This callable works on a bidirectional bipartite graph with edge types(ntype, fwtype, other_type)and(other_type, bwtype, ntype)(wherentype,fwtype,bwtypeandother_typecould be arbitrary type names). It will generate a homogeneous graph of node typentypewhere the neighbors of each given node are the most commonly visited nodes of the same type by multiple random walks starting from that given node. Each random walk consists of multiple metapath-based traversals, with a probability of termination after each traversal. The metapath is always[fwtype, bwtype],walking from node typentypeto node typeother_typethen back tontype.
通过这段话我们可以得出以下几个信息:- PinSAGESampler采样必须使用在双向二部图中,即这个图是二部图,边必须得是双向边。在这个example中我们输入的图是符合这个要求的
- 采样到的邻居节点是与给定的初始节点相同类型的节点
- 元路径metapath是
[fwtype, bwtype]即先是一种类型的边,再是相反类型的边。在本例中元路径就是“watched by ——> watched”,这样正好就能从movie节点到user节点再到movie节点。
具体的PinSAGE采样过程是在NeighborSampler中的sample_blocks方法和sample_from_item_pairs方法中实现的。
先看sample_from_item_pairs方法:
def sample_from_item_pairs(self, heads, tails, neg_tails):
# Create a graph with positive connections only and another graph with negative
# connections only.
pos_graph = dgl.graph(
(heads, tails), num_nodes=self.g.num_nodes(self.item_type)
)
neg_graph = dgl.graph(
(heads, neg_tails), num_nodes=self.g.num_nodes(self.item_type)
)
pos_graph, neg_graph = dgl.compact_graphs([pos_graph, neg_graph])
seeds = pos_graph.ndata[dgl.NID]
blocks = self.sample_blocks(seeds, heads, tails, neg_tails)
return pos_graph, neg_graph, blocks可以看到在该方法中首先根据之前采样的正样本节点和负样本节点构建了正负样本子图 pos_graph和neg_graph,此时正负样本子图中存在很多孤立节点,因为这两个子图在创建时指定了num_nodes=self.g.num_nodes(self.item_type),因此创建出来的子图包含了训练图中的所有节点,而只有heads和tails或者neg_tails之间是有边的,因此又通过dgl.compact_graphs对这两个图进行了压缩,消除了这两个图中没有边的孤立节点。此处需要注意的是:
- 经过dgl.compact_graphs对两个图进行压缩后,两个图中的存在的节点都是一样的,只是边不一样了而已。
接下来sample_from_item_pairs方法调用了sample_blocks方法,将pos_graph中的所有节点作为起始节点去在训练图中进行PinSAGE采样,我们通过前面的内容知道训练图包含了pos_graph和neg_graph中的所有节点。具体代码如下:
def sample_blocks(self, seeds, heads=None, tails=None, neg_tails=None):
blocks = []
for sampler in self.samplers:
frontier = sampler(seeds)
if heads is not None:
eids = frontier.edge_ids(
torch.cat([heads, heads]),
torch.cat([tails, neg_tails]),
return_uv=True,
)[2]
if len(eids) > 0:
old_frontier = frontier
frontier = dgl.remove_edges(old_frontier, eids)
block = compact_and_copy(frontier, seeds)
seeds = block.srcdata[dgl.NID]
blocks.insert(0, block)
return blocks首先以pos_graph中的节点为起始点(seeds)进行采样,得到图frontier,此处需要注意以下几点:
- 通过PinSAGE采样会返回一个包含seeds及其采样得到的邻居节点的子图即代码中的frontier,这个子图的边上会有个特征
weights,这个weights源码的注释里是这么解释的:The name of the edge feature to be stored on the returned graph with the number of visits. 即weights为随机游走时,对应的邻居节点出现的次数。 - 采样得到的frontier可能包含pos_graph和neg_graph中的某些边,将来训练时我们是通过frontier来进行节点的信息传递、更新、聚合,如果提前有这些边存在的话,可能会在训练中导致信息泄露的问题,所以为了增强模型的鲁棒性和泛化性,做了一个将frontier中存在的与pos_graph和neg_graph相同的边剔除的操作。
DGL中的block
鉴于在大图中邻居采样后消息传递时,消息传递只与采样后的节点有关。所以为了避免直接在全图上进行消息传递产生过大的开销,DGL将消息传递时有依赖关系的节点变成一个小的二分图。DGL将这种仅包含必要输入节点和输出节点的二分图称为一个块(block)[3]。
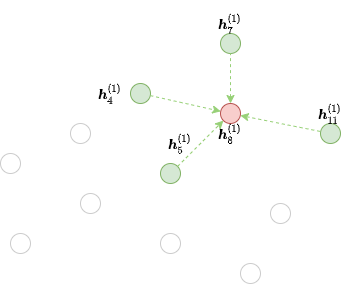
例如该图中我们以节点8为起始点采样了4、5、7、11四个节点,那8、4、5、7、11将构成一个block:
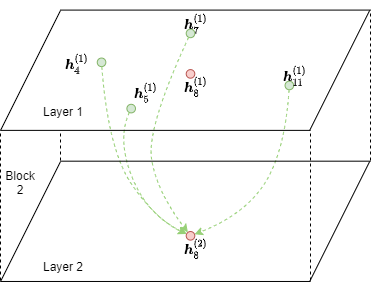
生成block的方法为:
output_nodes = torch.LongTensor([8])
# frontier为包含8、4、5、7、11的子图,output_nodes为4、5、7、11要传递消息的目标节点8
block = dgl.to_block(frontier, output_nodes)要注意block的输入节点中也会包含输出节点8,只不过8在这个block中不参与消息的传递。可以看一下面的代码:
# 获取block中全部输入节点
input_nodes = block.srcdata[dgl.NID]
# 获取block中全部输出节点
output_nodes = block.dstdata[dgl.NID]
# 断言从输入节点中得到的前输出节点个数的节点是否与输出节点相同,答案是相同的
assert torch.equal(input_nodes[:len(output_nodes)], output_nodes)了解完DGL中block的概念之后,我们继续分析sample_blocks这个方法,在为防止信息泄露消除了frontier中可能存在的正负样本图里的面边后,执行了:block = compact_and_copy(frontier, seeds)这个过程,我们来看compact_and_copy这个方法的具体实现:
def compact_and_copy(frontier, seeds):
# 转成block可以理解为转成了一个二部图,之前的frontier是同质图
block = dgl.to_block(frontier, seeds)
for col, data in frontier.edata.items():
if col == dgl.EID:
continue
block.edata[col] = data[block.edata[dgl.EID]]
return block我们看到与之前介绍block的概念相似,其中frontier即为包含了seeds和以seeds为初始节点进行PinSAGE采样的子图,此时frontier中采样的seeds的邻居节点为block中的输入节点,seeds为输出节点。
- 首先通过
dgl.to_block(frontier, seeds)生成了我们进行消息传递时所需要的block - 接着我们将frontier中边的信息往block中的边上对应地进行了赋值,其中最主要的是边上的weights信息,进行这个操作的目的在我看来是为了之后利用block进行消息的传递和更新时,会利用到weights信息,确保不同的节点会对目标节点进行不同程度的影响。
生成第一个block之后,因为卷积层数是两层,还需要一个block,这时将第一个block的的输入节点作为新的seeds再次进行采样,再生成一个block,并且将后面生成的这个block放到第一个block之前。有点绕,还是画个图展示一下吧:
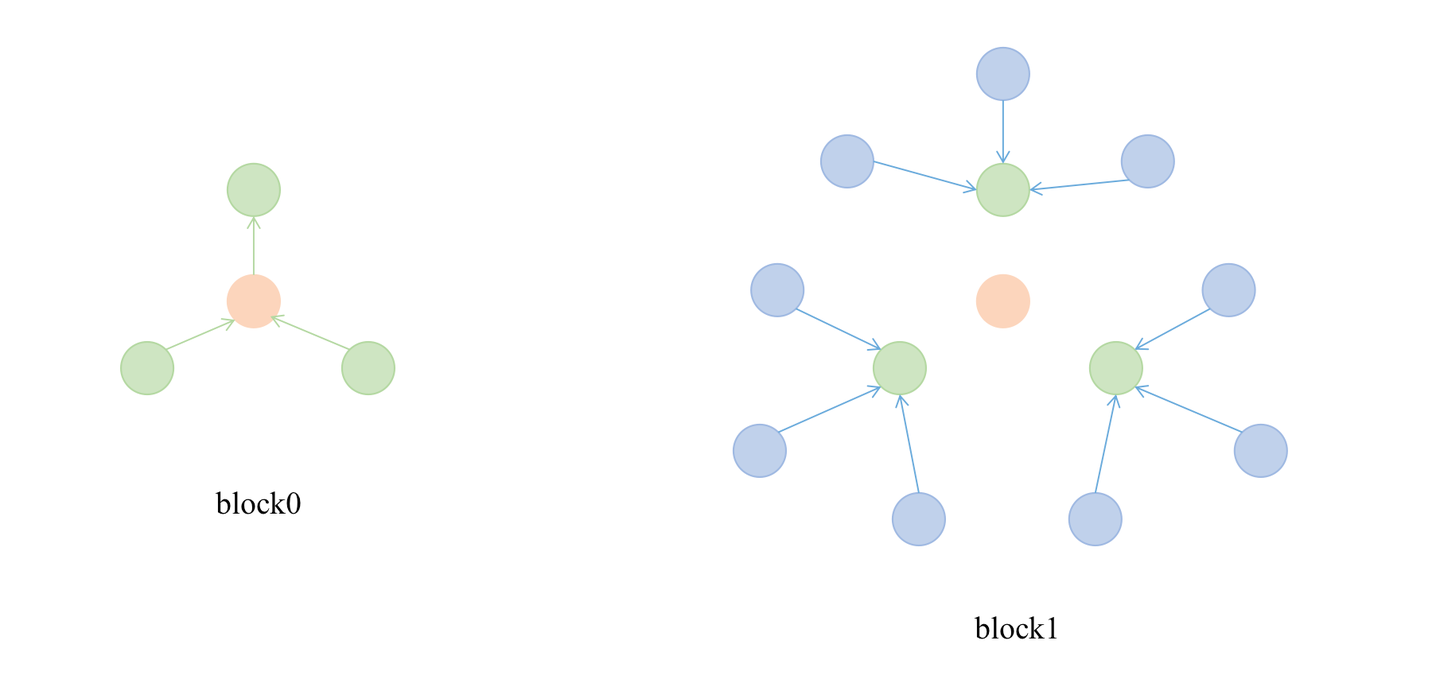
两次采样完成后,会将这两个block存入到blocks这个数组中,但block1会插入到block0前面,这是因为我们的卷积层数是两层,第一次卷积时是将block1中蓝色的节点信息聚合到绿色的节点上,第二次卷积时是将绿色的节点信息聚合到橙色的节点上。橙色节点是两层卷积后的最终输出节点。
通过以上的分析我们可以看到在NeighborSampler这个类中,卷积层数num_layers决定了采样器PinSAGESampler的个数也决定了将来要在其中进行节点消息传递、更新、聚合的block的个数。
以一张图来进行总结这以上所有内容其中的逻辑:
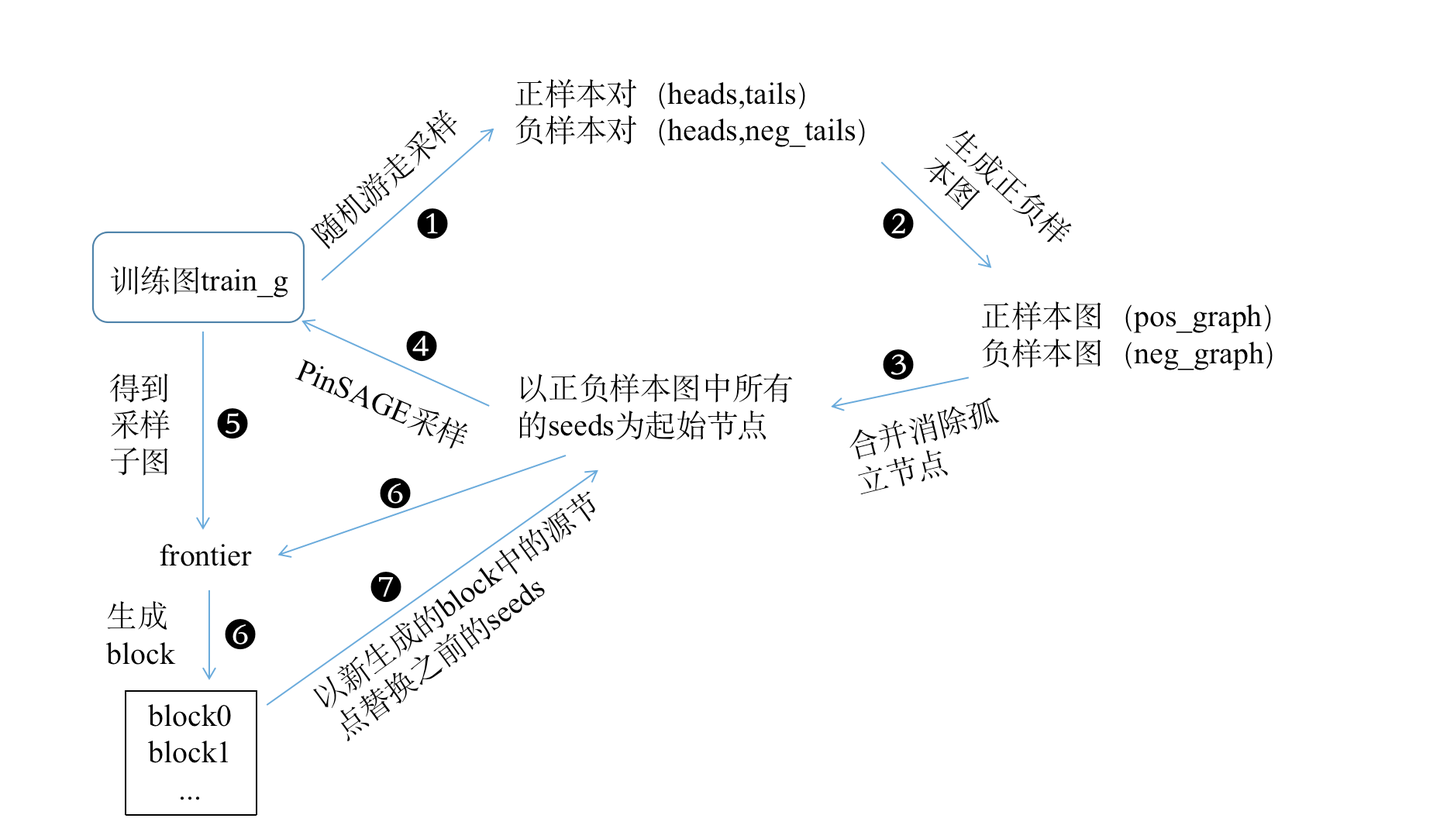
以上就是通过采样构建正负样本,以及形成将来卷积所需要的block数据结构的整体过程,下一篇讲具体的模型定义。
参考
[1] 图上随机游走算法II: frustrated random walks - 未到江南先一笑的文章 - 知乎 图上随机游走算法II: frustrated random walks - 知乎
[2] https://wmathor.com/index.php/archives/1533/
[3] https://docs.dgl.ai/guide_cn/minibatch-custom-sampler.html
关于作者:本人目前研二在读,研究方向是推荐系统,对AI领域热门技术有所追求。
想关注后续模型结构分析及具体训练过程的同学可以关注一波我的微信公众号:琛锡的算法笔记。
鉴于本人水平有限,内容如有错讹,敬请指正,欢迎大家关注公众号交流 。
















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









