







Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images(CVPR2015)
本文主要介绍深度神经网络的另一个缺陷:会将人类无法识别的图案以非常高的置信度归为某个label。当经过retrain的DNNs学会将负面例子分类为fool image时,即使经过多次再训练迭代,也可以产生一批新的fool image来愚弄这些新网络。

作者发现,尽管人类无法识别产生的图片是什么,但是如果通过DNNs给出的结果,可以发现,这些图片确实存在一些目标的特征。就比如下面的remote control就有类似的按钮。 作者认为这是因为算法只需要生成独特的特征或者有辨识度的特征而不需要整体的完整性特征就可以通过DNNs进行分类,也就是现有网络(文中实验网络为AlexNet)所存在的缺陷。

作者认为现有网络似乎在学习重复的特征:因为移出一部分重复的图案后置信度会下降。

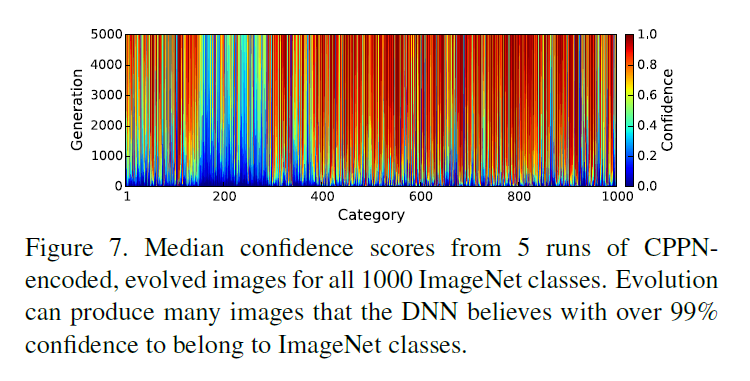
作者对于下图的现象给出了2种解释(class number 157-286是狗和猫类的图片):
- 对于猫狗大类下的子类(这两个大类下子类很多),网络在训练时会调整参数使得对不同类别的狗和猫达到准确的识别效果,从而更加难以overfitting。
- 某一类别下的子类别越多,就越难生成对抗样本
因为从图中可以看出,在157-286这个区间内,通过算法生成的对抗样本即使在迭代多次后也无法达到很高的置信度。
由于这些笔记是之前整理的,所以可能会参考其他博文的见解,如果引用了您的文章的内容请告知我,我将把引用出处加上~
如果觉得我有地方讲的不好的或者有错误的欢迎给我留言,谢谢大家阅读(点个赞我可是会很开心的哦)~















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









