








论文原文:Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images (提取码:fnrb)
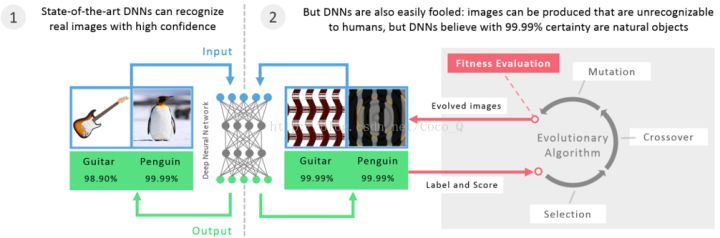
简单概括下这篇文章标题要表达的意思:深度神经网络很容易受到欺骗:无法识别图像的高置信度预测
无法识别图像的高置信度预测就是指深度神经网络无法区分置信度很高的错误分类图片,通俗的讲就是人肉眼无法识别的图像
但是对于机器却能以很高的置信度将图片错误分类。
本文主要介绍深度神经网络的另一个缺陷:会将人类无法识别的图案以非常高的置信度归为某个label。当经过重新训练的DNNs学会将负面例子分类为fool image时,即使经过多次再训练迭代,也可以产生一批新的fool image来愚弄这些新网络。
【摘要】
深度神经网络(DNN)最近在各种模式识别任务(尤其是视觉分类问题)上获得最先进的性能。鉴于DNN现在能够以接近人类水平的性能对图像中的对象进行分类,自然会产生关于计算机与人类视觉之间仍然存在哪些差异的问题。最近的一项研究显示,以人类无法感知的方式更改图像(例如狮子)会导致DNN将图像完全标记为其他图像(例如将狮子错误地标记为库)。在这里,我们展示了一个相关的结果:简单生成人类完全无法识别的图像,但是最新的DNN是具有99.99%置信度的将对象识别(例如,可以肯定地标记出白噪声静态是狮子)。具体来说,我们采用经过训练可在ImageNet或MNIST数据集上表现良好的卷积神经网络,然后使用进化算法或梯度上升来匹配图像,DNN将该梯度算法高度可信地标记为每个数据集类别。有可能产生完全无法被人眼识别的图像,而DNN几乎可以肯定地认为它们是熟悉的物体,我们称其为“愚弄图像”(更普遍地说,是愚弄样本)。我们的结果揭示了人类视觉与当前DNN之间的有趣差异,并提出了问题。
1.介绍
之前的相关文章提出对图片添加人眼无法识别的扰动却可以让DNN分类错误。而本文提出了另一种方法,即:生成一张人类无法分辨的图片,却能够让DNN以99%的置信度相信这是某个物体 。我们使用进化算法或者梯度上升来得到这样的图片。同时,作者也发现,对于使用MNIST训练集训练的DNN来说,使用对抗样本进行finetune也不能让DNN拥有良好的防御能力,即使重新训练的DNN分类出一部分对抗样本后,我们仍然可以重新生成一批这个重新训练的DNN无法防御的对抗样本。我们的发现,阐明了在人类视觉系统与计算机视觉系统的不同,同时引出了DNN的泛化性的问题。
2.方法
2.1 深度神经网络方法
作者认为,小的架构和优化方式的不同不会影响我们的结果,因此,作者选用了AlexNet作为实验模型,为了说明,我们的结果在其他的深度模型和数据上的结果,我们也使用了在MNIST上训练的LeNet。
2.2 使用进化算法生成图片
进化算法(evolutionary algorithms)是达尔文进化论启发下的优化算法。它们包含一个“有机体”(这里是图像)群体,这些有机体交替进行面部选择(保持最佳状态),然后进行随机排列(变异和/或交叉)。选择哪种有机体取决于拟合函数,在实验中,拟合函数是DNN对属于某一类的图像所作的最高预测值。如图所示:
传统的进化算法只能够针对一个目标或者是一小部分目标,比如,优化图像去匹配ImageNet的一个类。在这里,我们使用了一个新的算法,叫做:multi-dimensional archive of phenotypic elites MAP-Elites ,这个算法可以让我们同时的进化出一个群体,如:ImageNet的1000个类。
MAP-Elites的工作方式:在每一轮迭代中,随机选择一个样本并且对其进行随机的改变。如果这个样本有更高的适应性就替换掉当前这个objective的最优样本。适应性是由判别器DNN决定的:如果DNN对于这个图片给出了在任意分类下的更高的分数,就说明这个新生成的样本有更高的适应性。
论文提出用结合两种不同编码形式的EA算法(进化算法)去生成图像,来弄明白图片是如何跟基因组一样来进行操作的。
直接编码(direct encoding): 比如对于MNIST数据,生成的图像大小为28 × 28 pixels,并且每个像素上有一个灰度值;对于ImageNet数据,生成的图像大小为256 × 256 pixels,对于每个像素都有三个值(H,S,V值)。直接编码是在最初对每个pixel都随机初始化一个值,之后在原始图片上颜色空间中以一定概率随机变异,生成类似噪声的图.
间接编码(indirect encoding):使用CPPN来生成一些存在固定模式、套路的图片,其中每个CPPN中的node可以使用不同的激活函数,不同激活函数可以使得生成的图片包含不同的模式。此外CPPN也可以生成一些人类可以识别出的样本。(CPPN:合成模式生成网络:compositional pattern-producing network,它可以演化复杂的、规则的图像,重新组合自然和人造物体)
如下:

文章的一些内容翻译:
这些图片是在PicBreeder.org网站上制作的,在这个网站上,用户通过选择自己喜欢的图片作为进化算法中的适应度函数,这些图片成为下一代的父母。
CPPN类似于人工神经网络(artificial neural networks (ANNs))。CPPN接收像素的(x,y)位置作为输入,并输出该像素的灰度值(MNIST)或HSV颜色值元组(ImageNet)。与神经网络一样,CPPN计算的功能取决于CPPN中的神经元数量、它们之间的连接方式以及神经元之间的权重。每个CPPN节点可以是一组激活函数中的一个(这里是正弦、sigmoid、高斯和线性),这些激活函数可以为图像提供几何规则性。例如,将x输入传递给高斯函数将提供左右对称性,将y输入传递给正弦函数将提供上下重复。进化决定了种群中每个CPPN网络的拓扑结构、权值和激活函数。
CPPN网络在刚开始的时候,是没有隐藏节点的,隐藏节点会随着时间来加进来,这让进化算法可以在变得复杂之前,能够找到简单的规则的图像。
实验是在Sferes进化计算框架上完成的。
3.结果
3.1 进化出不规则的图片来匹配MNIST
说明:这里的规则与不规则是上一节所指的直接与间接的编码,由于CPPN会为图像提供几何的规则性(对称等),所以称之为规则的,而直接编码没有几何性质,所以称为不规则的。还有一个区别是,CPPN可以进化出能够识别的图片,如上图。而直接编码进化出来的图片,无法识别。

我们直接对编码图片进行进化,来让LeNet将其分类为0~9之间(MNIST)。多次独立的进化过程反复产生的图像,让DNN能够有99%的置信度,但让人类无法识别。
3.2 进化出规则的图片来匹配MNIST
因为CPPN编码能够生成让人能够识别的图片,所以我们来测试,是否这种规则会给我们带来更好的结果。其生成的图片如下:

经过一小轮的迭代,有图片能够置信度达到99.99%,经过200轮的迭代后,DNN的置信度已经平均有99.99%。 由图片我们可以看到,被分类为1的图片,会有竖直的线,被分类为2的图片,在底部会有水平的线。结果表明,EA利用了DNN所学习的特征来生成的图片。
为了作对比,我们可以在这里总结下这两者的区别:

左侧Fig.4是直接编码生成的看起来像白噪声的图,DNN依然可以得到99.99%这样的成绩。
右侧Fig.5间接编码生成的图片尽管出现了一些固定模式,但是和我们通常认知的数字依然相去甚远。并且这些图片存在一些规律:比如识别数字1的图片,通常包含许多垂直条纹,而数字2的图片则在图片下方有水平粗线,可以认为DNN主要是依据这些特征来识别数字的并且EA算法发现了这一点。
3.3 进化出不规则的图片来匹配ImageNet
我们对大数据集进行了测试。发现,结果并不成功,哪怕20000次迭代后,也没有为很多类生成高置信度的图片,平均置信度21.59%。当然也有一些成功的,进化算法为45个类生成了置信度超过99%的图片。在各类上的置信度如下:

3.4 进化出规则的图片来匹配ImageNet
这次使用CPPN来进化图片。在五次独立的迭代后,CPPN生成了许多置信度大于99.99%的图片,但是无法被人识别。在经过5000轮迭代后,平均置信度达到了88.11%。

同样在这里对比下规则与不规则在ImageNet上的区别
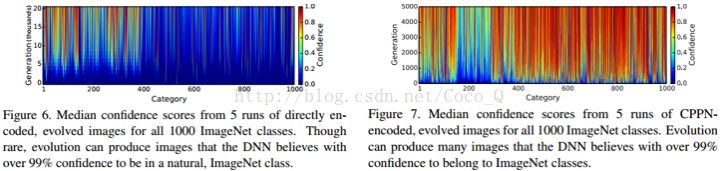
左侧Fig.6是直接编码的结果,成功率很低(中位数为21.59%)不过在其中的45类图片上依然得到了超过99%的结果。
右侧Fig.7是使用间接编码CPPN的结果,多数类上都可以达到超过99%的结果,中位识别置信度达到了88.11%。
此外,在ImageNet的工作上,还有几点值得注意:
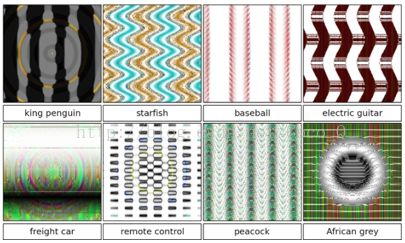
1.比如下图中海星的图片包含蓝色的海洋和橙色的生物组织,垒球的图片有红色线条和白色背景,遥控器的图片有按钮的网格图样...所以大致可以理解为DNN依靠这类特征对图像进行分类。而EA算法只需要生成某一类独特的或者有辨识度的feature,而不是这个类所有的features。
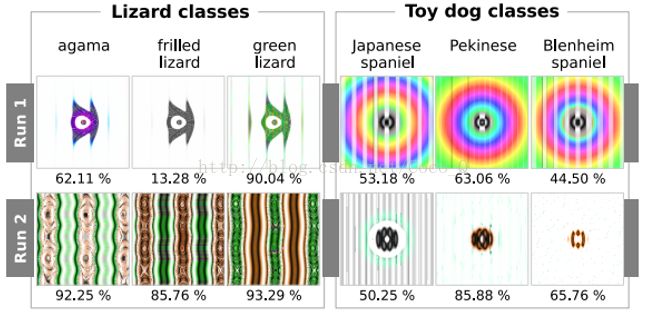
2.下图中,对于同一个大类生成的子类图片很相似。并且对于不同的生成轮次,对于同一类别生成的图片类型不同,这是因为不同的生成算法探索出了不同的具有辨识度的features。所以对于同一个DNN的每个类别有很多不同的干扰方式。
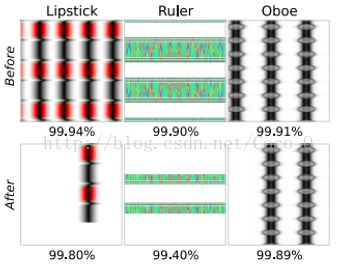
3.对于很多图片,去除额外的重复的部分导致了最后结果置信度的下降。这个结果表明DNN倾向于去学习低层和中层特征,而不是学习对象的全局结构:
文章后面还提到了:在这些生成的图片中,对猫和狗的攻击的表现比较差,作者说明了两个可能的解释:1、数据集中的猫和狗的图片更多一些,也就意味着,它过拟合程度更低,也意味着其更难去欺骗,这个方面说明,数据集越大,网络越难被攻击。2、另一个可能的解释是因为ImageNet有太多猫和狗的类了,EA对每一个类很难找到最有代表性的图片(在该类置信度高,在别的类置信度低),而这对于以softmax为分类器的DNN来说是很重要的,这个方面说明,数据集的类别越多,越难被攻击。
3.5进化得到的图像具有泛化性
之前,我们用EA得到了DNN对某一类的特征,那么是否所有的DNN对这一类别都是这种特征呢?我们可以通过对其他DNN进行测试来证明这一点。我们进行了两个实验,我们用DNN A来生成图片,然后输入到DNN B中,第一种情况是,DNN A和DNN B具有相同的结构和训练方法,但是初始化方式不同。第二种情况是,两者用相同的数据集训练,但具有不同的结构。在MNIST和ImageNet上都做了这个实验。结果显示,图片在DNN A 和DNN B 上的置信度都大于99.99%,因此DNN的泛化性可以被EA利用。
3.6 训练网络来识别这些图片(防御方法)
DNN可以很容易的被我们训练好的图片愚弄,为了进行对抗防御,那么我们应该重新训练一下网络,使得网络将对抗样本分类为"fooling images"类别,而不是之前的任何类。
作者在MNIST和ImageNet上对上述假设进行测试,操作如下:我们现在某个数据集上训练一个DNN 1,使用CPPN得到进化的图片,然后我们把这些图片添加到数据集上,标签为第n+1类。然后我们在新的数据集上训练DNN 2。
之后又对上述过程进行了优化,又在DNN 2的基础上,使用CPPN得到图片,将得到的图片仍然记为n+1类,然后不断地迭代。在每次迭代过程中,只添加n+1个类当中的m类(随机选取)的优化的图片。
MNIST数据集总共60000张图片,共10个类别,平均每个类别6000张。
我们在第一次迭代中添加了6000张进化得到的图片(经过了3000次迭代)。每次新的迭代,我们都会增加1000张新得到的图片到训练集中。
作者发现,在重复操作后,LeNet的防御能力仍然很一般,我们仍然可以通过CPPN生成置信度99.99%的图片。
这里是使用的ISLVRC(ImageNet的子数据集),共1281167张图片,1000个类别,平均每个类别有1300张。
我们在第一次迭代中添加了9000张进化得到的图片。每次新的迭代,我们都会增加7*1300张新得到的图片到训练集中。如果没有这种数据的不平衡,那么使用反例来训练网络是没有用处的。
在ImageNet上,DNN 2比DNN 1更难通过CPPN生成图片,且置信度下降。ImageNet的网络更容易去区分CPPN生成的图片与原始数据集,因此更容易通过反例的训练来提高自己的防御能力。
另一种去生成图片的方式,是在像素空间内的梯度上升 。
我们会计算DNN的softmax的输出对于输入的梯度,我们根据梯度来增加一个单元的激活值,目的是去找到一个图片能够得到很高的分类置信度。
这种方法相比于之前介绍的两种EA算法,能够生成更多不同的样本。
4、讨论
通过进化算法,按道理来说,应该会出现两种情况,一种是我们能够为每一个类进化出人类可识别的图像。第二种是,考虑到局部最优的情况,生成的图片应该会在所有的类上的置信度都比较低。
但事实却与上述相反,我们得到的图片DNN可识别而人类无法识别,且置信度在某些类别上很高,而在某些类别上很低。作者认为这是判别模型和生成式模型的不同导致的。
判别式模型,即 p ( y ∣ X ) p ( y ∣ X ) p ( y ∣ X ) p(y∣X) p(y∣X) \ p(y|X) p(y∣X) p(y∣X) p(y∣X) p(X) 较低时,DNN在此类图像的标签预测中的置信度会大打折扣。不幸的是,目前的通用模型并不能很好地扩展到像ImageNet这样的数据集的高维性,所以测试它们在多大程度上被愚弄必须等待生成模型的发展。
CPPN EA可以看作是一种能够可视化DNN所学习到的特征的一种新奇的方法。
5、总结
首次提出假反例攻击,即:生成人类无法识别的图片,却能够让神经网络以高置信度分类成某个类别
使用了多种不同的方法生成图片,称为“fooling images”
- 普通的EA算法,对图片的某个像素进行变异、进化
- CPPN EA算法,可以为图像提供一些几何特性,如对称等
- 梯度上升
将fooling images添加到数据集中,作为n+1类,重新训练网络,然后将得到的网络再生成fooling images,再训练,如此迭代,来提高模型的防御能力。
介绍了在MNIST数据集和ImageNet数据集上进行实验的区别
在MNIST数据集上,由于数据量小,得到的网络模型的容量小,更容易生成fooling images,也跟难通过 利用fooling images重新训练模型的方式 来提高其防御能力
在ImageNet数据集上,数据量大,类别多,得到的网络模型的容量大,更难生成fooling images,不过由于其容量大,能够通过重新训练的方式提高防御能力
判别式模型 p ( y ∣ X ) p ( y ∣ X ) p ( y ∣ X ) p(y∣X) p(y∣X) \ p(y|X) p(y∣X) p(y∣X) p(y∣X) p(y,X) 的对比:判别式模型比生成式模型拥有更好的防御能力
假反例攻击为神经网络的部署提出了很大的应用问题。
个人小结
这篇文章读起来意思大概能懂,具体的一些细节在这里没有解释的很清楚,希望在日后的学习中加深对文章的理解,如果写的不好请多多指正。
















 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









