







 这篇博客介绍了如何运用逻辑回归分析电信公司的客户流失情况。通过两变量独立性分析,确定影响流失的因素,并建立预测模型。数据集来源自GitHub,作者使用训练和测试数据集构建了在网时长对流失的逻辑回归模型,评估了模型的准确性和召回率,并采用向前逐步法优化模型,探讨了相关疑问点和遗留问题。
这篇博客介绍了如何运用逻辑回归分析电信公司的客户流失情况。通过两变量独立性分析,确定影响流失的因素,并建立预测模型。数据集来源自GitHub,作者使用训练和测试数据集构建了在网时长对流失的逻辑回归模型,评估了模型的准确性和召回率,并采用向前逐步法优化模型,探讨了相关疑问点和遗留问题。
数据集及源码https://github.com/JCATHoney/python-data-analysis
一、问题描述
电信公司希望针对客户的信息预测其流失可能性
分析思路:
在对客户流失与否的影响因素进行模型研究之前,首先对各解释变量与被解释变量进行两变量独立性分析,以初步判断影响流失的因素,进而建立客户流失预测模型
二、数据集
主要变量说明如下:
#subscriberID="个人客户的ID"
#churn="是否流失:1=流失";
#Age="年龄"
#incomeCode="用户居住区域平均收入的代码"
#duration="在网时长"
#peakMinAv="统计期间内最高单月通话时长"
#peakMinDiff="统计期间结束月份与开始月份相比通话时长增加数量"
#posTrend="该用户通话时长是否呈现出上升态势:是=1"
#negTrend="该用户通话时长是否呈现出下降态势:是=1"
#nrProm="电话公司营销的数量"
#prom="最近一个月是否被营销过:是=1"
#curPlan="统计时间开始时套餐类型:1=最高通过200分钟;2=300分钟;3=350分钟;4=500分钟"
#avPlan="统计期间内平均套餐类型"
#planChange="统计期间是否更换过套餐:1=是"
#posPlanChange="统计期间是否提高套餐:1=是"
#negPlanChange="统计期间是否降低套餐:1=是"
#call_10086="拨打10086的次数"
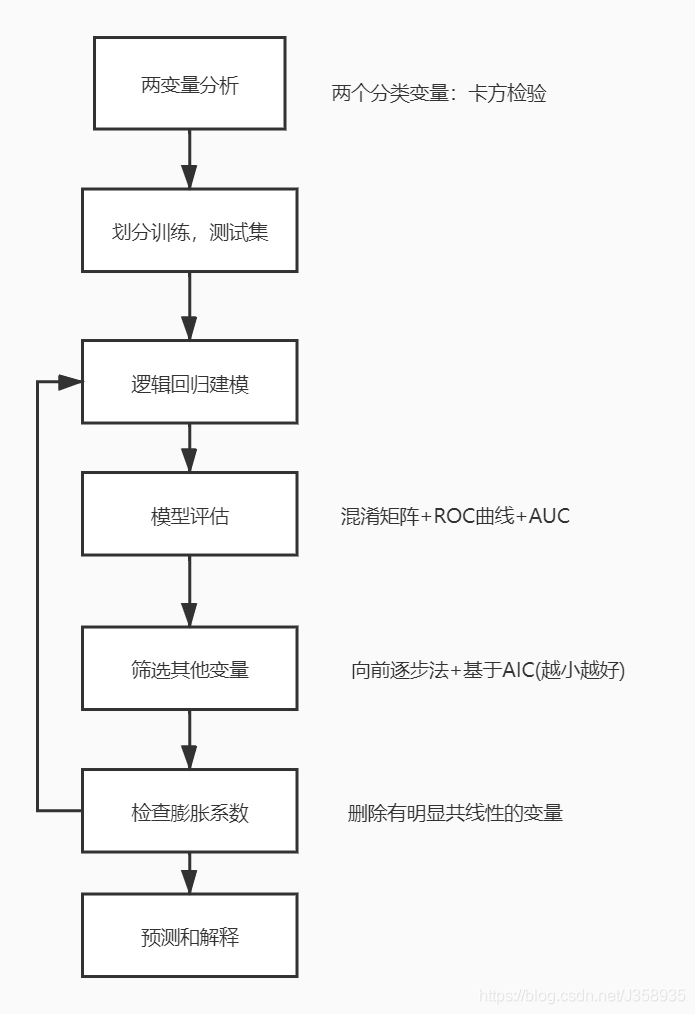
三、解题步骤
- 两变量分析:检验该用户通话时长是否呈现出上升态势(posTrend)对流失(churn) 是否有预测价值
- 首先将原始数据拆分为训练和测试数据集,使用训练数据集建立在网时长对流失的逻辑回归,使用测试数据集制作混淆矩阵(阈值为0.5),提供准确性、召回率指标,提供ROC曲线和AUC。
- 使用向前逐步法从其它备选变量中选择变量,构建基于AIC的最优模型,绘制ROC曲线,同时检验模型的膨胀系数
流程图:
四、疑问点记录
- margin=True
cross_table = pd.crosstab(data0.posTrend,data0.churn, margins=True)#margins 显示总数
‘margins=True’ 显示总数统计量,这个属性可以用在得到混淆矩阵后求召回率,精确率等
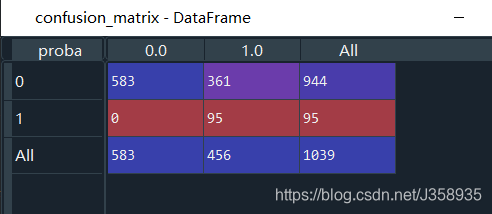
precision = confusion_matrix.loc[0, 0] /confusion_matrix.loc['All', 0]#命中率(A/A+C)
- float(‘inf’) 正无穷
五、代码
# -*- coding: utf-8 -*-
"""
Created on Mon Aug 10 11:32:08 2020
@author: Away
"""
#%%
import os
import numpy as np
from scipy import stats
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
os.chdir(r'C:\Users\Away\Desktop\笔记\数据分析\数据科学实践')
#%%
data0 = pd.read_csv('telecom_churn.csv', skipinitialspace=True)
data0.head()
#%%
#(一) 两变量分析:检验该用户通话时长是否呈现出上升态势(posTrend)对流失(churn) 是否有预测价值
# 两个分类变量的相关关系,列联表分析(卡方检验)
cross_table = pd.crosstab(data0.posTrend,data0.churn, margins=True)#margins 显示总数
#%%
def percConvert(ser):
return ser/float(ser[-1])
cross_table.apply(percConvert, axis=1)#做行百分比
'''
churn 0.0 1.0 All
posTrend
0.0 829 990 1819
1.0 1100 544 1644
All 1929 1534 3463
'''
# In[8]:
print('''chisq = %6.4f
p-value = %6.4f
dof = %i
expected_freq = %s''' %stats.chi2_contingency(cross_table.iloc 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7890
7890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









