









Cross-Modality Person Re-Identification via Modality Confusion and Center Aggregation(基于情态混淆和中心聚合的跨模态行人重识别)
期刊合集:最近五年,包含顶刊,顶会>>网址
文章来源:ICCV2021
研究背景
目前,大多数现有的重识别方法都是通过使用身份监督或模态标签来学习模态特定或模态共享的特征。与现有方法不同的是,本文提出了一种新的模态混淆学习网络(MCLNet)。基本思想是混淆两种模态(可见—红外光模态),确保优化明确地集中在模式无关的角度。具体来说,MCLNet被设计用来学习模态不变特征,在最小化单个框架中实例之间的跨模态差异的同时,最大化跨模态相似性。此外,还引入了一种身份感知的边缘中心聚集策略来提取集中特征,同时在边缘约束下保持多样性。最后,设计了一个摄像头感知的学习方案来丰富识别能力。
在作者看来,大多数的研究工作集中在生成共模态或交叉模态图像的任务上 (不赞同这样做,这样做带有噪声,并且会增加计算量)。文章就提出了不同的观点,一种端到端模态混淆学习网络(MCLNet),用于学习模态不变特征。网络不需要输入的先验信息,也不需要额外的子空间特征,保证了输入信息的最大化而不产生额外的噪声,减少了不必要的计算量。 其基本思想是混淆特征学习过程中的模态判别,使优化明确地关注于模态无关的视角 图(a)。MCLNet通过最小-最大博弈最小化跨模态差异,同时最大化实例之间的跨模态相似性,结合部分共享的两流网络,MCLNet可以同时学习模态特定特征和提取模态不变特征。通过混淆学习的方式,实现了模态混淆和一般跨模态特征学习之间的平衡。此外,引入了一种身份感知的边缘中心聚合策略,以增强对模态差异的表示不变性 图(b),其基本思想是约束在两个模态中属于相同单位的样本是不变的,在鼓励提取集中特征的同时,加入了一个边际约束,以确保样本不会过于集中。这样既保持了特征的多样性,又大大增强了泛化能力。此外,根据观察到人物图像是在完全不同的相机环境中捕获的,进一步集成了一个相机感知的边缘中心聚合方案 图©。该组件充分利用相机标签,为学习的表示捕获相机特定的信息。这个约束增强了对相机变化的鲁棒性,提出的组件可以很容易地集成到其他高级学习模型中。

论文分析
文章贡献点如下:
(1) 提出了一种新颖的模态混淆学习网络 (MCLNet)。提取与模态无关的有效学习结构,从而增强了学习的表示形式对模态变化的鲁棒性。
(2) 引入了一种身份感知的边际约束中心聚合策略 (ICA)。在提取集中化特征的同时,保持多样性以获得具有边际约束的更好的泛化能力。
(3) 设计了一种相机感知学习方案 (CCA),该方案应用相机标签监督,通过相机感知表示来丰富可分辨性。
MCLNet 网络框架
采用AGW作为识别任务的特征提取器,中心聚合损失的方法得到预测身份,另外加上身份损失(ID loss ) Lid和加权正则化三元组(WRT)损失Lwrt指导网络学习。
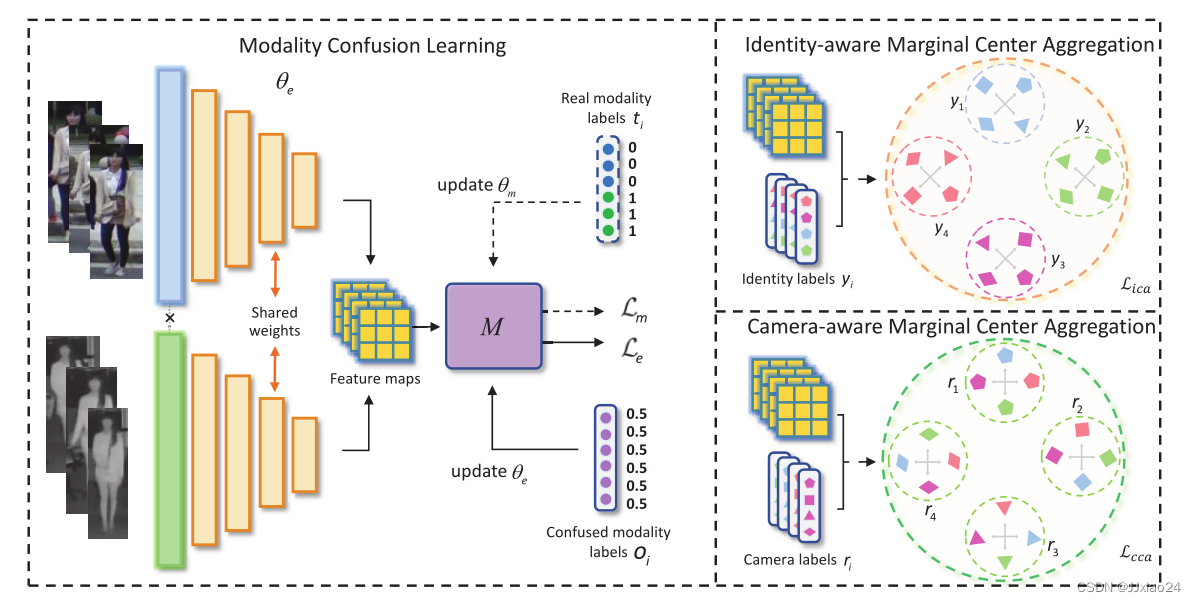
Feature Extractor(特征提取器)
特征提取器是一个连续提取模态特定特征和模态共享特征的双流网络。具体来说,为了处理两种异构模态的差异,在第一个卷积块中,对可见光图像和红外图像进行独立处理,目的是学习低级特征。在此之后,两个流的以下四个块共享参数并提取共同的高维特征。

Modality Confusion Learning(模态混淆学习)
通过最小-最大博弈最小化了模态间的差异,最大化了跨模态的相似度。应用混淆学习机制来欺骗网络,使可见模态与红外模态混淆。该机制避免了生成的交叉模态图像质量差和噪声的风险,并直接作用于两种模态的嵌入。具体来说,目标是实现模态分类器无法区分输入图像的模态的混乱。

对于每个样本图像xi,都有一个身份标签yi,一个真实模态标签ti和一个混淆模态标签oi。具体来说,使用二维向量来定义one-hot模态标签,对每个输入样本xi,可见光图像,真实模态标签ti设为[1,0];红外图像,真实模态标签ti设为[0,1]。对于混淆的模态标签oi,对于来自两个不同模态的所有样本,它被设置为[0.5,0.5]。
模态混淆学习由两个部分组成:特征提取器(Feature Extractor)和模态混淆模块M(Modality Confusion Learning)。使用参数θm表示M,作为模态混淆模块(MCM)。模态混淆学习本质上是一个两层分类器,其目的是准确地将输入图像区分为某种模态。对于提取特征fxi的样本xi, M输出模态预测概率pm(fxi),并将其与真实模态标签ti进行比较。M的损失函数可表示为:

其中N表示批中的样本数,xi是第i个输入样本。给定一个学习的特征提取器θe和模态分类器θm,样本xi被正确分类的概率由pm(fxi,θm; θe) 表示,并由softmax函数归一化。 特征提取器的目的是提取模态不变和区分性的特征。 同样,用参数θe构造E作为特征提取器。为了实现模态混淆,将特征提取器的预测概率与混淆的模态标签oi进行比较。损失函数可表示为:

在训练阶段,通过交替更新参数θm和θe,直到它们达到平衡。其中,θe表示特征提取器,其目的是通过使特征分布尽可能相似来最大化模态混淆模块的损失。θm表示模态混淆模块,用来最大限度地减少模态分类器的损失,帮助网络区分模态。θm和θe的优化如下:

在优化过程中,每一步都只会更新一个模块,另一个模块就会被固定。比如,特征提取器E正在更新参数θm,那么模态混淆学习M的参数就不会发生改变。这一策略确保了网络以正确的梯度更新。最后,如果特征提取器提取的嵌入不能正确地分类到相应的模态中,那么就会达到模态混淆的目的。
Identity-aware Marginal Center Aggregation( 身份感知边缘中心聚合)

大多数现有方法都采用中心损失来同时学习每个类的中心进行特征嵌入,并惩罚样本与其相应类之间的距离。中心损失Lc可以表示为:

其中xi为第i个输入样本,cyi为第i个类中心,fxi为第yi类特征提取器所提取的嵌入。
考虑到如果严格集中两种模态中相同身份的图像,会牺牲不同人图像的多样性,导致测试集泛化能力有限。文章给出了一种关于身份感知的边缘中心聚合策略(ICA),在适度提取集中特征的同时,考虑到识别信息。

如上图所示,每种颜色都对应着某种身份。中心损失的作用是使所有样本都靠近相应类别的中心(a)。不同的是,应用 ICA是将相同身份的特征约束在一定范围内(b),而不是像(a)那样。特别的,应用超参数σ用来保证属于同一类的样本都不会太靠近中心,防止特征过度拟合到特征中心(不同身份的特征预测出相同人物),即使在不同的模式下也能适度保持身份描述的多样性。这种多样性可以为网络提供更多特定于样本的信息,以区分不同人的身份。ICA鼓励统一分布在高维球体上的相同身份的特征,而不是盲目追求表示相似性。用于身份预测的ICA的损失可以表示为:

其中,xi表示第i个样本,yi是xi的身份标签,cyi是第yi个单位的类中心,foyi是距离cyi中心最近的特征嵌入,N是某批样本个数,σ是超参数,表示某类球体的半径。
在等式(5)的右侧,第一项 中的第一元素是中心损耗的一般形式,其表示 (a) 和 (b) 中的外圆 (蓝色) 约束。减去第二个元素(样本和中心cyi之间的最小距离)
中的第一元素是中心损耗的一般形式,其表示 (a) 和 (b) 中的外圆 (蓝色) 约束。减去第二个元素(样本和中心cyi之间的最小距离)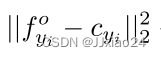 ),以便将样本特征逐渐从中心cyi移动一小部分。超参数 σ 迫使样本与其身份中心保持合理的距离,在 (b) 中,σ 可以看作内圆的半径 (红色虚线),这种设计避免了过于严格的中心集中。第二项计算不同身份中心的最小距离,通过在不同的身份中心之间应用多个约束,网络比较的是身份的相似性而不是样本的相似性。
),以便将样本特征逐渐从中心cyi移动一小部分。超参数 σ 迫使样本与其身份中心保持合理的距离,在 (b) 中,σ 可以看作内圆的半径 (红色虚线),这种设计避免了过于严格的中心集中。第二项计算不同身份中心的最小距离,通过在不同的身份中心之间应用多个约束,网络比较的是身份的相似性而不是样本的相似性。
Camera-aware Marginal Center Aggregation(摄像头感知边缘中心聚合)
考虑到较大的摄像头差异,本文提出了一种利用摄像头标签信息进行进一步改进的策略,加强了模态不变特征的学习。 在现实生活中,cm-ReID的任务通常是由多个摄像机捕获的,这促使需要对相机本身的差异进行建模,原因由如下几点:
1)不同的相机内部参数是不同的(品牌不同)。
2)不同的相机有不同的背景和视角(位置不同)。
3)相机之间通常没有重叠区域(没有交集)。为此,文章提出了一种基于摄像机感知的边缘中心聚合策略(CCA),目标是让网络学习不同摄像机的鉴别信息。具体来说,希望网络也能注意到来自不同摄像机的图像的差异,因为这些摄像机通常在不同的模式或不同的环境中工作。 在ICA和CCA的共同约束下,鼓励网络在不同摄像机下挖掘同一个人之间的隐式身份关联信息。相机感知边际中心聚集损失Lcca可以表示为:

其中ri为第i个样本的摄像机标签,cri为第ri个摄像机中心,ori表示离相机中心最近的样本。其他元素与公式5相似。 身份感知边缘中心聚合策略(ICA)和摄像头感知边缘中心聚合策略(CCA)以不同的方式提取识别信息。如图所示,ICA一方面对来自不同摄像机的同一身份图像进行约束。另一方面,CCA从不同的身份约束同一相机图像。这两个组件一起工作,显式地应用特定于身份的信息和特定于相机的信息。

一个由身份损失(ID loss ) Lid和加权正则化三元组(WRT)损失Lwrt组成的传统损失函数被设计用来学习判别表示:

经过特征提取,得到了具有理想性能的特征嵌入。分别采用ICA和CCA进行人物身份预测和摄像机身份预测。综上所述,得到最终损失为:

其中λ是一个预定义的权衡参数。值得注意的是,由于之前文章说明过,Le和Lm的更新是分开的,所以Lm不包括在总的损失当中,它们通过对抗性训练交替更新,监督网络以实现模态混淆,当达到模态混乱时,是可以忽略Lm(没对样本预测产生影响)。
实验结果
#pic_center
结论
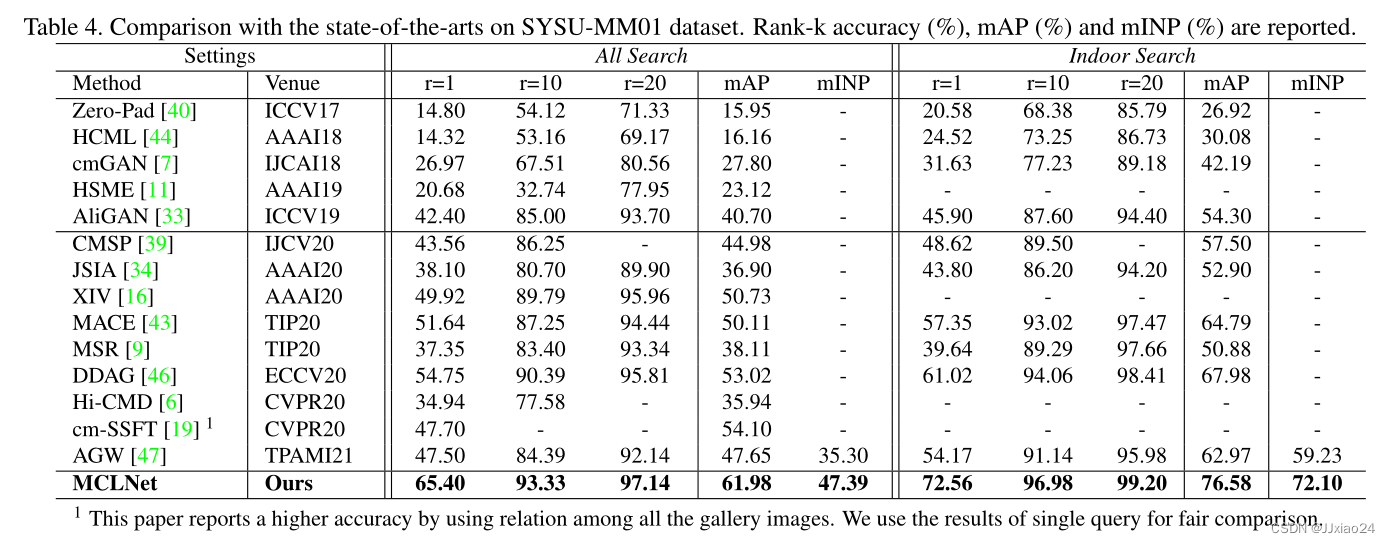
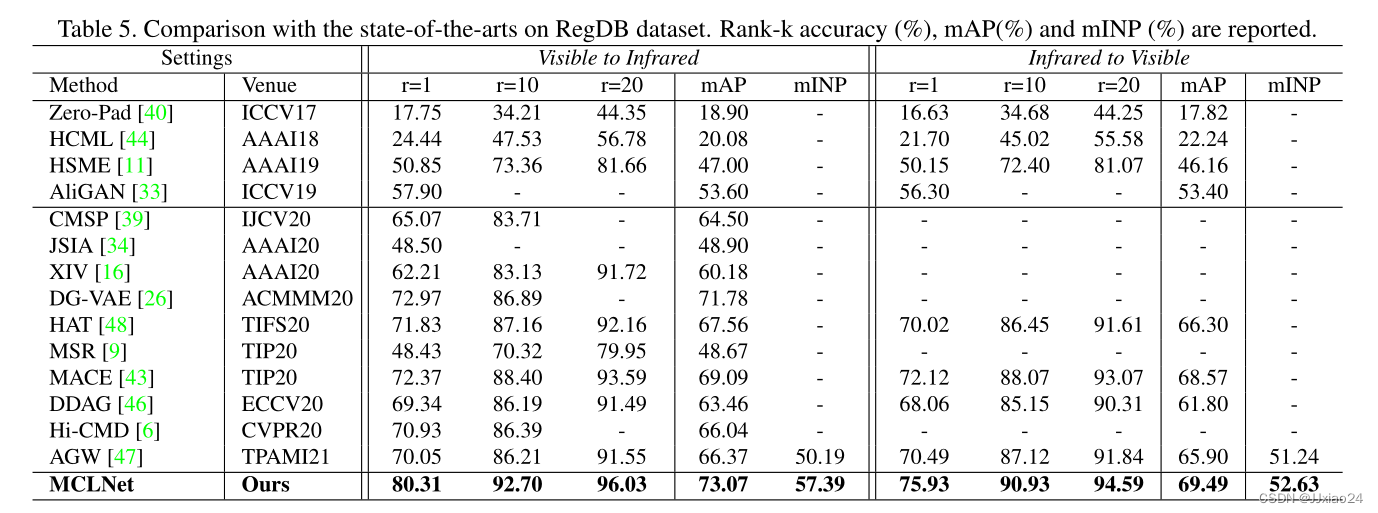
在本文中,作者提出了一种新的cm-ReID基线与模态混淆学习网络(MCLNet),它可以通过最小化跨模态差异来学习模态不变特征,同时最大化实例之间的跨模态相似性。与其他方法不同,MCLNet的目的是通过混淆学习机制来混淆两种模态。同时提出了一种身份感知和摄像头感知的边缘中心聚合策略,用于人ID和摄像头ID的预测,可以帮助框架适度地提取集中特征。大量的实验验证了所提方法的优越性能,以及框架中每个组件的有效性。在大规模SYSU-MM01数据集上,该模型的Rank-1精度和mAP值分别达到65.40%和61.98%。
















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











