






文章目录
利用python的pulp库进行CCR、BCC、超效率模型的数学建模
本文参考书目为
《数据包络分析方法与MaxDEA软件》
一、CCR、BCC、超效率模型公式?
1. 投入导向的CCR对偶公式

2. BCC模型公式

3. 超效率模型公式

二、数学模型构建
1.数据示例
import pandas as pd
data = pd.DataFrame([[4,3,1],[7,3,1],[8,1,1],[4,2,1],[2,4,1],[10,1,1],[12,1,1],[10,1.5,1]],columns=['x1','x2','y'],index=['A','B','C','D','E','F','G','H'])
data
>>>
x1 x2 y
A 4 3.0 1
B 7 3.0 1
C 8 1.0 1
D 4 2.0 1
E 2 4.0 1
F 10 1.0 1
G 12 1.0 1
H 10 1.5 1
1.1 pulp 包使用方法
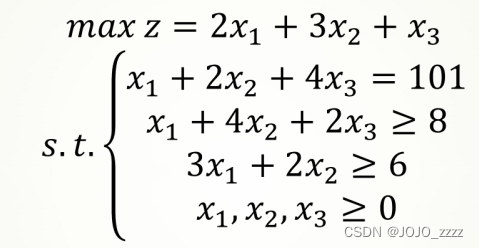
d = np.array([2,3,1])
da = np.array([1,2,4])
da1 = np.array([[1,3],[4,2],[2,0]])
r = np.array([8,6])
m = pulp.LpProblem(sense=pulp.LpMinimize)
x1 = pulp.LpVariable.dict("x",range(3),lowBound=0)
x = list(x1.values())
m += pulp.lpSum([d[i0] * x[i0] for i0 in range(3)])
for i in range(2):
m += pulp.lpSum([x[i0] * da1[i0][i] for i0 in range(3)]) >= r[i]
m += ( pulp.lpDot(da , x) == 101 )
m.solve()
pulp.value(m.objective)
>>>
28.75
>>>
# 以上可能写的太过复杂,可以参考一下简单例子
z = [2,3,1]
a = [[1,4,2],[3,2,0]]
b = [8,6]
c = [1,2,4]
d = 101
m1 = pulp.LpProblem(sense=pulp.LpMinimize) #定义函数
x = [pulp.LpVariable(f"x_{i}",lowBound=0) for i in range(3)] #设置变量
m1 += pulp.lpDot(z, x) # "m1 +=" 是固定符号,后面若无约束,则说明这条语句为目标函数
m1 += pulp.lpDot(c,x) == d # 约束条件
for i in range(len(a)): # 约束条件
m1 += (pulp.lpDot(a[i], x) >= b[i])
m1.solve()
pulp.value(m1.objective) # 得到的值
>>>
28.75
>>>
m1 #查看定义函数的整个公式情况
>>>
NoName:
MINIMIZE
2*x_0 + 3*x_1 + 1*x_2 + 0
SUBJECT TO
_C1: x_0 + 2 x_1 + 4 x_2 = 101
_C2: x_0 + 4 x_1 + 2 x_2 >= 8
_C3: 3 x_0 + 2 x_1 >= 6
VARIABLES
x_0 Continuous
x_1 Continuous
x_2 Continuous
>>>
1.2 学会基础建模后,套用书上给的CCR公式
# 非超效率CCR模型
import pulp as lp
DMUs = data.index.values
d_var = data.columns.values
# 变量
var = lp.LpVariable.dict("DMU",data.index.values,lowBound=0)
thita = lp.LpVariable('thita')
for DMU in DMUs:
# 目标函数
pr = lp.LpProblem('CCR',lp.LpMinimize)
pr += thita
# 约束条件
pr += lp.lpSum(data.to_dict()['x1'][i] * var[i] for i in DMUs) <= thita * data.to_dict()['x1'][DMU]
pr += lp.lpSum(data.to_dict()['x2'][i] * var[i] for i in DMUs) <= thita * data.to_dict()['x2'][DMU]
pr += lp.lpSum(data.to_dict()['y'][i] * var[i] for i in DMUs) >= data.to_dict()['y'][DMU]
#pr += lp.lpSum(var) == 1
result = pr.solve()
print(DMU,":",lp.value(thita))
>>>
A : 0.85714286
B : 0.63157895
C : 1.0
D : 1.0
E : 1.0
F : 1.0
G : 1.0
H : 0.75
#超效率CCR模型
import pulp as lp
DMUs = data.index.values
d_var = data.columns.values
var = lp.LpVariable.dict("DMU",data.index.values,lowBound=0)
thita = lp.LpVariable('thita')
for DMU in DMUs:
pr = lp.LpProblem('CCR',lp.LpMinimize)
pr += thita
pr += lp.lpSum(data.to_dict()['x1'][i] * var[i] for i in DMUs if i != DMU) <= thita * data.to_dict()['x1'][DMU]
pr += lp.lpSum(data.to_dict()['x2'][i] * var[i] for i in DMUs if i != DMU) <= thita * data.to_dict()['x2'][DMU]
pr += lp.lpSum(data.to_dict()['y'][i] * var[i] for i in DMUs if i != DMU) >= data.to_dict()['y'][DMU]
# pr += lp.lpSum(var) == 1
result = pr.solve()
print(DMU,":",lp.value(thita))
>>>
A : 0.85714286
B : 0.63157895
C : 1.1428571
D : 1.25
E : 2.0
F : 1.0
G : 1.0
H : 0.75
2. 面向对象,写入类函数
代码如下(示例):
#CCR模型
import pandas as pd
import numpy as np
import pulp as lp
class DEA_CCR:
def __init__(self, data, inputs_numbers, outputs_numbers, returns="CRS"):
"""
data(数据为pd.DataFrame形式);
inputs_numbers(输入投入个数);
outputs_numbers(输入产出个数);
returns (输入 "CRS" or "VRS")
"""
self.data = data
self.inputs_numbers = inputs_numbers
self.outputs_numbers = outputs_numbers
self.returns = returns
self.DMUs = data.index.values
self.d_var = data.columns.values
def _CCR(self):
self.var = lp.LpVariable.dict("DMU",self.data.index.values,lowBound=0)
thita = lp.LpVariable('thita')
dums_dict = {}
for DMU in self.DMUs:
pr = lp.LpProblem('CCR',lp.LpMinimize)
pr += thita
if self.returns == "VRS":
pr += lp.lpSum(self.var) == 1
for j0 in self.d_var[0:self.inputs_numbers]:
pr += lp.lpSum(self.data.to_dict()[j0][i] * self.var[i] for i in self.DMUs) <= thita * self.data.to_dict()[j0][DMU]
for r0 in self.d_var[self.inputs_numbers:self.inputs_numbers+self.outputs_numbers]:
pr += lp.lpSum(self.data.to_dict()[r0][i] * self.var[i] for i in self.DMUs) >= self.data.to_dict()[r0][DMU]
pr.solve()
dums_dict[DMU] = lp.value(pr.objective)
dums_dict_data = pd.DataFrame.from_dict(dums_dict, orient='index')
return dums_dict_data
def _CCR_super(self):
self.var = lp.LpVariable.dict("DMU",self.data.index.values,lowBound=0)
thita = lp.LpVariable('thita')
dums_dict = {}
for DMU in self.DMUs:
pr = lp.LpProblem('CCR',lp.LpMinimize)
pr += thita
if self.returns == "VRS":
pr += lp.lpSum([self.var[i] for i in DMUs if i!= DMU]) == 1 #超效率的VRS,和非超效率有些许不同
for j0 in self.d_var[0:self.inputs_numbers]:
pr += lp.lpSum([self.data.to_dict()[j0][i] * self.var[i] for i in self.DMUs if i != DMU]) <= thita * self.data.to_dict()[j0][DMU]
for r0 in self.d_var[self.inputs_numbers:self.inputs_numbers+self.outputs_numbers]:
pr += lp.lpSum([self.data.to_dict()[r0][i] * self.var[i] for i in self.DMUs if i != DMU]) >= self.data.to_dict()[r0][DMU]
result = pr.solve()
dums_dict[DMU] = lp.value(pr.objective)
dums_dict_data = pd.DataFrame.from_dict(dums_dict, orient='index')
return dums_dict_data
3. 测试
代码如下(示例):
C_data = DEA_CCR(data,2,2,returns = "VRS")._CCR()
C_data
>>>
A 0.857143
B 0.631579
C 1.000000
D 1.000000
E 1.000000
F 1.000000
G 1.000000
H 0.750000
C_data = DEA_CCR(data,2,2,returns = "VRS")._CCR_super()
C_data
>>>
A 0.857143
B 0.631579
C 1.142857
D 1.250000
E 2.000000
F 1.000000
G 1.000000
H 0.750000
总结
- 先对基础公式进行建模测试
- 然后放入类打包

















 2433
2433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









