






基于ChatGLM模型关于警情识别实战
ChatGLM模型训练
环境部署
首先需要下载仓库
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
下载代码后,修改requirements.txt文件,加上需要安装的依赖
icetk
chardet
streamlit
streamlit-chat
rouge_chinese
nltk
jieba
datasets
然后执行
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装依赖
数据集
数据集需按照自己的需求去选取数据
数据脱敏
在前面也提到,数据属于敏感数据(上述公开数据均为自创数据,属于脱敏数据,实际内容属于敏感数据),需要做脱敏处理。
首先看ptuning中main.py的这段代码片
def preprocess_function_eval(examples):
inputs, targets = [], []
for i in range(len(examples[prompt_column])):
if examples[prompt_column][i] and examples[response_column][i]:
query = examples[prompt_column][i]
history = examples[history_column][i] if history_column is not None else None
prompt = tokenizer.build_prompt(query, history)
inputs.append(prompt)
targets.append(examples[response_column][i])
inputs = [prefix + inp for inp in inputs]
model_inputs = tokenizer(inputs, max_length=data_args.max_source_length, truncation=True, padding=True)
labels = tokenizer(text_target=targets, max_length=max_target_length, truncation=True)
if data_args.ignore_pad_token_for_loss:
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
def preprocess_function_train(examples):
max_seq_length = data_args.max_source_length + data_args.max_target_length + 1
model_inputs = {
"input_ids": [],
"labels": [],
}
for i in range(len(examples[prompt_column])):
if examples[prompt_column][i] and examples[response_column][i]:
query, answer = examples[prompt_column][i], examples[response_column][i]
history = examples[history_column][i] if history_column is not None else None
prompt = tokenizer.build_prompt(query, history)
prompt = prefix + prompt
a_ids = tokenizer.encode(text=prompt, add_special_tokens=True, truncation=True,
max_length=data_args.max_source_length)
b_ids = tokenizer.encode(text=answer, add_special_tokens=False, truncation=True,
max_length=data_args.max_target_length)
context_length = len(a_ids)
input_ids = a_ids + b_ids + [tokenizer.eos_token_id]
labels = [tokenizer.pad_token_id] * context_length + b_ids + [tokenizer.eos_token_id]
pad_len = max_seq_length - len(input_ids)
input_ids = input_ids + [tokenizer.pad_token_id] * pad_len
labels = labels + [tokenizer.pad_token_id] * pad_len
if data_args.ignore_pad_token_for_loss:
labels = [(l if l != tokenizer.pad_token_id else -100) for l in labels]
model_inputs["input_ids"].append(input_ids)
model_inputs["labels"].append(labels)
return model_inputs
这两个函数的功能便是处理训练数据和推理数据,其中tokenizer.build_prompt()会将我们的query变为问答模式,即会添加一个“问:”query前面,添加一个“答:”在后面,这段比较抽象。强烈建议实操打印一下
然后我们将内容里面的tokenizer操作换在外面实现便可以实现脱敏
模型训练
我们使用train.sh脚本训练
train.sh
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file test/desensitiveoutput.json \
--validation_file test/dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
evaluate.sh
PRE_SEQ_LEN=128
CHECKPOINT=adgen-chatglm2-6b-pt-128-2e-2
STEP=3000
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file test/tuili.json \
--test_file test/tuili.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path THUDM/chatglm2-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
执行训练
bash train.sh

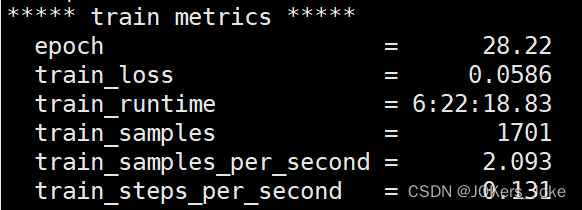
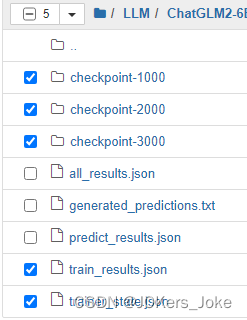
训练完成后会生成output文件夹,在该文件夹下可看到生成的checkpoint文件夹
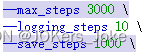
如果修改了train.sh的max_steps,请记得修改save_steps!!!
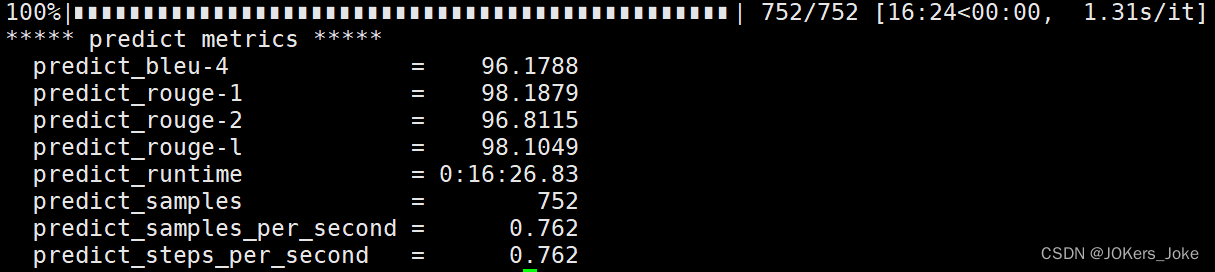
执行推理
bash evaluate.sh
下面就是本次测试集的打分
web网页使用训练模型
我们运行ptuning文件夹下的web_demo.sh文件,通过网页访问使用模型,脚本文件需要修改模型路径,修改后如下:
PRE_SEQ_LEN=128
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path THUDM/chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-3000 \
--pre_seq_len $PRE_SEQ_LEN
注意:checkpoint-3000记得修改为自己生成的数值(如果有修改的话)
运行
bash web_demo.sh
便会出现一个网址
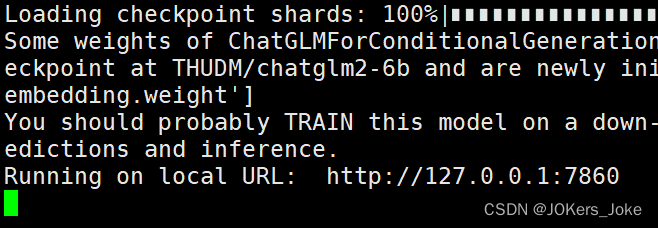
如果是在本地运行的,直接复制粘贴到网页即可运行,如果跟我一样是在服务器上进行的部署、训练、推理,则需要映射到本地后才能运行。
键盘上同时点击win+r,输入cmd进入命令窗口,然后输入
ssh -N -L 8896:127.0.0.1:7860 XXXXXX@172.17.70.21
XXXXXX为自己的服务器账号,输入完密码在浏览器输入网址
http://localhost:8896/
便可以启动自己的网页demo了
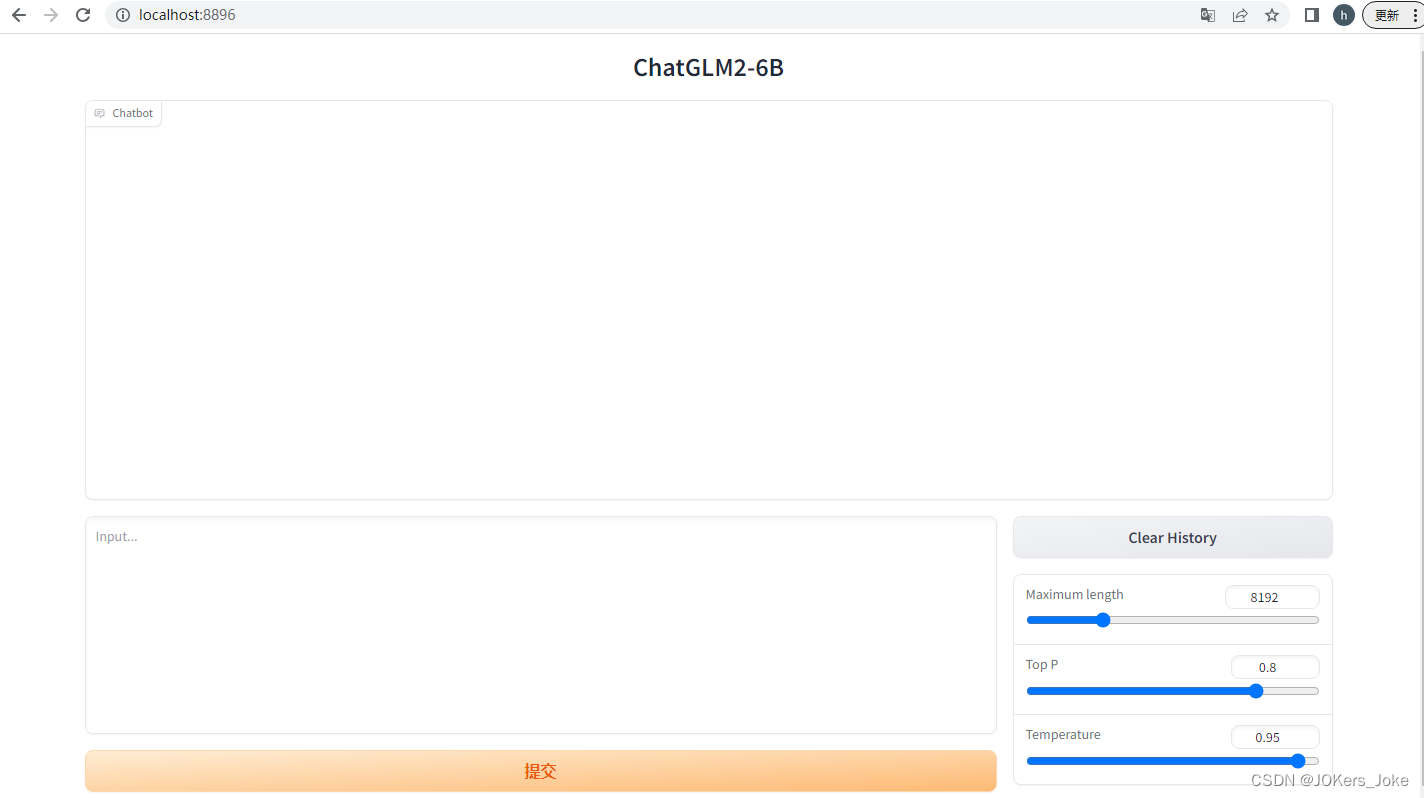
测试效果
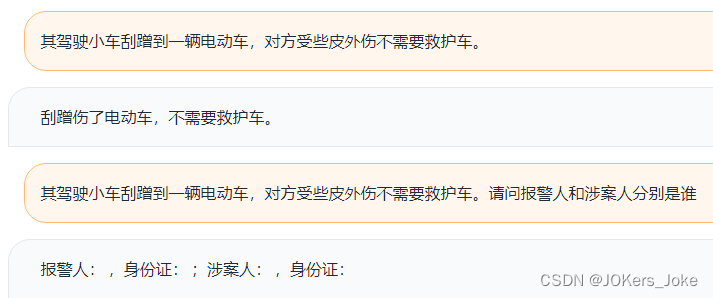
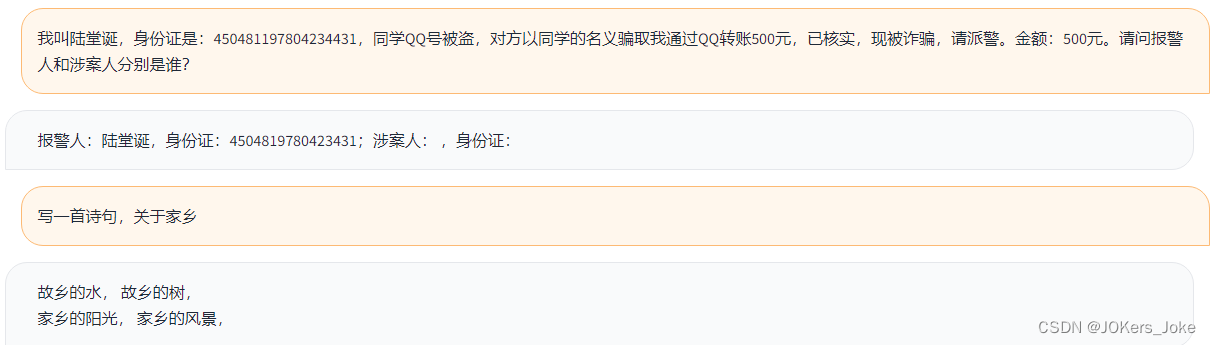
经过训练后,对于任务要求已经可以做到基本识别了,总体而言本次实战还算比较成功。

















 1688
1688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









