









惯性导航时常用到ARMA建模和卡尔曼滤波,最近两天准备科普一下。
X n =−(a 1 X n−1 +a 2 X n−2 +....+a p X n−p )+ξ n +b 1 ξ n−1 +b 2 ξ n−2 +....+b q ξ n−q
AR(1)
自回归模型AR(P),
P=1
,建立漂移一阶归模型AR(1)模型:
X n =−a 1 X n−1 +ξ n
在MATLAB中可以使用ar()函数,读者可以help一下即可。
AR(1)模型描述误差信号后,可以将其改为状态空间模型和输入输出模型:
X k =ΦX n−1 +W k−1
Z k =HX k +V k
其中 W k−1 和V k 为零均值白噪声序列
进行卡尔曼滤波,我们需要知道系统模型噪声方差阵,量测噪声方差阵,以及初始值,看文献得,经过AR(1)模型拟合后的漂移信号的协方差为系统噪声协方差阵,实测数据作为观测量,其协方差为测量噪声的正定方差阵。另外,原始测量值均方根值的1/10作为初始误差方差阵。以后即可进行卡尔曼滤波,有关卡尔曼滤波公式不再赘述。
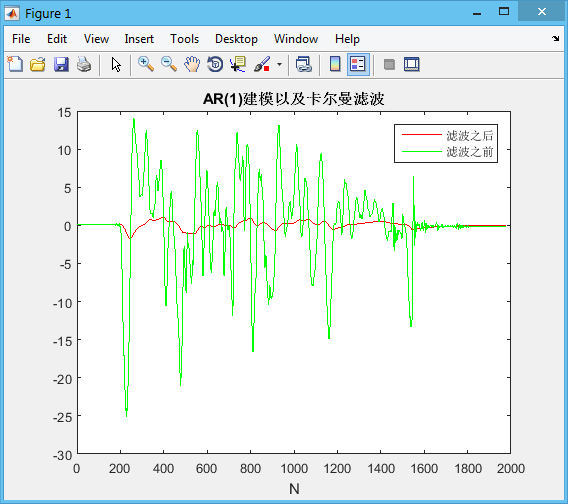
所得结果如下所示:















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









