







论文全名:Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction
基于深层特征重构的单目深度估计和视觉里程计的无监督学习
原文链接:https://arxiv.org/pdf/1803.03893v1.pdf
开源代码:https://github.com/Huangying-Zhan/Depth-VO-Feat(caffe)
1. Abstract
本文探讨了立体图片序列在 学习(训练) 深度和视觉测距中的应用。立体图片序列的使用使得系统能够使用空间(left-right pairs)和时间(forward-backward)photometric warp error?,并且将场景深度和相机运动约束在共同的真实世界尺度内。在测试时,该无监督框架能够使用单目序列来进行单视图深度估计和双视图测距。我们还展示了如何通过考虑a warp of deep features ?来改进标准photometric warp loss。大量实验证明:
(i)联合训练单目深度和视觉测距,改善了深度预测(因为对深度附加了额外的约束)并且视觉测距也取得较好结果;
(ii)基于特征的warping loss改善了单视图深度估计和视觉测距的简单photometric warp loss。
本文求场景无遮挡且为刚体,未来还需要对动态场景及遮挡进行建模。
2. Contributions
- 提出了联合学习深度估计器和视觉里程估计器的无监督框架,且不受尺度模糊影响。
- 利用了图像对在时间,空间上的全部约束,改进了现有技术基础上单目深度估计的性能。
- 产生最先进的、基于帧到帧的测程结果,性能显著优于同类无监督学习方法,与基于几何的方法同等水平。
- 除了基于颜色强度的图像重构loss(Image Reconstruction Loss)之外,使用了新的重构特征loss(Feature Reconstruction Loss),显著改善了深度和量距估计精度
3. Method
立体序列学习框架,从立体图像序列中联合学习单目深度卷积网络 C N N D CNN_D CNND(single view depth ConvNet)和视觉里程卷积网络 C N N V O CNN_{VO} CNNVO (visual odometry ConvNet)。此框架可克服使用单目图片序列训练遇到的尺度模糊问题,且使系统能够利用(left-right)空间和(forward-backward)时间一致性检查。
3.1 Network architecture
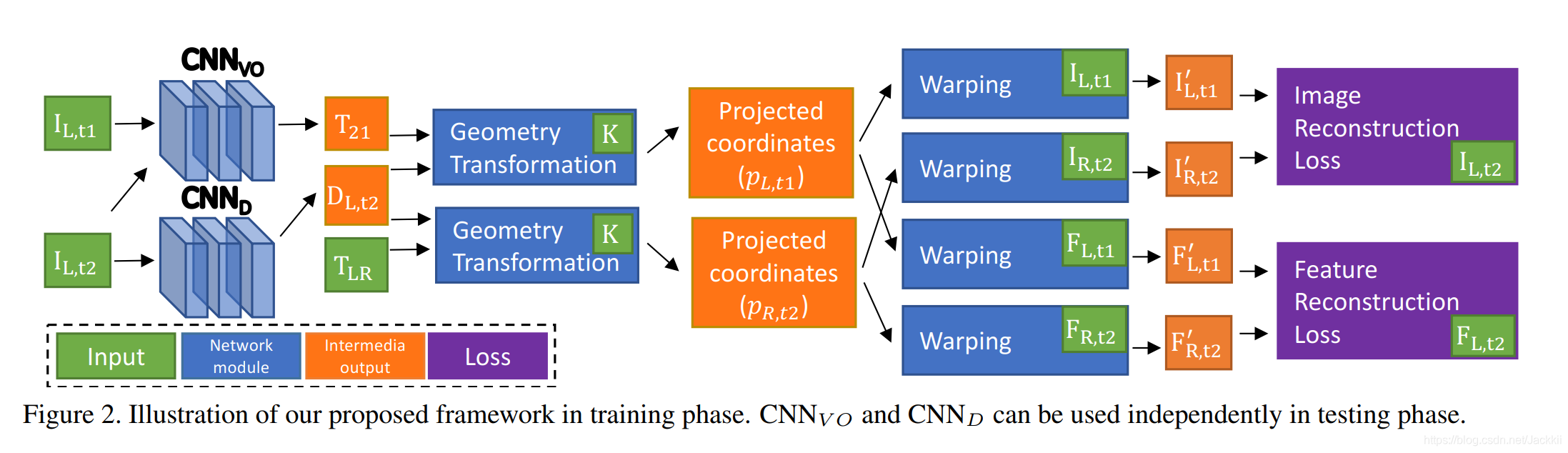 C N N D CNN_D CNND包含两个部分:编码器和解码器。
C N N D CNN_D CNND包含两个部分:编码器和解码器。
- 编码器采用 R e s N e t 50 ResNet50 ResNet50 的变体 R e s N e t 50 ResNet50 ResNet50- 1 b y 2 1by2 1by2 (含一半滤波器)。
- 解码器首先使用1x1 kernel 将编码器输出的1024通道特征图转化为1通道特征图,然后采用具有跳连接的传统双线性上采样kernels(使用跳连接融合来自编码器不同阶段提取到的低维特征),在最后预测层之后使用ReLU激活,保证输出预测值(深度值的倒数)为正。
- 最后我们将深度值倒数转化为深度值 D = 1 / ( D i n v + 1 0 − 4 ) D=1/(D_{inv}+10^{-4}) D=1/(Dinv+10−4)
C N N V O CNN_{VO} CNNVO
- 将两个沿着颜色通道连接的视图作为输入。
- 输出6D向量 [ u , v ] ∈ s e 3 [u,v]\in se3 [u,v]∈se3?(定义了 T r e f − > l i v e T_{ref->live} Tref−>live),然后将其转化为4x4变换矩阵。
- 网络由6个stride为2的卷积层+3个全连接层组成。
训练时,
- 采用双目图像序列 I I I为输入, C N N V O CNN_{VO} CNNVO 网络根据单目的前后序列图像,输出两个时刻间的变换矩阵 T 21 T_{21} T21(下文中的 T t 2 − > t 1 T_{t2->t1} Tt2−>t1)的估计值。
- 采用单目图像作为输入, C N N D CNN_D CNND输出深度的估计值 D L , t 2 D_{L,t2} DL,t2。
- 深度估计值 D L , t 2 D_{L,t2} DL,t2结合左右视图的变换矩阵 T L R T_{LR} TLR,以及相机的内参 K K K,得到右图的投影坐标。(同理 p L , t 1 p_{L,t1} pL,t1)
4.经过warping后,得到重构图和特征图,分别与真值的差异构成了损失函数,利用反向传播算法可以不断优化网络。
训练完成后,只利用单目数据做输入,即可得到深度估计值和单目相机的转移矩阵 T T T(可实现视觉测距的功能)。
3.2 Image reconstruction as supervision
给定两邻近视图,已知参考视图(reference view)深度和两视图之间的 相对相机姿态 ? 的情况下,我们可以从实时视图(live view)中重建参考视图。【深度和相对相机姿态可以通过卷积网络进行估计,真实图和重建图的不一致(loss)可以用来训练网络。】
没有额外约束的单目框架会有尺度模糊问题,因此作者提出使用立体序列框架,因为含有一个通过已知立体基线设置的额外约束(将 C N N D CNN_D CNND预测的场景深度和 C N N V O CNN_{VO} CNNVO预测的相对相机运动(姿态)约束在一个共同、真实的世界尺度中)。除了仅具有一个实时视图的立体对之外,时间对还为参考视图提供第二实时视图。 多视图场景利用了立体和时间图像对可用的全部约束。
【简单来说,使用双目序列可以解决尺度模糊问题以及引入更多约束】
对于每一个训练实例,
- 一个时间对( I L , t 1 , I L , t 2 I_{L,t1},I_{L,t2} IL,t1,IL,t2)和一个立体对( I L , t 2 , I R , t 2 I_{L,t2},I_{R,t2} IL,t2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









