







目录
一、卷积神经网络应用领域
CV领域发展
应用:目标检测,分类检索,超分辨率重构,医学任务,无人驾驶,人脸识别...
传统神经网络在特征提取上的问题:
1. 权重参数矩阵大
2. 过拟合风险大
二、 卷积神经网络
1. 卷积神经网络与传统神经网络的不同
大家可以参考神经网络(深度学习,计算机视觉,得分函数,损失函数,前向传播,反向传播,激活函数)![]() https://blog.csdn.net/JamesSwifte/article/details/136848838?spm=1001.2014.3001.5501来学习神经网络的有关知识。
https://blog.csdn.net/JamesSwifte/article/details/136848838?spm=1001.2014.3001.5501来学习神经网络的有关知识。
大家想一下,神经网络的输入是一个向量,即使数据原本是矩阵,也是将其拉成一长条。
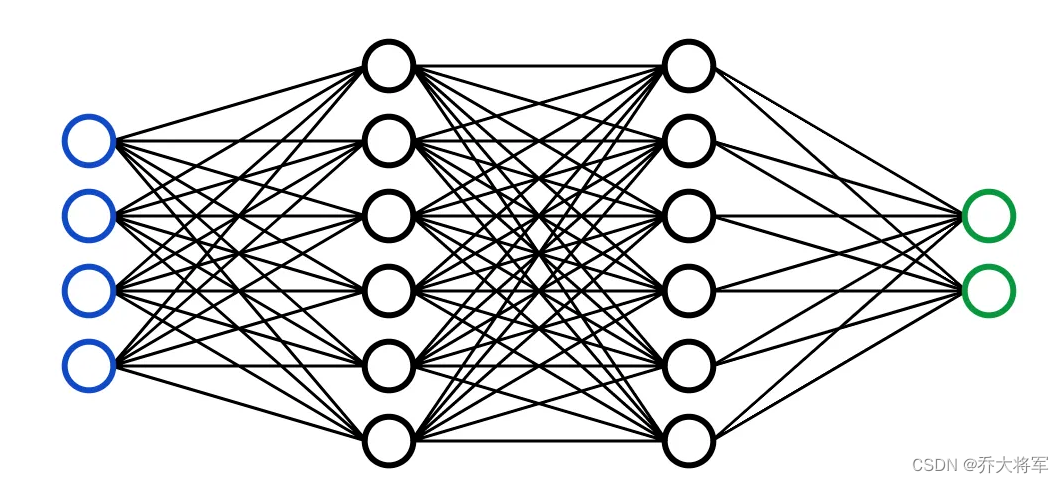
上图可以看出有4个特征输入,经过两个隐藏层,到达输出层。
那么卷积神经网络输入不在是向量,不是一条,而是张量,是矩阵。
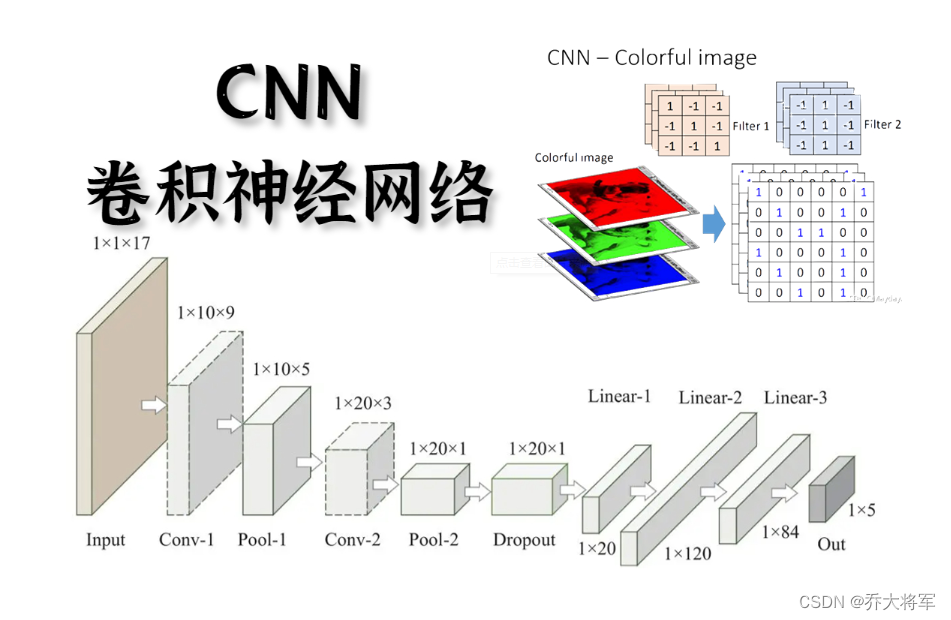
从上图可以看出输入的张量,中间经过卷积层后面加上全连接网络也就是神经网络。
2. 那么到底卷积做了什么事情呢??什么是卷积??
大家联系神经网络提取特征的过程,经过隐藏层,将输入特征值增大,减小,特征数量增多,减少,最后学习到了特征,虽然人是看不出,读不懂这样的特征。那么卷积的作用也是提取特征,而且克服了神经网络的参数过多,容易过拟合的问题。
想象一下,一张图片有主次之分,有背景,有人物,把一张图片分成一块一块的(张量),每一块都有它的代表特征,怎么得到这个特征呢???
引入卷积核(类似于神经网络中的权重参数矩阵)
 卷积核在定义了大小后,初始化类似与神经网络中的权重参数矩阵,然后在迭代优化中(反向传播)更新,达到最佳的一组。
卷积核在定义了大小后,初始化类似与神经网络中的权重参数矩阵,然后在迭代优化中(反向传播)更新,达到最佳的一组。
3. 卷积特征值的计算方法
数据与卷积核是怎么来做运算呢?答案是做内积,各自位置上的值相乘然后再相加。
上图的列子里:
而且有3个颜色通道,每个颜色通道进行计算,最后相加。
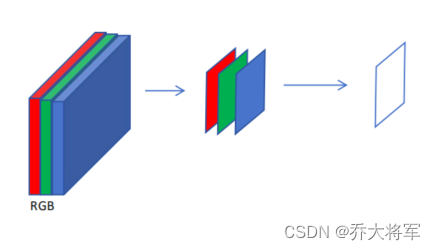
4. 得到特征图的表示
大家看上图的列子,用了一个5*5*3的卷积核得到了一个,特征图。一个特征图效果可能不好,那么想要得到多个特征图怎么做呢?答案是用多个5*5*3的卷积核。而且每个卷积核都不同,这样可以多尺度,多粒度进行特征提取。

而且为了提高提取特征的精确率,采用多次卷积的方式。

5. 卷积层涉及的参数
1. 滑动窗口步长 很显然步长小:粒度细,特征丰富 步长大:粒度粗,特征少
2. 卷积核尺寸 一般3X3
3. 边缘填充 我们发现一个问题:当步长太长,边缘的点被利用的次数明显比在里面的点的次数少,那么是边缘的点就不重要了吗?不是,经过边缘填充,将边缘点变为中间点,多利用几次,一定程度上弥补了边界信息缺失的问题(一般加0)加一圈。
4. 卷积核的个数 增大特征丰富度,有几个核就可以得到几个通道的特征图
6. 特征图尺寸的计算
在卷积后怎么计算卷积后的结果呢?即wight,hight,channel呢?
卷积结果计算公式:
其中表示输入的宽度,长度;
表示输出特征图的宽度,长度;
表示卷积核长和宽的大小;
表示滑动窗口的步长;
表示边界填充(加几圈)。
7. 参数共享
采用卷积神经网络可以大大降低参数的数量。例如:一张32*32*1的灰度图,用神经网络由输入层1024个特征到第一隐藏层784个特征,中间的权重参数一个需要1024*784=8028816个。而采用卷积神经网络需要一个7*7的卷积核,所需的参数49个。
那么如果对于每一区域的卷积核参数要不一样吗?如果不一样,那么参数就会像神经网络一样非常庞大。所以对每一个区域选择相同的卷积核。这就是参数共享。这是卷积神经网路非常重要的一个特点。
8.池化层的作用
池化层的作用:并不是所有的特征都重要,选择一些留下来。这个操作不涉及矩阵的计算。
池化方法:最大池化(选择该区域内最大值),最小池化(选择该区域内最小值),平均池化(该区域内平均值)
经过实验人员的验证最大池化效果最好,一般选择最大池化方式。 
9.整体网络架构
卷积的作用就是提取特征,所以和神经网络的隐藏层一样卷积层可以很多,但是唯一不同的是在卷积后,要加入全连接层,即神经网络的隐藏层后,再输出。而且卷积,非线性变换(relu),池化一般配套使用。
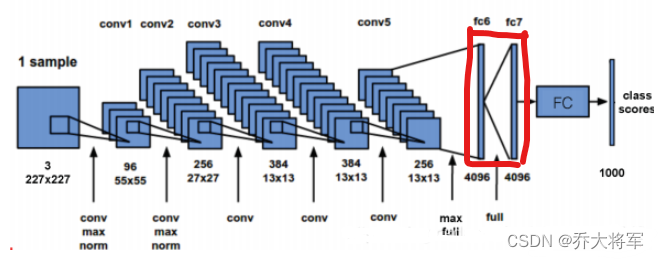
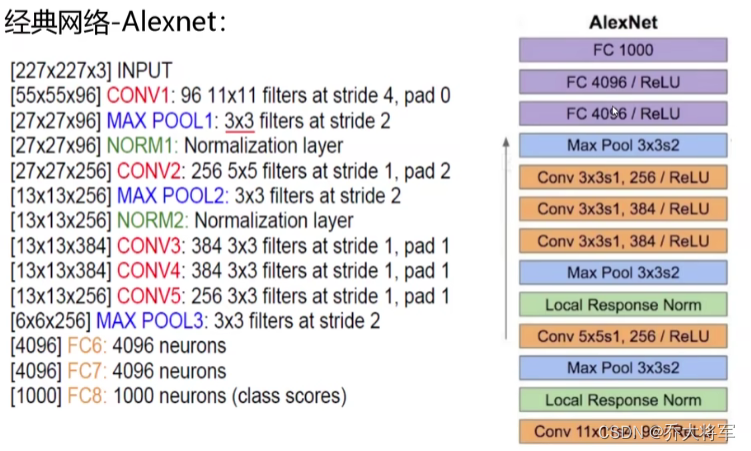
10.经典网络架构
做了解

11. 残差神经网络(Resnet)
深层网络遇到的问题:当卷积核的个数,网络的深度到达一定值后,网络的结果没有出现提升,反而越来越差。这是深度学习的末日,意思是深度学习就到此为止了吗?

分析一下问题:当深度越深效果反而不好,是因为下一层特征提取是在上一层提取的特征上进行的,不能保证效果越来越好的。
解决方案:有学的好的学的不好的,要保留学的好的,同时不能让学的不好的影响整体效果。
残差神经网络:
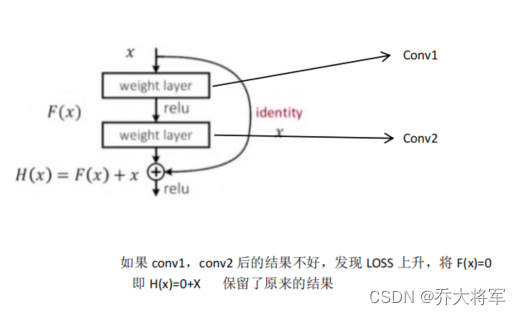

在上图我们可看到残差网络在18层和34层在误差上比普通网络有明显的下降。
12.感受野
在卷积神经网络中,感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的。神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着它可能蕴含更为全局,语义层次更高的特征;相反,值越小则表示其所包含的特征越趋向局部和细节。因此感受野的值可以用来大致判断每一层的抽象层次。
卷积层(conv)和池化层(pooling)都会影响感受野,而激活函数层通常对于感受野没有影响,当前层的步长并不影响当前层的感受野,感受野和填补(padding)没有关系。
公式求取的感受野通常很大,而实际的有效感受野(Effective Receptive Field)往往小于理论感受野,因为输入层中边缘点的使用次数明显比中间点要少,因此作出的贡献不同,所以经过多层的卷积堆叠后,输入层对于特征图点做出的贡献分布呈高斯分布形状。



三、卷积神经网络实战
构建卷积神经网络
卷积网络中的输入层与传统的神经网络有区别,需要重新设计,训练模块基本一致
1.导入包
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline2.读取数据
分别构建训练集和测试集(验证集)
DataLoader来迭代取数据
#定义超参数
input_size = 28 # 图像的总尺寸28*28
num_classes = 10 #标签的种类数
num_epochs = 3 #训练的总循环数
batch_size = 64 # 一个批次的大小,64张图片#训练集
train_dataset = datasets.MNIST(root='./data',
train = True,
transform=transforms.ToTensor(),
download = True)
#测试集
test_dataset = datasets.MNIST(root='./data',
train = False,
transform=transforms.ToTensor(),
)
#构建batch数据
train_loader = torch.utils.data.DataLoader(
dataset = train_dataset,
batch_size = batch_size,
shuffle = True
)
test_loader = torch.utils.data.DataLoader(
dataset = test_dataset,
batch_size = batch_size,
shuffle = True
)3. 构建网络
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Sequential( # 输入大小 (1,28,28)
nn.Conv2d(
in_channels = 1, #灰度图 一个颜色通道
out_channels = 16, #要得到几个特征图
kernel_size = 5, #卷积核大小
stride = 1, #步长
padding = 2, #如果希望卷积后的大小跟原来一样,设置padding=(kernel_size-1)/2 if stride = 1
),
nn.ReLU(), #激活函数
nn.MaxPool2d(kernel_size=2), #进行池化层操作(2x2 区域),输出结果为:(16,14,14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(16,32,5,1,2),
nn.ReLU(), #激活函数
nn.MaxPool2d(2), #进行池化层操作(2x2 区域),输出结果为:(32,7,7)
)
self.out = nn.Linear(32*7*7,10) #全连接层得到结果
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0),-1) #flatten操作,结果为:(batch_size,32*7*7)
output = self.out(x)
return output4. 训练网络
#定义一个准确率作为评估标准
def accuracy(predictions,labels):
pred = torch.max(predictions.data,1)[1]
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels)
#实例化
net = CNN()
#损失函数
criterion = nn.CrossEntropyLoss()
#优化器
optimizer = optim.SGD(net.parameters(),lr=0.01) # 定义优化器,普通的随机梯度下降算法
loss_num = []
#开始循环训练
for epoch in range(num_epochs):
#当前epoch的结果保存下来
train_rights = []
for batch_idx,(data,target) in enumerate(train_loader):
net.train()
output = net(data)
loss = criterion(output,target)
loss_num.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = accuracy(output,target)
train_rights.append(right)
if batch_idx % 100 == 0 :
net.eval()
val_rights = []
for (data,target) in test_loader:
output = net(data)
right = accuracy(output,target)
val_rights.append(right)
#准确率计算
train_r = (sum([tup[0] for tup in train_rights]),sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]),sum([tup[1] for tup in val_rights]))
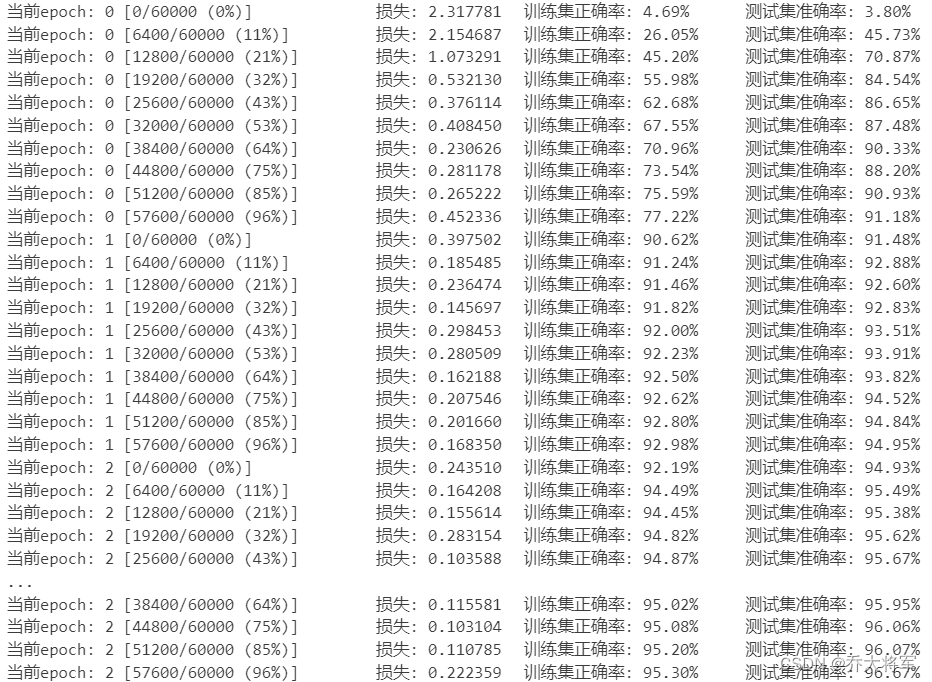
print('当前epoch: {} [{}/{} ({:.0f}%)] \t损失: {:.6f}\t训练集正确率: {:.2f}%\t测试集准确率: {:.2f}%'.format(
epoch,batch_idx*batch_size,len(train_loader.dataset),
100 * batch_idx / len(train_loader),
loss.data,
100 * train_r[0]/ train_r[1],
100 * val_r[0] / val_r[1]
)
)
5.查看损失结果
plt.figure(figsize=(10,4))
with torch.no_grad():
plt.plot(loss_num[:])
plt.xlabel('iterion')
plt.ylabel('loss')
plt.show()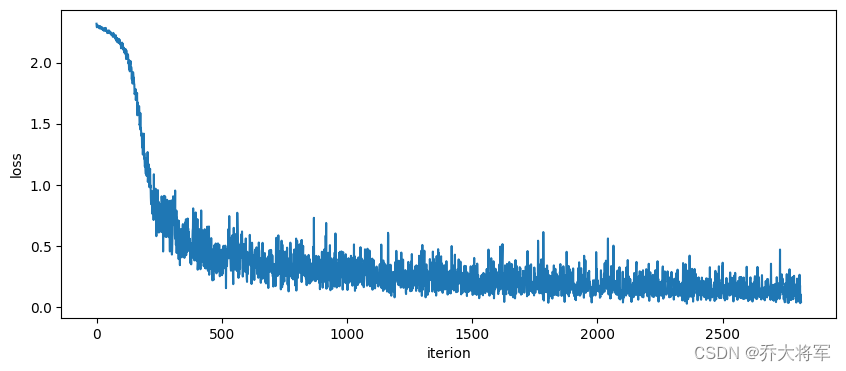














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









