







目录
一、 卷积神经网络的演变
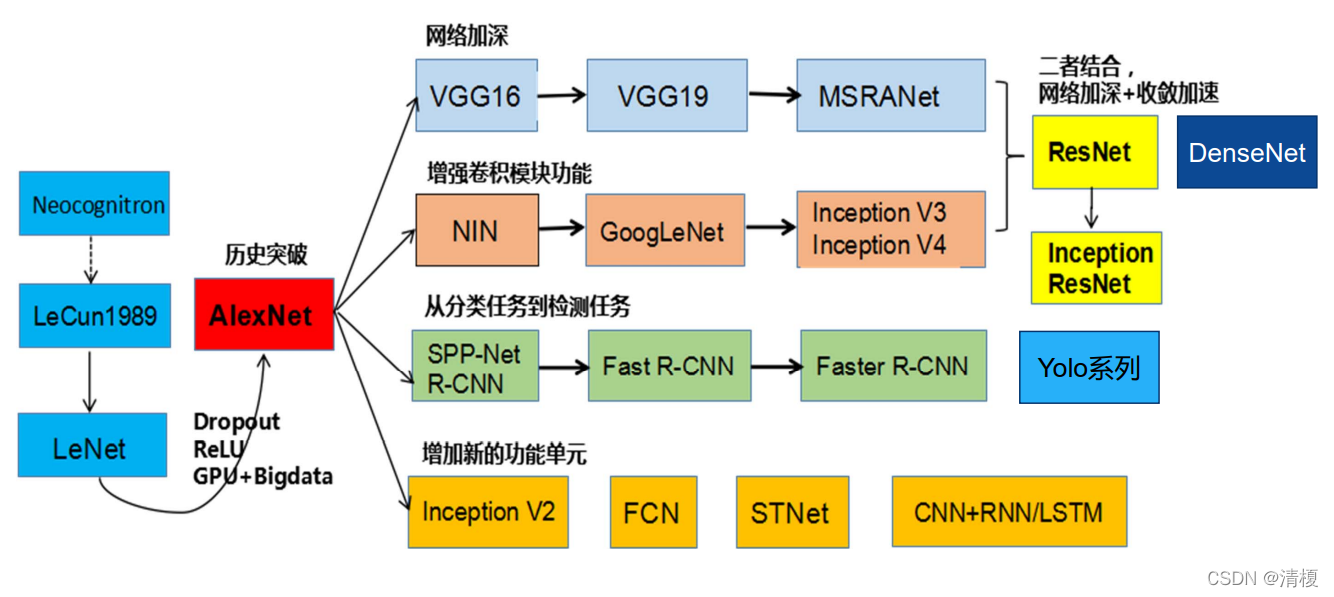
二、经典神经网络
2.1 LeNet5
2.1.1 背景
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, November 1998.
LeNet5是由Y.LeCun等人提出的,主要进行手写数字识别和英文字母识别。
很经典,虽然小,但是模块齐全。
2.1.2 结构
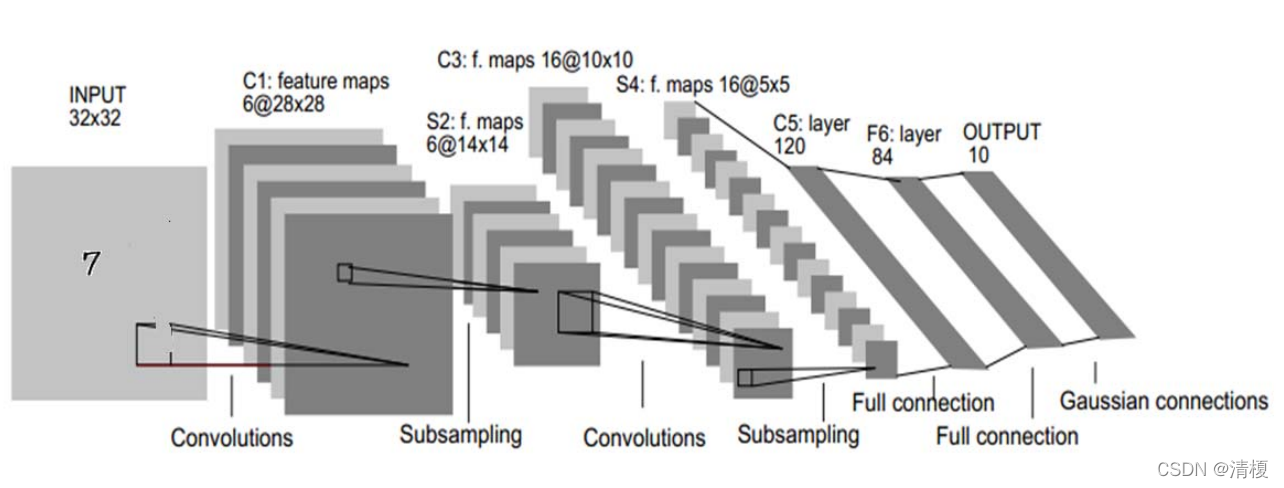
1. 输入层
32X32的图片
2. C1层(卷积层)
采用了6个5X5的卷积核,且步长为1(32-5+1 = 28)得到了6个28X28的特征图。此时神经元个数为6X28X28 = 784 个。
3. S2层(下采样层)
进行了平均池化,池化核2X2,步长为2(无重叠移动),得到6个14X14的特征图。平均池化后加乘一个权重,加上一个偏置作为激活函数的输入,激活函数的输出作为下一层的输入。
4. C3层
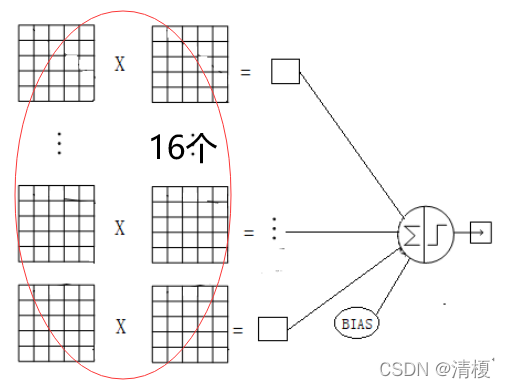
采用了16个5X5的卷积核组,且每个卷积核组中卷积核数量不同(前6个卷积核个数为3,中间6个为4,之后3个为4,最后一个为4),如下图所示:
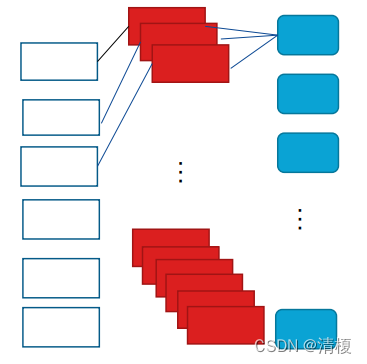
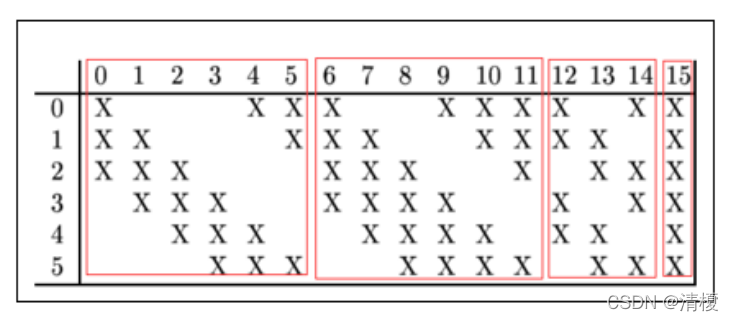
加偏置和激活函数后得到16个10X10的特征图(14-5+1 = 10),此时神经元数量为1600。
此处有个疑问,为什么要设计卷积核组中卷积核数量不同?应该是有助于减少参数数量,降低模型复杂度。
5. S4层
对16个10X10的特征图进行池化核为2X2,步长2的最大池化,得到的最大值乘以一个权重参数,再加上一个偏置参数作为激活函数(sigmoid)的输入,得到16张 5*5的特征图,神经元个数已经减少为16*5*5=400。
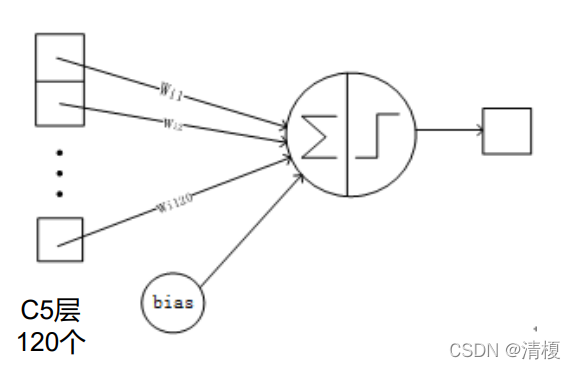
6. C5层
用16个5*5的卷积核进行卷积,乘以一个权重参数并求和, 再加上一个偏置参数作为激活函数 (sigmoid)的输入,得到1*1(5- 5+1=1)的特征图。
然后我们希望得到120个特征图,就要用总共120个5*5卷积核组(每个组16 个卷积核)进行卷积,神经元减少为 120个。
与C3层不同的是,这里的连接是一种全连接。
7. F6层
全连接层,有84个节点,对应的是一个7X12的比特图,如下所示:

特征图大小与C5一样都是1×1,与C5层全连接。计算输入向量和权重向量之间的点积,再加上一个偏置,然后将其传递给sigmoid 函数得出结果。
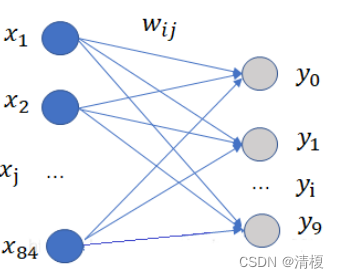
8.Output层(全连接层)
共有10个节点,分别代表数字0到9, 如果节点i的输出值为0(比如向量为[0,1,1,1,...1],识别为数字0),则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。
假设x是上一层的输入(F6层的84个神经元),y是RBF的输出,则RBF输出的计算方式是:

的值由i的比特图编码确定,i从0到9,j取值从0到84-1。 RBF输出的值越接近于0,表示当前网络输入的识别结果与字符i 越接近。
2.1.3 总结
卷积核大小、卷积核个数(特征图需要多少个)、池化核大小和步长等这些参数都是变化的,这就是所谓的CNN调参,需要学会根据需要进行不同的选择 。
后续补上LeNet5识别首先数字的代码。
2.2 AlexNet
2.2.1 背景
获得ImageNet LSVRC-2012(物体识别挑战赛)的冠军,1000 个类别120万幅高清图像,Error: 26.2%(2011)→15.3%(2012)。
AlexNet确定了CNN在计算机视觉领域的王者地位。
A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012
2.2.2 创新点
- 首次成功应用ReLU作为CNN的激活函数。
- 使用Dropout丢弃部分神元,避免了过拟合。
- 使用重叠MaxPooling(让池化层的步长小于池化核的大小),一 定程度上提升了特征的丰富性。
- 使用CUDA加速训练过程。
- 进行数据增强,原始图像大小为256×256的原始图像中重复截取 224×224大小的区域,大幅增加了数据量,大大减轻了过拟合, 提升了模型的泛化能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









