







AI平台与泛AI平台
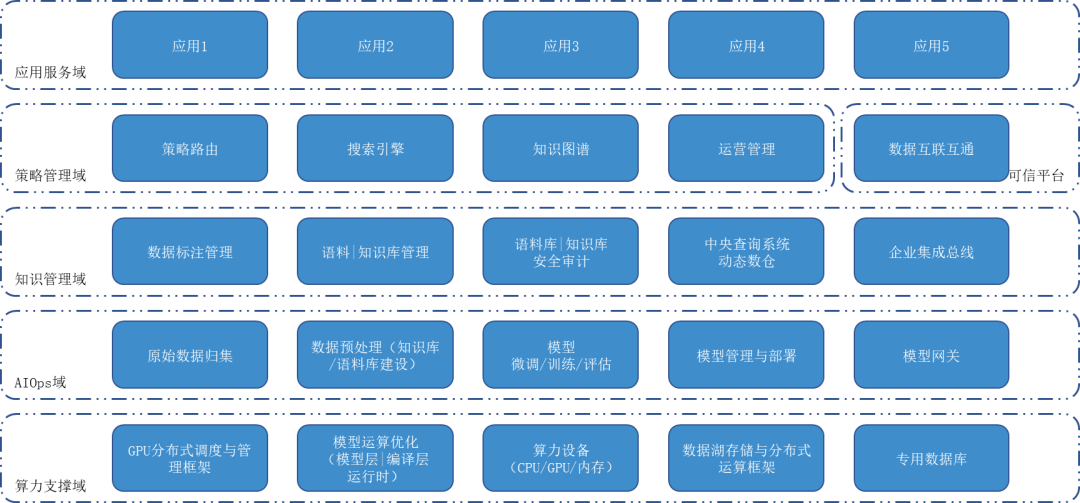
AI平台的架构涉及的方面很广,按照系统领域设计可以分为应用服务域、策略管理域、知识管理域、AIops域和算力支撑域。按照基础架构的角度可以分为算力、存储、网络包括GPU集群的调度与搭建。
从业务架构的角度而言,泛AI平台的范围从数据清洗之后开始,覆盖动态数仓、语料库管理、模型训练、模型管理、应用框架、模型部署以及资源调度的整个周期。此处对于数据采集、清洗、治理和加工则不在这个平台范围之内。大模型犹如哪吒一般,成熟的搜索引擎技术和知识图谱技术则犹如混天绫和风火轮。设计得当的LLMOps平台则为乾坤圈为其大幅提升整体的武力值。
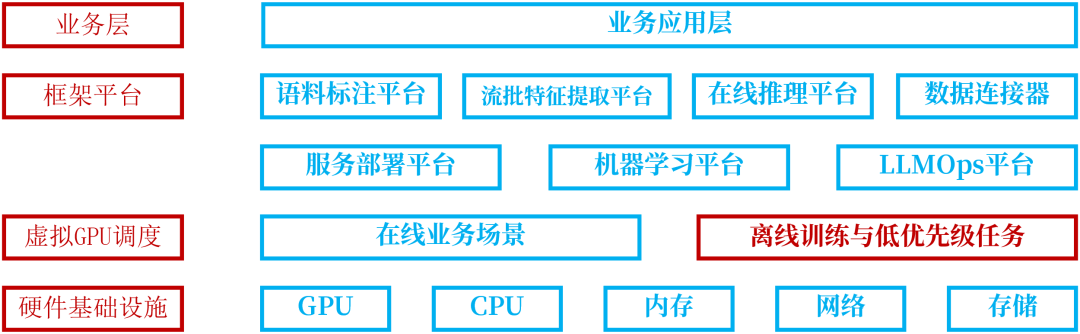
传统的云原生更加关注的是服务动态扩容,资源池以及一键发布等功能,携带GPU资源的AI平台则优先要考虑GPU的资源利用效率,确保在线任务与近离线任务之间的合理调度。再者也要考虑不同公司的GPU集群配置,这些配置有可能存在单机单卡、多机多卡、异构卡等。最后,需要考虑在故障和异常的场景下如何快速恢复。
AI平台的架构设计和传统云原生的架构设计稍微有点区别,多了一层GPU的资源调度,所以在设计量产架构的时候就需要考虑额外的因素。为了更好的讲述,专栏将会如何构架高效的GPU集群架构入手,阐述GPU集群在算力调度、存储和网络通讯中架构的实际运用。分析设计面临的挑战以及如何应对。让读者明白了之后,在回到AI平台的架构设计,以便有更加立体认知。
目前Nvidia的研发生态十分成熟与完善,而且具有很好的普适性,因此本文将以Nvidia为例,其他显卡的分析将放在额外的文章分析。

















 3886
3886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









