







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
键值(KV)缓存对于加速基于Transformer的大型语言模型 (LLM) 的解码至关重要。多查询注意力(MQA)和分组查询注意力(GQA)通过允许多个查询头共享单个键/值头,可以有效地减少 KV 缓存大小。跨层注意力(CLA)通过在相邻层之间共享键和值头来进一步实现这一点,从而在保持准确性的同时将 KV 缓存大小减少 2 倍。CLA针对位于传统帕累托前沿的MQA进行改进,在推理过程中实现更长的序列长度和更大的批量大小。

MQA和GQA
Transformer模型中的注意力机制允许解码器专注于输入中最相关的部分,从而提高模型对复杂文本的理解。它的工作原理类似于数据库查询,其中一个单词(Query)被查询或与所有其他单词(Key)的相关性进行比较,结果是检索到的“值”的加权和,其中包含相关性信息。由于每个单词都会与序列中的所有其他单词进行比较,因此查询、键和值可以被视为单词本身——但它们通过可学习的权重矩阵(Wq、Wk 和 Wv)进行区分,这权重矩阵由神经网络训练以提供更好的上下文。
在“我帮助老奶奶过马路”这样的句子中,“我”和“老奶奶”之间存在关系,而“老奶奶”和“过马路”这个动作之间也存在另一个重要的联系。为了解决这个问题,Llama 13B和Llama2 7B等模型中使用的多头注意力机制(MHA)多次并行应用上述注意力机制,以捕捉数据中的不同类型的关系。
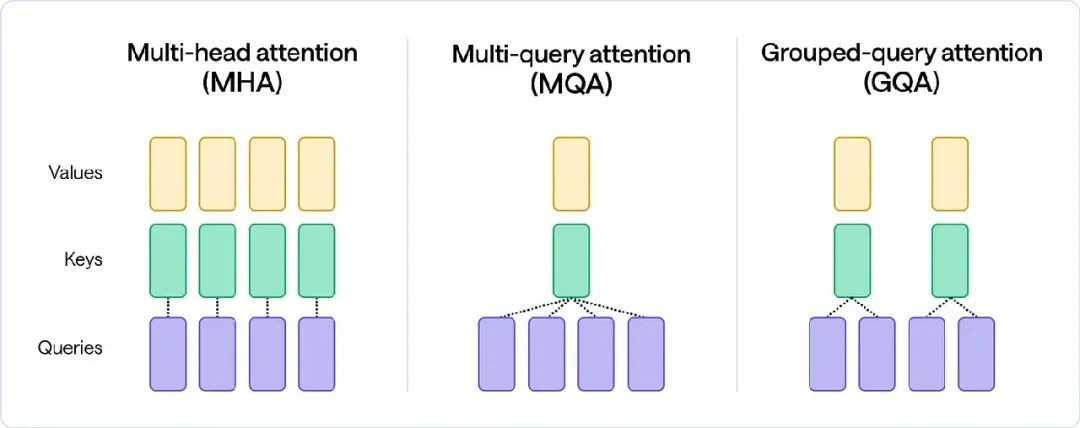
多头注意力机制包含多个注意力层,每个注意力层都保存Query、Key和Value的权重矩阵。虽然这种复杂性可以捕捉到更多细微差别,但MHA的最大缺点在于它在推理过程中对内存和带宽的压力。由于必须在每个解码器步骤中加载所有注意力键和值,因此这种内存和带宽开销可能成为严重的瓶颈。
多查询注意机制 (MQA)较为激进,其中多个查询头只存在一个键值头。虽然MQA显着减少了内存负载并提高了推理速度,但它的代价是质量较低和训练不稳定。
分组查询注意机制 (GQA)在MHA的质量和MQA的速度之间取得了良好的平衡。GQA使用键值头的数量作为1(MQA)和查询头数量(MHA)之间的中间值。由于要加载的键值对较少,内存负载和计算复杂度均会降低。

模型架构
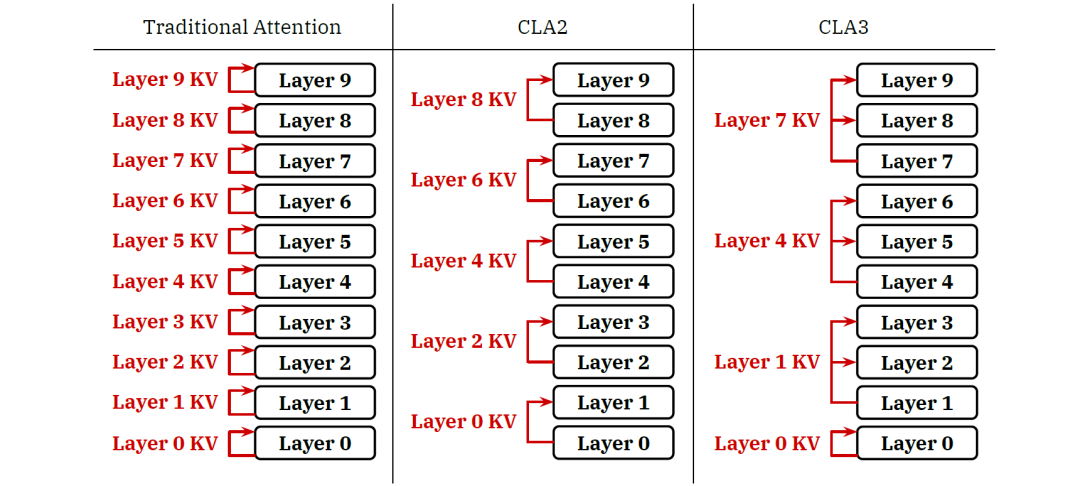
受到MQA和GQA的启发,MIT研究团队提出了Cross-Layer Attention。从图中可以看出两层之间有一层直接使用上一层的kv参数。
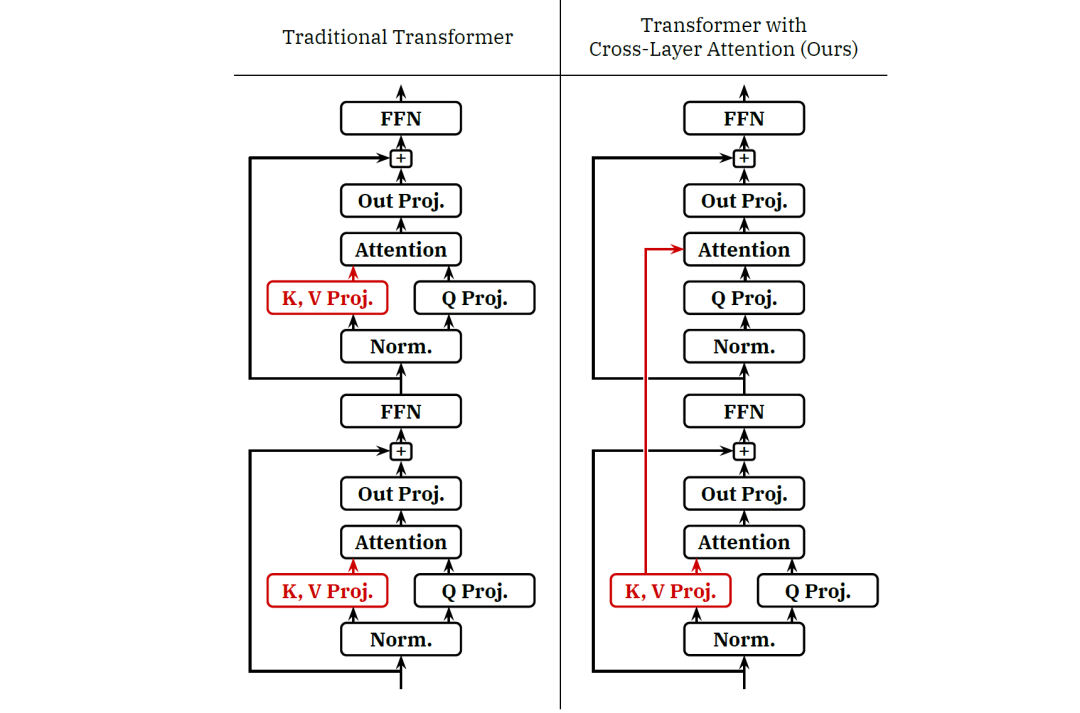
可以看到在CLA中,只有模型中的一部分层会将输入和KV矩阵参数进行计算,而哪些被跳过的注意力机制层则重复使用空投过来的KV激活值,这意味着真正进行KV运算的层可以通过缓存结果空投至后层。与传统架构相比,被空投的那层少了KV参数矩阵,因此CLA能够减少对内存的使用。
当然,CLA其实是一种空投的策略,它还是可以和MQA、GQA、MHA进行组合使用。此外,与GQA的机制不同,CLA 可以改变共享每个KV参数矩阵的层数(即将数据空投的层数)。不同的共享因子形成不同CLA配置,例如CLA2,它在一对相邻层之间进行数据空投;CLA3,它是在3层之间共享参数,即最底下的那层将计算好的数据直接空投至上面两层。如下图所示:
正因为参数少了,所以在开销方面的指标肯定提升不少,当然是否还得确保准确率不变。提升的指标如下:
-
KV 缓存内存:CLA 显着减少了 KV 缓存内存占用量,减少的倍数等于共享因子
-
训练内存占用:CLA 减少了训练期间具体化的中间 KV 激活张量的内存占用,尽管对于 GQA 和 MQA 模型,此类 KV 张量与模型的隐藏状态和 MLP 激活相比通常很小。
-
模型并行性:CLA 与标准完全兼容并行技术,可用于跨多个加速器分片模型权重。
-
参数和FLOP:由于CLA 减少了模型中KV投影块的总数,因此CLA 略微减少了模型中参数的数量以及前向或后向传递期间所需的FLOP计算总量。
-
解码延迟:在完整的LLM服务堆栈的背景下,CLA可以实现比其他方式更大的批量大小和更长的KV缓存持久时间,可以减少推理延迟。
-
核心Attention延迟:与MQA和GQA不同,CLA对每个解码步骤中Attention机制消耗的内存带宽没有直接影响。

组合性能评估
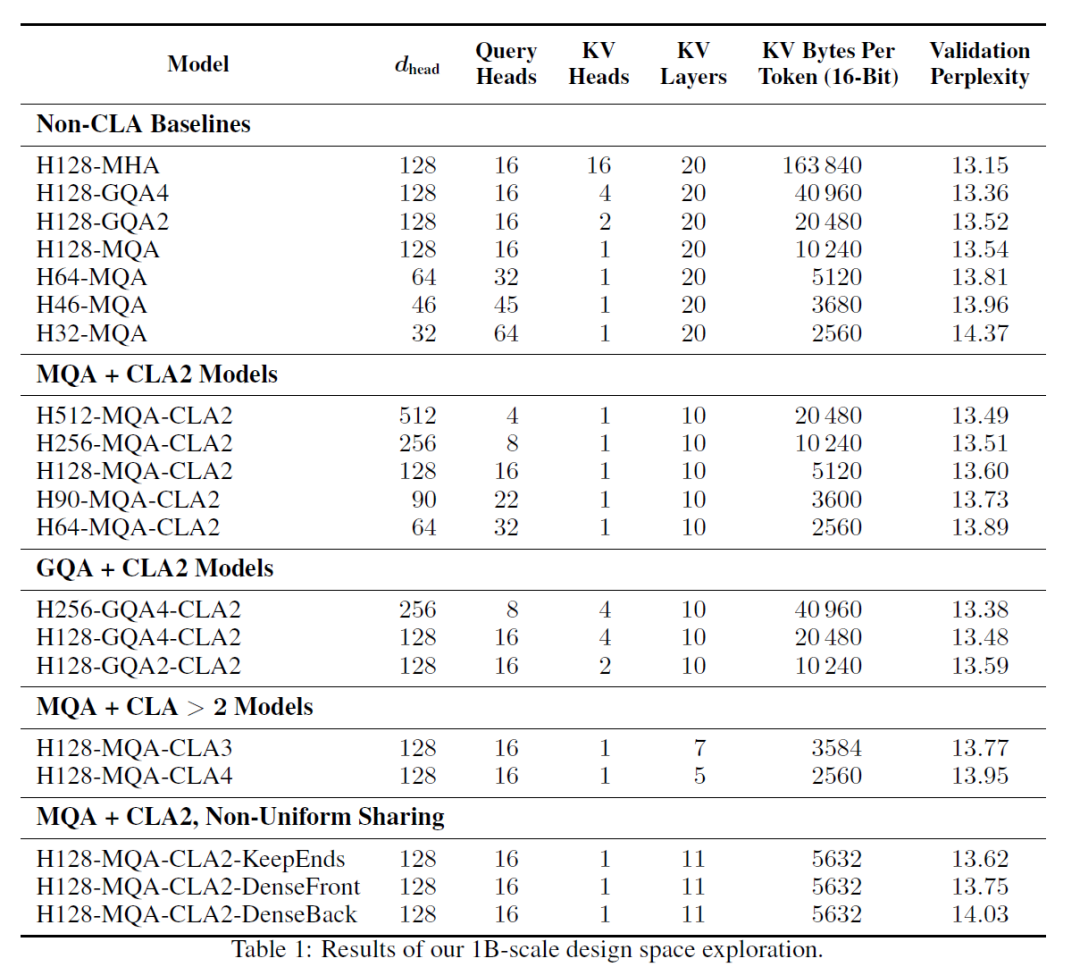
在众多的实验之中,MQA结合CLA2表现得最好。研究人员一共针对MQA 和CLA2训练了五个模型。将MQA-CLA2模型的Head Size从dhead = 512 降低到 dhead = 64,从而使能够与一系列具有不同KV缓存容量的非CLA 基线模型进行比较。
与需要相同数量 KV 缓存的基线模型相比,MQA-CLA2型能够实现更好的困惑度,从而提高了准确性/记忆帕累托前沿。
上图展示了使用和不使用 CLA 时的准确性/内存Pareto前沿图。MQA-CLA2模型的头部尺寸dhead ∈ {64, 90, 128} 能够与基线MQA模型的KV缓存内存占用相匹配。头部尺寸 dhead ∈ {32, 46, 64},同时实现 0.21-0.48 点范围内的困惑度(perplexity)显着改善。 此外,MQA-CLA2模型具有 dhead ∈ {256, 512} 的大头部尺寸,能够与dhead=128 的MQA和GQA2基线的KV缓存相匹配,同时实现0.03点的小幅困惑度改进。
那为什么是MQA+CLA2是最优的呢?单独的MQA和单独的GQA都能够找到解释。而CLA的背后的逻辑是什么就需要交给读者去判断了,因为只有找到CLA的内在,才能真正的判断这种架构的合理性。















 4456
4456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









