







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
Embeddings
Embeddings会分为两个章节,前部分主要还是放在常规方法总结,后者主要放在神经网络技术。其实这个英文单词不难理解,就是将对象用数字标识描述。其实一直纠结是否要讲述这个话题,因为可深可浅。
若要用一句话概括,就是给输入分配一个数字标识,可以是一个整数数值也可以是一个向量。不过最重要的目的是在模型训练的过程中能够高效且有效的学习参数。
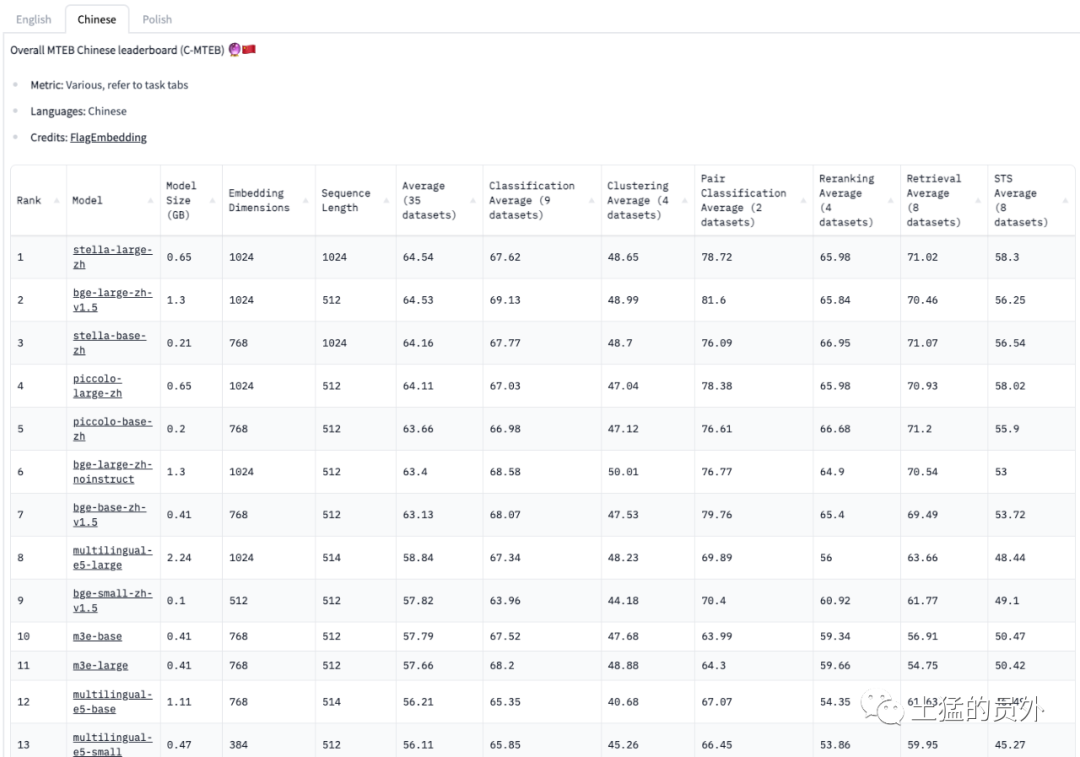
这里需要解释下向量,例如apple可以使用三维的向量[0.95,0.23,-0.23]来表示,也可以使用四维的向量来表示[0.95,0.23,-0.23,0.12],请注意下图中Embedding Dimensions这一列,不同模型的Embedding维度不一

one-hot encoding
这是一种最直观,也是最不需要动脑子的编码模式。假如有10000个对象,那么每个对象就是一个10000维的向量,朴素也暴力。例如apple这个词在第50个,那么apple对应的编码就是:10000维的向量,这个向量除了第50个为1之外,其余的数值均为0。
#词汇表Vocabulary:{'mat', 'the', 'bird', 'hat', 'on', 'in', 'cat', 'tree', 'dog'}#词汇表中词汇和位置的映射Word to Index Mapping:{'mat': 0, 'the': 1, 'bird': 2, 'hat': 3, 'on': 4, ……}#输入一句话的编码矩阵One-Hot Encoded Matrix:cat: [0, 0, 0, 0, 0, 0, 1, 0, 0]in: [0, 0, 0, 0, 0, 1, 0, 0, 0]the: [0, 1, 0, 0, 0, 0, 0, 0, 0]hat: [0, 0, 0, 1, 0, 0, 0, 0, 0]dog: [0, 0, 0, 0, 0, 0, 0, 0, 1]on: [0, 0, 0, 0, 1, 0, 0, 0, 0]the: [0, 1, 0, 0, 0, 0, 0, 0, 0]mat: [1, 0, 0, 0, 0, 0, 0, 0, 0]bird:[0, 0, 1, 0, 0, 0, 0, 0, 0]in: [0, 0, 0, 0, 0, 1, 0, 0, 0]the: [0, 1, 0, 0, 0, 0, 0, 0, 0]tree:[0, 0, 0, 0, 0, 0, 0, 1, 0]
这种编码方式的缺点显而易见,One-hot编码会产生高维向量,使其计算成本高昂且占用大量内存,尤其是在词汇量较大的情况下;它不捕捉单词之间的语义关系;它仅限于训练期间看到的词汇,因此不适合处理词汇表之外的单词。

Feature Vector
第二种编码方式是基于特征,其实彩色图片是一种很好的例子。做过视觉学习的都知道彩色图片常见的有三种通道(三维向量),分别代表RGB(红绿蓝)。三种颜色取不同的值就可以合成任意一个位置的色块。举个例子橘色其实就可以使用orange = [1, .5, 0]来表示。说白了就是每个维度代表一种特征,然后组合起来就能代表一个输入对象。

为了加深大家的理解,上图这个例子更加直观。假如约定的编码只有4个维度,分别是“春夏秋冬”,那么上图右侧框框中的事物都可以使用下面的编码来替代。具体的意思就是这个物体是不是在四季节出现,当然学过数学组合的都知道这种编码方式只能将整个世界的对象分成16类。但是它已经开始在编码中存储对象之间的某种关系。
emoji = [spring, summer, autumn, winter]🌳 = [1, 1, 1, 0]🍂 = [1, 0, 0, 0]🍁 = [1, 0, 0, 0]🌻 = [0, 1, 0, 0]🎁 = [0, 0, 1, 1]🎅 = [0, 0, 1, 1]...etc
这种编码模式更加符合人脑,人类在记忆某种事物的时候其实也是某种编码,例如看到笔,一般会浮现它的形状,属性和相关的事物,例如纸张。

Document Vector
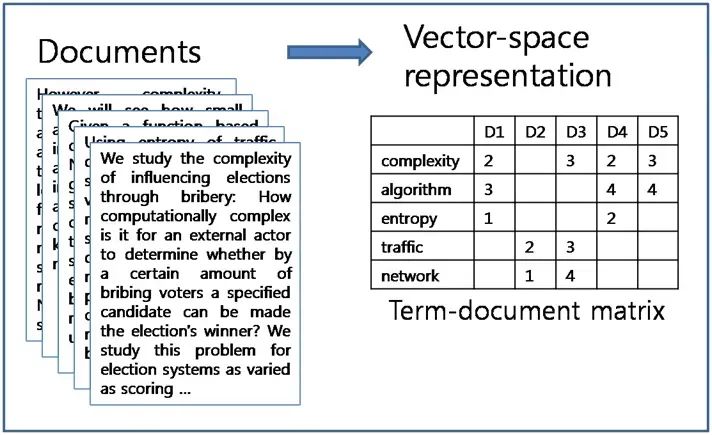
换个思路,假如收集了大量的文章,然后将文章里面的字词在文章中出现的次数做个标记。可以得到如下的矩阵:每一列代表着文章编号,每一行代表某个词,通过观察图片你就会发现其实traffic和network是不是有点相似,按照这个编码其实也是一种思路。

Co-occurrence Vector
顺着刚才的思路,其实还有一种编码的办法:可以将文章按照特定的长度进行窗口的滑动,然后统计在这个窗口里面单词之间的关联次数。下图给出例子,从其中可以发现其实data和mining还是挺相似的。这种编码的好处在于这种类型的embedding可以准确地捕获单词的使用含义(毕竟单词的含义会根据使用的时间、社区和上下文而变化)。


Neural Embedding
除了基于传统的统计学方法,其实可以采用神经网络来帮助自动化的抽取信息,方法很多。为了帮助大家更好的理解,这里先引入较早机器学习的一个术语,自编码器。其实它的历史很悠久,只不过到近期才被发扬光大而已。
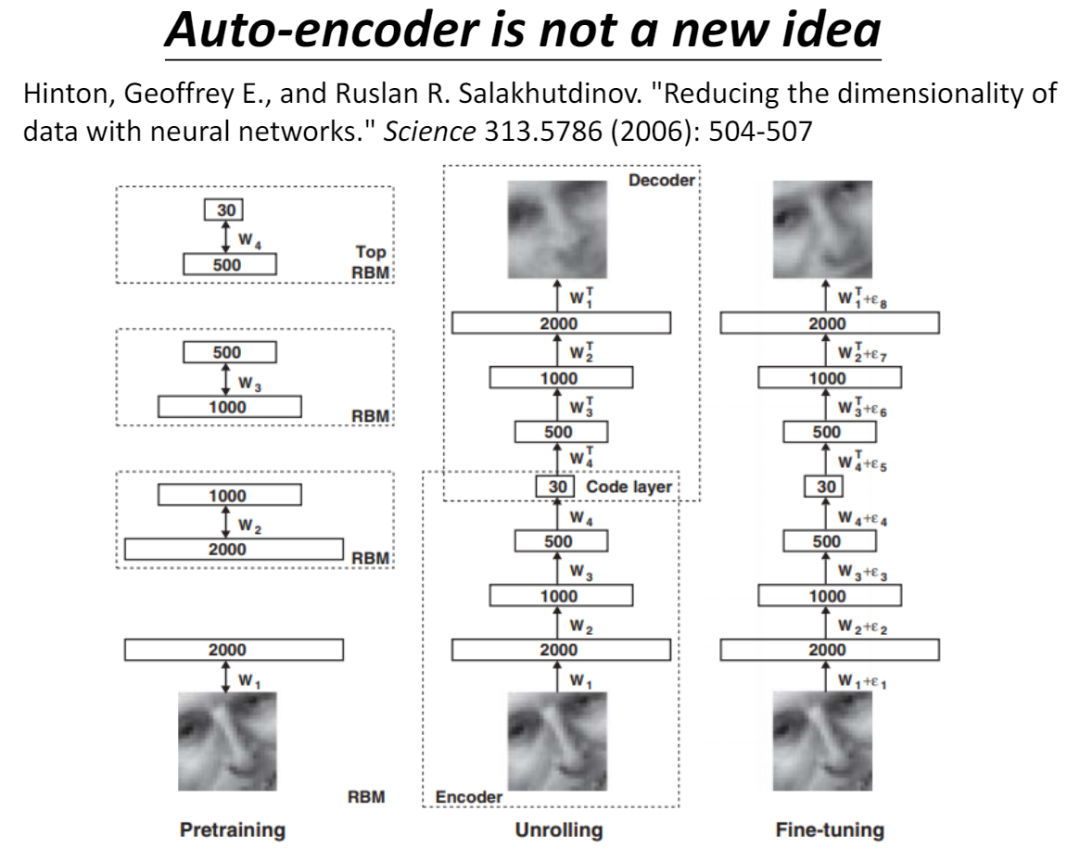
如何理解自编码器呢,请看下图:
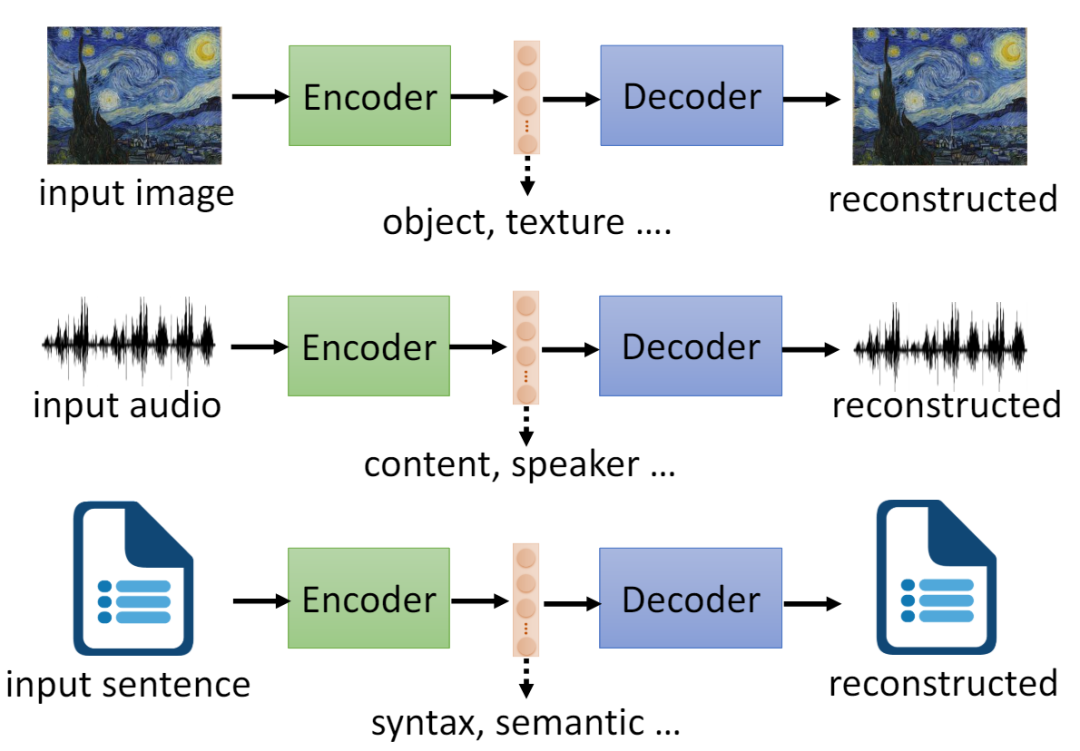
当输入一副图、一段语音或者一段文字的时候,通过绿色部分的神经网络,然后输出一个向量,紧接着再将这个向量输入紫色部分的神经网络,紫色部分的输出为重建之后的图、语音或者文字。最后用输出和真实值对比出差异反过来调整两个神经网络的参数。如此循环!
聪明的你一定反应过来了,要是重建之后的正确率很高的话。那么中间变量是不是经过压缩的向量,代表了原图,原语音或者原文。对了!这个就是自编码器。
那么中间的向量代表什么,其实是可以的解释。以输入“图片”为例,中间的向量有些维度描述对象特征,有些描述了材质。有人曾经做过实验,语音通过自编码器之后,中间向量有一部分代表内容,一部分代表音调。取一段中文和一段日文的语音输入编码器,然后将两个向量拆分组合,是可以重建出日语说中文。
如何用神经网络用于Embedding,下文会展开详细讲解。整体的基本思路还是在于将单词的上下文和情景信息,通过神经网络的参数训练进行编码。















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









