








斯坦福2024人工智能报告解读为通识性读物,而论文精读则围绕着行业实践和工程量产。若在阅读过程中有知识盲区,可以回到如何优雅的谈论大模型重新阅读。若需构建生产级别的AI架构则可关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。

代理能力评估
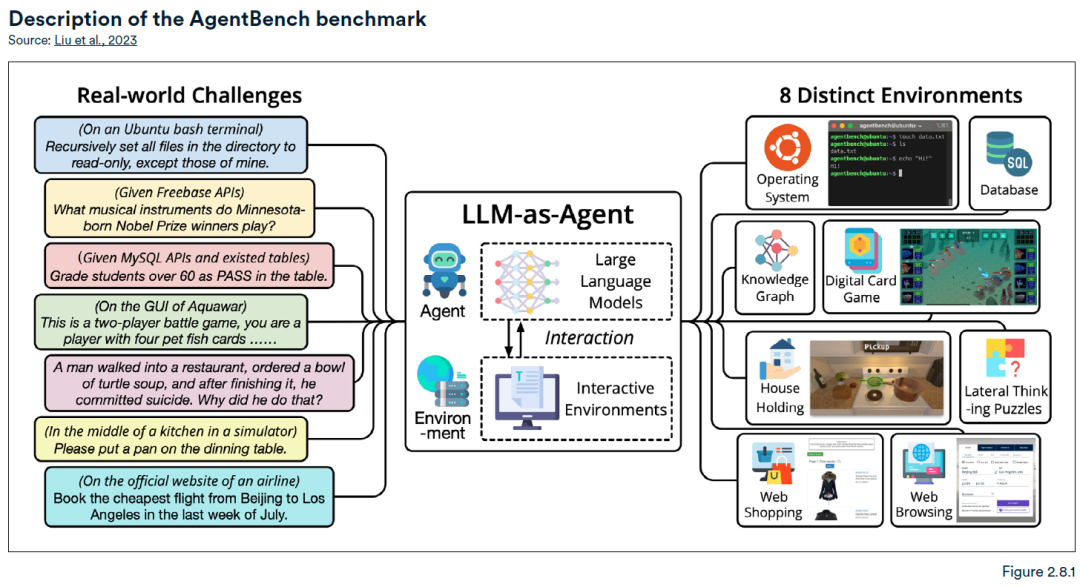
AgentBench评估基准通常是用来评估大模型在常规任务中作为代理的能力表现,该基准包含八种不同的交互式设置,包括 Web 浏览、在线购物、家庭管理等等,下图举例了大模型在现实生活中的应用场景,如,通过对大模型输入“预订7月最后一周从北京到洛杉矶的最便宜航班”后,大模型作为代理在航空公司官网执行输入指令。
该研究评估了超过25种基于大型语言模型(LLM)的代理,其中包括基于OpenAI的GPT-4、Anthropic的Claude 2以及Meta的Llama 2构建的代理。

表现最好的是GPT-4总分为 4.01
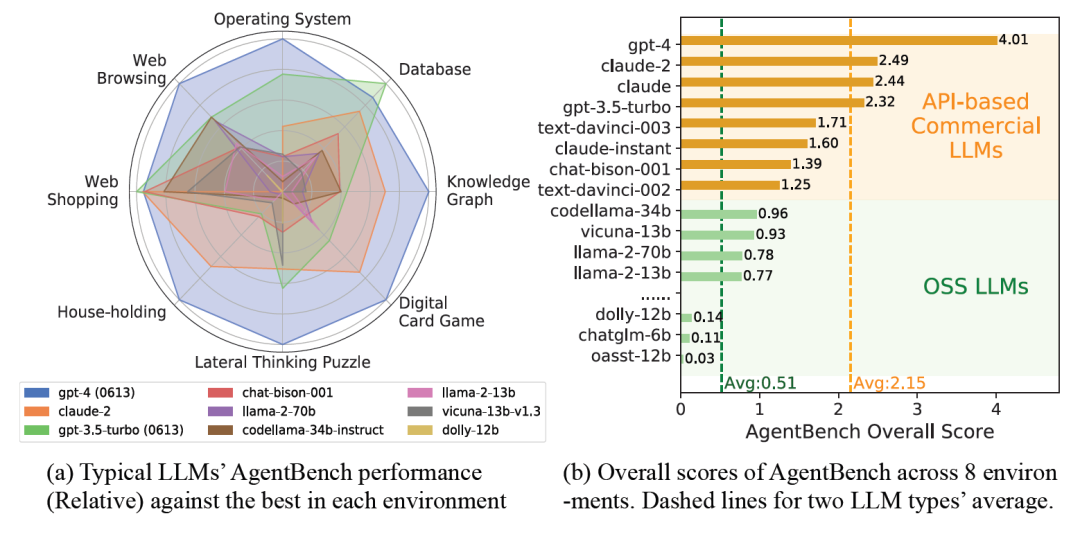
此外,AgentBench研究团队推测,代理在某些基准测试子集表现不理想,可能归因于其在长期推理、决策制定以及指令遵循等方面有限能力。
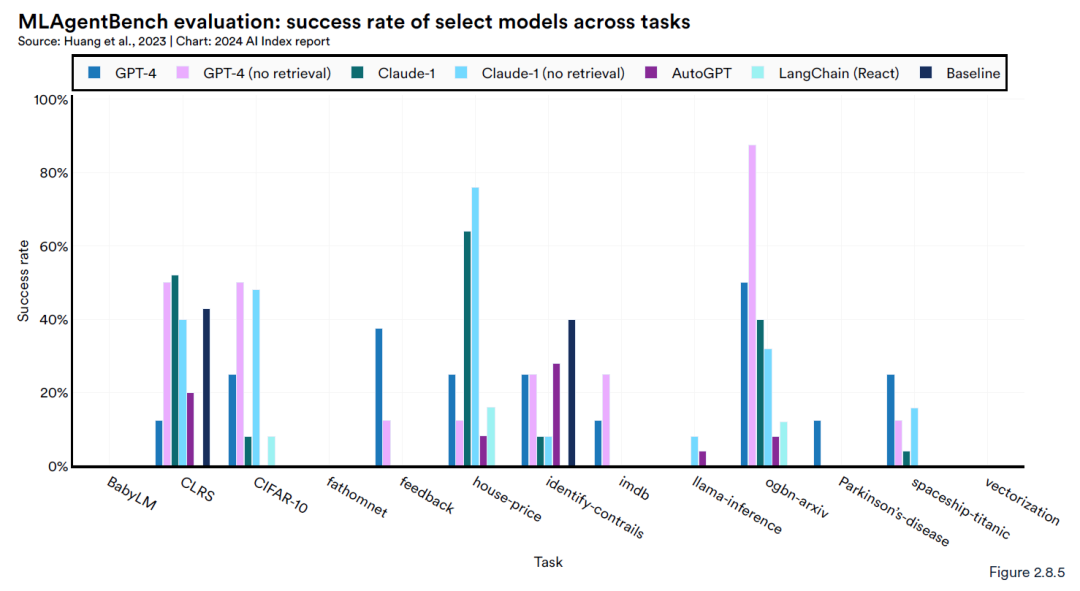
MLAgentBench是一个新的基准测试平台,主要用于评估 AI 智能体在科学研究中的表现。具体而言,它检验AI系统是否能成为合格的计算机科学研究助理,通过13种不同的研究任务来考察它们的能力。
这些任务包括在CIFAR-10图像数据集上优化基线模型和在BabyLM上训练一个涵盖超过1000万词汇的语言模型。参与测试的有多种基于LLM的AI智能体,如GPT-4, Claude-1, AutoGPT, 和 LangChain。
测试结果表明,虽然AI智能体展现出了研究潜力,但它们在不同任务上的表现差异较大。在这些测试中,GPT-4 总是能够提供最优秀的表现,然而没有任何代理可以训练BabyLM。

具身智能Embodied Artificial Intelligence
黄仁勋表示,AI下一个浪潮将是“具身智能”。英伟达、微软、Google纷纷展开机器人的军备竞赛。英伟达VIMA基于T5模型,交错融合文本和多模态输入,集合历史信息进行协助机器人预测下一步的行动。斯坦福大学利用LLM的理解、推理和代码能力,与VLM交互并生成3D Value Map,规划机械臂的运行轨迹。微软则是基于ChatGPT强大的自然语言理解能力和推理能力,生成机器人的控制代码。Google戏路较广,布局条线广泛,包括从PaLM衍生PaLM-E,从Gato迭代来的RoboCat,以及最新基于RT-1和PaLM-E升级得到的RT-2。
具身人工智能是将机器学习、计算机视觉、机器人学习和语言技术进行集成,最终形成人工智能的“具身”:能够感知、行动和协作的机器人。
VLM
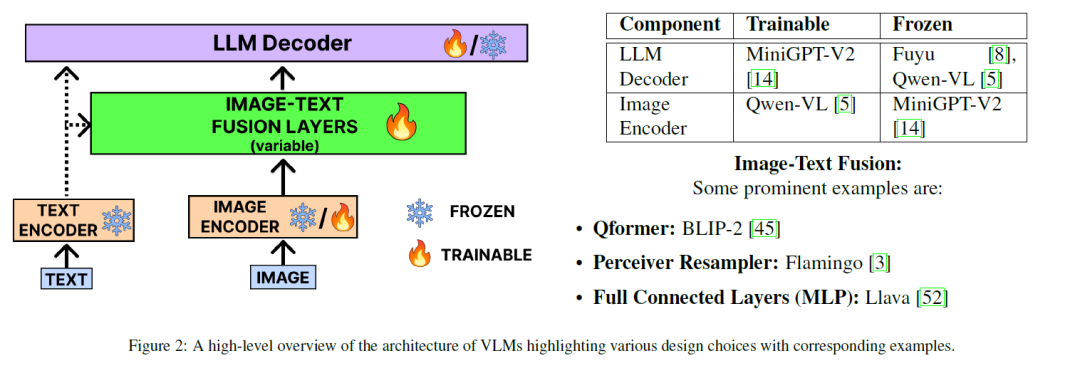
VLM视觉语言模型,是可以同时从图像和文本中学习以解决从视觉问答到图像字幕等多种任务的模型。它分为三类:视觉-语言理解模型、多模态输入文本生成模型和最先进的多模态输入-多模态输出模型。
VLM的一般架构(下图)包括一个图像和文本编码器,用于生成嵌入(不理解术语的请回到Embeddings章节)。这些嵌入在图像-文本融合层(绿色)融合,融合后的向量通过LLM生成最终的视觉感知文本。
PaLM-E
PaLM-E,多语言通识模型,适用于具身推理任务、视觉-语言任务以及语言任务。具身推理是指在机器学习模型中模拟具有物理形态的智能体(如机器人)的推理过程。将知识从视觉-语言领域转移到机器人推理领域,其能力涵盖了机器人的执行规划(在复杂动态和物理约束环境下),到所观测到世界的相关提问回答。
PaLM-E是将PaLM和ViT强强联合,5620亿的参数量为两个模型参数量相加(5400亿+220亿)。参数量是GPT-3的三倍,号称史上最大规模视觉语言模型,谷歌和柏林工业大学打造而成。作为一个能处理多模态信息的大模型,它还兼具非常强的逻辑思维。比如能从一堆图片里,判断出哪个是能滚动的。
PaLM-E 提供了一种训练通才模型的新范例,这是通过将机器人任务和视觉语言任务组合在一起:将图像和文本作为输入,并输出文本。一个关键的结果是PaLM-E从视觉和语言领域获得了明显的知识转移,提高了机器人学习的效率。
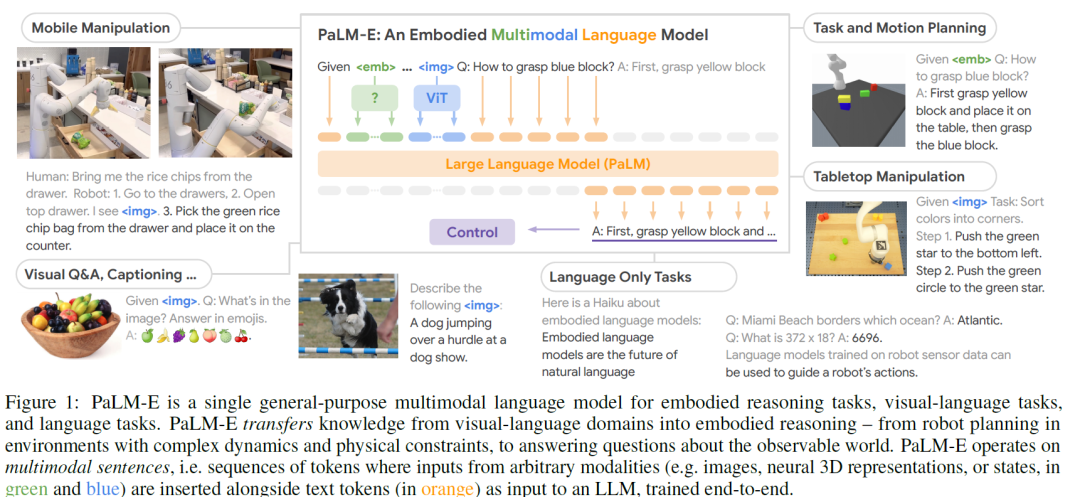
PaLM-E 的输入是文本和其他模态——图像、机器人状态、场景嵌入等——以任意顺序,可以称之为“多模态序列”。例如,输入可能类似于“ ……与……之间会发生什么?”,其中……和……可以是两个图像。输出是由 PaLM-E自动回归生成的文本,这个文本可以是问题的答案,也可以是文本形式的一系列指令。

RT-2(Robotics Transformer 2)
RT-2为Google DeepMind发布的视觉语言动作模型(VLA,Vision-Language-Action),RT-2基于大规模视觉语言模型(VLMs,Vision-Language Models)实现自然语言、图像与机器人动作的直接映射,以便通过语言指令及机器人观测到的视觉信息实现机器人运动控制任务。
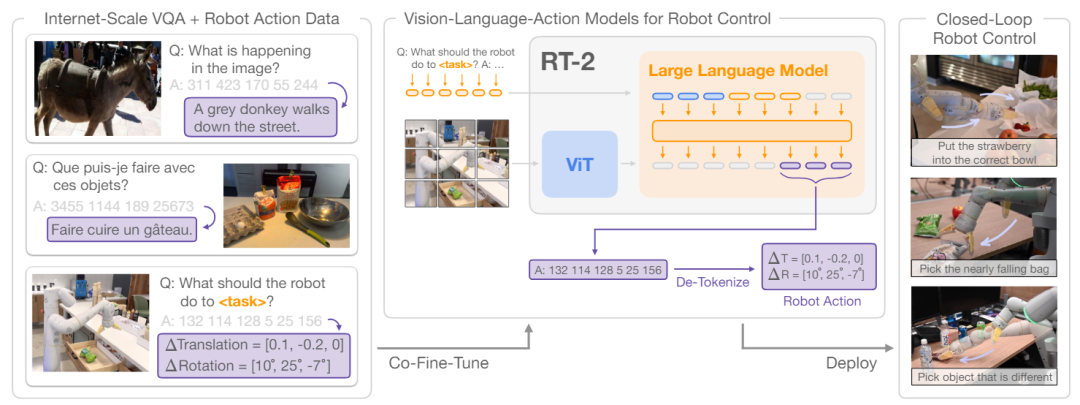
RT-2基于大规模互联网视觉语言数据集(Internet-Scale Vision-Language Datasets)对视觉大语言模型进行联合优调(Co-Fine-Tuning)改进了模型的泛化、推理、符号理解和人员识别等涌现能力。RT-2种种能力的“涌现”,并非视觉或机器人本身能力的“涌现”,而是大模型能力“涌现”的迁移。
RT-H
RT-H如图所示,有两个关键阶段:它首先从任务描述和视觉观察中预测动作(见左上图),然后对预测的动作、任务和观察进行条件设置,推断精确的执行指令(见左下图)。
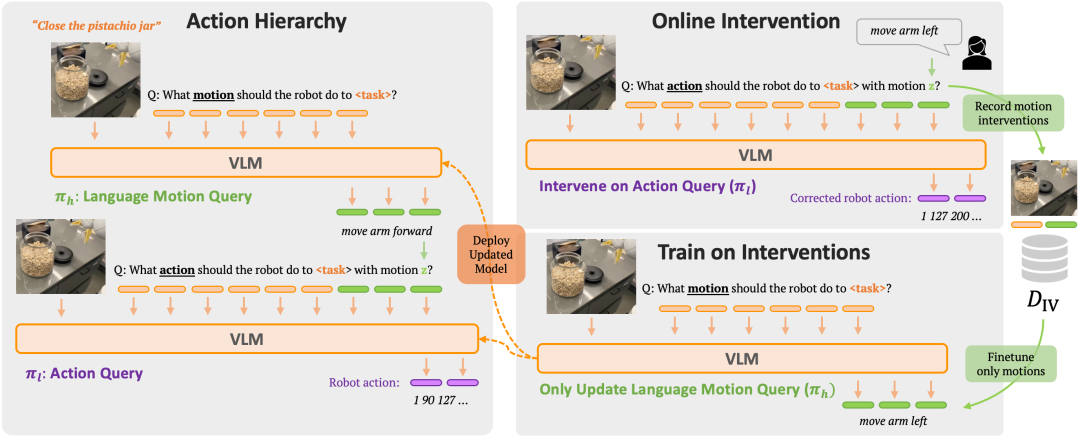
用VLM实例化RT-H,并遵循RT-2中的训练过程。与RT-2类似,通过联合训练,利用互联网规模数据中自然语言和图像处理方面的巨大先验知识。为了将这些先验知识纳入动作分层,利用这些知识库仅仅对vlm进行动作预测微调。















 1585
1585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









